When you need to extract information from the web, you will inevitably come across the term "web scraping". At the same time, you will find a myriad of services, tools and software, which want to help you in your endeavor.
With such a large number, it's not always easy to quickly find the right tool for your very own use case and to make the right choice. That's exactly what we want to check out in today's article.
We'll be taking a closer look at the tools and software, both commercial and open-source, available in the data scraping and data extraction landscape and elaborate on their features and how you may use them best for your particular use case.

The 8 Best Tools & Software For Web Scraping & Data Extraction
Introduction To Web Scraping
Web scraping is all about collecting content from websites. Scrapers come in many shapes and forms and the exact details of what a scraper will collect will vary greatly, depending on the use cases.
A very common example is search engines, of course. They continuously crawl and scrape the web for new and updated content, to include in their search index. Other examples include:
- E-commerce - comparing prices of products across different online online shops
- Finance - monitoring the performance of stocks and commodities
- Jobs - aggregation of open vacancies from company websites and job boards
ℹ️ We have a lovely article, dedicated to this very subject - What is Web Scraping.
Please feel free to check it out, should you wish to learn more about web scraping, how it differs from web crawling, and a comprehensive list of examples, use cases, and technologies.
How To Choose A Tool For Web Scraping?
Many of us like to play Dart 🎯, but we shouldn't necessarily pick our scraping platform (or technology) like that, right?
So, before we simply jump in at the deep end, let's establish a few key parameters for our scraping project, which should help us narrow down the list of potential scraping solutions.
What to consider when scraping the web?
- Scraping Intervals - how often do you need to extract information? Is it a one-off thing? Should it happen regularly on a schedule? Once a week? Every day? Every hour? Maybe continuously?
- Data Input - what kind of data are you going to scrape? HTML, JSON, XML, something binary, like DOCX - or maybe even media, such as video, audio, or images?
- Data Export - how do you wish to receive the data? In its original raw format? Pre-processed, maybe sorted or filtered or already aggregated? Do you need a particular output format, such as CSV, JSON, XML, or maybe even imported into a database or API?
- Data Volume - how much data are you going to extract? Will it be a couple of bytes or kilobytes or are we talking about giga- and terabytes?
- Scraping Scope - do you need to scrape only a couple of pre-set pages or do you need to scrape most or all of the site? This part may also determine whether and how you need to crawl the site for new links.
- Crawling Authority - how would you find out about additional links? Does the site link all of its URLs from a central page (e.g. a sitemap) or is it necessary to crawl the whole page? May search engines be useful in finding new pages (i.e. the
site:filter)? - Site Complexity - how straightforward is the site to scrape? Are you going to handle server-composed HTML documents, or will it rather be a more complex Single-page application with lots of JavaScript interaction?
- Scraping Obstacles - is the site you want to scrape employing any security layers to block crawlers and scrapers? Will you need to solve CAPTCHAs? Do you need to take into account rate limits? Do you need to send the request from a particular location - or maybe even need to rotate networks?
- In-House Expertise - how much effort will it be for you to create the scraper setup and maintain it? How far would you like to venture into custom application code?
- Platform Requirements - how well does a scraper integrate into your infrastructure and workflows? Does it support the existing operating system? Are there interfaces to third party services and APIs you may want to use?
Once you have a clearer picture of your requirements, it should be easier to match them against the available technologies and platforms and pick the most appropriate tool for your particular scraping job.
All right, let's now take a closer look at the different types of web scrapers and popular representatives of each category. Here we go 🥳
SaaS Scrapers
SaaS scraping platforms typically provide an all-in-one service, where you use their tools to define which sites you'd like to scrape and how retrieved data should be transformed and ultimately provided to you.
While they usually come at a recurring subscription fee, they also provide quite a few additional services (e.g. proxy management, browser support) that other solutions either do not support at all or only via third-party plugins.
Generally speaking, choosing a SaaS platform for your scraping project will provide you with the most comprehensive package, both, in terms of scalability and maintainability.
ScrapingBee
ScrapingBee offers a lightweight REST API (along with support libraries for popular language platforms) which provides easy access to all the platform's features.
Among those features, you will find support for data extraction (using CSS selectors), screenshots of pages, access to Google's search API, and traditional (data-center), as well as, premium, residential proxies. Especially the latter is often necessary, in order to avoid being blocked while accessing a site.
ScrapingBee also provides access to a full-fledged Chrome browser engine, which is particularly important when scraping websites which heavily rely on JavaScript and client-side rendering.
When should I use ScrapingBee?
ScrapingBee is for developers and tech-companies who want to handle the scraping pipeline themselves without taking care of proxies and headless browsers.
ScrapingBee's black box approach ensures that all the proxy and network management is taken care of by the platform and the user only needs to provide the desired site addresses, along with the applicable request parameters.
💡 ScrapingBee offers a completely free trial with 1,000 API calls entirely on the house. All the details at https://app.scrapingbee.com/account/register.
Pros & Cons of ScrapingBee
👍
- Easy integration
- Comprehensive documentation
- Fully supporting SPAs with JavaScript rendering
- Cheaper than buying proxies, even for a large number of requests per month
- Support libraries for Python and JavaScript
👎
- Requires developer expertise on your side (in particular web API handling)
Diffbot
Diffbot offers a set of web APIs, which return the scraped data in a structured format. The service supports sentiment and natural language analysis, though it is rather on the pricey side, with the smallest plan starting at USD 300 a month.
When should I use Diffbot?
Diffbot's primary audience are developers and tech-companies, whose use cases focus more on data analysis (including sentiments and natural language).
Pros & Cons of Diffbot
👍
- Easy integration
- Sentiment analysis
👎
- Doesn't work with all websites
- Full proxy support only on the Enterprise plan
- Expensive
Desktop Scraper Applications
Contrary to SaaS providers, desktop scrapers are (locally) installed applications over which you have full control (very much like your web browser).
While they typically do not come with a subscription tag, and are either freely available or for a one-time license fee, they also require you to maintain any scraper instances you are running. That means you need to provide the hardware, the connectivity, and the overall system maintenance. Depending on your setup, you may also experience issues with scaling your scraper instance.
However, for smaller projects, they are definitely a viable alternative.
ScrapeBox
ScrapeBox is a desktop scraper, available for Windows and macOS, with a strong focus on SEO related tasks, and the vendor claiming it to be the "Swiss Army Knife of SEO". Though, it does come with a number of other features, which extend the scope of SEO (e.g. YouTube scraping, email aggregation, content posting, and more).
When should I use ScrapeBox?
ScrapeBox positions itself primarily for SEO use, but it may be equally useful for bulk scraping of YouTube and for general content scraping.
With its limits on scalability and proxy support, it may be particularly useful for scraping projects with smaller datasets and where it is not necessary to rotate or specify the client location.
Pros & Cons of ScrapeBox
👍
- Runs on your local machine
- Perpetual license (one-time fee)
- Feature-rich
👎
- Limited scalability (may be slow for scraping large sites)
- Proxies come at additional costs
ScreamingFrog
ScreamingFrog's SEO spider is a website crawler for Windows, macOS, and Linux. It allows you to crawl URLs to analyze and perform technical audits and onsite SEO. It is able to crawl both small and large websites efficiently, while allowing you to analyze the results in real-time.
The following video provides you with a quick overview of the tool:
When should I use ScreamingFrog?
Out of all the platforms and services mentioned in this article, ScreamingFrog focuses exclusively on SEO, so it will be most useful for SEO professionals and agencies specializing in this field but can be easily used by anyone else to scrape data effortlessly.
Pros & Cons of ScreamingFrog
👍
- Free tier
- Useful for SEO related projects
- Real-time monitoring
👎
- Yearly subscription
- Free tier rather limited (only crawling)
💡 Are you an SEO expert? Check out our guide on How to scrape Google Search Results
Easy Web Extract
Easy Web Extract is a classic Windows desktop application and provides a user-friendly UI, where most data selection steps can be configured without the need for code.
When should I use Easy Web Extract?
Unlike ScrapeBox and ScreamingFrog, Easy Web Extract does not place its main emphasis on SEO, but markets itself rather as a general-purpose scraper.
With the application being limited by local system and network resources, you may experience scalability and site block issues, though. In this context, it may work best for small scraping jobs.
Pros & Cons of Easy Web Extract
👍
- Visual point'n'click scraper configuration
- Free trial version
- Perpetual license (one-time fee)
- Inexpensive license fee
👎
- No recent releases
- Limited scalability
- Manual proxy configuration
No-Code Browser Scrapers
Another rather popular category of web scrapers is based on browser extensions. These scrapers run directly in your web browser instance and make full use of your browser engine and its integrated web technologies (the DOM, CSS styles and selectors, and running JavaScript).
Both Firefox and Chrome have countless such scraper tools in their extension galleries. For example, for Chrome, you can find a full list at https://chrome.google.com/webstore/search/scraper?_category=extensions, but let's take a look at three representatives of this category of scraper.
WebScraper.io
WebScraper is one of the most popular Chrome scraper extensions. It allows you to scrape websites directly from your browser, without the need to locally set up any tools or or write scraping script code.
Here is a screenshot of the interface (accessible within the Chrome dev tools):
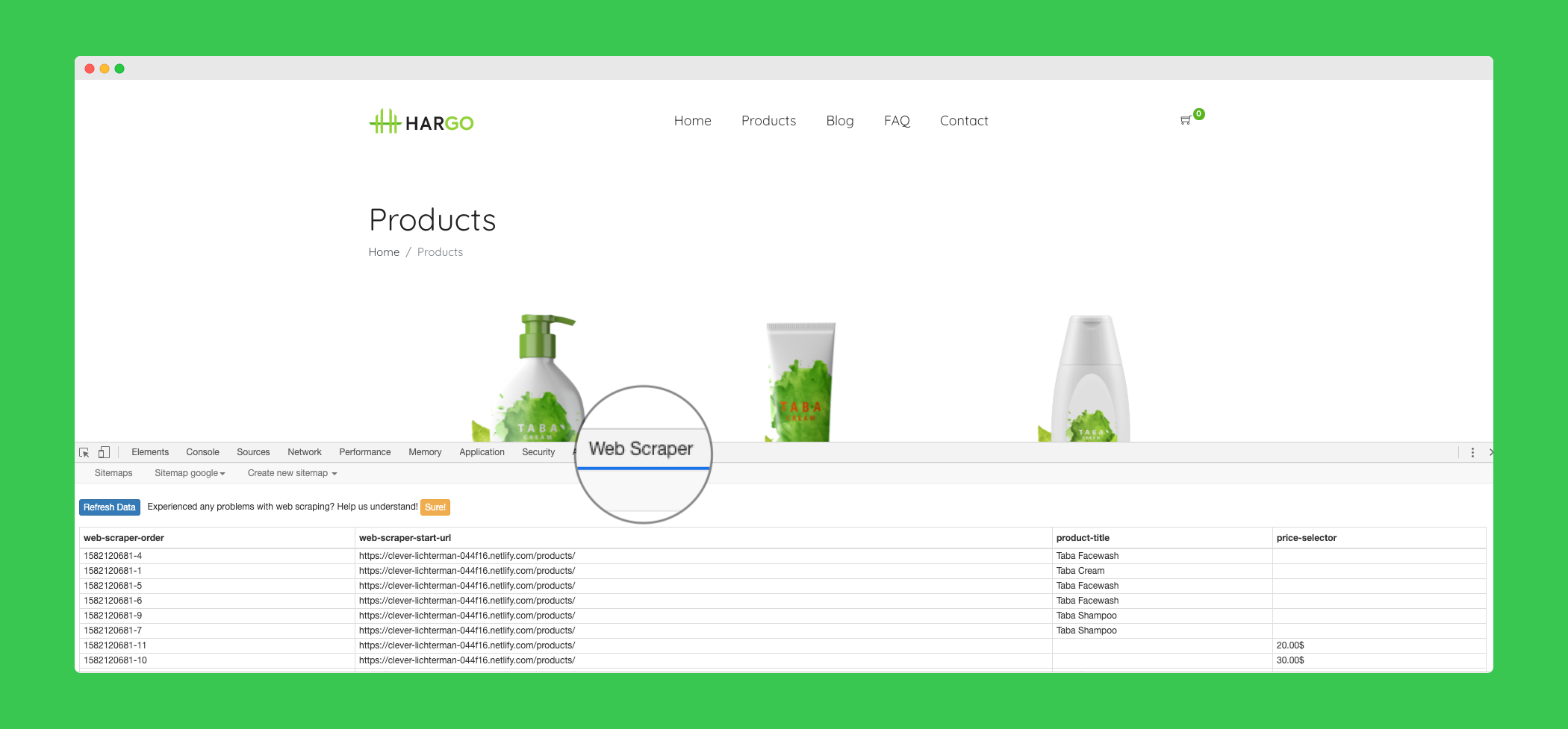
There's also a short video covering the basics of the extension:
They also offer a cloud-based, paid subscription service, which allows you to execute your scraping tasks on their infrastructure. This may be especially useful if your script needs to set a particular scraping location, with the use of proxies.
When should I use WebScraper.io?
Companies without developers, marketing teams, product managers...
Pros & Cons of WebScraper.io
👍
- Simple to use
👎
- Can't handle complex web scraping scenarios
Instant Data Scraper
Instant Data Scraper is the extension of webrobots.io. You simply add it to your Chrome profile and, after which a new button will show up in your browser toolbar, which provides you access to the scraper's features.
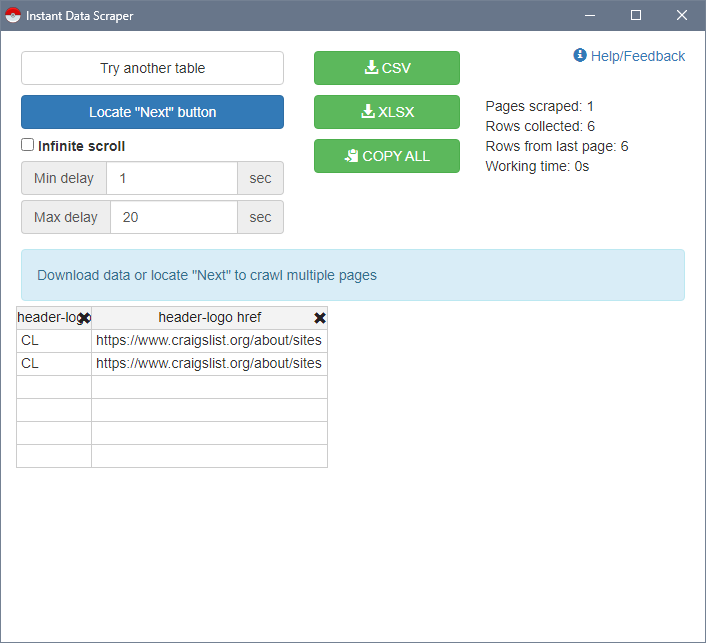
The extension is very data table-centric and you only need to select the desired data items with your mouse. Once scraping has finished you can export the data as CSV or Excel file.
Check out the following video to watch Instant Data Scraper live in action - even coupled with nice banjo tune 🪕:
When should I use Instant Data Scraper?
For quick, on-the-fly scraping sessions.
Pros & Cons of Instant Data Scraper
👍
- Straightforward UI
👎
- Limited scraping actions
Scraper
Scraper uses XPath expressions to extract data. You add the extension, open the desired page, right click and select "Scrape similar".
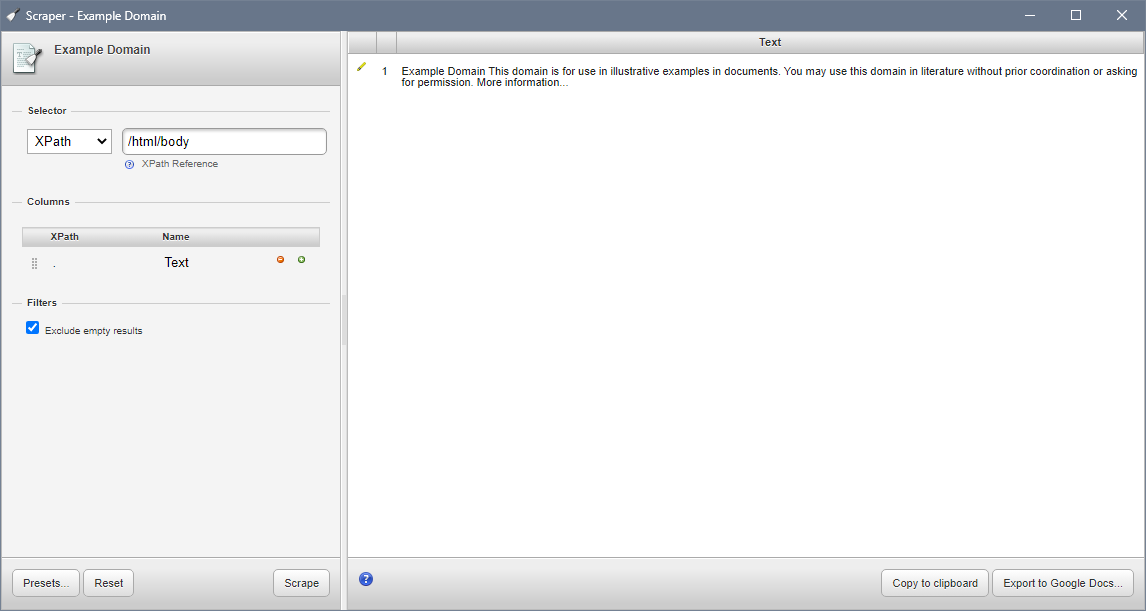
The extension does not pursue any commercial interest at the moment, so it is completely free, but neither offers any additional services (e.g. cloud-based execution).
ℹ️ What's XPath?
Glad you asked, we have a fantastic tutorial on XPath and how to use it to access and extract data from web pages. Check it out, highly recommended. You can also check our tutorial about XPath vs CSS selectors
When should I use Scraper?
For basic extraction tasks without complex page structures or browsing requirements.
Pros & Cons of Scraper
👍
- Completely free
👎
- Limited scraping actions
DIY Scrapers (Frameworks, Libraries)
Last, but not least, there's of course also always the option to build your very own, fully customized scraper in your favorite programming language.
You'll find web scraping libraries and entire frameworks for almost every language and even somewhat more exotic languages, such as the statistical R, have support for web scraping.
While we will focus in the following examples on Python, PHP, and JavaScript, please also feel free to check out ScrapingBee's blog, where you will find lots of more language examples, among them for Ruby, Groovy, Perl, Go, and C++ - just to name a few.
Scrapy
Scrapy is a free open-source web-crawling framework written in Python. As it handles requests in an asynchronous fashion, it performs quite well with a large number of sites, which contributes to its ability to scale well.
When should I use Scrapy?
Scrapy definitely is for an audience with a Python background. While it serves as framework and handles lots of the scraping on its own, it still is not an out-of-the-box solution but requires sufficient experience in Python.
It works particularly well in large-scale web scraping, for example:
- Extracting e-commerce product data
- Extracting articles from news websites
- Crawling entire domains for their links
Pros & Cons of Scrapy
👍
- Lots of features to solve the most common web scraping problems
- Actively maintained
- Great documentation
👎
- Development experience required
- Support for JavaScript needs to be configured manually
pyspider
pyspider is another open-source web crawling tool. It has a web UI that allows you to monitor tasks, edit scripts and view your results.
When should I use pyspider?
Similarly to Scrapy, it requires a Python background, but its integrated UI also makes it more suitable for the general public and provides a more user-friendly UX.
Pros & Cons of pyspider
👍
- Open-source
- Popular (16K Github stars) and active project
- Solves lots of common web scraping issues
- Powerful web UI
👎
- Steep learning curve
- Relies on PhantomJS, which was de-facto superseded by Headless Chrome, for JavaScript execution
Goutte
Goutte is a PHP library designed for general-purpose web crawling and web scraping. It heavily relies on Symfony components and conveniently combines them to support your scraping tasks.
Goutte provides a nice API to crawl websites and extract data from HTML/XML responses.
It also integrates nicely with the Guzzle requests library, which allows you to customize the framework for more advanced use cases.
When should I use Goutte?
Being a PHP library, Goutte certainly is limited to a PHP environment, but if your language choice is PHP, you may definitely want to check it out.
Pros & Cons of Goutte
👍
- Open-source
- Free
👎
- Less popular than Scrapy
- Fewer integrations than Scrapy
ℹ️ Check out our Goutte tutorial for how to get started with this very handy PHP library.
Beautiful Soup

After our short excursion to PHP-land, we are right back to Python. This time with Beautiful Soup.
Unlike Scrapy and pyspider, BS4 - as fans of the library call it affectionately 🤩 - is not a framework but rather a traditional library which you can use in your scraper application.
ℹ️ Check out our BeautifulSoup tutorial for real-world BS4 examples.
When should I use Beautiful Soup?
BS4 is a great choice if you decided to go with Python for your scraper but do not want to be restricted by any framework requirements.
Beautiful Soup offers a straightforward set of functions which will support you in building your own scraper.
Pros & Cons of Beautiful Soup
👍
- Regular releases
- Active community
- Straightforward API
👎
- Difficult to use for non-developers
Cheerio.js
If you are familiar with jQuery, you will immediately feel at home with Cheerio.js, it essentially is the server-side counterpart.
Cheerio supports all CSS selector syntax you know from jQuery and allows you to parse HTML documents from a number of sources and extract data with a familiar $('') call.
When should I use Cheerio.js?
Can really be summarized in one sentence: when you have HTML content to parse in a JavaScript or Node.js environment. And yes, you should be familiar with JavaScript, Node.js, and npm.
All right, those were two sentences. 😳
Pros & Cons of Cheerio.js
👍
- Familiar jQuery syntax with CSS selectors
- Excellent parsing and data extraction performance
👎
- Does not support JavaScript generated content (SPA)
- Requires experience in JavaScript and the Node.js environment
Puppeteer
Puppeteer is a Node.js library which acts as a bridge to a Chrome Headless instance, which allows you to control a full-fledged browser setup and scrape the web from your JavaScript code as if you were any regular user.
Full control in this context means you can take screenshots, load SPAs, and send and handle JavaScript events.
When should I use Puppeteer?
Puppeteer will be your go-to tool if your choice of platform is JavaScript and you want to scrape JavaScript-heavy sites (e.g. SPAs) where Cheerio, for example, did not manage to access the desired data. Backed by a proper browser engine, Puppeteer will grant you access to that data treasure in no time.
Pros & Cons of Puppeteer
👍
- Provides a full-fledged browser environment
- Can solve automated JavaScript challenges
👎
- Requires Chrome to be installed
- Heavier on resources than e.g. Cheerio
Cloudscraper
Cloudscraper is a Python library implemented with the Requests library, designed to bypass Cloudflare's anti-bot challenges. It is specifically created to scrape data from websites protected by Cloudflare.
This tool leverages a JavaScript engine/interpreter to overcome JavaScript challenges without requiring explicit deobfuscation and parsing of Cloudflare's JavaScript code.
When should I use Cloudscraper?
Cloudscraper is an actively maintained open-source project, which is a rarity for open-source Cloudflare tech.
It's important to note that not all Cloudflare-protected websites can be accessed. Currently, Cloudscraper cannot scrape websites protected by the newer version of Cloudflare. A significant number of websites are using this updated version. One such example is the Author website.
Pros & Cons of Cloudscraper
👍
- Open source and free
- Popular (4.1K Github stars) and active project
- Designed to be similar to the popular requests library
- Solves lots of cloudflare anti-bot mechanisms
👎
- Can't scrape websites protected by the newer version of Cloudflare or more advanced CAPTCHA systems.
- Continuous maintenance is required to stay up-to-date.
Check out our full guide on How to bypass Cloudflare at scale.
Undetected Chromedriver
The Selenium undetected_chromedriver is an enhanced version of the standard ChromeDriver which is designed to bypass anti-bot services such as Cloudflare, Distill Network, Imperva, or DataDome.
It enables your bot to appear more human-like as compared to a regular one.
When should I use undetected_chromedriver?
Undetectable ChromeDriver is capable of patching most of the ways through which anti-bot systems can detect your Selenium bot or scraper, but it still struggles against advanced anti-bot systems.
Pros & Cons of Cloudscraper
👍
- Open source and free
- Actively maintained project
- Capable of patching most of the ways of anti-bot systems
👎
- Require knowledge of Selenium chromerdriver.
- Setting up and using undetected chromedriver requires additional configuration.
- Continuous maintenance is required to stay up-to-date.
Nodriver
NoDriver is an asynchronous tool that replaces traditional components such as Selenium or webdriver binaries, providing direct communication with browsers.
This approach not only reduces the detection rate by most anti-bot solutions but also significantly improves the tool's performance.
When should I use Nodriver?
NoDriver will be your go-to tool whenever you need a blazing-fast framework for web automation, web scraping, bots, and any other creative ideas normally hindered by annoying anti-bot systems like Captcha, CloudFlare, Imperva, and hCaptcha.
If you're familiar with Python Selenium WebDriver and undetected Chromedriver, picking up NoDriver is a breeze. It's the official successor to the Undetected-Chromedriver Python package, built for seamless integration.
Pros & Cons of Nodriver
👍
- No more webdriver, no more selenium.
- A fast and undetected Chrome automation library.
- Can be set up and running in just one line of code.
- Uses a fresh profile for each run and cleans up on exit.
- Open source, free, and actively maintained.
👎
- Nodriver struggles against advanced anti-bot systems.
- Smaller user base and less readily available support resources like tutorials or forums.
Honourable mention (Common Crawl)
While not a scraper application or code framework per se, it still is worth mentioning Common Crawl.
The project does not function as a data extractor, like the services and tools we so far talked about, but approaches the topic from a very different angle. It essentially crawls and scrapes the web in advance and provides that data as publicly available datasets for everyone to access at no cost.

To put their crawling efforts and the available data into perspective, as of the time these lines are written, their current dataset is close to 400 TB (to have the inevitable comparison to some completely unrelated object 😉, that's about 650,000 traditional CDs).
When should I use Common Crawl?
Common Crawl will be ideal if its datasets match your requirements. If the quality of the data it pre-scraped is sufficient for your use case, it may be the easiest way to evaluate web data.
Pros & Cons of Common Crawl
👍
- Data readily available
- No scraping infrastructure necessary
👎
- No room for customizing datasets
- Very large downloads
Summary
The world of web scraping is built around a quite diverse landscape. It offers solutions for all sorts of data scraping jobs, ranging from small, local desktop applications to Enterprise platforms which can scale your crawlers up to hundreds of requests per second.
On top of that, there's a vast number of scraper libraries which will support you in almost every programming language, should you decide to go the manual route and build your own platform to crawl and scrape the web.
Whichever technology you choose, make sure you test it well before you use it for production and check for edge cases as well. Two important aspects are how well the platform scales (that is, how it deals with a large number of URLs) and how it ensures your requests do not get blocked in the first place.
We briefly touched upon the latter at What to consider when scraping the web?, and that can really be an important bit in your planning, as many sites employ anti-scraper techniques, which can essentially stop your crawler in its tracks - and you wouldn't want that 🛑.
💡 Web Scraping without getting blocked
We have a comprehensive article on this very subject, which explains quite in detail which things you may need to consider and how to avoid getting your crawler blocked. Please check it out and feedback is more than welcome.
We hope this article provided you with a good, first overview of the different available technologies in web scraping and that it may make it a bit easier to choose among all these different platforms, services, technologies, and libraries.
Should you have any further questions on how to best go ahead with your scraping project and how ScrapingBee could possibly help you, please don't even hesitate a second to reach out to us. We have specialized in this field and we are happy to help.
Happy scraping from ScrapingBee!

Kevin worked in the web scraping industry for 10 years before co-founding ScrapingBee. He is also the author of the Java Web Scraping Handbook.

