Rust web scraping is about programmatically collecting data from websites using Rust's speed, safety, and async tooling. It matters because more products, prices, and public data live on the web, and developers need reliable ways to extract that data without fragile scripts or slow runtimes.
In this guide, you'll learn how to scrape websites with Rust step by step. We'll start with a minimal setup for static pages, show how to parse and extract structured data, and then move into real-world cases like JavaScript-heavy sites and bot-protected marketplaces. You'll also see when it makes sense to switch from low-level scraping to a Web Scraping API, and how Rust fits cleanly into that workflow.
By the end, you'll know how to build practical Rust web scrapers that work on both simple demo sites and messy production pages.

Quick answer (TL;DR)
Rust web scraping usually comes down to three steps:
- Fetch HTML with
reqwest - Parse it with
scraperusing CSS selectors - Extract data into Rust structs
For static or lightly dynamic sites, this stack is enough: reqwest for HTTP, tokio for async, scraper for HTML parsing.
When sites rely heavily on JavaScript, rotate markup often, or block bots aggressively, many developers switch to a Web Scraping API. The API handles rendering, proxies, retries, and blocking. Rust stays focused on parsing and processing clean HTML or JSON.
If you're unsure whether your use case is scraping or crawling, this explainer helps clarify the difference:
Scraping vs Crawling.
Let's check a quick example that fetches a page, parses HTML, extracts book titles, and prints results.
You'll need the following dependencies:
[dependencies]
reqwest = { version = "0.12.25", features = ["rustls-tls"] }
tokio = { version = "1.48.0", features = ["full"] }
scraper = "0.25"
And here's the copy-pasteable code:
use scraper::{Html, Selector};
// Async entry point powered by Tokio
// This allows us to use `.await` inside `main`
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
// Target page to scrape
let url = "https://books.toscrape.com/";
// Fetch raw HTML from the page
let html = fetch_html(url).await?;
// Parse HTML and extract book titles
let titles = extract_titles(&html);
// Basic output to verify results
println!("Found {} books", titles.len());
for (i, title) in titles.iter().take(5).enumerate() {
println!("{}. {}", i + 1, title);
}
Ok(())
}
// Fetches page HTML over HTTP
// Fails early on non-2xx responses
async fn fetch_html(url: &str) -> Result<String, reqwest::Error> {
// For real sites, you'll usually want to set a User-Agent
reqwest::get(url)
.await?
.error_for_status()? // turn HTTP errors into Rust errors
.text() // read response body as text
.await
}
// Extracts book titles from page HTML
fn extract_titles(html: &str) -> Vec<String> {
// Parse HTML into a DOM tree
let document = Html::parse_document(html);
// Selector for individual book cards
let book_sel = Selector::parse("article.product_pod").unwrap();
// Selector for title links inside each card
let title_sel = Selector::parse("h3 a").unwrap();
document
// Find all book cards
.select(&book_sel)
// For each card, find the first title link (if any)
.filter_map(|book| book.select(&title_sel).next())
// Extract the full title from the "title" attribute
.map(|a| a.value().attr("title").unwrap_or("").trim().to_string())
// Drop empty titles just in case
.filter(|t| !t.is_empty())
// Collect results into a vector
.collect()
}
When this is enough:
- Static pages
- Predictable HTML
- Small to medium scrape jobs
- Learning Rust web scraping fundamentals
When to use an API instead:
- JavaScript-rendered pages
- Unstable or hashed CSS classes
- Aggressive anti-bot protection
- Large-scale scraping
In those cases, you let an API fetch clean HTML or JSON, and keep Rust focused on parsing and data logic.
What you need for Rust web scraping
Before you jump into Rust web scraping, let's level-set. This isn't a massive setup, and you don't need to be a Rust wizard. But having the right tools (and knowing why you need them) will save you a ton of pain later.
Think of this as your starter pack.
Core tools you'll use
- reqwest — your main HTTP workhorse. This is how you fetch pages, send headers, deal with cookies, and make GET or POST requests. If you're scraping with Rust, you're almost always using reqwest.
- scraper — for turning raw HTML into something usable. It lets you query pages with CSS selectors and pull out text, links, prices, whatever you're after. If you've used BeautifulSoup or Cheerio before, this will feel familiar.
- tokio — the async engine running under the hood. Most Rust web scraping is async, especially once you scrape more than one page.
- Headless browsers (optional) — only if the site needs JavaScript. If the content isn't in the raw HTML, you'll need rendering. That can mean Playwright, Selenium, or an external scraping service that handles JS for you. For beginners, avoid this unless you truly need it.
Skills you should have first
You don't need years of Rust experience, but a few basics should already feel normal:
- Basic Rust syntax (functions, structs, enums)
- How
cargoworks and how to add dependencies - A rough idea of HTTP (requests, responses, status codes)
- Some HTML knowledge (tags, attributes, nesting)
That's it. You'll learn more Rust naturally as you scrape more sites.
If CSS selectors still feel a bit blurry, bookmark this: XPath and CSS Cheat Sheet. You'll come back to it constantly when doing Rust web scraping.
Setting up Rust for web scraping
Let's get you from zero to a real request.
1. Install Rust
If Rust isn't on your machine yet, this is the fastest way on macOS and Linux:
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
On Windows, just grab rustup-init.exe from rustup.rs and follow the instructions.
Once that's done, make sure everything is alive:
rustc --version
cargo --version
If both commands respond, you're set.
2. Create a new project
Spin up a fresh project:
cargo new rust-web-scraper
cd rust-web-scraper
That's it. You now have a working Rust project with src/main.rs ready to go. Cargo handles the boring parts.
3. Add dependencies
Open Cargo.toml and drop this in:
[dependencies]
reqwest = { version = "0.12.25", features = ["rustls-tls"] }
tokio = { version = "1.48.0", features = ["full"] }
scraper = "0.25"
This combo covers most Rust web scraping use cases:
reqwestfor fetching pagestokiofor async executionscraperfor pulling data out of HTML
You won't need much more at the beginner stage.
4. Make your first request
Open src/main.rs and replace it with:
// Async entry point enabled by Tokio
// Allows us to use `.await` inside `main`
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
// Send a simple GET request to the target URL
let body = reqwest::get("https://example.com")
.await? // wait for the HTTP response
.text() // read response body as text
.await?; // wait for the full body to be collected
// Print the raw HTML response
println!("{}", body);
Ok(())
}
Run it:
cargo run
If HTML shows up in your terminal, congrats: that's your first successful Rust web scraping request. From here, everything else is just filtering and looping.
If you come from frontend land and want a familiar mental model for parsing, this is useful: HTML Parsing with jQuery.
Handling dynamic pages
Not every site plays nice. Some won't give you the data upfront.
What "dynamic pages" actually mean
Some pages load their content with JavaScript after the page loads. If you fetch them with reqwest, you only get the bare HTML shell: no product list, no prices, nothing useful.
That's what people mean by a dynamic page.
Why this matters in Rust
In Rust web scraping, reqwest is just making HTTP requests. It does not execute JavaScript. So if the site relies on JS to load data, reqwest will never see it. It's just how HTTP works.
Your main options
You usually have three realistic paths here:
- Find the underlying API — this is the best-case scenario. Many sites load data from JSON endpoints. If you can hit those directly, scraping becomes fast, clean, and reliable.
- Use a headless browser — tools like Selenium or Playwright run a real browser, execute JavaScript, and give you the final rendered page. More power, more setup, slower runs.
- Use a scraping service — these handle JavaScript rendering, browser automation, proxies, and blocking for you. You trade control for convenience.
For beginners, always try the API route first. It saves time and sanity.
If you want to see how Selenium fits into this setup, start here: Getting started with RSelenium
How to scrape websites in Rust step by step
Let's do a real scrape. We'll use books.toscrape.com because it's simple and stable.
Goal: fetch the page, find each book card, and pull out a few fields.
1. Fetch HTML with reqwest
This example downloads the page HTML and fails fast if something goes wrong.
use reqwest::header::{HeaderMap, USER_AGENT};
pub async fn fetch_html(url: &str) -> Result<String, reqwest::Error> {
// Some sites block requests with no/odd User-Agent.
// This is a simple, polite one.
let mut headers = HeaderMap::new();
headers.insert(USER_AGENT, "rust-web-scraper/0.1".parse().unwrap());
// Client is built once per call here for simplicity.
// If you're scraping multiple URLs, build it once and reuse it (see note below).
let client = reqwest::Client::builder()
.default_headers(headers)
.build()?;
client
.get(url)
.send()
.await?
// Turns 404/500 into an error right here.
// Without this, you'd happily parse a "Not Found" HTML page.
.error_for_status()?
.text()
.await
}
A few key points worth knowing for Rust web scraping:
- User-Agent is not optional in practice. Some sites serve different content (or block you) if you look like a blank client. Setting a basic one is an easy win.
Clientreuse matters for speed.reqwest::Clientkeeps connections open and reuses them. If you fetch many pages, build the client once and pass it in, instead of rebuilding it every time..error_for_status()saves you from silent garbage. Without it, a 404 page is still valid HTML, and your parser will happily extract "data" that isn't real.- This returns raw HTML, not parsed data. That's on purpose. Keep fetching and parsing separate. It makes your code easier to debug and test.
2. Count books and extract titles
Now we move from raw HTML to actual data.
First, let's count how many books are on the page.
pub fn count_books(html: &str) -> usize {
let document = Html::parse_document(html);
let book_selector = Selector::parse("article.product_pod").unwrap();
document.select(&book_selector).count()
}
What's happening here:
Html::parse_documentturns the HTML string into a searchable DOM.article.product_podis the CSS selector for a single book card on the page.select()finds all matching elements.count()tells us how many there are.
Next, let's extract the book titles.
pub fn extract_titles(html: &str) -> Vec<String> {
let document = Html::parse_document(html);
let book_selector = Selector::parse("article.product_pod").unwrap();
let title_selector = Selector::parse("h3 a").unwrap();
document
.select(&book_selector)
// look inside each book card
.filter_map(|book| book.select(&title_selector).next())
.map(|a| {
// the full title lives in the "title" attribute
// visible text can be truncated
a.value().attr("title").unwrap_or("").trim().to_string()
})
// drop empty results just in case
.filter(|t| !t.is_empty())
.collect()
}
Key ideas to notice:
- We scope selectors: first find book cards, then search inside them. This avoids accidental matches.
- The book title comes from the
titleattribute, not the visible text. filter_mapkeeps the code safe if an element is missing.- The result is a clean
Vec<String>you can print, save, or process further.
3. Tie it together in main
Now we wire everything up and actually run the scrape.
use reqwest::header::{HeaderMap, USER_AGENT};
use scraper::{Html, Selector};
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
let url = "https://books.toscrape.com/";
let html = fetch_html(url).await?;
let books_count = count_books(&html);
println!("Found {} books on the page", books_count);
for (i, title) in extract_titles(&html).into_iter().take(5).enumerate() {
println!("{}. {}", i + 1, title);
}
Ok(())
}
// other functions...
What this does:
#[tokio::main]lets us useasynccode inmain.- We fetch the HTML once and reuse it.
count_booksgives us a quick sanity check that parsing works.extract_titlesreturns all titles as a vector..take(5)limits output so you don't spam your terminal while testing.enumerate()is just for nice numbering.
This is the basic Rust web scraping flow you'll use everywhere: request → parse → select → loop. Once this works, scaling up is mostly about looping over pages, handling errors, and storing results.
If you ever need a "browser-style" approach instead (simulate a real browser DOM), this is a decent reference point: Getting started with HtmlUnit.
Extracting structured data
Now we stop dumping raw HTML and start pulling real fields you can actually use.
On books.toscrape.com, each book lives inside article.product_pod. From there, you can grab everything you need:
- title:
h3 a[title](this holds the full title) - price:
.price_color - link:
h3 a[href](relative URL) - image:
.image_container img[src](relative URL) - rating:
p.star-rating(class likeThree,Five, etc.)
This structure is very typical. Once you understand one page, most others feel the same.
How data parsing works (in plain words)
HTML scraping never gives you perfect data out of the box. You mostly get strings, often messy ones. So the usual cleanup steps look like this:
trim()text to remove random whitespace- normalize URLs (
catalogue/...→ full URL) - convert types (price string → number, rating words → integer)
None of this is Rust-specific. This is just scraping reality.
Below is an example that pulls those fields into a struct and prints JSON. That's usually the point where scraped data becomes actually useful.
Example: Extract books and output JSON
Dependencies for structured scraping
Add these to Cargo.toml:
[dependencies]
reqwest = { version = "0.12.25", features = ["rustls-tls"] }
tokio = { version = "1.48.0", features = ["full"] }
scraper = "0.25"
serde = { version = "1", features = ["derive"] }
serde_json = "1"
url = "2"
What each one does:
- reqwest — fetch pages
- tokio — async runtime
- scraper — HTML parsing with CSS selectors
- serde / serde_json — turn Rust structs into JSON
- url — safely resolve relative URLs
Define the data shape
We start by defining what a "book" looks like in Rust.
use serde::Serialize;
#[derive(Debug, Serialize)]
struct Book {
title: String,
price: String,
rating: String,
link: String,
image: String,
}
This struct is your contract. Everything you scrape should end up here in a clean, predictable form.
Main flow
The main function just coordinates the work.
use reqwest::header::{HeaderMap, USER_AGENT};
use scraper::{Html, Selector};
use serde::Serialize;
use url::Url;
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
// Parse the base URL once
// This is later used to resolve relative links and image paths
let base_url = Url::parse("https://books.toscrape.com/")?;
// Fetch raw HTML from the page
let html = fetch_html(base_url.as_str()).await?;
// Extract structured book data from the HTML
let books = extract_books(&html, &base_url);
// Print a quick summary
println!("Found {} books", books.len());
// Output full data as pretty-printed JSON
println!("{}", serde_json::to_string_pretty(&books)?);
Ok(())
}
What's happening:
- Parse the base URL once
- Fetch HTML once
- Extract all books into
Vec<Book> - Print JSON for easy inspection or export
This is a very typical Rust web scraping flow.
Fetching HTML (again, but reusable)
async fn fetch_html(url: &str) -> Result<String, reqwest::Error> {
// Build a small set of default headers
// Setting a User-Agent helps avoid basic bot blocking
let mut headers = HeaderMap::new();
headers.insert(USER_AGENT, "rust-web-scraper/0.1".parse().unwrap());
// Create a reusable HTTP client
// Clients keep connections open and are more efficient than one-off requests
let client = reqwest::Client::builder()
.default_headers(headers)
.build()?;
client
.get(url) // send a GET request
.send()
.await? // wait for the response
.error_for_status()? // fail fast on 4xx / 5xx responses
.text() // read response body as text
.await // wait for full body to be collected
}
So, what we're doing here:
- Set a
User-Agent - Fail fast on bad HTTP responses
- Return raw HTML, not parsed data
Extracting books from the page
This is where most of the logic lives.
fn extract_books(html: &str, base_url: &Url) -> Vec<Book> {
// Parse the raw HTML into a DOM structure
let document = Html::parse_document(html);
// Selector for each individual book card
let book_sel = Selector::parse("article.product_pod").unwrap();
// Selector for the title link inside a book card
let title_sel = Selector::parse("h3 a").unwrap();
// Selector for the price element
let price_sel = Selector::parse(".product_price .price_color").unwrap();
// Selector for the book cover image
let img_sel = Selector::parse(".image_container img").unwrap();
// Selector for the rating element (stored as a CSS class)
let rating_sel = Selector::parse("p.star-rating").unwrap();
// Output vector that will hold all extracted books
let mut out = Vec::new();
// we'll add a loop here next...
}
We parse once, define all selectors once, and reuse them. This keeps the loop clean and readable.
Extracting individual fields
Inside the loop, we extract fields defensively:
fn extract_books(html: &str, base_url: &Url) -> Vec<Book> {
// ... previous code ...
for book in document.select(&book_sel) {
let Some(title_a) = book.select(&title_sel).next() else {
continue;
};
let Some(price_p) = book.select(&price_sel).next() else {
continue;
};
let Some(img) = book.select(&img_sel).next() else {
continue;
};
}
}
If a required element is missing, we skip that book.
Title handling prefers the full value:
fn extract_books(html: &str, base_url: &Url) -> Vec<Book> {
// ... previous code ...
for book in document.select(&book_sel) {
// ... previous code in the loop ...
// Prefer the full title from the "title" attribute
// Fallback to visible text if the attribute is missing
let title = title_a
.value()
.attr("title")
.map(|s| s.trim().to_string())
.unwrap_or_else(|| title_a.text().collect::<String>().trim().to_string());
// Price is extracted as plain text and kept as a string for now
let price = price_p.text().collect::<String>().trim().to_string();
// Rating is encoded as a CSS class (e.g. "star-rating Three")
// We extract the meaningful part and map it to a readable value
let rating = book
.select(&rating_sel)
.next()
.and_then(|p| p.value().attr("class"))
.map(extract_rating_word)
.unwrap_or_else(|| "Unknown".to_string());
}
}
Resolving relative URLs
Links and images on this site are relative, so we normalize them:
fn extract_books(html: &str, base_url: &Url) -> Vec<Book> {
// ... previous code ...
for book in document.select(&book_sel) {
// ... previous code in the loop ...
// Resolve the relative link against the base URL
// This avoids manual string concatenation and broken URLs
let link = title_a
.value()
.attr("href")
.and_then(|href| base_url.join(href).ok())
.map(|u| u.to_string())
.unwrap_or_default();
// Resolve the relative image path the same way
// Keeps image URLs consistent and usable
let image = img
.value()
.attr("src")
.and_then(|src| base_url.join(src).ok())
.map(|u| u.to_string())
.unwrap_or_default();
}
}
So, main things to note here:
- Relative URLs are common in HTML, so links and image paths are not usable as-is.
Url::joinsafely converts them into full absolute URLs.- This avoids brittle string concatenation and broken links.
- If resolution fails, the code falls back to an empty string instead of panicking.
Final assembly
Each book becomes a struct:
fn extract_books(html: &str, base_url: &Url) -> Vec<Book> {
// ... previous code ...
for book in document.select(&book_sel) {
// ...
out.push(Book {
title,
price,
rating,
link,
image,
});
}
out
}
Great! Here's the final version of the function:
fn extract_books(html: &str, base_url: &Url) -> Vec<Book> {
// Parse the raw HTML into a DOM structure
let document = Html::parse_document(html);
// Selector for each individual book card
let book_sel = Selector::parse("article.product_pod").unwrap();
// Selector for the title link inside a book card
let title_sel = Selector::parse("h3 a").unwrap();
// Selector for the price element
let price_sel = Selector::parse(".product_price .price_color").unwrap();
// Selector for the book cover image
let img_sel = Selector::parse(".image_container img").unwrap();
// Selector for the rating element (stored as a CSS class)
let rating_sel = Selector::parse("p.star-rating").unwrap();
// Output vector that will hold all extracted books
let mut out = Vec::new();
for book in document.select(&book_sel) {
let Some(title_a) = book.select(&title_sel).next() else {
continue;
};
let Some(price_p) = book.select(&price_sel).next() else {
continue;
};
let Some(img) = book.select(&img_sel).next() else {
continue;
};
let title = title_a
.value()
.attr("title")
.map(|s| s.trim().to_string())
.unwrap_or_else(|| title_a.text().collect::<String>().trim().to_string());
// Price is extracted as plain text and kept as a string for now
let price = price_p.text().collect::<String>().trim().to_string();
// Rating is encoded as a CSS class (e.g. "star-rating Three")
// We extract the meaningful part and map it to a readable value
let rating = book
.select(&rating_sel)
.next()
.and_then(|p| p.value().attr("class"))
.map(extract_rating_word)
.unwrap_or_else(|| "Unknown".to_string());
let link = title_a
.value()
.attr("href")
.and_then(|href| base_url.join(href).ok())
.map(|u| u.to_string())
.unwrap_or_default();
// Resolve the relative image path the same way
// Keeps image URLs consistent and usable
let image = img
.value()
.attr("src")
.and_then(|src| base_url.join(src).ok())
.map(|u| u.to_string())
.unwrap_or_default();
out.push(Book {
title,
price,
rating,
link,
image,
});
}
out
}
Helper: rating extraction
fn extract_rating_word(class_attr: &str) -> String {
// Split the class attribute into individual class names
// Example input: "star-rating Three"
class_attr
.split_whitespace()
// Ignore the base "star-rating" class
// The remaining class represents the actual rating
.find(|c| *c != "star-rating")
// Fallback if the rating class is missing
.unwrap_or("Unknown")
.to_string()
}
This turns "star-rating Three" into "Three".
If you want to export CSV later, the flow stays exactly the same: extract into Vec<Book>, then write rows with the csv crate.
If you're curious how browser automation scrapes pages in a different ecosystem, this is a useful comparison: Using Watir to automate web browsers with Ruby.
Using Rust with a web scraping API
At some point, most Rust devs stop building everything from scratch. Not because Rust web scraping is weak, but because some sites are simply hard to deal with:
- pages rendered entirely with JavaScript
- unstable or hashed CSS classes
- aggressive bot protection
- large-scale scraping where IPs burn quickly
You can handle all of this yourself, but it often adds a lot of complexity. A Web Scraping API removes that overhead by handling rendering, proxies, retries, and blocking for you. Rust stays focused on what it does best: fetching, parsing, and processing data.
Tools like ScrapingBee fit naturally into this workflow. You send a URL, get back clean HTML or JSON, and keep your Rust code simple.
Example: Scraping car listings
Car marketplaces are a classic "don't do this the hard way" case.
They usually:
- load listings with JavaScript
- use hashed or auto-generated CSS classes
- change markup without warning
- block plain HTTP clients pretty aggressively
Webmotors is a good example of this kind of site.
Instead of scraping it directly, we'll do the sane thing:
- request the page through a ScrapingBee API (with JavaScript rendering enabled)
- get back fully rendered HTML
- parse it with Rust like a normal page
- extract a few basic fields
- print a quick summary
Same Rust parsing logic as before: just a smarter way to fetch the page.
Step 1: Fetch rendered HTML
Here we don't hit the site directly. We request the page through the API and ask it to behave like a real browser.
JavaScript rendering and premium proxies are enabled so we get the final, fully loaded HTML, not an empty shell.
pub async fn fetch_rendered_html_debug(
target_url: &str,
) -> Result<String, Box<dyn std::error::Error>> {
// API key is read from env so it's not hardcoded in source
let api_key = env::var("SCRAPINGBEE_API_KEY")?;
// Basic User-Agent to look like a normal client
let mut headers = HeaderMap::new();
headers.insert(USER_AGENT, "rust-web-scraper/0.1".parse()?);
// Reusable HTTP client with a long timeout
// JS rendering can take a few seconds on complex pages
let client: Client = Client::builder()
.default_headers(headers)
.timeout(Duration::from_secs(90))
.build()?;
// --- Debug request: take a screenshot ---
// This helps verify that the page actually rendered
println!("Requesting screenshot (debug_wait.png)...");
let screenshot_res = client
.get("https://app.scrapingbee.com/api/v1/")
.query(&[
("api_key", api_key.as_str()),
("url", target_url),
("render_js", "true"),
("premium_proxy", "true"),
// wait until a known element appears in the DOM
("wait_for", r#"p[data-qa="research_container"]"#),
("screenshot", "true"),
])
.send()
.await?;
println!("Screenshot status: {}", screenshot_res.status());
let screenshot_res = screenshot_res.error_for_status()?;
let bytes = screenshot_res.bytes().await?;
std::fs::write("debug_wait.png", &bytes)?;
println!("Saved screenshot to debug_wait.png");
// --- Actual HTML request ---
println!("Requesting HTML (with wait_for)...");
let res = client
.get("https://app.scrapingbee.com/api/v1/")
.query(&[
("api_key", api_key.as_str()),
("url", target_url),
("render_js", "true"),
("premium_proxy", "true"),
("wait_for", r#"p[data-qa="research_container"]"#),
])
.send()
.await?;
println!("HTML status: {}", res.status());
let res = res.error_for_status()?;
Ok(res.text().await?)
}
What's important here:
render_js=truemakes the API execute JavaScript like a real browserwait_forensures the page is actually ready before HTML is returned- Screenshots are optional, but extremely useful when debugging selectors
From Rust's point of view, this is still just an HTTP request returning HTML. Once you have this HTML, everything else works exactly like normal Rust web scraping.
Step 2: Extracting the content
Let's be honest: the markup on this car site is rough. You're dealing with hashed class names, weak semantics, and layout-driven HTML. That's very common for large marketplaces, and it's why scraping them always feels a bit defensive.
Here's a screenshot of the page generated with the script we're currently writing. It looks just like in the browser:
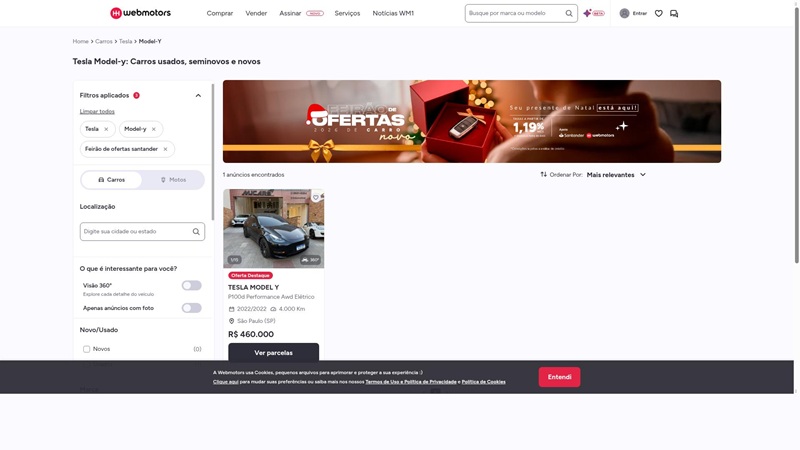
So, let's get into the dirty details: we need to find cards containing car information, extract titles, URLs, and general car information (like price, mileage, and year).
pub fn extract_car_summaries(html: &str) {
let document = Html::parse_document(html);
// Marker element to confirm the page actually rendered
let marker_sel = Selector::parse(r#"p[data-qa="research_container"]"#).unwrap();
let marker_text = document
.select(&marker_sel)
.next()
.map(|p| p.text().collect::<String>().trim().to_string())
.unwrap_or_else(|| "<not found>".to_string());
println!("Marker (research_container): {}", marker_text);
// Listing card container
// Uses partial class match because class names are hashed
let card_sel = Selector::parse(r#"div[class*="_BodyContent"]"#).unwrap();
// Core selectors inside a card
let link_sel = Selector::parse(r#"a[href*="/comprar/"]"#).unwrap();
let title_sel = Selector::parse(r#"a[href*="/comprar/"] h2"#).unwrap();
let desc_sel = Selector::parse(r#"h3[title]"#).unwrap();
// Year / mileage cells
let cell_p_sel = Selector::parse(r#"div[class*="_CellItem"] p"#).unwrap();
// Fallback selector to scan all text nodes
let p_sel = Selector::parse("p").unwrap();
let mut printed = 0;
for card in document.select(&card_sel) {
// Extract link
let link = card
.select(&link_sel)
.next()
.and_then(|a| a.value().attr("href"))
.unwrap_or("")
.to_string();
// Extract title text
let title = card
.select(&title_sel)
.next()
.map(|h2| h2.text().collect::<String>().trim().to_string())
.unwrap_or_else(|| "Unknown title".to_string());
// Skip non-listing cards
if link.is_empty() || title == "Unknown title" {
continue;
}
// Description is stored in a title attribute
let description = card
.select(&desc_sel)
.next()
.and_then(|h3| h3.value().attr("title"))
.unwrap_or("")
.trim()
.to_string();
// Year and mileage usually appear as the first two cell items
let mut year = String::new();
let mut mileage = String::new();
let cell_texts: Vec<String> = card
.select(&cell_p_sel)
.map(|p| p.text().collect::<String>().trim().to_string())
.filter(|t| !t.is_empty())
.collect();
if !cell_texts.is_empty() {
year = cell_texts[0].clone();
}
if cell_texts.len() >= 2 {
mileage = cell_texts[1].clone();
}
// City and price are easier to detect by text patterns
let all_ps: Vec<String> = card
.select(&p_sel)
.map(|p| {
p.text()
.collect::<String>()
.replace('\u{00A0}', " ")
.trim()
.to_string()
})
.filter(|t| !t.is_empty())
.collect();
let price = all_ps
.iter()
.find(|t| t.contains("R$"))
.cloned()
.unwrap_or_default();
// Very loose heuristic, but works for this layout
let location = all_ps
.iter()
.find(|t| t.contains('(') && t.contains(')'))
.cloned()
.unwrap_or_default();
println!("---");
println!("Title: {}", title);
if !description.is_empty() {
println!("Desc: {}", description);
}
println!("Link: {}", link);
if !year.is_empty() {
println!("Year: {}", year);
}
if !mileage.is_empty() {
println!("Mileage: {}", mileage);
}
if !location.is_empty() {
println!("Location: {}", location);
}
if !price.is_empty() {
println!("Price: {}", price);
}
printed += 1;
if printed >= 5 {
break;
}
}
println!("Printed {} cards", printed);
}
A few important takeaways:
- Modern marketplaces often don't have clean, semantic HTML
- Partial class matching and attribute-based selectors are sometimes the only option
- Text-based heuristics (
contains("R$"), parentheses, etc.) are common in practice - Marker elements help confirm rendering worked before parsing
- This code is intentionally defensive as real pages break ofte
The Rust part is the easy bit. The hard part is surviving the markup.
Step 3: Wiring it together
This is the final glue code. Nothing fancy — it just connects all the pieces and makes the scrape run end to end.
use dotenvy::dotenv;
use reqwest::header::{HeaderMap, USER_AGENT};
use reqwest::Client;
use scraper::{Html, Selector};
use std::env;
use std::time::Duration;
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
// Load environment variables from .env (if present)
dotenv().ok();
// Target page (complex, JS-heavy marketplace)
let url = "https://www.webmotors.com.br/ofertas/feiroes/feiraodeofertassantanderrr/carros/estoque/tesla/model-y?feirao=Feir%C3%A3o%20de%20Ofertas%20Santander&tipoveiculo=carros&marca1=tesla&modelo1=model-y&page=1";
println!("Fetching rendered HTML...");
let html = fetch_rendered_html_debug(url).await?;
println!("HTML length: {}", html.len());
// Save HTML locally for debugging selectors
std::fs::write("debug.html", &html)?;
println!("Saved HTML to debug.html");
// Parse and print a short summary
extract_car_summaries(&html);
Ok(())
}
What's going on here:
.envis loaded so secrets stay out of source code- The API key is read once and reused by the fetch function
- Fully rendered HTML is fetched instead of fighting JavaScript
- The HTML is saved locally to make selector debugging easier
- Parsing and output stay fully in Rust
If you follow this setup, add the dependency below to your Cargo.toml:
dotenvy = "0.15"
Try ScrapingBee with Rust
If you want to skip proxy headaches, JavaScript quirks, and random blocks, this is the easy path.
But with ScrapingBee you get:
- JavaScript rendering — get the fully rendered DOM after all client-side scripts have run, just like in a real browser
- Premium proxy network — automatic IP rotation and geo-targeting to avoid blocks and throttling
- Built-in anti-bot handling — retries, fingerprinting, and common bot defenses are handled automatically
- Smart waiting & page readiness — wait for specific elements to appear before HTML is returned
- AI Web Scraping API — describe the data you want in plain language and get structured results without writing or maintaining brittle selectors
- Cleaner Rust code — your Rust scraper focuses on parsing and data processing, not browser automation or proxy management
You get 1,000 free credits right away, which is more than enough to test real-world pages and run all the examples from this guide.
If you're serious about Rust web scraping beyond toy sites, this setup saves a lot of time and frustration. Start scraping today!
Conclusion
Rust web scraping is a solid choice when you want speed, safety, and predictable behavior. For simple sites, a small stack with reqwest, scraper, and tokio goes a long way. You fetch HTML, select elements, and extract data in a clean, testable way. Once you understand that flow, most static pages feel straightforward.
For modern, JavaScript-heavy sites, the game changes. Instead of fighting browser logic and anti-bot systems, it often makes sense to offload rendering and blocking to a scraping API, then keep Rust focused on parsing and data processing. The code stays simpler, and the results are more reliable.
The main takeaway is this: start simple, scale deliberately, and don't be afraid to mix tools. Rust handles the data side extremely well, and with the right setup, it works just as comfortably on real-world sites as it does on demos. From here, you can expand into pagination, concurrency, data storage, and automation, but the core ideas you've seen here will stay the same.
Before you go, check out these related reads:
- Web Scraping in C++ with libxml2 and libcurl
- How to Scrape With Camoufox to Bypass Antibot Technology
Frequently asked questions (FAQs)
Is Rust good for web scraping?
Yes. Rust is a strong choice for web scraping because it's fast, memory-safe, and handles concurrency well. It's especially good when you need reliable scrapers that run long-term or at scale. Compared to older stacks like Web Scraping With Visual Basic, Rust offers far better performance and safety.
Can Rust scrape JavaScript pages?
Not directly. Rust HTTP clients like reqwest do not execute JavaScript, so JS-rendered content won't appear in the HTML response. To scrape those pages, you either target the underlying JSON APIs, use a headless browser, or fetch rendered HTML via a Web Scraping API like ScrapingBee.
How do I parse HTML in Rust?
HTML is usually parsed with the scraper crate. You load the page into a DOM using Html::parse_document, then query elements with CSS selectors. The flow is simple: fetch HTML, select elements, extract text or attributes, and convert the data into Rust types.
What is the difference between scraping and crawling?
Scraping focuses on extracting specific data from pages, like titles or prices. Crawling is about discovering and visiting many pages by following links. In practice, scraping is about data extraction, while crawling is about navigation and coverage. Many projects use both together.


