In this tutorial we're diving into the world of web scraping with Ruby. We'll explore powerful Gems like Faraday for HTTP requests, Nokogiri for parsing HTML, and browser automation with Selenium and Capybara. Along the way, we'll scrape real websites with some example scripts, handle dynamic Javascript content and even run headless browsers in parallel.
By the end of this tutorial, you'll be equipped with the knowledge and practical patterns needed to start scraping data from websites — whether for fun, research, or building something cool.
Ruby Web Scraping Technology
If you're new to Web Scraping with Ruby, here's a list of some of the most notable Gems that might be of use to you in your data extraction journey:
- faraday – Adapter-based HTTP client with middleware support. Great for building API clients.
- Capybara - Lets you control a real browser (like Chrome) using Selenium.
- httparty – Makes HTTP feel like a friendly Ruby object. Great for quick and readable requests.
- spidr – Flexible crawler that can work across domains or go deep on one.
- nokogiri – The gold standard. CSS selectors, XPath, all the good stuff.
- loofah – Built on Nokogiri, focused on sanitizing and cleaning HTML.
- watir – Built on Selenium. Super clean API for browser automation.
- mechanize – Classic tool for navigating and interacting with pages. Knows about forms, links, cookies, etc.
- metainspector – Pulls titles, descriptions, images, links, etc.
- addressable – Drop-in replacement for URI with full RFC compliance and template support.
- parallel – Easy multithreading/multiprocessing. Super practical.
- oj – Optimized JSON parser/generator, crazy fast.
- selenium – Drives real browsers. Chrome, Firefox, you name it.
Now on with the Ruby tutorial.
Prerequisites
Expected knowledge and environment
Before we dive in, here's what you'll need to follow along:
- Basic knowledge of Ruby (you should know how to run scripts and install gems)
- Ruby 3.x installed on your system
- Any code editor (VS Code, Sublime, whatever makes you happy)
- A terminal (bash, zsh, fish, the usual suspects)
We're keeping it simple — no Rails, no heavy setup. Just clean and nice Ruby.
Setting up your Ruby scraping project
Let's create a new Ruby project folder real quick. Open your terminal and run:
mkdir ruby_scraper
cd ruby_scraper
bundle init
This will create a Gemfile for you. Now let's create the main Ruby script:
touch scraper.rb
You should now have:
ruby_scraper/
├── Gemfile
└── scraper.rb
We'll start adding gems and writing code in the next sections.
Making HTTP requests with Ruby
There are a lot of ways to make HTTP requests in Ruby. Seriously — the Ruby ecosystem has more HTTP clients than I have unread emails. Well, in fact strong community is a big advantage of the language. You've got Net::HTTP, HTTP.rb, HTTParty, Typhoeus, RestClient, and probably a few options I've blocked from memory.
But today we'll be utilizing Faraday. It's flexible, pluggable, and easy to use. I like Faraday as some people like their morning coffee — reliable, configurable, and slightly addictive. No, actually I like it much more. Anyway...
Getting started with Faraday
First, add Faraday to your Gemfile. We'll go with version 2:
gem 'faraday', '~> 2.0'
Then install it:
bundle install
Let's make our first HTTP GET request to a sample web page. Open up scraper.rb and try this:
require 'faraday'
response = Faraday.get('https://example.com')
puts "Status: #{response.status}"
puts "Headers: #{response.headers.inspect}"
puts "Body: #{response.body[0..200]}..." # Show only the first 200 chars
In this example we're reading response status code, headers, and body.
Run it with:
bundle exec ruby scraper.rb
You should see something like:
Status: 200
Headers: { ... }
Body: <!doctype html><html><head>...
Congrats — you just scraped your first page. You're basically a hacker now!
Customizing requests with Faraday
Faraday's not just for basic GET requests — it's highly customizable. You can send JSON payloads, tweak headers, use middleware, and yeah, even handle gzip like a pro scraper.
Let's say we want to send JSON and support gzip compression in our requests. First, we'll need to add an extra gem (to boast a bit, I'm currently maintaining this solution):
gem 'faraday-gzip', '~> 3'
And install it:
bundle install
Now update your script like this:
require 'faraday'
require 'faraday/gzip'
require 'json'
conn = Faraday.new(
url: 'https://jsonplaceholder.typicode.com',
headers: {
'Content-Type' => 'application/json',
'User-Agent' => 'RubyScraper/1.0'
}
) do |f|
f.request :gzip
# You can also add other middleware here like logging, retries, etc.
end
# GET request
res = conn.get('/posts/1')
puts JSON.pretty_generate(JSON.parse(res.body))
# POST request
res = conn.post('/posts') do |req|
req.body = JSON.dump({ title: 'Hello', body: 'From Ruby', userId: 1 })
end
puts "Created post ID: #{JSON.parse(res.body)['id']}"
Here's what's going on in that code:
- We load the necessary libraries:
faradayfor HTTP,faraday/gzipto enable gzip support, andjsonfor encoding/decoding JSON data. - We create a
Faradayconnection object (conn) with a base URL and default headers. The headers tell the server we're sending and expecting JSON, and theUser-Agentis just something custom (you can put anything there). - Inside the block passed to
Faraday.new, we configure middleware. Thef.request :gzipline tells Faraday to sendAccept-Encoding: gzipand decompress gzipped responses automatically. - After that, we use
conn.getto send a GET request and pretty-print the JSON response. - Then we use
conn.postto send a JSON payload. The body is dumped usingJSON.dump, and we pass it directly to the request.
That setup is quite good for starters. If you need more power, you can plug in retries, logging, error handling, or even use other adapters.
Learn how to use proxies with Ruby and Faraday in our blog post.
Parsing HTML with Nokogiri
Once we've got the HTML, we need a way to dig into it and pull out the juicy bits — that's where Nokogiri comes in. It's a very popular HTML and XML parser in Ruby. Super fast, works with both XPath and CSS selectors, and has been around forever (seriously, I remember using it like 15 years ago).
Installing Nokogiri
Add this to your Gemfile:
gem 'nokogiri', '~> 1.18'
And don't forget to run bundle install. Nokogiri comes with native extensions, so don't be surprised if it takes some time to compile stuff.
Parsing a sample web page with Ruby and Nokogiri
As the first demo, we're going to reuse our Faraday connection from earlier and parse the response from example.com.
Here's what that page looks like (simplified):
<body>
<div>
<h1>Example Domain</h1>
<p>This domain is for use in illustrative examples in documents...</p>
<p><a href="https://www.iana.org/domains/example">More information...</a></p>
</div>
</body>
Now let's fetch and parse it:
# frozen_string_literal: true
require 'faraday'
require 'faraday/gzip'
require 'nokogiri'
conn = Faraday.new(
url: 'https://jsonplaceholder.typicode.com',
headers: {
'Content-Type' => 'application/json',
'User-Agent' => 'RubyScraper/1.0'
}
) do |f|
f.request :gzip
end
res = conn.get('https://example.com')
doc = Nokogiri::HTML(res.body)
# Grab the <h1> text
puts "Title: #{doc.at('h1')&.text}"
# Grab the first paragraph
puts "Intro: #{doc.at('p')&.text}"
# Grab the link text and href
link = doc.at('a')
puts "Link text: #{link&.text}"
puts "Link href: #{link&.[]('href')}"
What's going on here?
Nokogiri::HTML(res.body)takes the raw HTML and gives us a parsed document object.doc.at('h1')finds the first<h1>tag (or returnsnilif it's not there).atis shorthand for "find one".&.textsafely grabs the text content. The&.avoids errors if the tag isn't found.doc.at('p')works the same, pulling out the paragraph.doc.at('a')finds the first<a>tag, andlink['href']gives us thehrefattribute.
💡 If you'd like to find out more about the DOM and XPath, we have a helpful article on that: Practical XPath for Web Scraping
Scraping real-world pages with Ruby and Nokogiri: Rotten Tomatoes example
Alright, time to scrape something real. Let's hit the front page of Rotten Tomatoes and pull out a list of movies currently playing in theaters.
Step 1: Inspect the page
Before we write any code, we need to understand how the page is structured. Open rottentomatoes.com in your browser, right-click somewhere, and click Inspect. That opens the browser's DevTools, which lets you see the actual HTML behind the scenes.
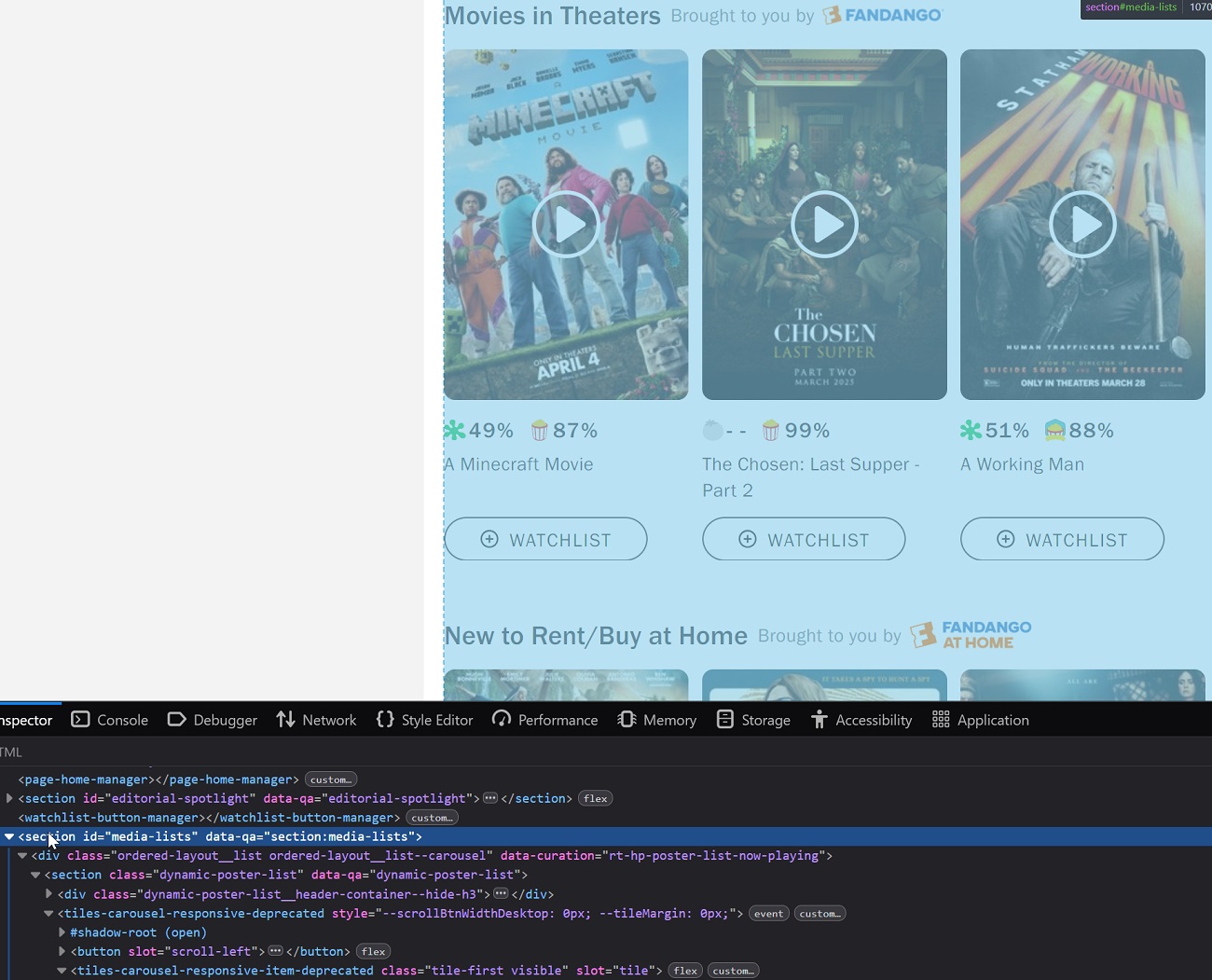
Here's what I was able to find after doing some detective work:
- There's a top-level element with
id="media-lists", which wraps several horizontal scrollers with movie info. - The first scroller is the one we care about — it shows movies that are in theaters now.
- That scroller lives inside a
<section>with classdynamic-poster-list. - Each movie is inside a custom element called
<tile-dynamic>. That's the main wrapper for a single movie card.
Inside each <tile-dynamic> I found:
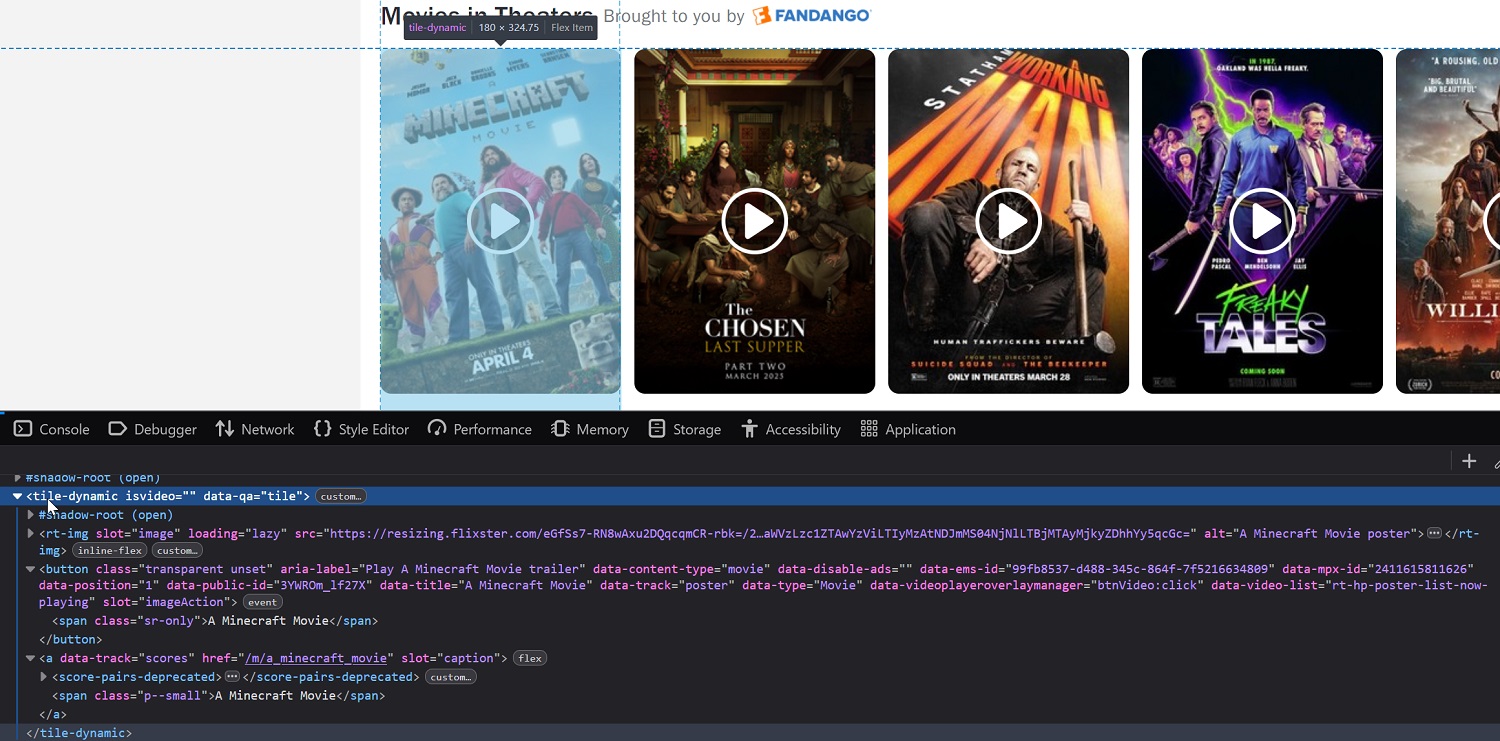
- A
<rt-img>element — that's where the movie poster is. - A
<button>that contains a<span>— this holds the movie title. - An
<a>withdata-track="scores"which contains: - A
<rt-text slot="criticsScore">— this shows the critics score. - A
<rt-text slot="audienceScore">— this shows the audience score.
Step 2: Write the scraper
Here's a script that grabs a few movies from that first scroller and prints their poster URL, title, and scores:
# frozen_string_literal: true
require 'faraday'
require 'faraday/gzip'
require 'nokogiri'
conn = Faraday.new(
url: 'https://www.rottentomatoes.com',
headers: {
'User-Agent' => 'RubyScraper/1.0'
}
) do |f|
f.request :gzip
end
res = conn.get('/')
doc = Nokogiri::HTML(res.body)
# Find the first 'dynamic-poster-list' section
poster_list = doc.at_css('#media-lists .dynamic-poster-list')
# Grab 5 movie elements
movies = poster_list.css('tile-dynamic').first(5)
movies.each_with_index do |movie, index|
puts "--- Movie #{index + 1} ---"
# Poster image
img = movie.at_css("rt-img")&.attribute("src")&.value
puts "Poster: #{img}" if img
# Movie title
title = movie.at_css('button span')&.text
puts "Title: #{title}"
# Critics score
critics_score = movie.at_css("rt-text[slot='criticsScore']")&.text&.strip
puts "Critics Score: #{critics_score}" if critics_score && !critics_score.empty?
# Audience score
audience_score = movie.at_css("rt-text[slot='audienceScore']")&.text&.strip
puts "Audience Score: #{audience_score}" if audience_score && !audience_score.empty?
puts '==='
end
How does it work?
- The script finds the first
dynamic-poster-listunder#media-lists— that's the "In Theaters" section. - It grabs the first five
<tile-dynamic>elements, each representing a movie. - Inside each movie, we extract the poster image, title, and both score slots (if available).
🤖 Need help finding all the URLs on a website so you can scrape them? Check out our expert-level guide on How to find all URLs on a domain’s website (multiple methods)
Dealing with anti-scraping
Here's the thing — websites don't like being scraped. Some will block or throttle you, especially if you're hitting them too often or from a known IP. They might load content with JavaScript, use captchas, or serve different HTML to bots.
To make your life easier, you can use out scraper API. It gives you premium proxies, proxy rotation, automatic retries, JavaScript rendering, and even AI-powered scraping if you're feeling spicy.
🤖 Having trouble scraping websites that end up blocking you? Bypass anti-web scraping technology such as Cloudflare with our guide on Web Scraping without getting blocked
Getting started with ScrapingBee
- Sign up here for 1,000 free credits
- Go to your profile and grab your API key
- Instead of requesting the site directly, you send a request to ScrapingBee's API with the target URL as a parameter
Updating the scraping code
Here's how to plug it into our existing code:
require "faraday"
require "faraday/gzip"
require "nokogiri"
API_KEY = 'YOUR_API_KEY'
target_url = 'https://www.rottentomatoes.com'
scrapingbee_url = "https://app.scrapingbee.com/api/v1/?api_key=#{API_KEY}&url=#{target_url}"
conn = Faraday.new(headers: { 'User-Agent' => 'RubyScraper/1.0' }) do |f|
f.request :gzip
end
res = conn.get(scrapingbee_url)
doc = Nokogiri::HTML(res.body)
# ... work with your Nokogiri document as before ...
The rest of your scraping logic stays exactly the same. Learn more about other ScrapingBee features in the official documentation.
Taking it to the next level: Retries and saving to CSV
So far, our scraper is functional — but let's level it up a bit.
Adding retries
Even with a premium service like ScrapingBee, network hiccups or occasional API flakiness can still happen. Thus, let's introduce retry logic using the faraday-retry gem. This middleware helps us deal with temporary failures — things like timeouts, dropped connections, or 500 errors.
First, add it to your Gemfile:
gem 'faraday-retry', '~> 2.0'
And run bundle install.
Now let's define retry options and plug the middleware into our Faraday setup:
require 'faraday'
require 'faraday/gzip'
require "faraday/retry"
require 'nokogiri'
API_KEY = 'YOUR_API_KEY'
target_url = 'https://www.rottentomatoes.com'
scrapingbee_url = "https://app.scrapingbee.com/api/v1/?api_key=#{API_KEY}&url=#{target_url}"
retry_options = {
max: 2,
interval: 0.05,
interval_randomness: 0.5,
backoff_factor: 2
}
conn = Faraday.new(headers: { 'User-Agent' => 'RubyScraper/1.0' }) do |f|
f.request :retry, retry_options
f.request :gzip
end
res = conn.get(scrapingbee_url)
doc = Nokogiri::HTML(res.body)
Here's what the retry options mean:
max: how many times to retry (not counting the first attempt)interval: how long to wait before the first retryinterval_randomness: adds some randomness to the delay (helps avoid thundering herd)backoff_factor: increases the delay between each retry (exponential backoff)
Saving movie data to a CSV file
Instead of printing the scraped data to the screen, let's store it in a CSV file. That way you can keep the results, analyze them later, or feed them into another system.
The CSV gem is not part of the default gems starting from Ruby 3.4 therefore we need to add it to the Gemfile:
gem 'csv', '~> 3.3'
Run bundle install.
We'll extract the same pieces of info: title, poster URL, critics score, and audience score.
require 'csv'
# ... other requires ...
# Making request, creating Nokogiri document...
poster_list = doc.at_css('#media-lists .dynamic-poster-list')
movies = poster_list.css('tile-dynamic').first(5)
CSV.open('movies.csv', 'w', write_headers: true,
headers: ['Title', 'Poster URL', 'Critics Score', 'Audience Score']) do |csv|
movies.each do |movie|
title = movie.at_css('button span')&.text&.strip
poster = movie.at_css("rt-img")&.attribute("src")&.value
critics_score = movie.at_css("rt-text[slot='criticsScore']")&.text&.strip
audience_score = movie.at_css("rt-text[slot='audienceScore']")&.text&.strip
csv << [title, poster, critics_score, audience_score]
end
end
puts 'Scraped movie data saved to movies.csv'
This version is more fault-tolerant and actually produces a usable file. You can open movies.csv in Excel, Numbers, Google Sheets, or wherever you want.
When Nokogiri isn't enough: Enter Selenium and Capybara
So far we've been working with static HTML — stuff that's already present in the page source when the request hits. But some sites don't play nice. They load content dynamically with JavaScript, lazy-load elements, or hide data behind clicks and scrolling.
That's where tools like Selenium and Capybara come in. They let you drive a real browser — load pages, wait for JS to execute, click buttons, fill out forms, all that good stuff.
What's the difference?
- Selenium is the engine — it automates a real browser (like Chrome or Firefox) and gives you low-level control over it.
- Capybara is a wrapper that makes browser automation pleasant. It gives you a clean, Ruby-flavored DSL that reads like English. Originally made for feature testing, but works great for scraping too.
Installing the gems
Add these to your Gemfile:
gem 'selenium-webdriver', '~> 4.31'
gem 'capybara', '~> 3.40'
And run bundle install.
To use Selenium or Capybara, you need a real browser installed — either Chrome or Firefox — along with a matching driver that lets Selenium control it.
Here's what you need depending on your setup:
macOS
For Chrome:
brew install --cask google-chrome
brew install chromedriver
For Firefox:
brew install --cask firefox
brew install geckodriver
Make sure the drivers (chromedriver or geckodriver) are available in your system's PATH.
Windows
Install the browser:
Install the driver:
After downloading, put the driver .exe somewhere safe and add the folder it's in to your System PATH so Ruby can find it.
Opening movie details page with Selenium and Capybara
Let's level up our Rotten Tomatoes scraper and simulate what a real user would do: click on a movie and watch the trailer. Nokogiri can't do that — but Capybara with Selenium absolutely can.
We'll open the homepage, find the first movie, click its link, wait for the movie page to load, and then click the trailer button. This is a great example of how to scrape JavaScript-driven pages with interaction, something static scraping just can't do.
Step-by-step
- Load
rottentomatoes.com - Find the first
<tile-dynamic>element inside the "In Theaters" section - Inside it, grab the
<a>withdata-track="scores"— that's the movie link - Click it to open the detail page
- On the detail page, wait for
<media-hero> - Inside that, find a
<rt-button>and click it to play the trailer
Let's write the code:
require 'capybara'
require 'capybara/dsl'
Capybara.default_driver = :selenium
# No need to run any local servers (initially Capybara was designed to test local apps)
Capybara.run_server = false
Capybara.default_max_wait_time = 10
include Capybara::DSL
# Visit homepage
visit 'https://www.rottentomatoes.com'
# Wait until the movie scroller is loaded
within '#media-lists' do
movie_link = first("tile-dynamic a[data-track='scores']")
movie_url = movie_link[:href]
puts "Navigating to movie: #{movie_url}"
movie_link.click
end
# Now on the movie page
# Wait for the main hero section to load
if page.has_css?("media-hero rt-button[slot='trailerCta']", wait: 10)
puts 'Found trailer button, clicking it...'
find("media-hero rt-button[slot='trailerCta']").click
else
puts 'No trailer button found.'
end
# Optional: wait a bit to see the trailer open
sleep 3
# Close the session
Capybara.reset_sessions!
- We use within "#media-lists" to scope our search to that section (avoids false matches).
- Trailer buttons may not be present on every movie page. We use has_css? to check and avoid crashes.
- You can add headless: true later if you want this to run without showing the browser window.
Handling the cookie popup
Yeah, of course there's a cookie popup... Rotten Tomatoes sometimes shows a GDPR-style cookie consent overlay. If it appears, we need to dismiss it before we can interact with the page. The popup lives inside a div with id="onetrust-consent-sdk", and the "Reject All" button has id="onetrust-reject-all-handler".
Let's update our code to handle that first, before we move on to clicking movies:
visit 'https://www.rottentomatoes.com'
if page.has_css?('#onetrust-consent-sdk', wait: 2) && page.has_button?('Reject All', id: 'onetrust-reject-all-handler')
puts 'Cookie popup detected, rejecting...'
click_button('Reject All')
end
# ... Perform other actions ...
Creating page screenshots
You can easily create page screenshots with Capybara and Selenium. To achieve that, simply write:
page.save_screenshot("trailer_page.png")
This way, the currently opened web page will be saved as a PNG image. Nice!
Running Selenium in headless mode
By default, when you run Capybara with Selenium, it opens a real browser window. That's great while you're developing and want to see what's going on — but for automation, background jobs, or running things on a server, it's kind of a pain.
That's where headless mode comes in. It runs the browser without showing any UI — completely silent, but still fully functional.
Why use headless mode?
- Keeps things quiet when running in the background
- Works great in CI pipelines or remote servers
- Slightly faster since it skips rendering the UI
- You code like a true wizard
Enabling headless mode
Here's how to set it up for Firefox:
# frozen_string_literal: true
require 'selenium-webdriver'
require 'capybara'
require 'capybara/dsl'
include Capybara::DSL
Capybara.register_driver :selenium_headless do |app|
options = Selenium::WebDriver::Firefox::Options.new
options.add_argument('-headless')
Capybara::Selenium::Driver.new(app, browser: :firefox, options: options)
end
Capybara.default_driver = :selenium_headless
Capybara.run_server = false
Capybara.default_max_wait_time = 10
visit 'https://www.rottentomatoes.com'
within '#media-lists' do
movie_link = first("tile-dynamic a[data-track='scores']")
movie_url = movie_link[:href]
page.save_screenshot('page.png')
puts "Navigating to movie: #{movie_url}"
movie_link.click
end
Capybara.reset_sessions!
From here, your script runs exactly the same — just no browser window pops up. You can even take screenshots in headless mode if you need to debug what happened.
Building a real scraper with headless Selenium and Capybara: Microphone hunting
Alright, let's stop playing around and build something real. We're going to write a full Ruby script that:
- Opens https://www.microcenter.com
- Asks the user what microphone they're looking for
- Enters the search term into the site's search bar
- Waits for results to load
- Collects search results and browser each product separately in parallel
- Makes product screenshots
- Finds product details and store all the information in a CSV file
Initial configuration and page load
Let's start by setting up the project and laying out the class. We'll call it MicroScraper — because we're searching for microphones, and also because this is a micro scraper. Get it, huh? Tiny but mighty.
# frozen_string_literal: true
require 'csv'
require 'capybara'
require 'capybara/dsl'
require 'selenium-webdriver'
require 'fileutils'
require 'logger'
class MicroScraper
include Capybara::DSL
# The website to scrape
ROOT_URL = 'https://www.microcenter.com'
# How many products we want to find
PRODUCTS_LIMIT = 5
# Number of concurrent requests (don't go crazy here!)
CONCURRENCY = 3
# Where to store screenshots for debugging
SCREENSHOT_DIR = 'screens'
# Output file with all the information
OUTPUT_CSV = 'products.csv'
def initialize
@logger = Logger.new($stdout)
@logger.level = Logger::INFO
setup_capybara
end
def run
query = ask_for_search_term
@logger.info "Searching for '#{query}' ..."
end
private
def ask_for_search_term
query = nil
loop do
print 'Enter Micro Center search term: '
query = $stdin.gets&.chomp&.strip
break unless query.nil? || query.empty?
@logger.warn 'Search term cannot be empty.'
end
query
end
def setup_capybara
Capybara.register_driver :selenium_headless_firefox do |app|
options = Selenium::WebDriver::Firefox::Options.new
options.add_argument('-headless')
Capybara::Selenium::Driver.new(app, browser: :firefox, options: options)
end
Capybara.default_driver = :selenium_headless_firefox
Capybara.run_server = false
Capybara.default_max_wait_time = 10
FileUtils.mkdir_p(SCREENSHOT_DIR)
end
end
# Kick it off
scraper = MicroScraper.new
scraper.run
We start by setting up our environment. This includes:
- Capybara with a headless Firefox browser so we can automate page interaction without opening a real window.
- A logger to print clean status updates and warnings.
- Some constants to define limits, output paths, and concurrency.
- A prompt that asks the user what they want to search for — and keeps asking if the input is empty.
We also make sure the screenshot folder exists before anything starts running.
Searching for stuff
Let's get our scraper to actually perform the search.
On the Micro Center homepage, the search input lives inside a <div> with id="standardSearch", and the input itself has id="search-query". It's part of a form with id="searchForm", so we can click on the "search" button to submit it.
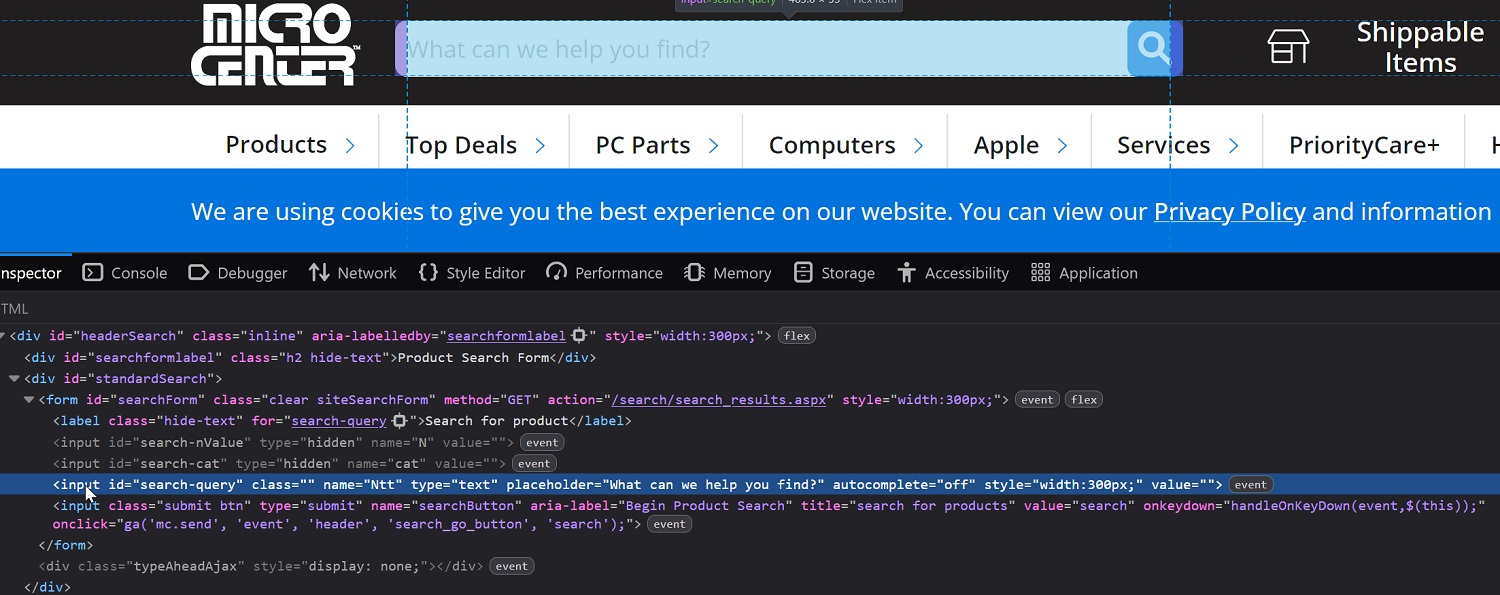
Here's how we do it:
# ...
class MicroScraper
def run
query = ask_for_search_term
go_to_root
@logger.info "Searching for '#{query}' ..."
perform_search_with(query)
Capybara.reset_sessions!
end
private
def go_to_root
visit ROOT_URL
@logger.info "Opened Micro Center homepage at #{ROOT_URL}"
end
def perform_search_with(query)
within '#standardSearch form#searchForm' do
input = find('input#search-query', visible: true)
input.click
input.set(query)
find("input[type='submit'][name='searchButton']").click
end
# Wait for the result bar to appear
unless page.has_css?('main#mainContent .searchInfoBar', wait: 10)
@logger.error 'Timed out waiting for search results. Exiting.'
exit(1)
end
result_info = find('main#mainContent .searchInfoBar').text
@logger.info "Search info: #{result_info}"
page.save_screenshot(File.join(SCREENSHOT_DIR, 'search_results.png'))
end
end
I've noticed that the search form has some JavaScript magic attached to it, so unless we explicitly click on the input field first, it won’t accept the search term. That’s why we call input.click before setting the query. Weird quirk — but issues like this are pretty common when writing scrapers.
After submitting the search, we wait for the .searchInfoBar element to appear, which shows how many results were found. Then we save a screenshot of the page for debugging purposes.
Collecting search results
The next step is to grab a few search results (defined by PRODUCTS_LIMIT constant), and collect the links to the corresponding products:
class MicroScraper
def run
query = ask_for_search_term
go_to_root
@logger.info "Searching for '#{query}' ..."
perform_search_with(query)
product_links = collect_product_links
if product_links.empty?
@logger.error 'No product links found. Exiting.'
return
end
@logger.info "Collected #{product_links.size} product links:"
product_links.each { |link| @logger.info " - #{link}" }
results = scrape_product_pages(product_links)
Capybara.reset_sessions!
end
private
def collect_product_links
links = []
if page.has_css?('article#productGrid ul', wait: 5)
items = all('article#productGrid ul li.product_wrapper').first(PRODUCTS_LIMIT)
links = items.map do |li|
relative = li.find('a.productClickItemV2', match: :first)[:href]
URI.join(ROOT_URL, relative).to_s
rescue Capybara::ElementNotFound
@logger.warn 'Product link not found for an item. Skipping.'
nil
end.compact
else
@logger.error 'No product grid found on the search results page.'
end
links
end
end
Nothing too fancy, we just find list items under the #productGrid and fetch links defined by the a.productClickItemV2 tags. Here's how it looks in the markup:
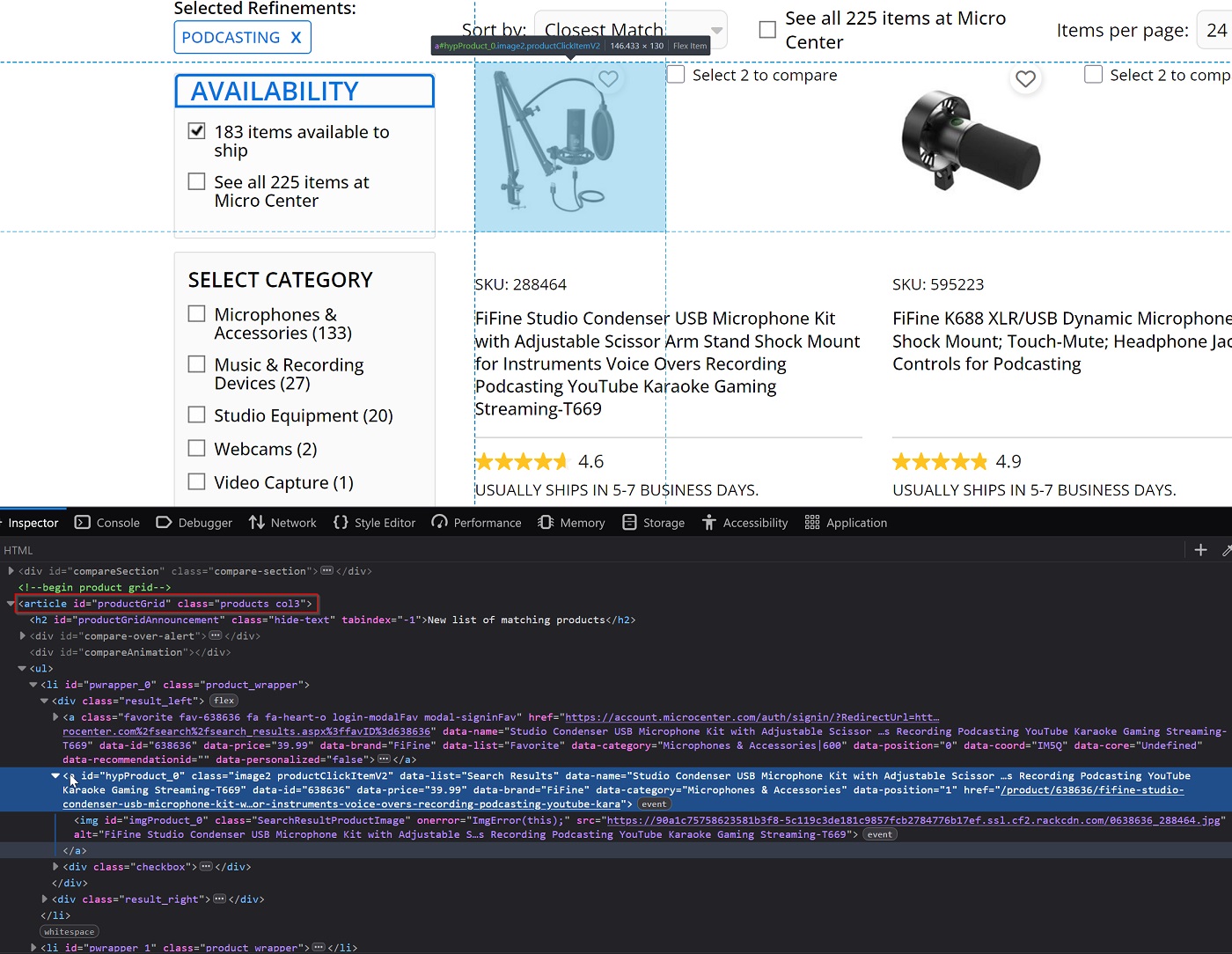
Scraping products in parallel
And now comes the big one: parallel processing of the found products. To achieve this, we'll need to create multiple headless browsers in different threads, open the detected links inside, and then wait for all threads to complete before moving forward.
First, let's check the product page markup:
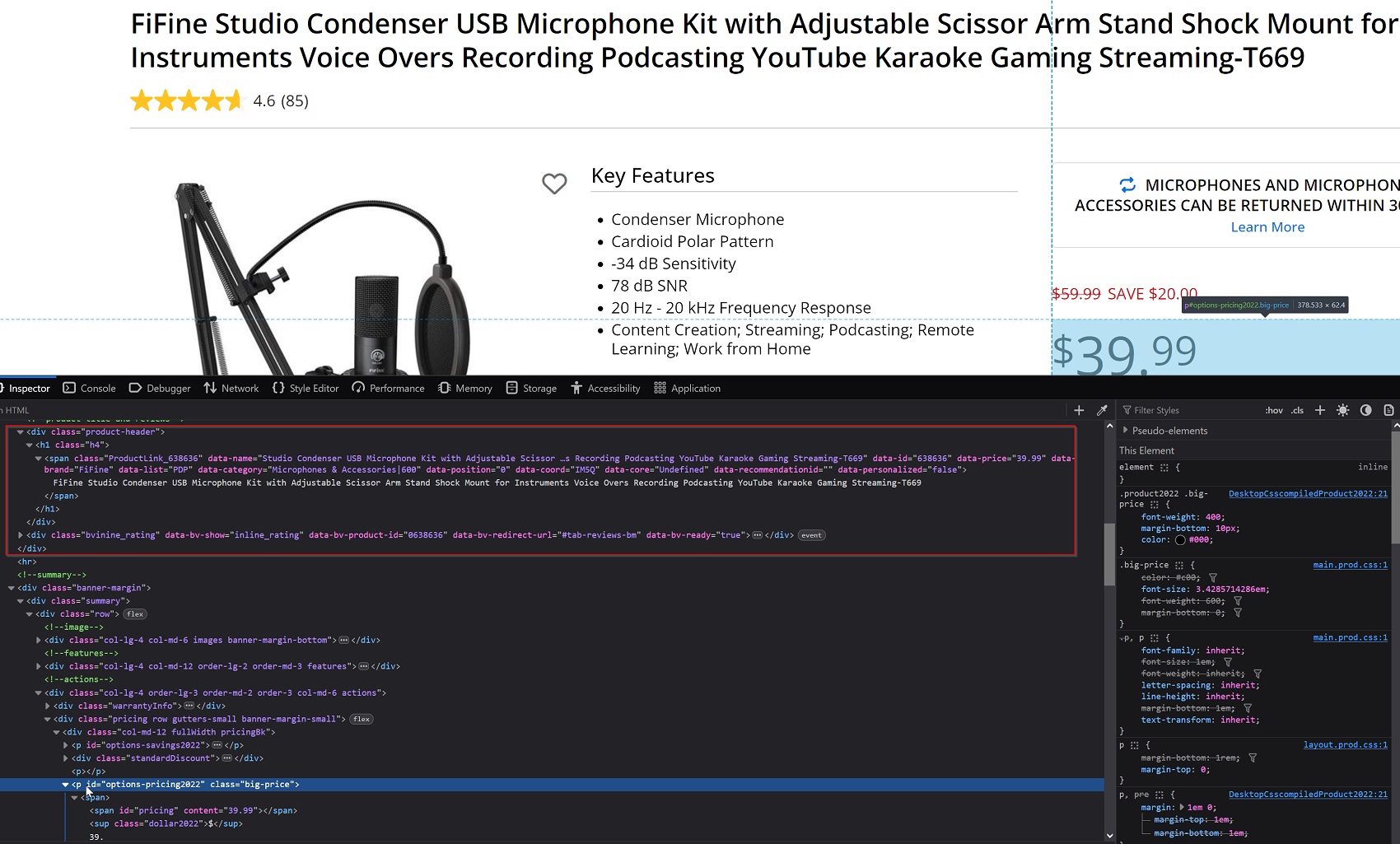
Here's the relevant code:
class MicroScraper
def run
query = ask_for_search_term
go_to_root
@logger.info "Searching for '#{query}' ..."
perform_search_with(query)
product_links = collect_product_links
if product_links.empty?
@logger.error 'No product links found. Exiting.'
return
end
@logger.info "Collected #{product_links.size} product links:"
product_links.each { |link| @logger.info " - #{link}" }
results = scrape_product_pages(product_links)
Capybara.reset_sessions!
end
def scrape_product_pages(links)
# Use thread-safe queues for both work and results
product_queue = Queue.new
links.each_with_index { |url, index| product_queue << [url, index] }
results_queue = Queue.new
threads = Array.new(CONCURRENCY) do
Thread.new do
loop do
pair = begin
product_queue.pop(true)
rescue StandardError
nil
end
break unless pair
url, index = pair
session = Capybara::Session.new(:selenium_headless_firefox)
begin
@logger.info "Thread #{Thread.current.object_id}: Visiting product #{index + 1}: #{url}"
session.visit(url)
if session.has_css?('div.product-header h1', wait: 10)
title = session.find('div.product-header h1').text.strip
price = begin
session.find('p.big-price', match: :first).text.strip
rescue StandardError
'N/A'
end
@logger.info "Thread #{Thread.current.object_id}: Loaded: #{title} – #{price}"
screenshot_file = File.join(SCREENSHOT_DIR, "product_#{index + 1}.png")
session.save_screenshot(screenshot_file)
results_queue << {
index: index + 1,
url: url,
title: title,
price: price
}
else
@logger.warn "Thread #{Thread.current.object_id}: Failed to find product title on page #{index + 1}"
end
rescue StandardError => e
@logger.error "Thread #{Thread.current.object_id}: Error visiting #{url}: #{e.message}"
ensure
session.quit
end
end
end
end
threads.each(&:join)
# Convert results_queue to an array and sort by original index
results = []
results << results_queue.pop until results_queue.empty?
results.sort_by { |r| r[:index] }
end
end
- We use a thread-safe queue to feed product URLs into multiple threads.
- Each thread creates its own Capybara session, visits the product page, and scrapes the title and price.
- A screenshot of each product page is saved with an index-based filename.
- Scraped data is pushed into a result queue, which we collect and sort after all threads finish.
Note that we limit the number of parallel requests with the CONCURRENCY constant. This is actually a very good practice because if you spam the server with too many simultaneous requests, you might be blocked.
Saving results to CSV
The last step is to save all the results in a CSV file. This is easy:
class MicroScraper
def run
query = ask_for_search_term
go_to_root
@logger.info "Searching for '#{query}' ..."
perform_search_with(query)
product_links = collect_product_links
if product_links.empty?
@logger.error 'No product links found. Exiting.'
return
end
@logger.info "Collected #{product_links.size} product links:"
product_links.each { |link| @logger.info " - #{link}" }
results = scrape_product_pages(product_links)
save_as_csv(results)
Capybara.reset_sessions!
@logger.info 'Scraping completed successfully.'
end
def save_as_csv(results)
CSV.open(OUTPUT_CSV, 'w', write_headers: true, headers: %w[Title Price URL]) do |csv|
results.each do |product|
csv << [product[:title], product[:price], product[:url]]
end
end
@logger.info "Saved #{results.size} products to #{OUTPUT_CSV}"
rescue StandardError => e
@logger.error "Failed to save CSV: #{e.message}"
end
end
So, we just collect all the relevant info and store it in a regular CSV file.
Final script
And here's your final script:
# frozen_string_literal: true
require 'csv'
require 'capybara'
require 'capybara/dsl'
require 'selenium-webdriver'
require 'fileutils'
require 'logger'
class MicroScraper
include Capybara::DSL
ROOT_URL = 'https://www.microcenter.com'
PRODUCTS_LIMIT = 5
CONCURRENCY = 3
SCREENSHOT_DIR = 'screens'
OUTPUT_CSV = 'products.csv'
def initialize
@logger = Logger.new($stdout)
@logger.level = Logger::INFO
setup_capybara
end
def run
query = ask_for_search_term
go_to_root
@logger.info "Searching for '#{query}' ..."
perform_search_with(query)
product_links = collect_product_links
if product_links.empty?
@logger.error 'No product links found. Exiting.'
return
end
@logger.info "Collected #{product_links.size} product links:"
product_links.each { |link| @logger.info " - #{link}" }
results = scrape_product_pages(product_links)
save_as_csv(results)
Capybara.reset_sessions!
@logger.info 'Scraping completed successfully.'
end
private
def save_as_csv(results)
CSV.open(OUTPUT_CSV, 'w', write_headers: true, headers: %w[Title Price URL]) do |csv|
results.each do |product|
csv << [product[:title], product[:price], product[:url]]
end
end
@logger.info "Saved #{results.size} products to #{OUTPUT_CSV}"
rescue StandardError => e
@logger.error "Failed to save CSV: #{e.message}"
end
def scrape_product_pages(links)
# Use thread-safe queues for both work and results
product_queue = Queue.new
links.each_with_index { |url, index| product_queue << [url, index] }
results_queue = Queue.new
threads = Array.new(CONCURRENCY) do
Thread.new do
loop do
pair = begin
product_queue.pop(true)
rescue StandardError
nil
end
break unless pair
url, index = pair
session = Capybara::Session.new(:selenium_headless_firefox)
begin
@logger.info "Thread #{Thread.current.object_id}: Visiting product #{index + 1}: #{url}"
session.visit(url)
if session.has_css?('div.product-header h1', wait: 10)
title = session.find('div.product-header h1').text.strip
price = begin
session.find('p.big-price', match: :first).text.strip
rescue StandardError
'N/A'
end
@logger.info "Thread #{Thread.current.object_id}: Loaded: #{title} – #{price}"
screenshot_file = File.join(SCREENSHOT_DIR, "product_#{index + 1}.png")
session.save_screenshot(screenshot_file)
results_queue << {
index: index + 1,
url: url,
title: title,
price: price
}
else
@logger.warn "Thread #{Thread.current.object_id}: Failed to find product title on page #{index + 1}"
end
rescue StandardError => e
@logger.error "Thread #{Thread.current.object_id}: Error visiting #{url}: #{e.message}"
ensure
session.quit
end
end
end
end
threads.each(&:join)
# Convert results_queue to an array and sort by original index
results = []
results << results_queue.pop until results_queue.empty?
results.sort_by { |r| r[:index] }
end
def collect_product_links
links = []
if page.has_css?('article#productGrid ul', wait: 5)
items = all('article#productGrid ul li.product_wrapper').first(PRODUCTS_LIMIT)
links = items.map do |li|
relative = li.find('a.productClickItemV2', match: :first)[:href]
URI.join(ROOT_URL, relative).to_s
rescue Capybara::ElementNotFound
@logger.warn 'Product link not found for an item. Skipping.'
nil
end.compact
else
@logger.error 'No product grid found on the search results page.'
end
links
end
def go_to_root
visit ROOT_URL
@logger.info "Opened Micro Center homepage at #{ROOT_URL}"
end
def perform_search_with(query)
within '#standardSearch form#searchForm' do
input = find('input#search-query', visible: true)
input.click
input.set(query)
find("input[type='submit'][name='searchButton']").click
end
# Wait for the result bar to appear
unless page.has_css?('main#mainContent .searchInfoBar', wait: 10)
@logger.error 'Timed out waiting for search results. Exiting.'
exit(1)
end
result_info = find('main#mainContent .searchInfoBar').text
@logger.info "Search info: #{result_info}"
page.save_screenshot(File.join(SCREENSHOT_DIR, 'search_results.png'))
end
def ask_for_search_term
query = nil
loop do
print 'Enter Micro Center search term: '
query = $stdin.gets&.chomp&.strip
break unless query.nil? || query.empty?
@logger.warn 'Search term cannot be empty.'
end
query
end
def setup_capybara
Capybara.register_driver :selenium_headless_firefox do |app|
options = Selenium::WebDriver::Firefox::Options.new
options.add_argument('-headless')
Capybara::Selenium::Driver.new(app, browser: :firefox, options: options)
end
Capybara.default_driver = :selenium_headless_firefox
Capybara.run_server = false
Capybara.default_max_wait_time = 10
FileUtils.mkdir_p(SCREENSHOT_DIR)
end
end
# Kick it off
scraper = MicroScraper.new
scraper.run
Run it with:
bundle exec ruby scraper.rb
Enter a search term (for example, "podcasting") and observe the results. Great job!
Conclusion
That's it for today. We've covered a lot of useful information on Ruby scraping and learned how to use Faraday, Nokogiri, Selenium, and Capybara to achieve impressive results. We've crafted our own scraper that sends parallel requests to optimize the process and handle real-world websites with ease.
With these tools and patterns under your belt, you're ready to take on more complex scraping challenges — whether it's for data analysis, automation, or just good old curiosity. The web is your playground now.
As always, thank you for staying with me, and until next time!

Ilya is an IT tutor and author, web developer, and ex-Microsoft/Cisco specialist. His primary programming languages are Ruby, JavaScript, Python, and Elixir. He enjoys coding, teaching people and learning new things. In his free time he writes educational posts, participates in OpenSource projects, tweets, goes in for sports and plays music.
