Selenium is a popular browser automation library that allows you to control headless browsers programmatically. However, even with Selenium, your script can still be identified as a bot and your IP address can be blocked. This is where Selenium proxies come in.
A proxy acts as a middleman between the client and server. When a client makes a request through a proxy, the proxy forwards it to the server. This makes detecting and blocking your IP harder for the target site.
This article will explore setting up a rotating proxy in your Python Selenium script, authentication configuration, and error and timeout handling. We'll also discuss the best alternatives to rotating proxies in Python selenium.
Without further ado, let's get started!

TL:DR Selenium Rotating Proxy quick start code
If you're in a hurry, here's the code we'll be writing in this article. However, to follow along smoothly, make sure to install selenium and selenium-wire using the following commands first.
pip install selenium==4.17.2
pip install selenium-wire==5.1.0
Ensure that you replace the IP address and port number with your own and fill in your credentials correctly if required by your proxy server.
from selenium.webdriver.common.by import By
from seleniumwire import webdriver as wiredriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.common.exceptions import TimeoutException
from urllib3.exceptions import ProtocolError
import random
import time
def rotate_proxy():
# List of proxy IP addresses and ports
proxy_pool = ["191.96.100.33:3155",
"167.86.115.218:8888", "20.205.61.143:80"]
# Chrome options for headless browsing
chrome_options = Options()
chrome_options.add_argument("--headless")
# Number of retries for proxy rotation
retries = 3
for _ in range(retries):
random_proxy = random.choice(proxy_pool)
# Set up proxy authentication
proxy_username = "xyz"
proxy_password = "<secret-password>"
# Proxy options for both HTTP and HTTPS connections
proxy_options = {
"http": f"http://{proxy_username}:{proxy_password}@{random_proxy}",
"https": f"https://{proxy_username}:{proxy_password}@{random_proxy}",
}
try:
# Initialize Chrome driver with Selenium-Wire, using the random proxy
driver = wiredriver.Chrome(
service=ChromeService(ChromeDriverManager().install()),
seleniumwire_options={"proxy": proxy_options},
chrome_options=chrome_options,
)
# Visit a test site to verify the proxy connection
driver.get("http://httpbin.org/ip")
print(driver.find_element(By.TAG_NAME, "body").text)
driver.quit()
break # Proxy connection successful, exit loop
except (TimeoutException, ProtocolError) as e:
# Handle timeout or protocol error
print(f"Error occurred: {e}")
print(f"Retrying... ({retries - 1} retries left)")
retries -= 1
if retries == 0:
print("Maximum retries reached. Exiting...")
break
time.sleep(1)
finally:
# Ensure the driver is closed even if an exception occurs
if "driver" in locals():
driver.quit()
if __name__ == "__main__":
rotate_proxy()
🤖 Check out how Selenium performs in headless mode vs other headless browsers when trying to go undetected by browser fingerprinting technology in our How to Bypass CreepJS and Spoof Browser Fingerprinting face-off.
How to Set up Rotating Proxies in Selenium
During web scraping, I discovered that a single proxy's IP address can be blocked after a certain amount of activity. To avoid this and ensure efficient large-scale scraping, using a pool of proxies and continuously switching between them is necessary.
This constant change in IP address makes it hard for the server to identify and block you. By appearing like a new user each time, you can bypass restrictions and continue scraping effectively. This is the power of proxy rotation!
Prerequisites
Before you start, make sure you meet all the following requirements:
- Download the latest version of Python from the official website. For this blog, we’re using Python 3.12.2.
- Choose a code editor like Visual Studio Code, PyCharm, or Jupyter Notebook.
- Install the selenium and selenium-wire libraries. Selenium helps you automate web browser interaction, while selenium-wire makes it very easy to use proxies with Selenium.
Steps for Rotating Proxy
Let's see how proxy rotation is an excellent choice for scenarios where you need to avoid frequent IP-based restrictions by changing your IP address. Follow the steps below to set up rotating proxies.
Step 1. Choose a Reliable Proxy Provider
Select a reliable proxy provider that offers a list of rotating proxies. These proxies will assign a new IP address for each request or after a certain time interval.
Step 2. Obtain Credentials from the Proxy Provider
Obtain the necessary credentials from your chosen proxy provider. These credentials include the IP address, port, username (if applicable), and password to connect to the proxy server.
Step 3. Verify Connection (Optional)
Once you have the credentials, you can use tools like cURL or Python libraries such as requests to verify that you can connect to the proxy server and receive responses.
Step 4. Configure Chrome Options
Set up Chrome options by adding the --proxy-server argument and passing a random proxy from your working proxies list to this argument. After this, initialize the Chrome WebDriver with the configured options.
Step 5. Access the URL
Visit a test URL to verify that the WebDriver is using the proxy correctly. Print out the response to confirm the IP address associated with the proxy.
Great! You might not have understood the above steps clearly. Don't worry, let's see these steps in action in the further sections.
Adding Rotating Proxy to Selenium
When using Selenium, you can add a rotating proxy by defining a list of proxies and randomly selecting one for each web page visit. However, be cautious with free proxies, as they are often unreliable and short-lived. If you choose to proceed with free proxies, you'll need to test them individually to identify working ones for your web scraping tasks.
This is exactly what we do in the following code. The getProxies function will find all the relevant proxies according to set conditions, and the testProxy function will test and find the working proxies. Now in the rotateProxy function, we are using the --proxy-server argument and passing a random proxy from the list of working proxies.
Here’s the code:
from selenium.webdriver.chrome.options import Options
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
import random
from selenium.webdriver.common.by import By
import concurrent.futures
import requests
from bs4 import BeautifulSoup
def getProxies():
r = requests.get("https://free-proxy-list.net/")
soup = BeautifulSoup(r.content, "html.parser")
table = soup.find("tbody")
proxies = []
for row in table.find_all("tr"):
columns = row.find_all("td")
if columns[4].text.strip() == "elite proxy":
proxy = f"{columns[0].text}:{columns[1].text}"
proxies.append(proxy)
return proxies
def testProxy(proxy):
try:
r = requests.get(
"https://httpbin.org/ip", proxies={"http": proxy, "https": proxy}, timeout=5
)
r.raise_for_status() # Raises HTTPError if the response status code is >= 400
return proxy
except requests.exceptions.RequestException:
return None
def rotateProxy(working_proxies):
if not working_proxies:
print("No working proxies found.")
return
random_proxy = random.choice(working_proxies)
print(f"Rotating to proxy: {random_proxy}")
options = Options()
options.add_argument("--headless")
options.add_argument(f"--proxy-server={random_proxy}")
driver = webdriver.Chrome(
service=ChromeService(ChromeDriverManager().install()),
options=options,
)
driver.get("http://httpbin.org/ip")
print(driver.find_element(By.TAG_NAME, "body").text)
driver.quit()
def main():
proxies = getProxies()
working_proxies = []
with concurrent.futures.ThreadPoolExecutor() as executor:
results = executor.map(testProxy, proxies)
for result in results:
if result is not None:
working_proxies.append(result)
num_working_proxies = len(working_proxies)
print(f"Found {num_working_proxies} working proxies.")
rotateProxy(working_proxies)
if __name__ == "__main__":
main()
Here’s the result:
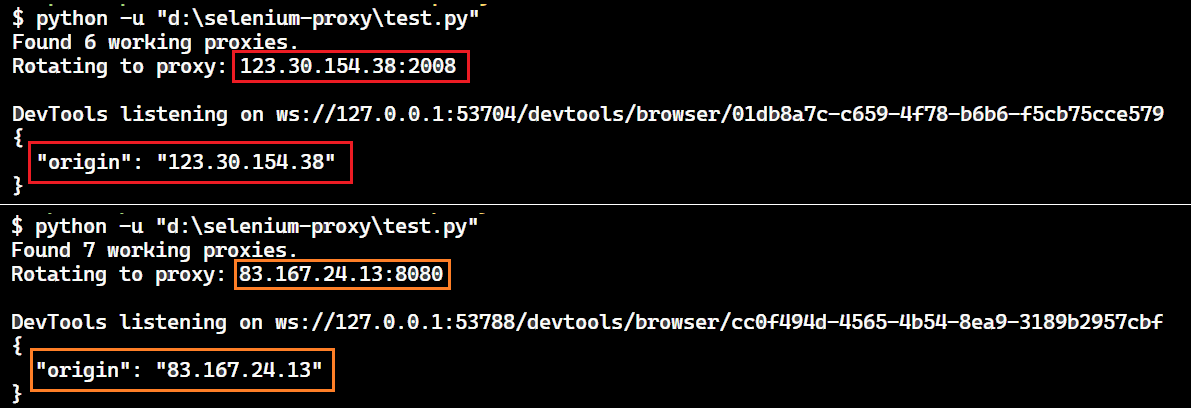
We successfully confirmed that Selenium is using a random proxy by matching the rotated IP address with the one from the web page response.
By rotating proxies, I was able to scrape data from various websites at scale without getting IP banned.
Here are some guidelines to help you determine how often you should rotate your proxies:
- Adapting to Anti-Scraping Measures: If a website has more aggressive anti-scraping measures, you should rotate your proxies more frequently, ideally with every request or every few requests. However, you can rotate your proxies every few minutes for websites with less strict anti-scraping measures.
- Proxy Pool Size: The size of your proxy pool also determines how often you should rotate your proxies. If you’ve a larger pool of high-quality proxies, you can rotate them less frequently. But if you’ve a smaller pool, you’ll need to rotate them more often to avoid reusing the same ones.
- Data Volume and Complexity: If you're scraping a large amount of data or performing complex tasks, you may need to rotate your proxies more frequently to avoid triggering anti-scraping mechanisms.
Configuring Authentication
Some proxy servers require authentication, restricting access only to users with valid credentials. This ensures that only authorized users can connect to the server. This is typically the case with commercial proxy services or premium proxies. The proxy URL in these cases will look something like this:
<PROXY_PROTOCOL>://<USERNAME>:<PASSWORD>@<PROXY_IP_ADDRESS>:<PROXY_PORT>
Note that when using a URL in the --proxy-server command, the Chrome driver ignores the username and password by default. However, there is a third-party plugin called Selenium Wire that can help with this issue. It provides advanced features such as proxy management with authentication, request interception, and modification, which can help resolve this problem.
First, you need to install Selenium Wire using pip:
pip install selenium-wire
Update your scraper to use the seleniumwire webdriver instead of the default selenium webdriver.
from seleniumwire import webdriver as wiredriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
import random
def rotateProxy():
proxy_pool = [
"191.96.100.33:3155",
"146.190.53.175:32782",
"167.86.115.218:8888",
"20.205.61.143:80",
]
chrome_options = Options()
chrome_options.add_argument("--headless")
random_proxy = random.choice(proxy_pool)
# Set up selenium-wire with the proxy
proxy_username = "xyz"
proxy_password = "<secret-password>"
proxy_options = {
"http": f"http://{proxy_username}:{proxy_password}@{random_proxy}",
"https": f"https://{proxy_username}:{proxy_password}@{random_proxy}",
}
driver = wiredriver.Chrome(
service=ChromeService(ChromeDriverManager().install()),
seleniumwire_options={"proxy": proxy_options},
chrome_options=chrome_options,
)
driver.get("http://httpbin.org/ip")
print(driver.find_element(By.TAG_NAME, "body").text)
driver.quit()
if __name__ == "__main__":
rotateProxy()
When you first run the code using Selenium Wire, you might encounter an error similar to the one described below.

To resolve this, you need to install the certificate in Chrome. You can extract the certificate using the command. Learn more about it here.
python -m seleniumwire extractcert
Note: If your credentials are invalid, the proxy server will respond with a [407: Proxy Authentication Required](https://developer.mozilla.org/en-US/docs/Web/HTTP/Status/407) error, and your Python Selenium script will fail with an ERR_HTTP_RESPONSE_CODE_FAILURE error. Ensure you use valid username and password credentials.
Handling Errors and Timeouts
While scraping web pages using rotating proxies, you need to handle invalid proxies and timeouts to prevent your program from crashing. Here are the steps to follow:
- Wrap your scraping code in a
try-catchblock. This catches any errors that might occur during the scraping process, including those related to invalid proxies or timeouts - Implement a retry mechanism for failed proxy connections. If a connection attempt fails, try with another proxy from your pool up to a certain number of attempts.
- Set appropriate timeouts for different operations, like page navigation and HTTP requests.
Here's the code for handling errors and retrying failed proxy connections (up to 3 times).
from selenium.webdriver.common.by import By
from seleniumwire import webdriver as wiredriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.common.exceptions import TimeoutException
from urllib3.exceptions import ProtocolError
import random
import time
def rotate_proxy():
proxy_pool = [
"191.96.100.33:3155",
"146.190.53.175:32782",
"167.86.115.218:8888",
"20.205.61.143:80",
]
chrome_options = Options()
chrome_options.add_argument("--headless")
retries = 3
for _ in range(retries):
random_proxy = random.choice(proxy_pool)
# Set up selenium-wire with the proxy
proxy_username = "xyz"
proxy_password = "<secret-password>"
proxy_options = {
"http": f"http://{proxy_username}:{proxy_password}@{random_proxy}",
"https": f"https://{proxy_username}:{proxy_password}@{random_proxy}",
}
try:
driver = wiredriver.Chrome(
service=ChromeService(ChromeDriverManager().install()),
seleniumwire_options={"proxy": proxy_options},
chrome_options=chrome_options,
)
driver.set_page_load_timeout(10) # Set a timeout for page loading
driver.get("http://httpbin.org/ip")
print(driver.find_element(By.TAG_NAME, "body").text)
driver.quit()
break # Proxy connection successful, exit loop
except (TimeoutException, ProtocolError) as e:
print(f"Error occurred: {e}")
print(f"Retrying... ({retries - 1} retries left)")
retries -= 1
if retries == 0:
print("Maximum retries reached. Exiting...")
break
time.sleep(1)
finally:
if "driver" in locals():
driver.quit()
if __name__ == "__main__":
rotate_proxy()
Note: The free proxies used in this blog are unreliable, short-lived, and can quickly become outdated. However, we’ll explore a better alternative.
Alternatives to rotating proxies in Python Selenium
To simplify your web scraper and achieve scalability, you might want to get rid of the infrastructure headaches and just focus on the data extraction. ScrapingBee API offers a solution that allows you to scrape the target page with just one API call.
ScrapingBee offers a fresh pool of proxies that can handle even the most challenging websites. To use this pool, you simply need to add stealth_proxy=True to your API calls. The ScrapingBee Python SDK makes it easier to interact with ScrapingBee's API.
Don't forget to replace "Your_ScrapingBee_API_Key" with your actual API key, which you can retrieve from here.
Before using an SDK, we’ll have to install the SDK. And we can do that using this command:
pip install scrapingbee
Here’s the quick start code:
from scrapingbee import ScrapingBeeClient
client = ScrapingBeeClient(
api_key="Your_ScrapingBee_API_Key"
)
response = client.get(
"https://author.today/",
params={
"stealth_proxy": "True",
},
)
print(response.status_code)
The snippet would return a status code of 200. Fantastic!
💡Interested in rotating proxies in other languages, check out our guide on Rotating proxies in Puppeteer.
Wrapping Up
You've learned about Selenium proxies, how to rotate them with Selenium, how to handle authenticated proxies, and how to deal with invalid proxies and timeouts. Finally, you've explored why free proxies are a bad idea and learned about alternative solutions.

