In the previous post about Web Scraping with Python we talked a bit about Scrapy. In this post we are going to dig a little bit deeper into it.
Scrapy is a wonderful open source Python web scraping framework. It handles the most common use cases when doing web scraping at scale:
- Multithreading
- Crawling (going from link to link)
- Extracting the data
- Validating
- Saving to different format / databases
- Many more
The main difference between Scrapy and other commonly used libraries, such as Requests / BeautifulSoup, is that it is opinionated, meaning it comes with a set of rules and conventions, which allow you to solve the usual web scraping problems in an elegant way.
The downside of Scrapy is that the learning curve is steep, there is a lot to learn, but that is what we are here for :)
In this tutorial we will create two different web scrapers, a simple one that will extract data from an E-commerce product page, and a more "complex" one that will scrape an entire E-commerce catalog!
Basic overview
You can install Scrapy using pip. Be careful though, the Scrapy documentation strongly suggests to install it in a dedicated virtual environment in order to avoid conflicts with your system packages.
Hence, I'm using Virtualenv and Virtualenvwrapper:
mkvirtualenv scrapy_env
Now we can simply install Scrapy ....
pip install Scrapy
.... and bootstrap our Scrapy project with startproject
scrapy startproject product_scraper
This will create all the necessary boilerplate files for the project.
├── product_scraper
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ ├── __init__.py
└── scrapy.cfg
Here is a brief overview of these files and folders:
- items.py is a model for the extracted data. You can define custom model (like a product) that will inherit the Scrapy Item class.
- middlewares.py is used to change the request / response lifecycle. For example you could create a middleware to rotate user-agents, or to use an API like ScrapingBee instead of doing the requests yourself.
- pipelines.py is used to process the extracted data, clean the HTML, validate the data, and export it to a custom format or save it to a database.
- /spiders is a folder containing Spider classes. With Scrapy, Spiders are classes that define how a website should be scraped, including what link to follow and how to extract the data for those links.
- scrapy.cfg is the configuration file for the project's main settings.
Scraping a single product
For our example, we will try to scrape a single product page from the following dummy e-commerce site
https://clever-lichterman-044f16.netlify.app/products/taba-cream.1/
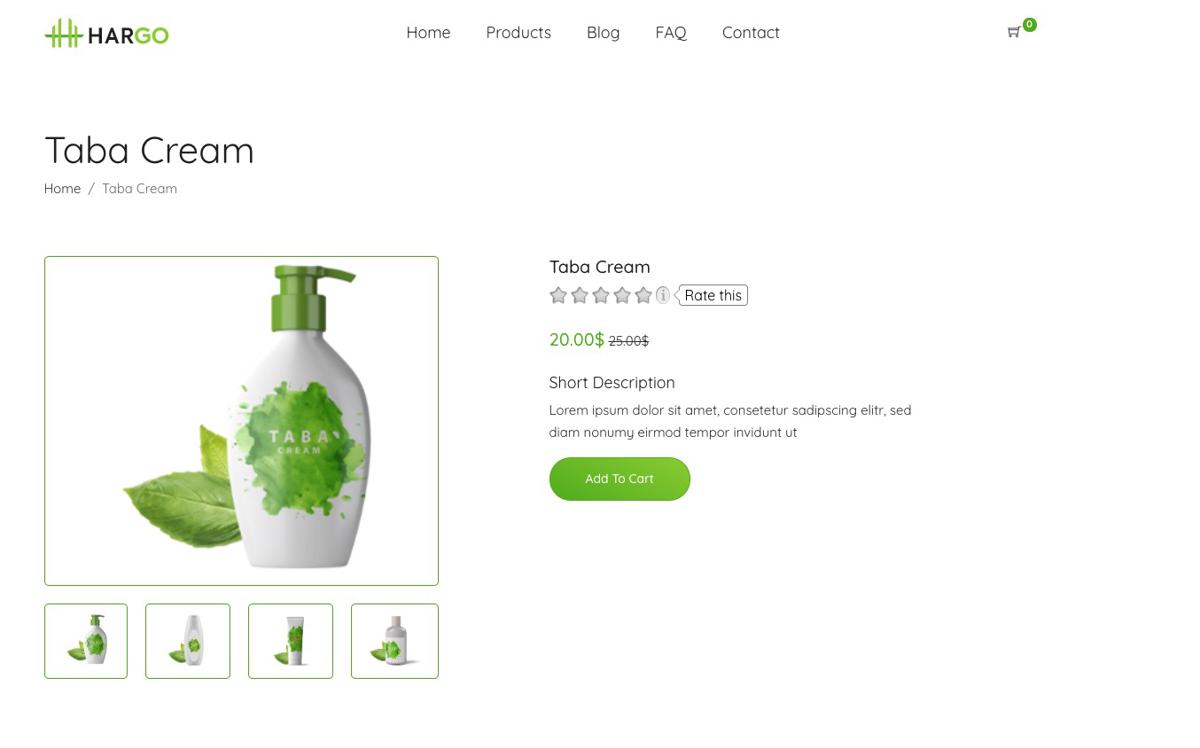
And we will want to extract the product name, the picture, the price, and the description.
Scrapy Shell
Scrapy comes with a built-in shell that helps you try and debug your scraping code in real time. You can quickly test your XPath expressions / CSS selectors with it. It's a very cool tool to write your web scrapers and I always use it!
You can configure Scrapy Shell to use another console instead of the default Python console like IPython. You will get autocompletion and other nice perks like colorized output.
In order to use it in your Scrapy Shell, you need to add this line to your scrapy.cfg file:
shell = ipython
Once it's configured, you can start using Scrapy Shell:
$ scrapy shell --nolog
[s] Available Scrapy objects:
[s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc)
[s] crawler <scrapy.crawler.Crawler object at 0x108147eb8>
[s] item {}
[s] settings <scrapy.settings.Settings object at 0x108d10978>
[s] Useful shortcuts:
[s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed)
[s] fetch(req) Fetch a scrapy.Request and update local objects
[s] shelp() Shell help (print this help)
[s] view(response) View response in a browser
In [1]:
We can start fetching a URL by simply running the following command:
fetch('https://clever-lichterman-044f16.netlify.app/products/taba-cream.1/')
This will start by fetching the /robots.txt file.
[scrapy.core.engine] DEBUG: Crawled (404) <GET https://clever-lichterman-044f16.netlify.app/robots.txt> (referer: None)
In this case, there isn't any robot.txt, that's why we got a 404 HTTP code. If there was a robot.txt, Scrapy will by default follow its rule set. You can disable this behavior by changing ROBOTSTXT_OBEY in product_scraper/settings.py:
ROBOTSTXT_OBEY = False
Running our fetch call again, you should now have a log like this:
[scrapy.core.engine] DEBUG: Crawled (200) <GET https://clever-lichterman-044f16.netlify.app/products/taba-cream.1/> (referer: None)
Scrapy will save the response straight into the response variable, which you can directly evaluate in Scrapy Shell.
For example, play with the following commands to get more insight on the response's status code and its headers.
>>> response.status
200
>>> response.headers
{b'Content-Length': [b'3952'], b'Age': [b'100'], b'Cache-Control': [b'public, max-age=0, must-revalidate'], b'Content-Type': [b'text/html; charset=UTF-8'], b'Etag': [b'"24912a02a23e2dcc54a7013e6cd7f48b-ssl-df"'], b'Server': [b'Netlify'], b'Strict-Transport-Security': [b'max-age=31536000; includeSubDomains; preload'], b'Vary': [b'Accept-Encoding']}
Additionally, Scrapy has also saved the response body straight to your temporary system directory, from where you can view it directly in your browser with
view(response)
Note, this will probably not render ideally, as your browser will only load the HTML, without its external resource dependencies or taking CORS issues into account.
The Scrapy Shell is like a regular Python shell, so don't hesitate to run your favorite scripts/function in it.
Extracting Data
Now let's try some XPath expression to extract the product title and price:
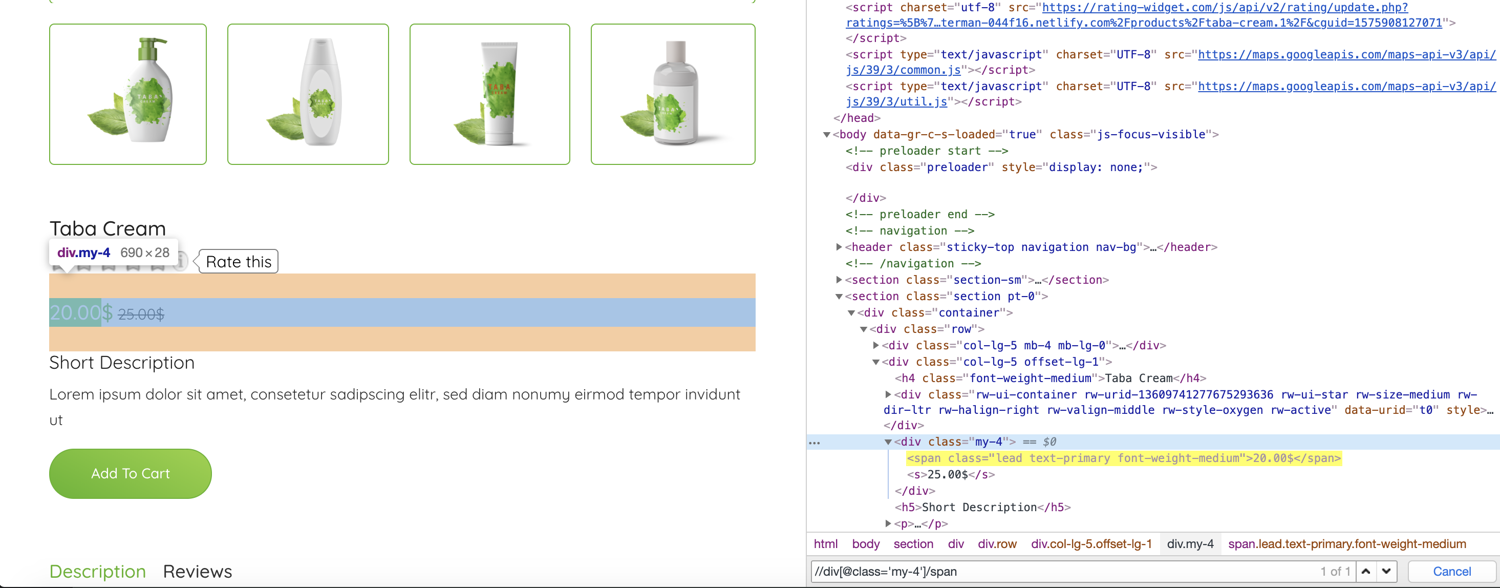
In this case, we'll be looking for the first <span> within our <div id="my-[4px]">
In [16]: response.xpath("//div[@class='my-[4px]']/span/text()").get()
Out[16]: '20.00$'
I could also use a CSS selector:
In [21]: response.css('.my-[4px] > span::text').get()
Out[21]: '20.00$'
Scrapy doesn't execute any JavaScript by default, so if the website you are trying to scrape is using a frontend framework like Angular / React.js, you could have trouble accessing the data you want.
Creating a Scrapy Spider
With Scrapy, Spiders are classes where you define your crawling (what links / URLs need to be scraped) and scraping (what to extract) behavior.
Here are the different steps used by a Spider to scrape a website:
- It starts by using the URLs in the class'
start_urlsarray as start URLs and passes them tostart_requests()to initialize the request objects. You can overridestart_requests()to customize this steps (e.g. change the HTTP method/verb and usePOSTinstead ofGETor add authentication credentials) - It will then fetch the content of each URL and save the response in a Request object, which it will pass to
parse() - The
parse()method will then extract the data (in our case, the product price, image, description, title) and return either a dictionary, an Item or Request object, or anIterable
You may wonder why the
parsemethod can return so many different objects. It's for flexibility. Let's say you want to scrape an E-commerce website that doesn't have any sitemap. You could start by scraping the product categories, so this would be a first parse method.This method would then yield a Request object to each product category to a new callback method
parse2(). For each category you would need to handle pagination Then for each product the actual scraping that generate an Item so a third parse function.
With Scrapy you can return the scraped data as a simple Python dictionary, but it is a good idea to use the built-in Scrapy Item class. It's a simple container for our scraped data and Scrapy will look at this item's fields for many things like exporting the data to different format (JSON / CSV...), the item pipeline etc.
So here is a basic product class:
import scrapy
class Product(scrapy.Item):
product_url = scrapy.Field()
price = scrapy.Field()
title = scrapy.Field()
img_url = scrapy.Field()
Now we can generate a spider, either with the command line helper:
scrapy genspider myspider mydomain.com
Or you can do it manually and put your Spider's code inside the /spiders directory.
Spider types
There's quite a number of pre-defined spider classes in Scrapy
- Spider, fetches the content of each URL, defined in
start_urls, and passes its content toparsefor data extraction - CrawlSpider, follows links defined by a set of rules
- CSVFeedSpider, extracts tabular data from CSV URLs
- SitemapSpider, extracts URLs defined in a sitemap
- XMLFeedSpider, similar to the CSV spider, but handles XML URLs (e.g. RSS or Atom)
Let's start off with an example of Spider
Scrapy Spider Example
# -*- coding: utf-8 -*-
import scrapy
from product_scraper.items import Product
class EcomSpider(scrapy.Spider):
name = 'ecom_spider'
allowed_domains = ['clever-lichterman-044f16.netlify.app']
start_urls = ['https://clever-lichterman-044f16.netlify.app/products/taba-cream.1/']
def parse(self, response):
item = Product()
item['product_url'] = response.url
item['price'] = response.xpath("//div[@class='my-[4px]']/span/text()").get()
item['title'] = response.xpath('//section[1]//h2/text()').get()
item['img_url'] = response.xpath("//div[@class='product-slider']//img/@src").get(0)
return item
Here, we created our own EcomSpider class, based on scrap.Spider, and add three fields
name, which is our Spider's name (that you can run usingscrapy runspider spider_name)start_urls, defines an array of the URLs you'd like to scrapeallowed_domains, optional but important when you use a CrawlSpider instance that could follow links on different domains
Finally, we added our own parse() method, where we instantiate a Product object, populate it with the data (using XPath again, ain't XPath great? 🥳), and return our product object.
Let's run our code in the following way, to export the data as JSON (but you could also choose CSV)
scrapy runspider ecom_spider.py -o product.json
You should now have got a nice JSON file:
[
{
"product_url": "https://clever-lichterman-044f16.netlify.app/products/taba-cream.1/",
"price": "20.00$",
"title": "Taba Cream",
"img_url": "https://clever-lichterman-044f16.netlify.app/images/products/product-2.png"
}
]
Item loaders
There are two common problems that you can face while extracting data from the Web:
- For the same website, the page layout and underlying HTML can be different. If you scrape an E-commerce website, you will often have a regular price and a discounted price, with different XPath / CSS selectors.
- The data can be dirty and you may need to normalize it, again for an E-commerce website it could be the way the prices are displayed for example (
$1.00,$1,$1,00)
Scrapy comes with a built-in solution for this, ItemLoaders. It's an interesting way to populate our product object.
You can add several XPath expression to the same Item field, and it will test it sequentially. By default, in case Scrapy could successfully more than one XPath expression, it will load all of them into a list. You can find many examples of input and output processors in the Scrapy documentation.
It's really useful when you need to transform/clean the data your extract. For example, extracting the currency from a price, transforming a unit into another one (centimeter to meters, Celsius to Fahrenheit) ...
In our webpage we can find the product title with different XPath expressions: //title and //section[1]//h2/text()
Here is how you could use and Itemloader in this case:
def parse(self, response):
l = ItemLoader(item=Product(), response=response)
l.add_xpath('price', "//div[@class='my-[4px]']/span/text()")
l.add_xpath('title', '//section[1]//h2/text()')
l.add_xpath('title', '//title')
l.add_value('product_url', response.url)
return l.load_item()
Generally, you only want the first matching XPath, so you will need to add this output_processor=TakeFirst() to your item's field constructor.
And that's exactly what we are going to do in our case, so a better approach would be to create our own ItemLoader and declare a default output processor to take the first matching XPath:
from scrapy.loader import ItemLoader
from scrapy.loader.processors import TakeFirst, MapCompose, Join
def remove_dollar_sign(value):
return value.replace('$', '')
class ProductLoader(ItemLoader):
default_output_processor = TakeFirst()
price_in = MapCompose(remove_dollar_sign)
I also added a price_in field, which is an input processor to delete the dollar sign from the price. I'm using MapCompose which is a built-in processor that takes one or several functions to be executed sequentially. You can attach as many functions as you like. The convention is to add _in or _out to your Item field's name to add an input or output processor to it.
There are many more processors, you can learn more about this in the documentation.
Item pipelines
Another extremely useful feature of Scrapy are pipelines.
Pipelines are represented by plain classes which implement a process_item method. When your spider runs, it will call that method for each product item it earlier created and each configured pipeline instance will perform its validation and post-process steps on that item.
Let's try that with a pipeline instance, which validates and normalizes our price field. The class should be declared in our product_scraper/pipelines.py file.
import re
class PriceValidatorPipeline:
def process_item(self, item, spider):
price = item.get('price')
if price is not None:
price = re.sub("[^0-9\.]", "", price)
if price:
# Convert string to float
price = float(price)
# Validate price
if price < 10 or price > 100:
price = None
else:
price = None
if price is not None :
# Set normalised price
item['price'] = price;
return item
else:
raise DropItem(f"Missing price")
What we did here is to declare a plain class PriceValidatorPipeline with aforementioned method, process_item.
That method first checks if the item has a price at all. If it doesn't, it immediately skips it with a DropItem exception.
Should there be a price, it will first try to sanitize the price string and convert it to a float value. Finally it will check if the value is within our (arbitrary) limit of USD 10 and USD 100. If all that checks out, it will store the sanitized price value in our item and pass it back to the spider, otherwise it will throw a DropItem exception to signal to our spider, that it should drop this specific item.
Last, but not least, we also need to make our spider aware of our pipeline class. We do this by editing our ITEM_PIPELINES entry in product_scraper/settings.py.
ITEM_PIPELINES = {
'product_scraper.pipelines.PriceValidatorPipeline': 100
}
The numeric value specifies the pipeline's priority. The lower the value, the earlier it will run.
Voilà, we have configured our pipeline class and the spider should now call it for each item and validate the price according to our business logic. All right, let's take that a step further and add a second pipeline to persist the data in a database, shall we?
Database pipeline
For our example, we pick MySQL as our database. As always, Python has got us covered, of course, and there's a lovely Python MySQL package, which will provide us with seamless access to our database. Let's install it first with pip
pip install mysql-connector-python
Perfect, let's code! 😎
Hang on, what about the database?
Database setup
For brevity we assume you have already set up MySQL. If not, please follow MySQL's excellent installation guide.
Once we have our database running, we just need to create a database
CREATE DATABASE scraper
and within our database a table
CREATE TABLE products (
url VARCHAR(200) NULL DEFAULT NULL,
price FLOAT NULL DEFAULT NULL,
title VARCHAR(200) NULL DEFAULT NULL,
img_url VARCHAR(200) NULL DEFAULT NULL
);
All set!
Database configuration
Next, we only need to configure our database access credentials. Just add the following four entries (with their actual values) to our configuration file product_scraper/settings.py.
MYSQL_HOST = '127.0.0.1'
MYSQL_USER = 'username'
MYSQL_PASS = 'password'
MYSQL_DB = 'scraper'
Database class
And here we go. Just add that code to product_scraper/pipelines.py.
import mysql.connector
class MySQLPipeline:
def __init__(self, mysql_host, mysql_user, mysql_pass, mysql_db):
self.mysql_host = mysql_host
self.mysql_user = mysql_user
self.mysql_pass = mysql_pass
self.mysql_db = mysql_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mysql_host = crawler.settings.get('MYSQL_HOST'),
mysql_user = crawler.settings.get('MYSQL_USER'),
mysql_pass = crawler.settings.get('MYSQL_PASS'),
mysql_db = crawler.settings.get('MYSQL_DB')
)
def open_spider(self, spider):
self.con = mysql.connector.connect(
host = self.mysql_host,
user = self.mysql_user,
password = self.mysql_pass,
database = self.mysql_db
)
def close_spider(self, spider):
self.con.close()
def process_item(self, item, spider):
cursor = self.con.cursor()
cursor.execute(
'INSERT INTO products (url, price, title, img_url) VALUES (%s, %s, %s, %s)',
(item['product_url'], item['price'], item['title'], item['img_url'])
)
self.con.commit()
cursor.close();
return item
What exactly did we do here?
We first implemented the from_crawler() method, which allows us to initialize our pipeline from a crawler context and access the crawler settings. In our example, we need it to get access to the database connection information, which we have just specified in product_scraper/settings.py.
All right, from_crawler() initializes our pipeline and returns the instance to the crawler. Next, open_spider will be called, where we initialize our MySQL instance and create the database connection. Lovely!
Now, we just sit and wait for our spider to call process_item() for each item, just as it did earlier with PriceValidatorPipeline, when we take the item and run an INSERT statement to store it in our products table. Pretty straightforward, isn't it?
And because we are good netizens, we clean up when we are done in close_spider().
At this point we are pretty much done with our database pipeline and just need to declare it again in product_scraper/settings.py, so that our crawler is aware of it.
ITEM_PIPELINES = {
'product_scraper.pipelines.PriceValidatorPipeline': 100
'product_scraper.pipelines.MySQLPipeline': 200
}
We specified "200" as priority here, to make sure it runs after our price validator pipeline.
When we now run our crawler, it should scrape the specified pages, pass the data to our price validator pipeline, where the price gets validated and properly converted to a number, and eventually pass everything to our MySQL pipeline, which will persist the product in our database. 🎉
Scraping multiple pages
Now that we know how to scrape a single page, it's time to learn how to scrape multiple pages, like the entire product catalog. As we saw earlier there are different kinds of Spiders.
When you want to scrape an entire product catalog the first thing you should look at is a sitemap. Sitemap are exactly built for this, to show web crawlers how the website is structured.
Most of the time you can find one at base_url/sitemap.xml. Parsing a sitemap can be tricky, and again, Scrapy is here to help you with this.
In our case, you can find the sitemap here: https://clever-lichterman-044f16.netlify.app/sitemap.xml
If we look inside the sitemap there are many URLs that we are not interested by, like the home page, blog posts etc:
<url>
<loc>
https://clever-lichterman-044f16.netlify.com/blog/post-1/
</loc>
<lastmod>2019-10-17T11:22:16+06:00</lastmod>
</url>
<url>
<loc>
https://clever-lichterman-044f16.netlify.com/products/
</loc>
<lastmod>2019-10-17T11:22:16+06:00</lastmod>
</url>
<url>
<loc>
https://clever-lichterman-044f16.netlify.com/products/taba-cream.1/
</loc>
<lastmod>2019-10-17T11:22:16+06:00</lastmod>
</url>
Fortunately, we can filter the URLs to parse only those that matches some pattern, it's really easy, here we only to have URL that
have /products/ in their URLs:
class SitemapSpider(SitemapSpider):
name = "sitemap_spider"
sitemap_urls = ['https://clever-lichterman-044f16.netlify.app/sitemap.xml']
sitemap_rules = [
('/products/', 'parse_product')
]
def parse_product(self, response):
# ... scrape product ...
Here, we simply used the default sitemap_rules field to specify one entry, where we instructed Scrapy to call our parse_product method for each URL which matched our /products/ regular expression.
You can run this spider with the following command to scrape all the products and export the result to a CSV file:
scrapy runspider sitemap_spider.py -o output.csv
Now what if the website didn't have any sitemap? Once again, Scrapy has a solution for this!
Let me introduce you to the... CrawlSpider.
Just like our original spider, the CrawlSpider will crawl the target website by starting with a start_urls list. Then for each url, it will extract all the links based on a list of Rules.
In our case it's easy, products has the same URL pattern /products/product_title so we only need filter these URLs.
import scrapy
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
from product_scraper.productloader import ProductLoader
from product_scraper.items import Product
class MySpider(CrawlSpider):
name = 'crawl_spider'
allowed_domains = ['clever-lichterman-044f16.netlify.com']
start_urls = ['https://clever-lichterman-044f16.netlify.com/products/']
rules = (
Rule(LinkExtractor(allow=('products', )), callback='parse_product'),
)
def parse_product(self, response):
# .. parse product
As you can see, all these built-in Spiders are really easy to use. It would have been much more complex to do it from scratch.
With Scrapy you don't have to think about the crawling logic, like adding new URLs to a queue, keeping track of already parsed URLs, multi-threading...
💡 One thing to still keep in mind is rate limits and bot detection. Many sites use such features to actively stop scrapers from access their data. At ScrapingBee, we took all these issues into account and provide a platform to handle them in an easy, elegant, and scalable fashion.
Please check out our no-code scraping solution for more details on how ScrapingBee can help you with your scraping projects. And the first one thousand API calls are entirely free.
Conclusion
In this post we saw a general overview of how to scrape the web with Scrapy and how it can solve your most common web scraping challenges. Of course we only touched the surface and there are many more interesting things to explore, like middlewares, exporters, extensions, pipelines!
If you've been doing web scraping more "manually" with tools like BeautifulSoup / Requests, it's easy to understand how Scrapy can help save time and build more maintainable scrapers. I hope you liked this Scrapy tutorial and that it will motivate you to experiment with it.
For further reading don't hesitate to look at the great Scrapy documentation. We have also published our custom integration with Scrapy, it allows you to execute Javascript with Scrapy, so please feel free to check it out and provide us with any feedback you may have.
You can also check out our web scraping with Python tutorial to learn more about web scraping.
Happy Scraping!
Before you go, check out these related reads:

Kevin worked in the web scraping industry for 10 years before co-founding ScrapingBee. He is also the author of the Java Web Scraping Handbook.
