Web scraping is one of the rather important parts when it comes automated data extraction of web content. While languages like Python are commonly used, C++ offers significant advantages in performance and control. With its low-level memory management, speed, and ability to handle large-scale data efficiently, it is an excellent choice for web scraping tasks that demand high performance.
In this article, we shall take a look at the advantages of developing our own custom web scraper in C++ and what its speed, resource efficiency, and scalability for complex scraping operations can bring to the table. You’ll learn how to implement a web scraper with the libcurl and libxml2 libraries.
Prerequisites
For this tutorial, you'll need the following:
- A basic understanding of HTTP
- C++ 11 or newer installed on your machine
- g++ 4.8.1 or newer
- The
libcurlandlibxml2C libraries - A resource with data for scraping (we’ll use the Merriam-Webster website as example here)
HTTP 101
HTTP is a typical request-response protocol, where each request sent by the client is supposed to receive in return a response from the server, containing the desired information. Both, requests and responses, contain sets of headers with additional payload information.
Let's take a look at a sample request. For instance, if you use cURL to make a request to Merriam-Webster’s website for the definitions of the word “esoteric”, the request would be similar to this:
GET /dictionary/esoteric HTTP/1.1
Host: www.merriam-webster.com
User-Agent: curl/8.9.1
Accept: */*
Once merriam-webster.com has received your request, it will respond with an HTTP response similar to the following:
HTTP/1.1 200 OK
Content-Type: text/html; charset=utf-8
Content-Length: 701664
Connection: keep-alive
Date: Sun, 02 Feb 2026 12:28:07 GMT
Server: nginx
Cache-Control: max-age=601
X-Rid: rid2883d6b2-e161-11ef-af36-0afff51ec309
Vary: Accept-Encoding
X-Cache: Hit from cloudfront
Via: 1.1 5af4fdb44166a881c2f1b1a2415ddaf2.cloudfront.net (CloudFront)
X-Amz-Cf-Pop: NBO50-C1
Alt-Svc: h3=":443"; ma=86400
X-Amz-Cf-Id: HCbuiqXSALY6XbCvL8JhKErZFRBulZVhXAqusLqtfn-Jyq6ZoNHdrQ==
Age: 5
<!DOCTYPE html>
<html lang="en">
<head>
<!--rest of it goes here-->
Apart from the actual HTML content, the response contains additional status information as part of the response headers. For example, the first line provides a status code of "200", indicating a successful request. It also states which server software is used (i.e. nginx) and provides further directives, such as for caching.
ℹ️ Learn more about HTTP at What is HTTP.
Building the Web Scraper
The scraper we’re going to build in C++ will accept a single word as a command line argument and fetch the respective dictionary definition from Merriam-Webster. To start, let’s create a directory called scraper and, in it, the file scraper.cc:
mkdir scraper
cd scraper
touch scraper.cc
Next, we need to set up our development environment.
Setting up the Libraries
The two C libraries you’re going to use, libcurl and libxml2, work here because C++ interacts well with C. While libcurl is an API that enables several URL and HTTP-predicated functions and powers the client of the same name used in the previous section, libxml2 is a mature and well supported library for XML and HTML parsing.
Using vcpkg
Developed by Microsoft, vcpkg is a cross-platform package manager for C/C++ projects. Follow this guide to set up vcpkg on your machine. You can install libcurl and libxml2 by typing the following command:
vcpkg install curl libxml2
If you are using Visual Studio on Windows, you can also run the following command to integrate vcpkg in your MSBuild project:
vcpkg integrate install
Using apt
If you are using a Debian-flavoured Linux distribution, you can also use apt to install libcurl and libxml2 with the following command:
sudo apt install libcurl4-openssl-dev libxml2-dev
The main() function
Now that we have everything set up, we can start writing the code of our C++ web scraper. For this, we open scraper.cc in our IDE and start adding the functions we need for our scraper to work. As with each C program, we start our code execution with the main() function:
int main(int argc, char **argv)
{
if (argc != 2)
{
std::cout << "Please provide a valid English word" << std::endl;
exit(EXIT_FAILURE);
}
std::string arg = argv[1];
std::string res = request(arg);
std::cout << scrape(res) << std::endl;
return EXIT_SUCCESS;
}
The function is relatively short and almost self-explanatory:
- We check
argcand whether our program actually received a command line argument with the word to check. - We call our
request()function, where we will use cURL to get the HTML content from Merriam-Webster. - We pass the HTML content that we just received to our
scrape()function.
The request() function
Here, we basically only use cURL to load the content from the merriam-webster.com definition page for the word
std::string request(std::string word)
{
CURLcode res_code = CURLE_FAILED_INIT;
CURL *curl = curl_easy_init();
std::string result;
std::string url = "https://www.merriam-webster.com/dictionary/" + strtolower(word);
curl_global_init(CURL_GLOBAL_ALL);
if (curl)
{
curl_easy_setopt(curl,
CURLOPT_WRITEFUNCTION,
static_cast<curl_write>([](char *contents, size_t size,
size_t nmemb, std::string *data) -> size_t
{
size_t new_size = size * nmemb;
if (data == NULL) {
return 0;
}
data->append(contents, new_size);
return new_size; }));
curl_easy_setopt(curl, CURLOPT_WRITEDATA, &result);
curl_easy_setopt(curl, CURLOPT_URL, url.c_str());
curl_easy_setopt(curl, CURLOPT_USERAGENT, "simple scraper");
res_code = curl_easy_perform(curl);
if (res_code != CURLE_OK)
{
return curl_easy_strerror(res_code);
}
curl_easy_cleanup(curl);
}
curl_global_cleanup();
return result;
}
- We initialise our cURL object with
curl_easy_init(). - We assemble the target URL and save it under
url. - We use
curl_easy_setopt()to a few connection options for our cURL object (i.e. a callback for receiving the response, the URL, and the user agent). - We send the request using
curl_easy_perform(). - After a successful request execution, our function returns the content we received in
result.
The scrape() function
This function takes the HTML content we obtained in our previous step, attempts to parse it into a DOM tree, and extract the relevant word definitions with the following XPath expression:
//div[contains(@class, 'vg-sseq-entry-item')]/div[contains(@class, 'sb')]//span[contains(@class, 'dtText')]
💡 Curious about how XPath expressions work in detail?
Check out our dedicated tutorial on XPath expressions: Practical XPath for Web Scraping
std::string scrape(std::string markup)
{
std::string res = "";
// Parse
htmlDocPtr doc = htmlReadMemory(markup.data(), markup.length(), NULL, NULL, HTML_PARSE_NOERROR);
// Instantiate XPath context
xmlXPathContextPtr context = xmlXPathNewContext(doc);
// Fetch all elements matching the given XPath and iterate over them
xmlXPathObjectPtr definitionSpanElements = xmlXPathEvalExpression((xmlChar *)"//div[contains(@class, 'vg-sseq-entry-item')]/div[contains(@class, 'sb')]//span[contains(@class, 'dtText')]", context);
if (definitionSpanElements->nodesetval == NULL) return "No definitions available";
for (int i = 0; i < definitionSpanElements->nodesetval->nodeNr; ++i)
{
char *def = (char*)xmlNodeGetContent(definitionSpanElements->nodesetval->nodeTab[i]);
res += def;
res += "\n";
free(def);
}
xmlFreeDoc(doc);
xmlCleanupParser();
return res;
}
- We first parse the HTML document with
htmlReadMemory()into a DOM tree. - We use
xmlXPathEvalExpression()to evaluate our XPath expression. - With a for-loop, we iterate over each element that matched our expression and append its content to the
resstring. - Eventually, we return all the definitions we found as part of
res.
The strtolower() function
In request(), you may have noticed already the function call to strtolower(). This is to normalise the word to lowercase. The function name was inspired by PHP and simply uses the transform() method of C++.
std::string strtolower(std::string str)
{
std::transform(str.begin(), str.end(), str.begin(), ::tolower);
return str;
}
The full code
The scraper.cc file should now include the following code:
#include "iostream"
#include "string"
#include "algorithm"
#include "curl/curl.h"
#include <libxml/HTMLparser.h>
#include <libxml/xpath.h>
typedef size_t (*curl_write)(char *, size_t, size_t, std::string *);
std::string strtolower(std::string str)
{
std::transform(str.begin(), str.end(), str.begin(), ::tolower);
return str;
}
std::string request(std::string word)
{
CURLcode res_code = CURLE_FAILED_INIT;
CURL *curl = curl_easy_init();
std::string result;
std::string url = "https://www.merriam-webster.com/dictionary/" + strtolower(word);
curl_global_init(CURL_GLOBAL_ALL);
if (curl)
{
curl_easy_setopt(curl,
CURLOPT_WRITEFUNCTION,
static_cast<curl_write>([](char *contents, size_t size,
size_t nmemb, std::string *data) -> size_t
{
size_t new_size = size * nmemb;
if (data == NULL) {
return 0;
}
data->append(contents, new_size);
return new_size; }));
curl_easy_setopt(curl, CURLOPT_WRITEDATA, &result);
curl_easy_setopt(curl, CURLOPT_URL, url.c_str());
curl_easy_setopt(curl, CURLOPT_USERAGENT, "simple scraper");
res_code = curl_easy_perform(curl);
if (res_code != CURLE_OK)
{
return curl_easy_strerror(res_code);
}
curl_easy_cleanup(curl);
}
curl_global_cleanup();
return result;
}
std::string str_replace(std::string search, std::string replace, std::string &subject)
{
size_t count;
for (std::string::size_type pos{};
subject.npos != (pos = subject.find(search.data(), pos, search.length()));
pos += replace.length(), ++count)
{
subject.replace(pos, search.length(), replace.data(), replace.length());
}
return subject;
}
std::string scrape(std::string markup)
{
std::string res = "";
// Parse
htmlDocPtr doc = htmlReadMemory(markup.data(), markup.length(), NULL, NULL, HTML_PARSE_NOERROR);
// Instantiate XPath context
xmlXPathContextPtr context = xmlXPathNewContext(doc);
// Fetch all elements matching the given XPath and iterate over them
xmlXPathObjectPtr definitionSpanElements = xmlXPathEvalExpression((xmlChar *)"//div[contains(@class, 'vg-sseq-entry-item')]/div[contains(@class, 'sb')]//span[contains(@class, 'dtText')]", context);
if (definitionSpanElements->nodesetval == NULL) return "No definitions available";
for (int i = 0; i < definitionSpanElements->nodesetval->nodeNr; ++i)
{
char *def = (char*)xmlNodeGetContent(definitionSpanElements->nodesetval->nodeTab[i]);
res += def;
res += "\n";
free(def);
}
xmlFreeDoc(doc);
xmlCleanupParser();
return res;
}
int main(int argc, char **argv)
{
if (argc != 2)
{
std::cout << "Please provide a valid English word" << std::endl;
exit(EXIT_FAILURE);
}
std::string arg = argv[1];
std::string res = request(arg);
std::cout << scrape(res) << std::endl;
return EXIT_SUCCESS;
}
Compile and run
With all the functions in place, we can save scraper.cc, compile it, and run a first test.
Execute the following command to compile the source code:
g++ scraper.cc -lcurl -lxml2 -std=c++11 -o scraper -I/usr/include/libxml2/
If the compilation was successful, you should now have an executable named scraper in the same directory. We can now run a first test with the term "esoteric".
./scraper esoteric
: designed for or understood by the specially initiated alone
: requiring or exhibiting knowledge that is restricted to a small group
: difficult to understand
: limited to a small circle
: private, confidential
: of special, rare, or unusual interest
: taught to or understood by members of a special group
: hard to understand
: of special or unusual interest
The following screenshot is of the page we just scraped:
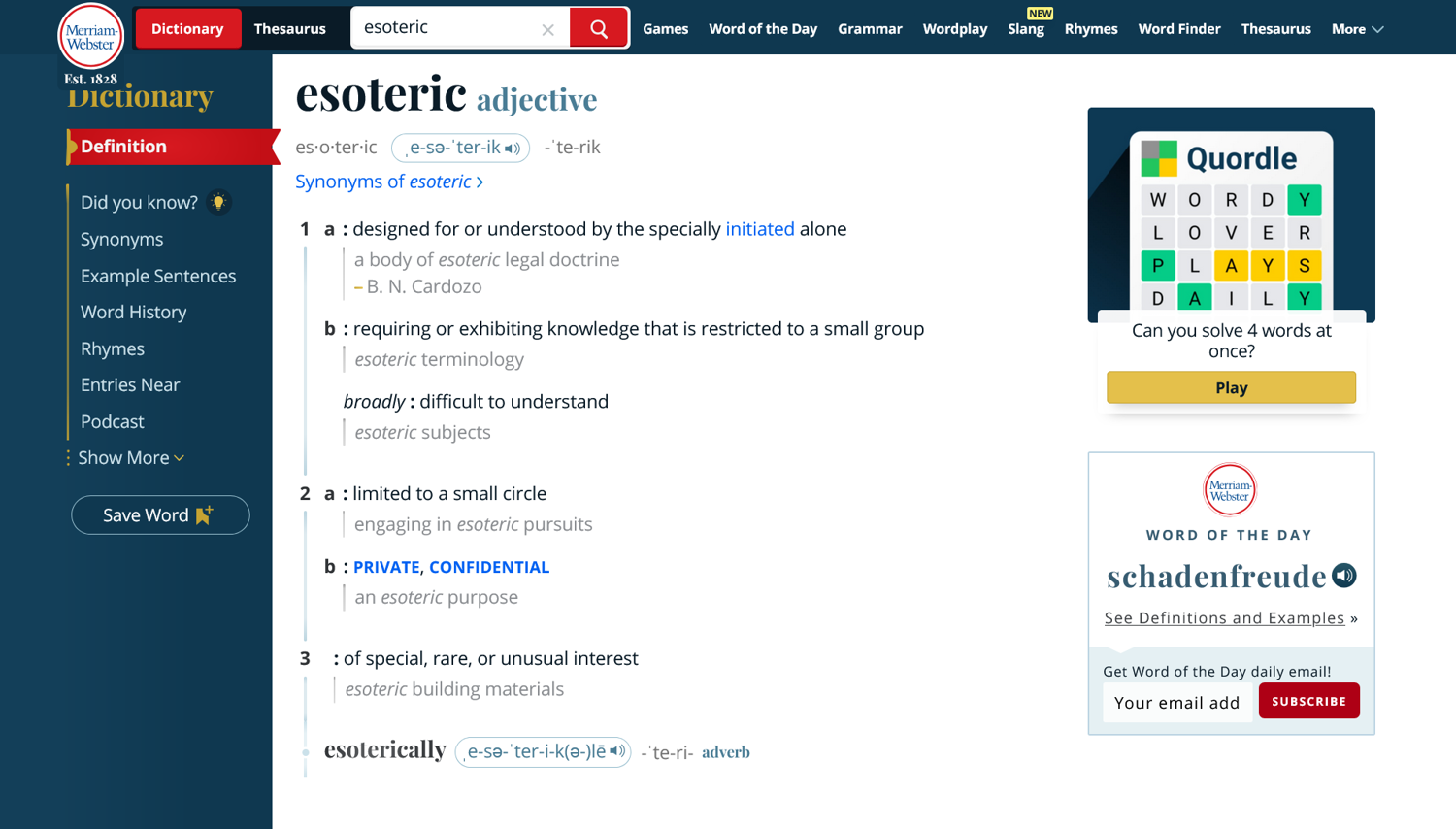
Conclusion
As we learned in this tutorial, C++ - even though typically used for low-level, system programming - can equally well serve as the foundation for web scraper projects.
One thing you may note is that the example was relatively simple and didn’t address more complex use cases, such as handling JavaScript, using proxies, or implementing techniques to avoid being blocked. This is where dedicated scraping services, such as ScrapingBee, can be highly beneficial, supporting scraping projects of any scale. Please feel free to check out our free scraping trial and get 1,000 API calls on the house.
If you would like to learn more about cURL you can check: How to follow redirect using cURL?, How to forward headers with cURL? or How to send a POST request using cURL?
Before you go, check out these related reads:

Alexander is a software engineer and technical writer with a passion for everything network related.
