The internet is an endless source of data, and for many data-driven tasks, accessing this information is critical. Thus, the demand for web scraping has risen exponentially in recent years, becoming an important tool for data analysts, machine learning developers, and businesses alike. Also, Python has become the most popular programming language for this purpose.
In this detailed tutorial, you'll learn how to access the data using popular libraries such as Requests and Beautiful Soup with CSS selectors.
Without further ado, let’s get started!
Getting the HTML
When you're web scraping, the first step is to retrieve the contents of a web page from a URL using an HTTP GET request. One popular and easy-to-use option is the Python Requests library. It allows you to send HTTP requests easily and offers various useful features.
Install the Requests library with the following command:
pip install requests==2.32.3
Once you have extracted the HTML data, you can use the BeautifulSoup library to parse it and pull out the desired information efficiently.
To install the library, launch the below command in the terminal:
pip install beautifulsoup4==4.12.3
We will build a Hacker News scraper using Requests and BeautifulSoup to extract the rank, URL, and title from all articles posted on HN.
Create a Python script named main.py and import requests. In main.py, use Requests to make a GET request to your target website, storing the retrieved HTML content in the html_content variable, and then log it to the console.
import requests
# Send a GET request to the specified URL
response = requests.get("https://news.ycombinator.com/")
# Check if the request was successful (status code 200)
if response.status_code == 200:
html_content = response.content
print(html_content)
else:
print(response)
In the code, the requests.get() sends an HTTP GET request to a URL and retrieves the website's HTML content. It then checks the server's response status code using response.status_code. A 200 code indicates success, allowing the code to proceed with the HTML. Any other code (like a 404 "Not Found") is considered an error.
Note: The GET request to the server may fail due to a temporary outage, incorrect URL, or blocked IP. Error handling logic (if/else) prevents crashes and ensures the script only continues on successful (2xx) responses.
Here’s the result after running the code:
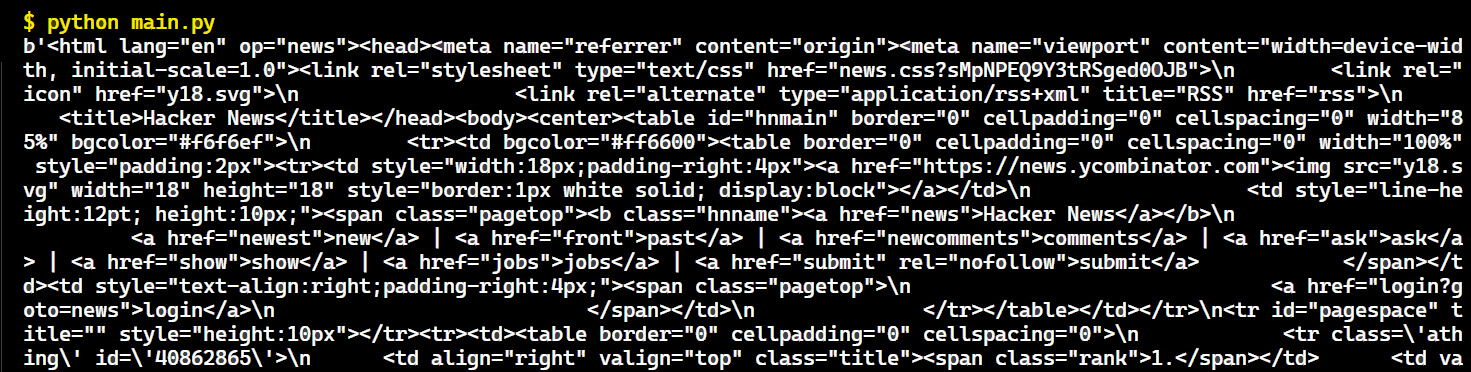
Great! Now, it's time to use Beautiful Soup to parse the page's HTML code and extract the specific data we want.
Parsing the HTML with Beautiful Soup
In the previous section, we retrieved an HTML document from the server. It appears as a complex structure of HTML tags and elements, and the only way to make sense of it is by extracting the desired data through HTML parsing.
Beautiful Soup is a Python library that allows you to select HTML elements and easily extract data from them
Let’s use BS4 to parse the content:
import requests
from bs4 import BeautifulSoup
response = requests.get("https://news.ycombinator.com/")
html_content = response.content
# Use Beautiful Soup to parse the HTML
soup = BeautifulSoup(html_content, "html.parser")
The BeautifulSoup() constructor takes HTML content and a string specifying the parser. Here "html.parser" tells Beautiful Soup to use the built-in HTML parser.
Note: When using BeautifulSoup, it's better to use a response.content instead of response.text. This is because response.content holds the raw HTML data in bytes, which is easier for BeautifulSoup to decode than the text representation in response.text. Using response.content helps avoid potential issues with character encoding.
Now, move on to the code. This soup object is very handy and allows us to access many useful pieces of information such as:
# The title tag of the page
print(soup.title)
# Output: <title>Hacker News</title>
# The title of the page as string
print(soup.title.string)
# Output: Hacker News
# All links in the page
nb_links = len(soup.find_all("a"))
print(f"There are {nb_links} links in this page")
# Output: There are 231 links on this page
# Text from the page
print(soup.get_text())
# Output:
# Hacker News
# Hacker News
# new | past | comments | ask | show | jobs | submit
# login
# ...
Targeting DOM elements
When using BeautifulSoup for web scraping, one of the most important tasks is targeting and extracting specific DOM (Document Object Model) elements. The DOM is a programming interface for web documents. Imagine the HTML code of a webpage as an upside-down tree. Each HTML element (headings, paragraphs, and links) is a node in this tree.
BS4 allows you to quickly and elegantly target the DOM elements you need. Here are the different ways Beautiful Soup provides to target these elements within the DOM:
Finding by Tag
To find elements by their tag name in Beautiful Soup, you have two main options: the find method and the find_all method.
- find: This method searches the parsed HTML document from top to bottom and returns the first occurrence of the tag you specify.
- find_all: This method searches the entire parsed HTML document and returns a list containing all instances of the specified tag or set of tags.
For instance, to find the first <a> tag in a document, you can use:
soup.find("a")

If you want to find all <a> tags, you can use the find_all method, which will return a list of all <a> tags in the document.
soup.find_all("a")

The .find('span') method will return the first <span> tag it finds in the parsed HTML:
soup.find("span")

.find_all('span') returns a list containing all <span> tags found in the HTML. This allows you to iterate through the list and access the content or attributes of each tag.
soup.find_all("span")

Finding by Class or ID
BS4 provides methods to locate elements by their class or ID attributes. For instance, to find an element with a specific class:
soup.find(class_="athing")

You can also find all elements with a specific class using:
soup.find_all(class_="athing")

Note: For classes, use class_ instead of class because the class is a reserved keyword in Python.
To find an element by its ID:
soup.find(id="pagespace")

CSS selectors
Why learn about CSS selectors if BeautifulSoup already has a way to select elements based on their attributes?
Well, you'll soon understand.
Querying the DOM
Often, DOM elements do not have proper IDs or class names. While perfectly possible, selecting elements in that case can be rather verbose and require lots of manual steps.
For example, let's say that you want to extract the score of a post on the HN homepage, but you can't use class name or id in your code. Here is how you could do it:
results = []
all_tr = soup.find_all('tr')
for tr in all_tr:
if len(tr.contents) == 2:
print(len(tr.contents[1]))
if len(tr.contents[0].contents) == 0 and len(tr.contents[1].contents) == 13:
points = tr.contents[1].text.split(' ')[0].strip()
results.append(points)
print(results)
>['168', '80', '95', '344', '7', '84', '76', '2827', '247', '185', '91', '2025', '482', '68', '47', '37', '6', '89', '32', '17', '47', '1449', '25', '73', '35', '463', '44', '329', '738', '17']
As promised, rather verbose, isn't it?
This is exactly where CSS selectors shine. They allow you to break down your loop and ifs into one expression.
all_results = soup.select('td:nth-child(2) > span:nth-child(1)')
results = [r.text.split(' ')[0].strip() for r in all_results]
print(results)
>['168', '80', '95', '344', '7', '84', '76', '2827', '247', '185', '91', '2025', '482', '68', '47', '37', '6', '89', '32', '17', '47', '1449', '25', '73', '35', '463', '44', '329', '738', '17']
The key here is td:nth-child(2) > span:nth-child(1). This selects for us the first <span> which is an immediate child of a <td>, which itself has to be the second element of its parent (<tr>). The following HTML illustrates a valid DOM excerpt for our selector.
<tr>
<td>not the second child, are we?</td>
<td>
<span>HERE WE GO</span>
<span>this time not the first span</span>
</td>
</tr>
This is much clearer and simpler, right? Of course, this example artificially highlights the usefulness of the CSS selector. But after playing a while with the DOM, you will fairly quickly realise how powerful CSS selectors are, especially when you cannot only rely on IDs or class names.
BeautifulSoup allows you to use CSS selectors to target elements more flexibly. For instance, to find all elements with a specific class within a <tr>:
soup.select("tr.athing")
The select method finds all elements in the parsed HTML that match a given CSS selector. It returns a list of all matching elements.
Here’s how you can select the first <tr> element in the HTML document that has the class athing.
soup.select_one("tr.athing")
The select_one method selects the first matching element based on the given CSS selector.
Or to find an element with a specific ID:
soup.select_one("#pagespace")
Easily debuggable
Another thing that makes CSS selectors great for web scraping is that they are easily debuggable. Let's check it out.
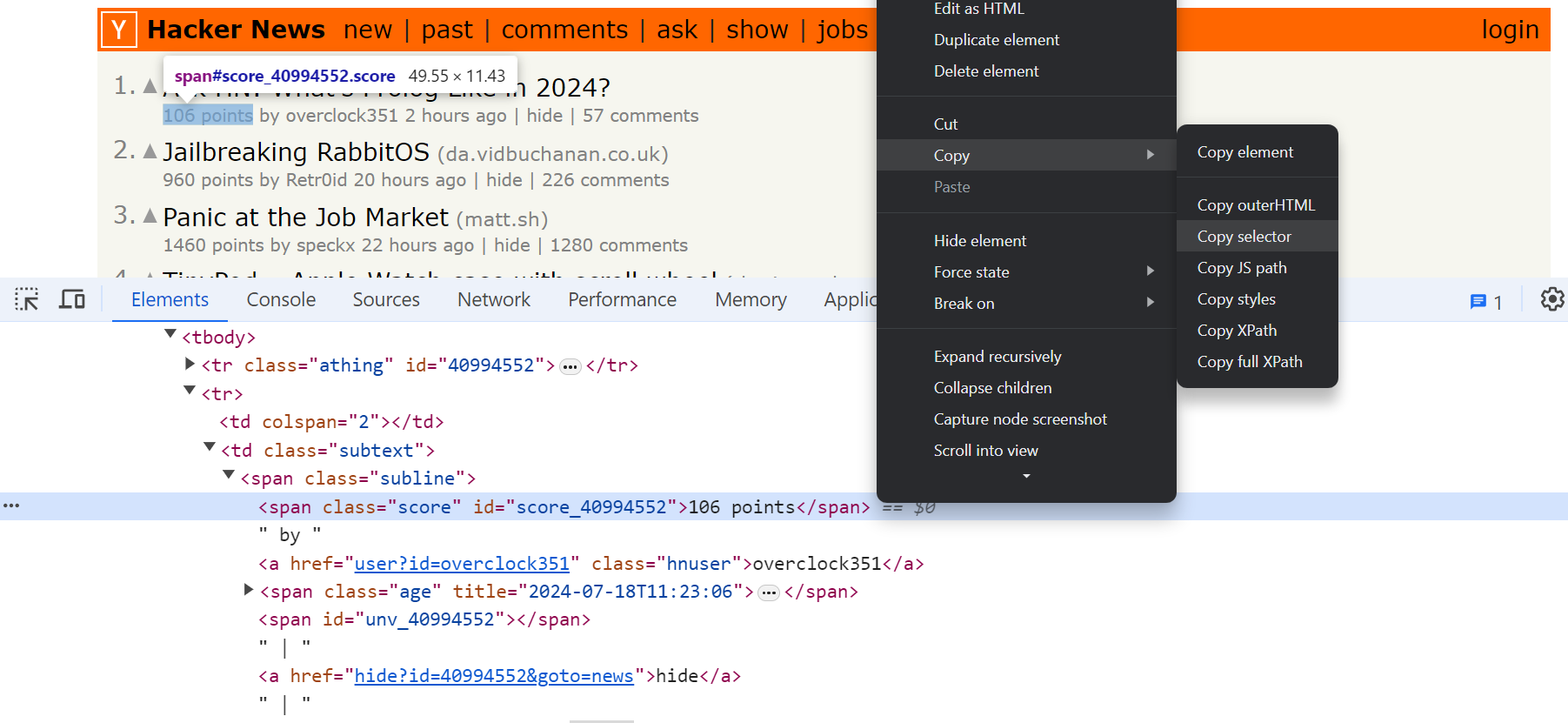
Open the developer tools (F12) in Chrome or Firefox, select the document tab, and use Ctrl/⌘ + F to open the search bar. Now enter any CSS expression (e.g. html body) and the browser will find the first matching element. Pressing Enter will iterate over the elements.
![]()
What is great is that it works the other way around too. Right-click any element in the DOM inspector and choose Copy - Copy Selector from the context menu.
Voilà, you have the right selector in your clipboard.
Advanced expressions
CSS selectors provide a comprehensive syntax to select elements in a wide variety of settings.
This includes child and descendant combinators, attribute selectors, and more.
Child and descendants: Child and descendant selectors allow you to select elements which are either immediate or indirect children of a given parent element.
# all <p> directly inside of an <a>
a > p
# all <p> descendants of an <a>
a p
And you can mix them together:
a > p > .test .example > span
That selector will work perfectly fine with this HTML snippet.
<a>
<p>
<div class="test">
<div class="some other classes">
<div class="example">
<span>HERE WE GO</span>
</div>
</div>
</div>
</p>
</a>
Siblings:
This one is one of my favorites because it allows you to select elements based on the elements on the same level in the DOM hierarchy, hence the sibling expression.
#html example
<p>...</p>
<section>
<p>...</p>
<h2>...</h2>
<p>This paragraph will be selected</p> (match h2 ~ p / h2 + p)
<div>
<p>...</p>
</div>
<p>This paragraph will be selected</p> (match h2 ~ p)
</section>
To select all p coming after an h2 you can use the h2 ~ p selector (it will match two <p>s).
You can also use h2 + p if you only want to select the <p> immediately following the our <h2> (it will match only one <p>).
Attribute selectors
Attribute selectors allow you to select elements with particular attributes values. So, p[data-test="foo"] will match
<p data-test="foo"></p>
Pseudo-classes:
Let's assume we have this HTML document.
<section>
<p>Paragraph 1</p>
<p>Paragraph 2</p>
<p>Paragraph 3</p>
<p>Paragraph 4</p>
</section>
Furthermore, let's assume we only want to select a particular <p> element. Welcome to pseudo-classes!
Pseudo-classes, such as :first-child, :last-child, and :nth-child, for example allow you to select specific elements by their position within the DOM tree.
// Selects "Paragraph 4"
section > p:last-child()
// Selects "Paragraph 2"
section > p:nth-child(2)
There are plenty of other pseudo-classes (e.g. input[type="checkbox"]:checked will select all checked checkboxes) and you can find a full list here. If you like to learn more about CSS selectors, you may also find this article interesting.
Maintainable code
I also think that CSS expressions are easier to maintain. For example, at ScrapingBee, when we do custom web scraping tasks all of our scripts begins like this:
TITLE_SELECTOR = "title"
SCORE_SELECTOR = "td:nth-child(2) > span:nth-child(1)"
...
This makes it easy to fix scripts when changes to the DOM are made.
Certainly, a rather easy way to determine the right CSS selector is to simply copy/paste what Chrome gave you when you right-click an element. However, you ought to be careful, as these selector paths tend to be very "absolute" in nature and are often neither the most efficient nor very resilient to DOM changes. In general it's best to verify such selectors manually before you use them in your script.
Traversing the DOM
Next, let's use Beautiful Soup to parse the HTML data and scrape the contents from all the articles on the first page of Hacker News. Before we select an element, let's use our developer tools to inspect the page and find what selectors we need to use to target the data we want to extract.
The content we are looking for is inside the tr tag with the class 'athing'.
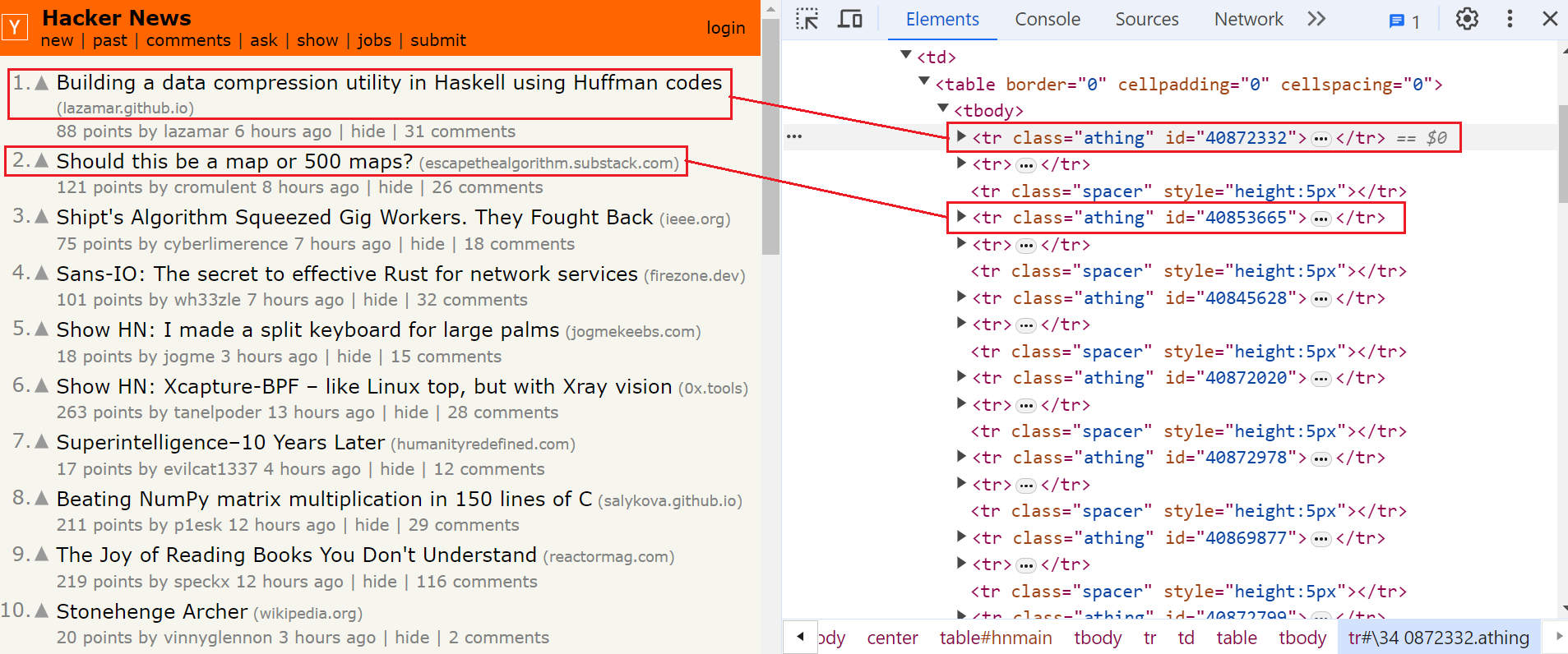
Now, let's use the Beautiful Soup find_all method to select all elements containing the athing class.
import requests
from bs4 import BeautifulSoup
# Send a GET request to the website
response = requests.get("https://news.ycombinator.com/")
html_content = response.content
# Use BeautifulSoup to parse the HTML content
soup = BeautifulSoup(html_content, "html.parser")
# Find all articles with the class 'athing'
articles = soup.find_all(class_="athing")
A common mistake you can make is failing to check for None.
Methods like find() and select_one() return None if they can't find the desired element. Since web pages change over time, the element you're trying to find might be located differently or may no longer exist.
To avoid errors, always check if the method result is not None before using it in your code.
#...
if articles is not None:
# ...
Next, let's loop through each article and print its text contents to the console, just to verify we have selected the correct elements.
import requests
from bs4 import BeautifulSoup
# Fetch the content from the URL
response = requests.get("https://news.ycombinator.com/")
html_content = response.content
# Use Beautiful Soup to parse the HTML
soup = BeautifulSoup(html_content, "html.parser")
articles = soup.find_all(class_="athing")
# Check if articles were found
if articles:
# Loop through the selected elements
for article in articles:
# Print each article's text content to the console
print(article.text)
The result is:
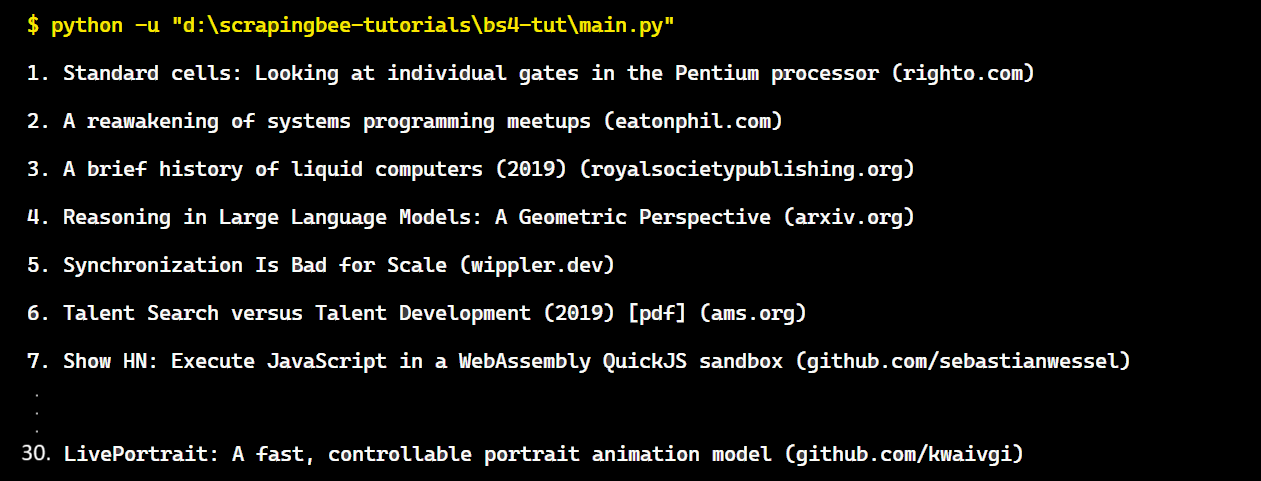
Great! We’ve successfully accessed the rank and title of each element.
In the next step, we will use the Beautiful Soup find method to grab the specific values we want to extract from each article and organize the obtained data in a Python dictionary.
For each article, we will extract the URL, rank, and title.
- The rank is located within the
spantag having the classrank. - The title and URL of the article are located within the
spantag having the classtitleline.
Take a look at the below image:
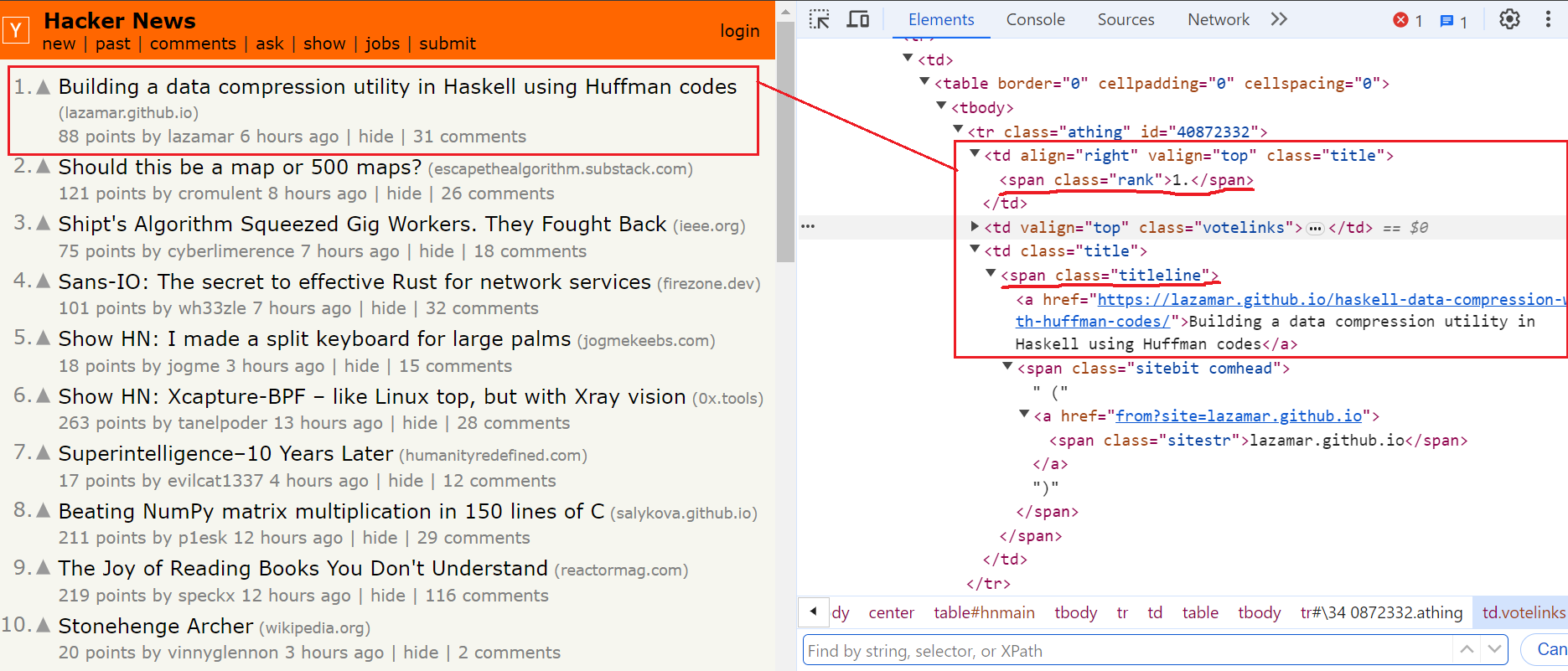
Here’s how our code looks when using the find method to get each article’s URL, title, and rank:
import requests
from bs4 import BeautifulSoup
# Fetch the content from the URL
response = requests.get("https://news.ycombinator.com/")
html_content = response.content
# Use Beautiful Soup to parse the HTML
soup = BeautifulSoup(html_content, "html.parser")
articles = soup.find_all(class_="athing")
scraped_data = []
# Check if articles are found
if articles is not None:
for article in articles:
data = {
"URL": article.find(class_="titleline").find("a").get("href"),
"title": article.find(class_="titleline").getText(),
"rank": article.find(class_="rank").getText().replace(".", ""),
}
scraped_data.append(data)
# Print the output list
print(scraped_data)
The result is:

Great! We've scraped information from the first page of Hacker News using Requests and Beautiful Soup. But wouldn't it be even better to get article data from all the pages? We can achieve this by applying the same logic to the remaining pages.
However, before applying the logic, you need to navigate to all the remaining pages. So, in the next section, we'll explore techniques for handling website pagination.
Handling pagination
Handling pagination in web scraping is a straightforward concept. You need to make your scraper repeat its scraping logic for each page visited until no more pages are left. To achieve this, you have to identify the last page to stop scraping and save the extracted data.
To handle pagination, we'll use two variables: "is_scraping" (a boolean tracking if the last page is reached) and "current_page" (an integer keeping track of the page being scraped).
is_scraping = True
current_page = 1
Next, let's create a while loop that continues scraping until the scraper reaches the last page. Within the loop, we will send a GET request to the current page of Hacker News to extract the URL, title, and rank.
import requests
from bs4 import BeautifulSoup
is_scraping = True
current_page = 1
scraped_data = []
while is_scraping:
# Fetch the content from the URL
response = requests.get(f"https://news.ycombinator.com/?p={current_page}")
html_content = response.content
print(f"Scraping page {current_page}: {response.url}")
# Use Beautiful Soup to parse the HTML
soup = BeautifulSoup(html_content, "html.parser")
articles = soup.find_all(class_="athing")
# ...
Within the loop, we will check if there is a "More" button with the class morelink on the page to navigate to the next page. Take a look at the below image:
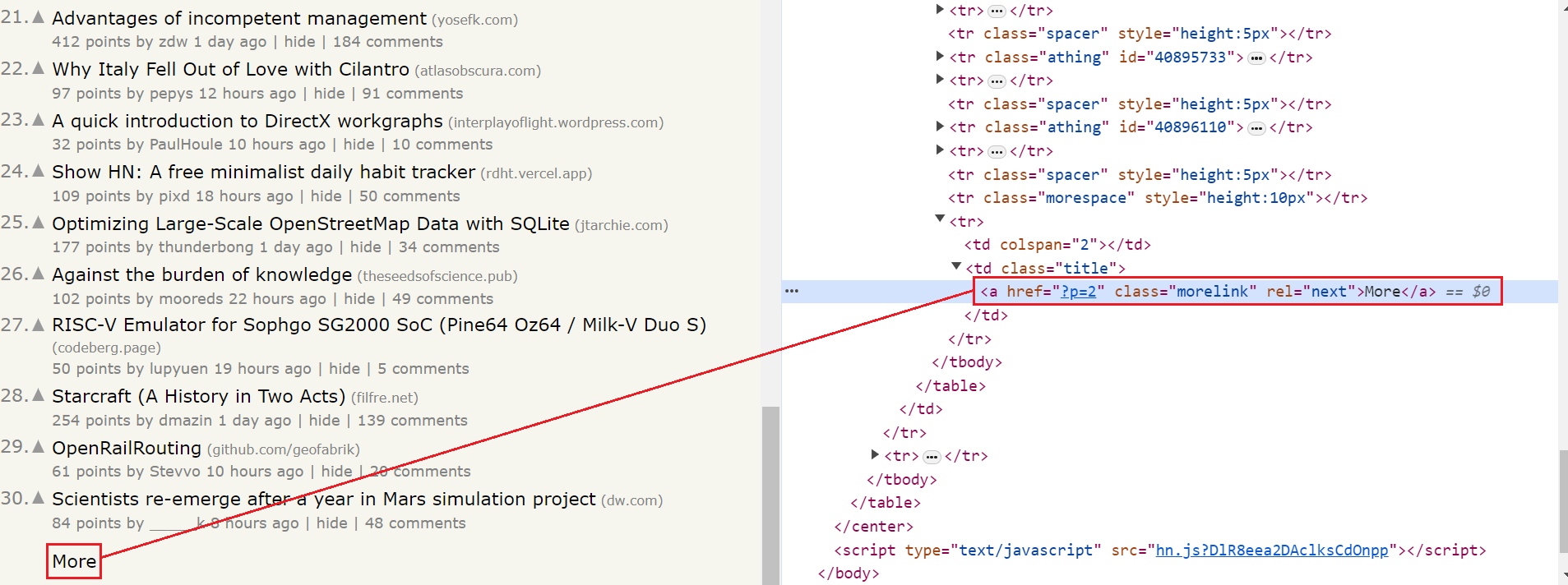
The "More" button is present on all pages, except the last one. So, if the morelink class is present on the page, the script increments the current_page variable and continues scraping the next page. If there is no morelink class, the script sets is_scraping to False and exits the loop.
# Check if there is a link to the next page
next_page_link = soup.find(class_="morelink")
if next_page_link:
current_page += 1
else:
is_scraping = False
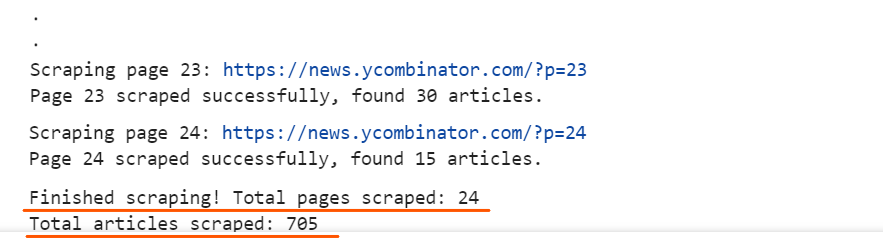
print(f"Finished scraping! Total pages scraped: {current_page}")
print(f"Total articles scraped: {len(scraped_data)}")
Putting it all together:
import requests
from bs4 import BeautifulSoup
is_scraping = True
current_page = 1
scraped_data = []
while is_scraping:
# Fetch the content from the URL
response = requests.get(f"https://news.ycombinator.com/?p={current_page}")
html_content = response.content
print(f"Scraping page {current_page}: {response.url}")
# Use Beautiful Soup to parse the HTML
soup = BeautifulSoup(html_content, "html.parser")
articles = soup.find_all(class_="athing")
# Check if articles are found
if articles is not None:
for article in articles:
data = {
"URL": article.find(class_="titleline").find("a").get("href"),
"title": article.find(class_="titleline").getText(),
"rank": article.find(class_="rank").getText().replace(".", ""),
}
scraped_data.append(data)
# Check if there is a link to the next page
next_page_link = soup.find(class_="morelink")
if next_page_link:
current_page += 1
else:
is_scraping = False
print(f"Finished scraping! Total pages scraped: {current_page}")
print(f"Total articles scraped: {len(scraped_data)}")
The result is:
Export the Scraped Data
The scraped information can be used for various needs and purposes. Therefore, it's crucial to convert it into a format that makes it easy to read and explore, like CSV or JSON. We currently have the article's information stored in a list named scraped_data. Now, let's explore how to store the data in CSV and JSON files.
Export to CSV
CSV is a popular format for data exchange, storage, and analysis, especially when dealing with large datasets. A CSV file stores information in a tabular form with comma-separated values.
import csv
# Scraping logic...
with open("hn_articles.csv", "a", newline="", encoding="utf-8-sig") as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=data.keys())
# Write headers only on the first iteration
if csvfile.tell() == 0:
writer.writeheader()
writer.writerows(scraped_data)
The code snippet performs the following tasks:
- It first imports the csv module, which provides the tools needed to work with CSV files.
- Then, it opens a file named "hn_articles.csv" in append mode.
- It creates a writer object called DictWriter. This object allows us to write dictionaries, where each key becomes a column header and the corresponding value goes into that column.
- The code checks if the file is empty. If it is (meaning the file pointer is at position 0), it writes the column headers (based on the
fieldnames) as the first row of the CSV file. - Finally, the snippet uses another method called writerows() to write each entry from your
scraped_datavariable, line by line, into the CSV file.
The result is:

Great! The data is stored in a CSV file.
Export to JSON
JSON is a text-based, human-readable format for representing structured data. It is commonly used for transmitting data between a server and a web application.
import json
# Scraping logic...
with open("hn_articles.json", "w", encoding="utf-8") as jsonfile:
json.dump(scraped_data, jsonfile, indent=4)
The logic above uses the json.dump() function from the standard json module. This function allows you to write a Python object to a JSON file.
json.dump() takes two arguments:
- The Python object to convert to JSON format.
- A file object created with
open().
The result is:
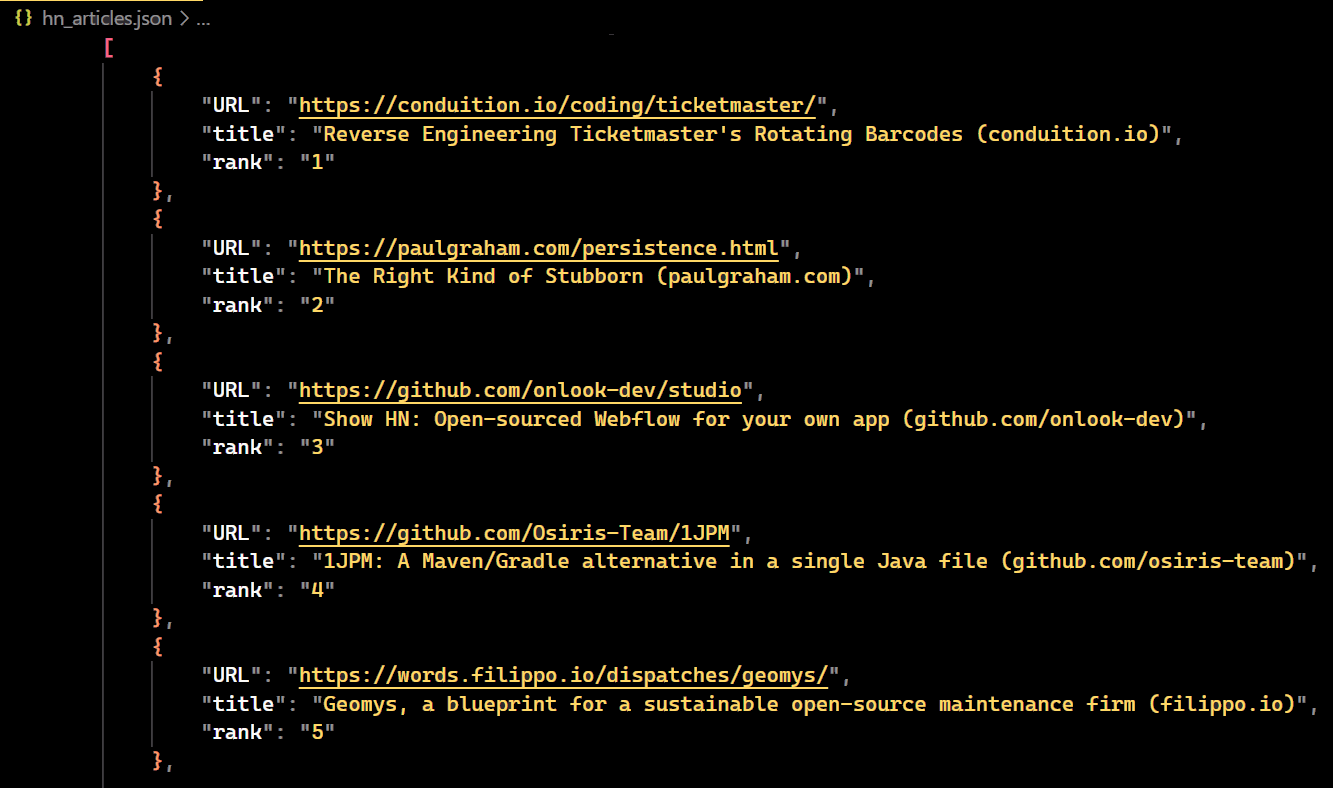
Great! The data is stored in a JSON file.
💡 Love BeautifulSoup? Check out our awesome guide to improving scraping speed performance with BS4.
Overcoming Web Scraping Challenges
Websites often use anti-bot systems like CAPTCHAs and fingerprint challenges, which can be difficult to bypass. Web scraping also requires significant computational resources, bandwidth, and ongoing maintenance and updates.
For instance, Hacker News is a simple website with minimal anti-bot protections, allowing us to scrape it relatively easily. Conversely, complex websites utilize sophisticated techniques to detect and block bots.
The difficulty of avoiding these blocks varies depending on the target website and the scale of your scraping operation. However, here are some techniques you can consider to mitigate them.
Rotate User Agents
The User-Agent header tells the server about the client's operating system, vendor, and version. If a server receives a large number of requests from the same User-Agent, it might block your requests. To avoid this, you can rotate User-Agents by generating a new one for each request.
Implement Rate Limiting
Anti-scraping measures often monitor the frequency of requests from the client. If a single IP sends too many requests too quickly, it might be flagged and blocked. A common way to bypass this is by introducing delays between requests. This ensures the server has enough time to process each request before receiving the next.
Use a Proxy Server
A rotating proxy server acts as a middleman between your scraping script and target websites. It routes your requests and assigns you a different IP address from its pool, automatically changing it periodically or after a set number of requests. Learn about How To Use A Proxy With Python Requests.
Add Retry Logic
Retry logic for network calls is essential in web scraping scripts. It improves reliability by handling temporary issues like server downtime or disconnections. Retrying failed calls before giving up, thus increasing the chance of successful data retrieval.
Robots.txt
To ensure ethical scraping, always check the website's terms of service and tailor your scripts accordingly. You should follow the rules outlined in the robots.txt file of the target website. Additionally, avoid scraping personal information without consent, as this violates privacy regulations.
Web scraping challenges require a combination of technical strategies, ethical considerations, and adherence to best practices. Some of these best practices include respecting the robots.txt file, rotating proxies and user agents, and so on.
But even with best practices, obstacles can arise that block you from getting the data you need. That's where tools like our web scraping API come in. It handles all anti-bot challenges, you can integrate in your code in just a matter of minutes.
Final code
We've come to the end of this detailed tutorial. Here's the final code you can use to scrape Hacker News. This code implements retry logic, which helps in retrying failed requests until the maximum attempts are reached.
import requests
from bs4 import BeautifulSoup
import time
import json
# Initialize variables
is_scraping = True
current_page = 1
scraped_data = []
max_retries = 3 # Maximum retries for failed requests
print("Hacker News Scraper started...")
# Continue scraping until there are no more pages to scrape
while is_scraping:
try:
# Make the request
response = requests.get(
f"https://news.ycombinator.com/?p={current_page}")
html_content = response.content
print(f"Scraping page {current_page}: {response.url}")
# Use BeautifulSoup to parse the HTML content
soup = BeautifulSoup(html_content, "html.parser")
articles = soup.find_all(class_="athing")
if articles:
# Extract data from each article on the page
for article in articles:
article_data = {
"URL": article.find(class_="titleline").find("a").get("href"),
"title": article.find(class_="titleline").getText(),
"rank": article.find(class_="rank").getText().replace(".", ""),
}
scraped_data.append(article_data)
print(f"Page {current_page} scraped successfully, found {len(articles)} articles.")
# Check if there's a link to the next page
next_page_link = soup.find(class_="morelink")
if next_page_link:
current_page += 1
else:
is_scraping = False
print(f"Finished scraping! Total pages scraped: {current_page}")
print(f"Total articles scraped: {len(scraped_data)}")
# Save scraped data to JSON file
with open("hn_articles.json", "w", encoding="utf-8") as jsonfile:
json.dump(scraped_data, jsonfile, indent=4)
except requests.exceptions.RequestException as e:
print(f"Error occurred while scraping page {current_page}: {e}")
# Implement retry logic with delay (up to max_retries attempts)
for attempt in range(1, max_retries + 1):
print(f"Retrying request for page {current_page} (attempt {attempt}/{max_retries})...")
time.sleep(2) # Adjust delay as needed
try:
response = requests.get(
f"https://news.ycombinator.com/?p={current_page}")
break # Successful request, exit retry loop
except requests.exceptions.RequestException:
pass # Continue retrying on failure
else:
print(f"Giving up after {max_retries} retries for page {current_page}")
# Always add a delay between requests
time.sleep(2)
💡 Love web scraping in Python? Check out our expert list of the Best Python web scraping libraries.
Conclusion
This detailed tutorial covered everything you need to know about getting started with Beautiful Soup and Requests in Python. You learned how to use them to build a web scraper that effectively extracts data from websites. However, web scraping has become increasingly challenging due to the rise of anti-bot and anti-scraping technologies. This is where tools like ScrapingBee come in.
I hope you liked this article about web scraping in Python and that it will make your life easier. For further reading, do not hesitate to check out our extensive Python web scraping guide.
Before you go, check out these related reads:
