If you've used Python Selenium for web scraping, you're familiar with its ability to extract data from websites. However, the default webdriver (ChromeDriver) often struggles to bypass the anti-bot mechanisms websites use to detect and block scrapers. With undetected_chromedriver, you can bypass some of today's most sophisticated anti-bot mechanisms, including those from Cloudflare, Akamai, and DataDome.
In this blog post, we’ll guide you on how to make your Selenium web scraper less detectable using undetected_chromedriver. We’ll cover its usage with proxies and user agents to enhance its effectiveness and troubleshoot common errors. Furthermore, we’ll discuss the limitations of undetected_chromedriver and suggest better alternatives.
Without further ado, let’s get started!
Tips for going undetected when webscraping
Web scraping can be frustrating when websites block your attempts. But by scraping responsibly, you can collect data efficiently and avoid disruptions caused by anti-bot measures. Here are some tips to stay under the radar while web scraping:
- Randomize request rate: Anti-scraping technologies can easily detect requests sent at a consistent interval. Real users don't browse websites at a constant rate. Introduce random delays between requests to mimic real user behavior and avoid detection. These delays should vary from a few seconds to several minutes.
- Rate limit: When scraping, be kind to the server you interact with. Bombarding a server with too many requests might lead to your scraper being blocked.
- Use proxies: When web scraping, if you're making a high number of requests from the same IP address, websites might recognize and block you. This is where proxies come in. Proxies allow you to use different IP addresses, making your requests seem like they're coming from various locations globally. This helps avoid detection and blocking.
- Captcha handling: Changing your IP address alone often isn't enough because of the common use of CAPTCHAs, tests that are easy for humans but hard for machines. CAPTCHAs usually appear for IP addresses that look suspicious. These tests can be bypassed using services like 2Captcha and Death by Captcha.
- Change user-agent: Although using a user agent can reduce your chances of getting blocked, sending too many requests from the same one can still trigger anti-bot systems. To avoid this, rotate through a list of browser user agents for scraping and keep them updated.
- Undetected webdriver: Leverage this optimized version of the standard ChromeDriver to bypass common anti-bot solutions like DataDome, PerimeterX, and Cloudflare.
In addition to the above tips, consider these other important points for website scraping. A detailed discussion is available in the blog “Web Scraping Without Getting Blocked (2026 Solutions)”.
🤖 Check out how undetected_chromedriver performs in headless mode vs other headless browsers when trying to go undetected by browser fingerprinting technology in our How to Bypass CreepJS and Spoof Browser Fingerprinting face-off.
Now, let's delve deeper into undetected_chromedriver in the following sections.
What is undetected_chromedriver and how does it work?
The Selenium Undetected ChromeDriver is an enhanced version of the standard ChromeDriver which is designed to bypass anti-bot services such as Cloudflare, Distill Network, Imperva, or DataDome.
Undetectable ChromeDriver is capable of patching most of the ways through which anti-bot systems can detect your Selenium bot or scraper. It enables your bot to appear more human-like as compared to a regular one.
Regular bots tend to leak a lot of information, which can be used by anti-bot systems to differentiate between an automated browser and a real user visiting the website.
Installation and configuration
You can install undetected_chromedriver using pip. First, create a virtual environment using venv to manage dependencies cleanly.
python -m venv myenv
myenv\Scripts\activate
Now, install the undetected_chromedriver using pip:
pip install undetected_chromedriver
Here’s what the process looks like:
If you do not have Selenium installed, it will be automatically added when you install the undetected_chromedriver.
Initializing undetected_chromedriver and launching the browser
Using the undetected_chromedriver in your code is straightforward. Just import the package and activate it with uc.Chrome().
import undetected_chromedriver as uc
driver = uc.Chrome()
driver.get("https://www.nowsecure.nl")
The uc.Chrome() downloads and patches the latest Chromedriver binary, which can then be used like regular Selenium Chromedriver.
When you run the below script, it will launch the Chrome browser in headless mode (headless=True) and then navigate to the target URL. To verify if it works successfully bypassing anti-bot protection, you can capture a screenshot of the loaded webpage.
import undetected_chromedriver as uc
import time
driver = uc.Chrome(headless=True)
driver.get("https://www.nowsecure.nl")
time.sleep(3)
driver.save_screenshot("image.png")
The results show that the Cloudflare protection has been successfully passed.

Target specific chrome version
If you want to specify your Chrome version instead of following the global version, you can use the uc.TARGET_VERSION method. Simply provide the Chrome version to this method before downloading the driver.
import undetected_chromedriver as uc
uc.TARGET_VERSION = 85
driver = uc.Chrome(headless=True)
driver.get("https://www.nowsecure.nl")
Proxies with undetected_chromedriver
You can make your scraper even more undetectable by using the undetected_chromedriver with proxies. Set the --proxy-server argument in ChromeOptions to use a different IP address for every page you load.
import undetected_chromedriver as uc
PROXY = "101.255.150.49:8089"
opts = uc.ChromeOptions()
opts.add_argument(f"--proxy-server={PROXY}")
driver = uc.Chrome(options=opts)
driver.get("https://www.nowsecure.nl")
Note that, free proxies are often unreliable and short-lived because they are public and used by many people, which can result in IP bans. On the other hand, premium proxies are well-maintained and sourced from reputable ISP providers, making them a better option for web scraping than data center IPs.
Scraping tools like ScrapingBee provide a pool of premium proxies, which allows you to scrape the target page with just one API call.
User-agent with undetected_chromedriver
Undetected ChromeDriver allows you to manipulate the user-agent. The default User Agent string used by Selenium is easily detectable as a bot. To overcome this, you can set a custom User Agent string. Here's how:
- Define a new User Agent string: Create a variable named
new_user_agentand assign your desired User Agent string to it. - Modify browser options: Use the
options.add_argumentmethod to add the custom User Agent string to the browser options.
Here’s the code:
import undetected_chromedriver as uc
# Define a custom user agent
agent = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36"
opts = uc.ChromeOptions()
opts.add_argument(f"user-agent={agent}")
driver = uc.Chrome(options=opts, headless=True)
driver.get("https://www.nowsecure.nl/")
driver.quit()
Drawbacks of undetected_chromedriver
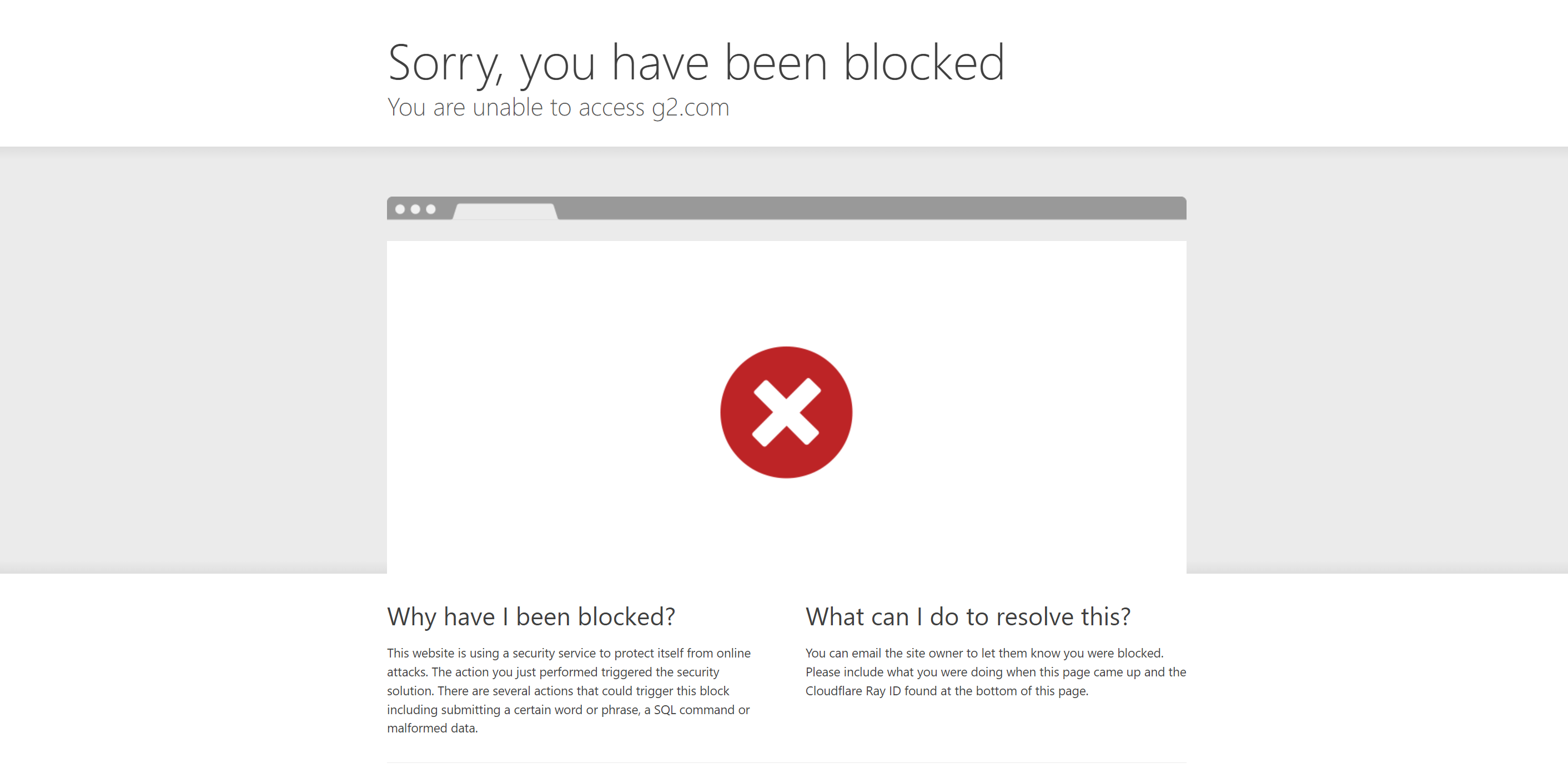
Undetected_chromedriver still struggles against advanced anti-bot systems. Here's an example of undetected_chromedriver being used against a Cloudflare-protected website, the G2 product review page:
import undetected_chromedriver as uc
import time
driver = uc.Chrome(headless=True)
driver.get("https://www.g2.com/products/anaconda/reviews")
time.sleep(4)
driver.save_screenshot("g2.png")
driver.quit()
Our scraper is instantly detected and blocked by G2's bot detection system, resulting in our failure to bypass it.
Moreover, many other issues need to be considered, such as stability. When running headless browsers like undetected_chromedriver at scale, it is common to encounter stability issues because they consume a lot of memory and can easily crash servers. Therefore, managing them at scale can be a significant challenge.
One of the major issues with open-source packages such as undetected_chromedriver is that anti-bot companies can detect how these packages bypass their anti-bot protection systems and easily fix the issues that they exploit. This leads to an ongoing arms race where these packages come up with new workarounds, and anti-bot companies patch these workarounds as well.
So, you’ve to choose a better solution that is effective in the long term. Let’s explore the alternative approaches in the next section.
Alternatives to undetected_chromedriver
If you are still blocked by websites, there are still alternatives. One such open-source alternative is nodriver, the official successor to the Python package undetected_chromedriver.
NoDriver is an asynchronous tool that replaces traditional components such as Selenium or webdriver binaries, providing direct communication with browsers. This approach not only reduces the detection rate by most anti-bot solutions but also significantly improves the tool's performance.
To get started with nodriver, you'll first need to install it using the following commands:
pip install nodriver
Here’s the sample code snippet:
import nodriver as uc
import time
async def main():
browser = await uc.start(headless=True)
page = await browser.get("https://www.nowsecure.nl")
time.sleep(4)
await page.save_screenshot("image.png")
if __name__ == "__main__":
uc.loop().run_until_complete(main())
This package has a unique feature that sets it apart from other similar packages - it is optimized to avoid detection by most anti-bot solutions. Its key features include:
- A fast and undetected Chrome automation library.
- No need for chromedriver binary or Selenium dependency.
- Can be set up and running in just one line of code.
- Uses a fresh profile for each run and cleans up on exit.
Since it is open source, there is a possibility that it may stop working with anti-bot systems in the future. Fortunately, web scraping APIs such as ScrapingBee have become the go-to solution for web scraping needs.
If you're looking for a simple and easy way to extract data from the web without being blocked or having to manage proxies or complex scraping rules, try using a web scraping API like ScrapingBee. Our tool simplifies the entire process by taking care of all the infrastructure and unblocking tactics so that you can focus solely on extracting the data you need.
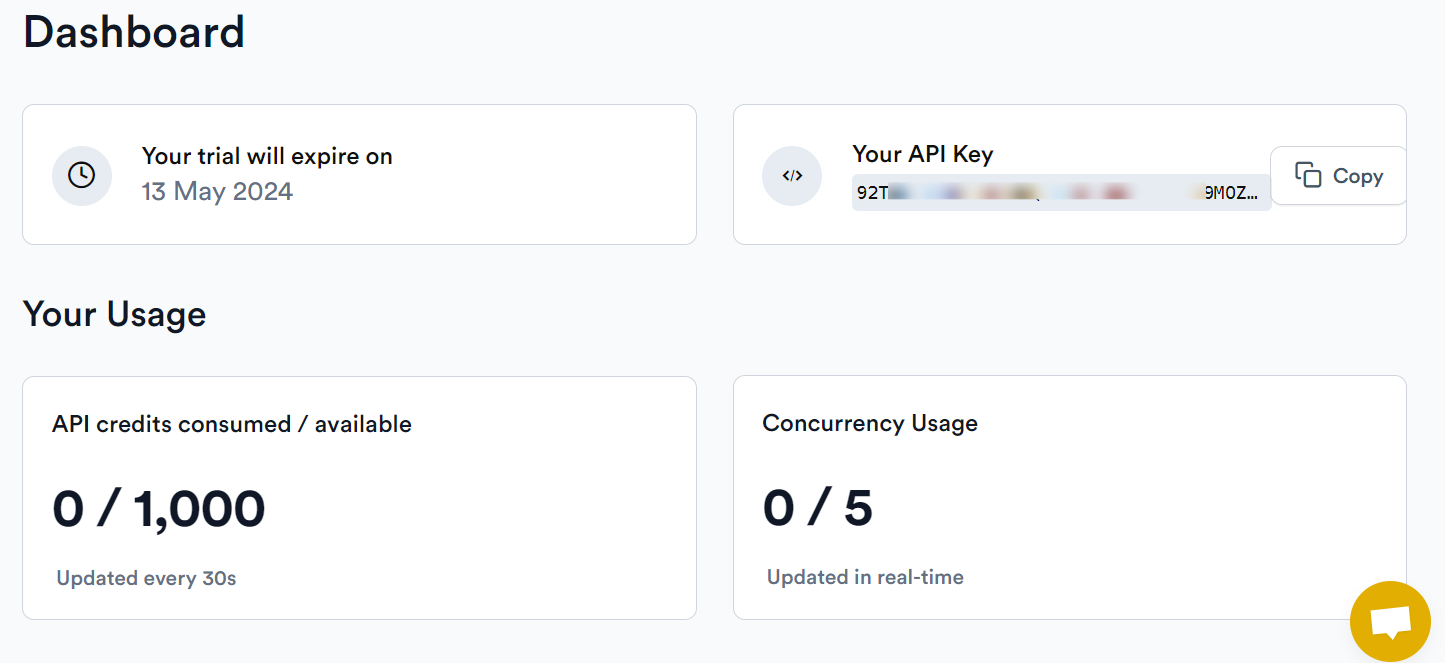
To start, sign up for a free ScrapingBee trial; no credit card is needed, and you'll receive 1000 credits to begin. Each request costs approximately 25 credits.
Upon logging in, navigate to your dashboard and copy your API key; you'll need this to send requests.
Next, install the ScrapingBee Python client:
pip install scrapingbee
You can use the below Python code to begin web scraping:
from scrapingbee import ScrapingBeeClient
client = ScrapingBeeClient(api_key="YOUR_API_KEY")
response = client.get(
"https://www.g2.com/products/anaconda/reviews",
params={
"stealth_proxy": True, # Use stealth proxies for more tough sites
"country_code": "gb",
"block_resources": True, # Block images and CSS to speed up loading
"device": "desktop",
"wait": "1500", # Milliseconds to wait before capturing data
# Optional screenshot settings:
# "screenshot": True,
# "screenshot_full_page": True,
},
)
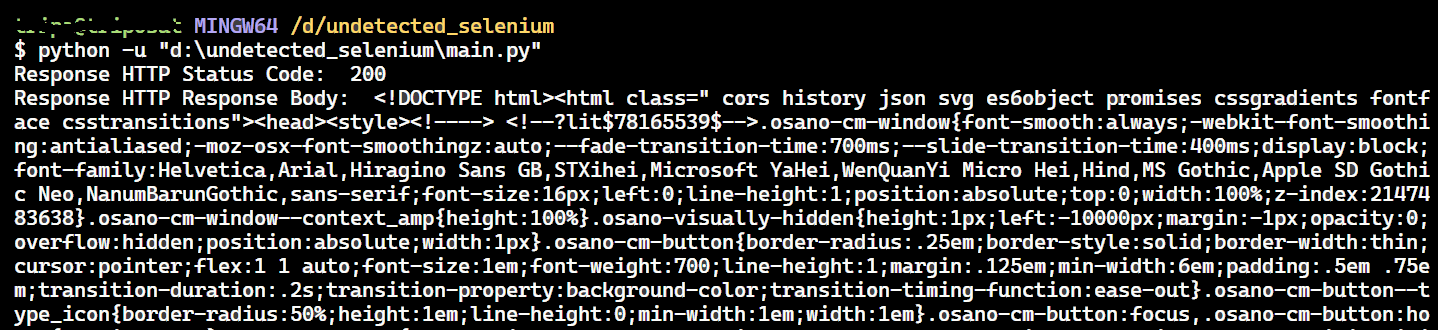
print("Response HTTP Status Code: ", response.status_code)
print("Response HTTP Response Body: ", response.text)
The status code 200 indicates that the G2 anti-bot has been bypassed.
Using a web scraping API like ScrapingBee saves you from dealing with various anti-scraping measures, making your data collection efficient and less prone to blocks.
Conclusion
This article explained how to use undetected_chromedriver for web scraping without getting blocked. Unlike Selenium WebDriver, undetected_chromedriver is more optimized and efficient at bypassing bot detection systems. However, there are still instances where it can fail. In such cases, ScrapingBee can be a great alternative.
Before you go, check out these related reads:
