Competitor analysis is a vital task in big or small companies. It allows you to confirm market needs by looking at what competitors are offering. At the same time, it allows you to build better products and impress potential customers by fixing what is wrong with the current options.
Of course, a company should focus on its own products. But you can’t just ignore what is happening out there. You can find amazing insights with data gathered from competitors, suppliers, customers.
Check out some examples of what you can do:
- Track competitor prices and create promotions
- Verify stock status
- Keep up with new product releases and new features
- Check spec changes that can affect product compatibility
- Look for customer reviews (good and bad)
- Read comments and feature requests
Alright, competitor analysis is important. But how can I monitor my competitors?
Manual checks are usually a bad idea. They are too time-consuming, and it’s easy to miss changes when you scroll through hundreds of pages.
Therefore, this is a task for a bot. After all, robots truly excel at repetitive tasks.
You’d need a lot of code to code such a bot. And dealing with different page designs is also quite a challenge. Not to mention that you can get blocked by your target sites.
But don’t give up on your competitor analysis yet. Today you’ll learn a way to monitor competitors automatically with no coding knowledge.
You can do it using two tools. You can use Integromat to define which pages to load and what to do when there are content updates. And you can use ScrapingBee to actually scrape your target pages.
This article shows you step by step how you can set up Integromat and Scrapingbee and how to use them together. You’ll learn:
- How to save a list of pages to track
- How to extract structured information from them
- How to run actions when there are content changes
Today you’ll see examples tracking general content updates in a product documentation. But you can use the same technique to monitor competitors in any way you want: prices, stock, features, ratings, comments, and so on.
Let’s get started!

Why ScrapingBee and Integromat?
Integromat is a no-code tool that allows you to connect different modules, creating scenarios. There are many apps you can use, and the beauty of it lies in combining different apps to run automated actions.
For example, you can create spreadsheet entries for emails received. You can send Telegram messages when there’s a new blog post. And you can monitor your competitor's sites using ScrapingBee.
ScrapingBee on the other side is an API that allows you to scrape pages with no risk of getting blocked. Think of it as a middleman that gets your request ("I want the element X on page Y") and finds a way to retrieve it for you.
You can use many programming languages to send your commands to ScrapingBee. But you can use a tool like Integromat in case you don’t want to do any programming at all.
In Integromat, you use form fields to tell ScrapingBee what you want to do. This is a great combo for quickly creating a scraper that just works.
No-code competitor analysis with a few clicks
It might seem like a daunting task, but you can break down competitor analysis into a 4-step process.
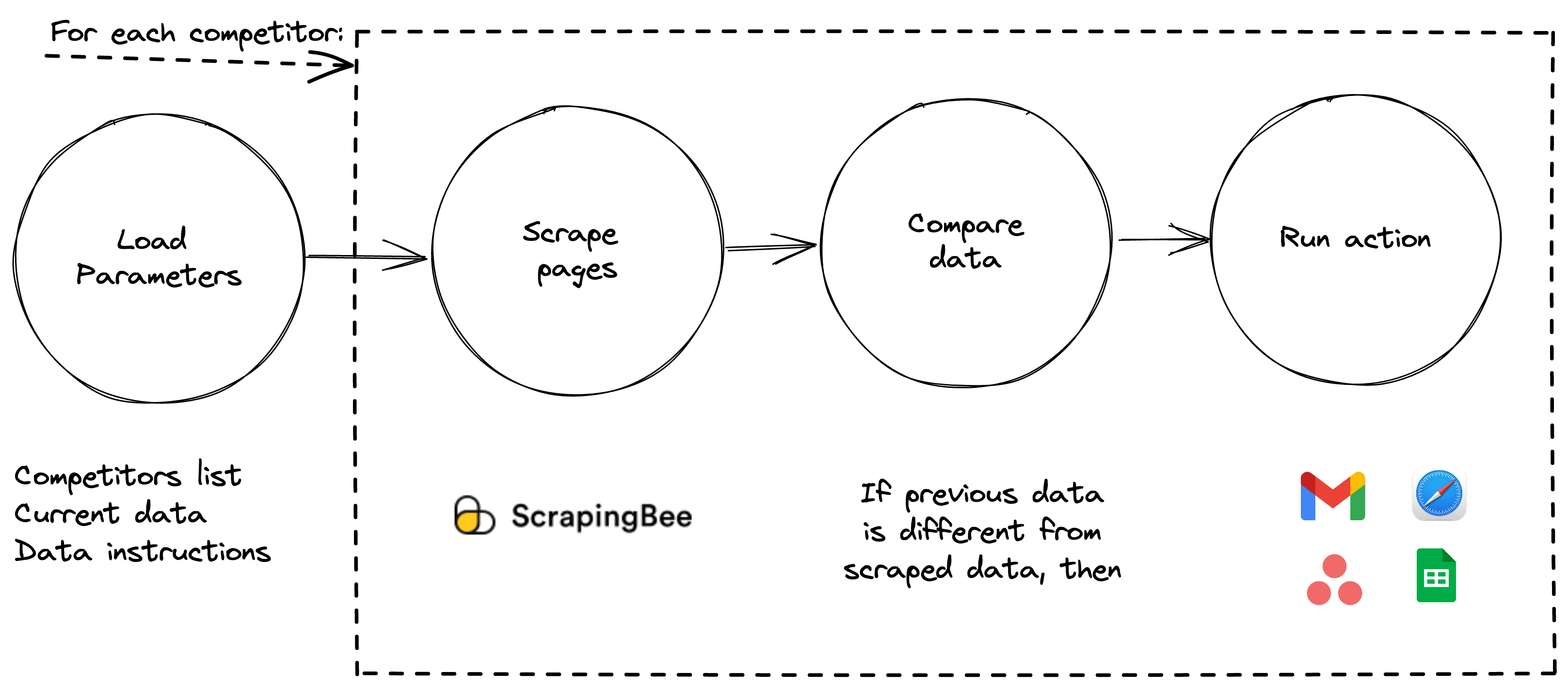
You need to:
- Load the current data and parameters: A list of the pages you want to load, how to load them, and the latest information you have
- Scrape pages and load content: ScrapingBee loads your target pages following the instructions
- Compare previous data with live data: Check if there were any changes
- Run desired actions: Create tasks, add Google Sheets rows, send emails…
Here’s a sneak peek of how this workflow turns into your Integromat scenario:
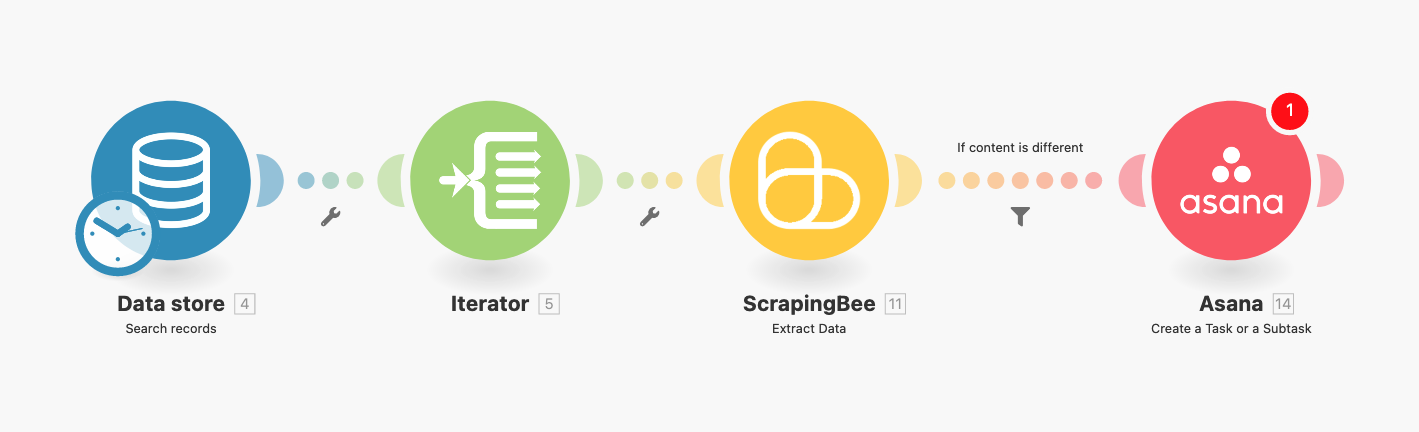
Each of these circles is a module. You will dive deeper into each step, but you can see how it relates to the previous workflow:
- Data store module loads our current records and sends them to the Iterator module
- The Iterator module sends each of our database records to ScrapingBee, one at a time, so it can load our pages
- The ScrapingBee module passes this information to a filter to check if there is new content
- If there are changes, the Asana Module creates a new task to manually review changes in that URL
Now the secret lies in Step 2 when ScrapingBee loads your target pages. There you can use all the ScrapingBee’s API options.
In this tutorial, the focus is the extract rules. You can use them to load specific page elements as if you were using CSS code.
Along with CSS code, you can add extra parameters to your extract rules. These parameters allow you to load not just tag contents, but attributes, raw HTML code, list multiple elements.
You can use these options to load content in almost any page design.
Now sign in to your Integromat and ScrapingBee accounts, so you can follow along step by step.
Step 1: Triggers and Data storage
In any app design, coding or no-code, you need to store data. For your competitor monitoring app, you can store these fields:
- URL — The competitor’s page link
- Selector — The instructions you send to ScrapingBee
- Current Value — The current data that you will use to compare with the live version and see if there were any updates.
Surely, you can add many other fields if you want. You can add the competitor name, date changed, active/inactive, and so on. But let’s keep it simple for now.
In Integromat, you can use the data stores module for data storage. It allows you to create databases and tables. Then, you can use these records in your scenarios and modules.
Each data store uses a data structure. They are general table designs containing the fields you want to use in your data store. You can create a data structure with the 3 fields we want to save (URL, Selector, Current Value).
Then, go to data store and create a new table for your competitors using this structure.
You can always manually edit your records for a data store in this section.
If you want a head start, you can copy the demo competitors:
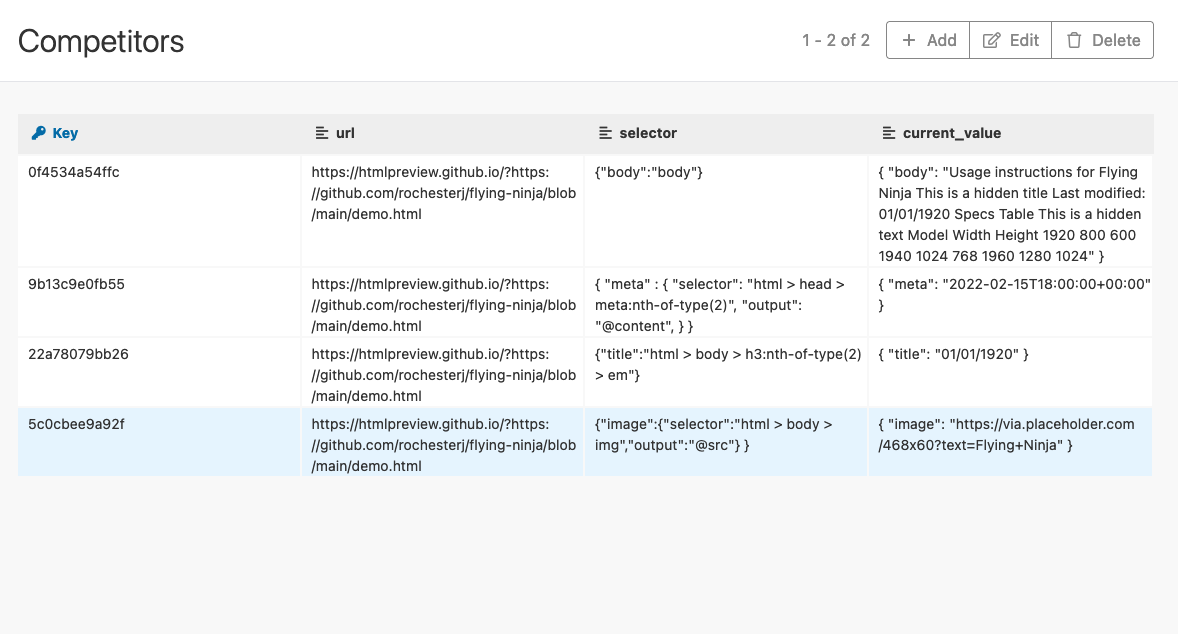
These are the parameters for your app. Now you need to create a module to load them in your scenario.
Go to Scenarios, and create a new scenario.
The first module you need to add is the data store module, using its “Search records” option.
You want to load all items from the competitor's table. Thus, you can filter by “URL” exists, and the module will return all records.
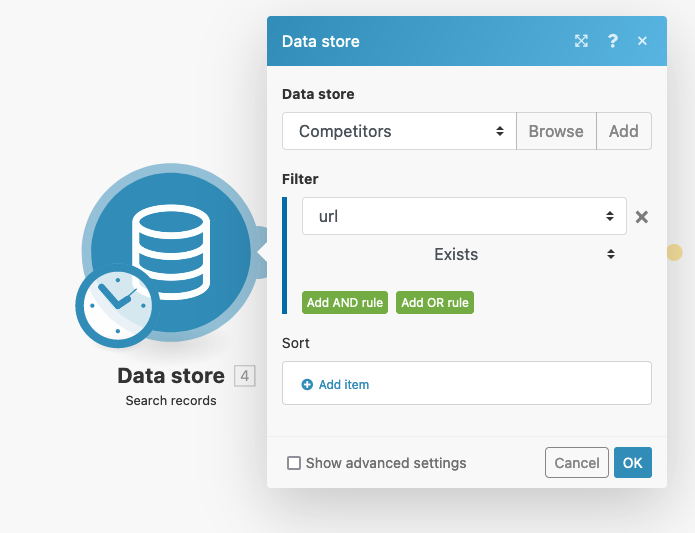
In the future, you can edit this option and load only “active” competitors, for example.
Next, you need to tell Integromat that you want to run a full sequence of tasks for each individual record. You can do this by using the Iterator module. It allows you to run the entire scenario again and again, for each array item.
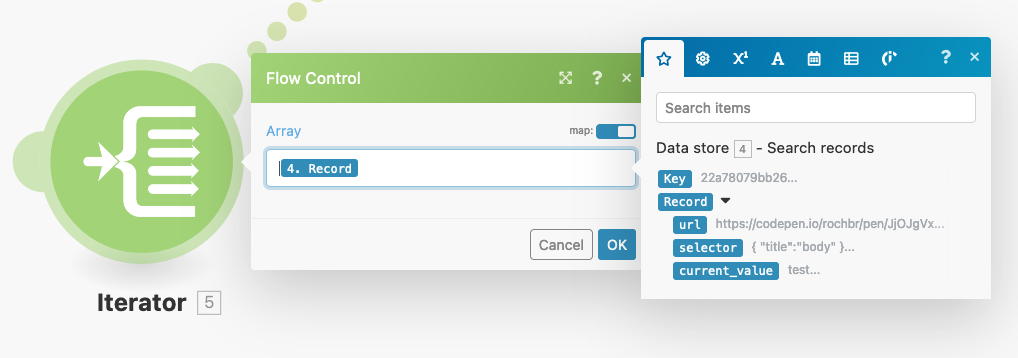
Everything is ready, let’s scrape some pages now.
Step 2: Scrape pages and Analyze contents
The next module in your scenario is the ScrapingBee module.
You need a license key to use it, and you can sign up for 1,000 free credits here.
Now you can add the ScrapingBee module with the “extract data” action.
You need to fill in your API key in the “connection” field. If you don’t have any API keys saved, you can click on “Add”.
Moving on, you can use variables coming from the data store for URL and extract rules. It might look like this:
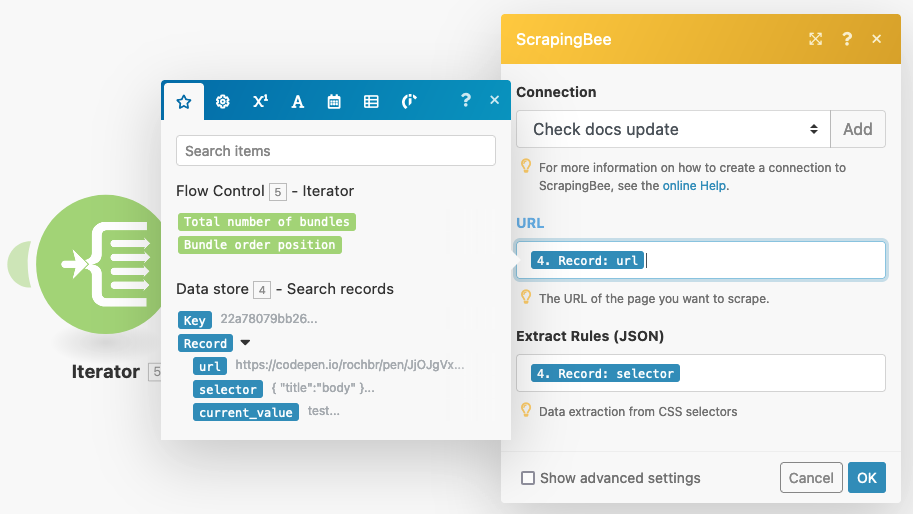
You can use the “show advanced settings” option as well. With it, you can perform specific actions, run JS code, take screenshots. A lot of fun stuff. But for today, let’s focus on the extract rules and CSS parsing.
It all seems simple. You add your variables, and Integromat loads them.
But you might be wondering how you can actually write these extract rules. After all, they are coming from your table, but you need to add them there in the first place.
That’s where the fun begins. The rules depend on your competitor’s page design, and where the content is in it.
Let’s explore a few different options you have to extract data from pages.
How to scrape visible content on a page
To make things easier, let’s use this demo page.
Now imagine that you want to extract the "Last Modified" text. You can compare this value with the previous “last modified” records. When it changes, you know that the content has changed.
You need to find a way to tell ScrapingBee to select that exact element using CSS code. The general syntax for extract rules is this:
{ "key_name" : "css_selector" }
You can pass multiple variables, along with the CSS selector to populate that variable.
If you can code, that’s great. You can use any CSS selector you want and extract your data.
If you know nothing about CSS code, there are is a magic solution for it.
You can right-click the element you want to monitor, then select "Inspect Element". If you don't see this option, you need to activate the developer tools in your browser.
Then right-click the HTML code for that element inside the developer tools, select "Copy > XPath":
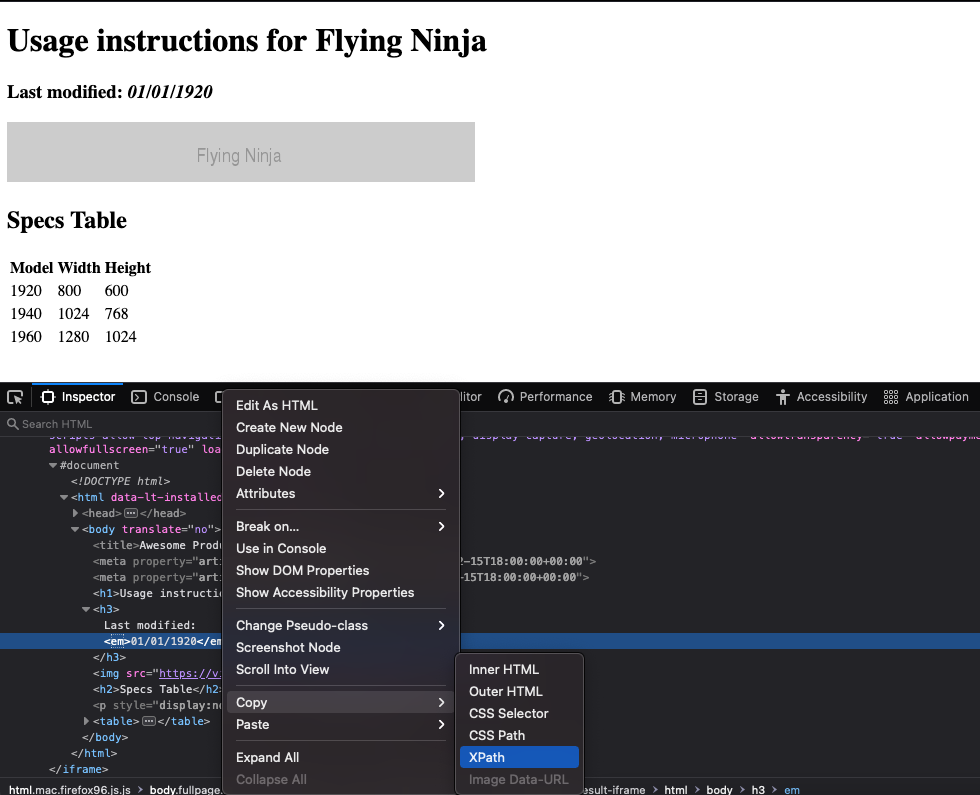
The XPath gives you the "folder" format of a CSS selector.
You need to use the XPath, and not the CSS Path for a couple of reasons. The big one is that the CSS Path is not specific enough. You might end up load the element’s siblings, since they all have the same CSS Path. Another reason is that copying directly the CSS selector from the browser is not very robust and will break often.
XPath gives you the exact path for the element only.
Here is the XPath for our example:
/html/body/h3[2]/em
This isn’t a valid CSS selector, but it is very close to being one. You just need to follow 2 rules
- Replace
/with>(with spaces around it) - Replace
[n]with:nth-of-type(n)” (with a space after it, and no spaces before it)
Alternatively, you can use an online XPath to CSS converter if you want.
Following the XPath conversion rules, this:
/html/body/h3[2]/em
Turns into this:
html > body > h3:nth-of-type(2) > em
Notice how spaces are important. For example, if you add a space before “:nth-of-type(1)” you are loading a completely different element.
Once you have the CSS selector, you can create your extract rule. This is what the “Last modified” extract rule looks like:
{
"date":"html > body > h3:nth-of-type(2) > em"
}
And this is the API response:
{
"title": "01/01/1920"
}
Just remember that you shouldn’t add extract rules to your scenario, since Integromat is loading them from your variables. Therefore, you can test your rules in ScrapingBee, and then add them to your data store.
Note: If you get an error 400 instead of the crawling results, try adding your selector with no additional spaces or tabs, like this:
{"title":"html > body > h3:nth-of-type(2) > em"}
How to load content from self-closing tags
The CSS rules with no arguments work fine to load content inside an HTML tag. But it won’t return content for self-closing tags. These are tags that don’t have content, only attributes. For example, a h1 tag has content, like this:
<h1>This is a title</h1>
But img tags don’t have content:
<img src=”IMAGE URL” />
In this case, you need to load the tag attributes.
For example, if you want to know when your competitor updates their products’ pictures. Using only the CSS selector won’t allow you to get the image. But you can get this information by adding more arguments to your extract rules.
The following extract rule is a simplified version where you have a lot of default values. When you use:
{
"image":"html img"
}
You are actually passing these attributes:
{
"image" : {
"selector": "html img",
"output": "text",
"type": "item"
}
}
Therefore, you can change the output format. In it, you can use:
- Text: Tag contents with HTML stripped
- HTML: The HTML code for the target element with inner HTML
@[attribute]: Tag’s attribute prefixed by@
Thus, to check if the image URL has changed, you need to compare the src attribute, to do this you can use this extract rule:
{
"image" : {
"selector": "html > body > img",
"output": "@src",
}
}
There are other use cases for the @attribute rule. For example, if you want to track the meta tag <meta property="article:modified_time" /> from the demo page.
In this case, you don’t have an option to right-click it from the page’s contents. But you can open the Developer Tools using right click (in any element) then inspect element. Next, you need to scroll up and copy the XPath for the meta tag.
This is an example for the extract rules for the meta tag “article:modified_time".
{
"meta" : {
"selector": "html > head > meta:nth-of-type(2)",
"output": "@content",
}
}
You can explore a page using the Developer Tools to find hidden tags as well. Quite often, your desired information is on the page, but it is hidden with some CSS code. But if it’s there, you can copy its XPath and scrape it.
How to load multiple items of the same type
Sometimes, you need to scrape tables or lists from your competitor’s site. In these cases, you can use the extract rules, and switch the type from item to list.
Item selectors are the default option, and they load only the first matched element. List selectors return all matched elements.
In our case, you can turn the CSS selector you have copied for a specific element into a broader CSS selector. You just need to remove the last :nth-of-type or :nth-child.
Head over to our demo page again.
Try to select the 1920 model. This is the XPath you’ll get:
/html/body/table/tbody/tr[2]/td[1]
Which turns into this CSS selector:
html > body > table > tbody > tr:nth-of-type(2) > td:nth-of-type(1)
Then, you can remove the very last part:
html > body > table > tbody > tr:nth-of-type(2) > td
Lastly, when you add your extract rules, you use the type list:
{
"1920_model" : {
"selector": "html > body > table > tbody > tr:nth-of-type(2) > td",
"type": "list",
}
}
And this is what the ScrapingBee API returns, with the whole table line for the 1920 model:
{
"1920_model": [
"1920",
"800",
"600"
]
}
How to track content changes comparing the entire page
Sometimes you just want to know if something has changed. You don’t need to know what exactly has changed.
In these cases, you can load the entire page in your API call.
You could use the ScrapingBee options to return the HTML version of a page. Then you save it and compare it with future versions.
But this isn’t ideal, as it would lead to a lot of false positives for content changes. For example, sites store images and scripts in CDNs. And in these cases, they can use a cached URL, with a random string in it. This means that any change in the cache will show up as a page update.
An alternative is to return the entire body of the page as text. So instead of crafting a specific CSS selector, you can return the entire page as text with this extract rule:
{
"content": "body"
}
Step 3: Compare the ScrapingBee’s results with Integromat’s storage
When you add modules to your scenario, they are connected with a few dots. Each of them has a little icon that you can use to create a filter.
Thus, you can decide if your data passes to the next module only if certain criteria are met.
In our case, you want to move to the next step only if the data store field doesn’t match the live site. You can do it with this filter:
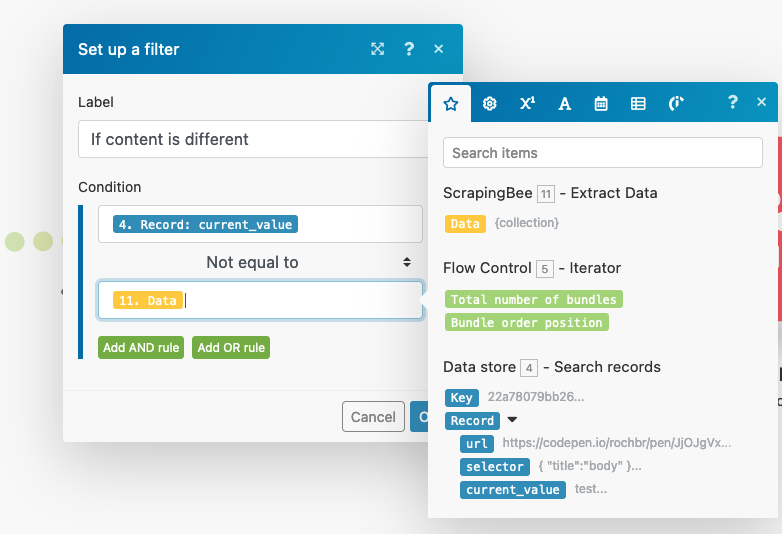
In this case, we are getting the entire ScrapingBee response and saving/comparing it. You can deal with multiple variables if you want, you just need to add a JSON parser module after ScrapingBee.
Besides, you can add a router in case you want to catch many scenarios. For example, you might want to perform a different action in case the content didn’t change. Or maybe you want to perform yet another action in case the current URL is a specific high-profile competitor.
Also, don’t forget to add a data store module to record the new values. This allows Integromat to load the correct current value in future scraping actions.
Step 4: Run an action
Now it’s your time to shine. You can do anything you want with this new information.
Here are some actions that you can run if there is a content update on your competitor's site:
- Add a task in Asana to manually check [page URL]
- Add a row in a Google Sheet with the competitor URL, content change, and date
- If it’s a high profile competitor, email John, so he can check the latest update
- Update our internal docs with new specs using the Google Docs module
- Open browser tab in your phone (using the Android or iOS modules) with the competitor’s URL
Then you just need to schedule this scenario in Integromat, in case you want to do it automatically.
🤖 Want more No-Code Web Scraping? Check out our guide on N8N Web Scraping
Conclusion
Today we looked into how to create a no-code app to monitor your competitors. With it, you can watch many competitors and content types. In addition, you can perform automated actions when there is new content.
We hope you’ve enjoyed it, and see you again next time!
Before you go, check out these related reads:


