Puppeteer is a popular headless browser used with Node.js for web scraping. However, even with Puppeteer, your IP can get blocked if your script is identified as a bot. That's where the Puppeteer proxy comes in.
A proxy acts as a middleman between the client and server. When a client makes a request through a proxy, the proxy forwards it to the server. This makes detecting and blocking your IP harder for the target site.
In this article, we'll explore how to set up a rotating proxy in your Node.js Puppeteer script, which includes authentication configuration, error and timeout handling, and advanced proxy configurations like proxy chaining. We'll also discuss the best alternatives to rotating proxies in Puppeteer.
Without further ado, let's get started!

TL:DR Puppeteer Rotating Proxy quick start code
If you're in a hurry, here's the code we'll write in this tutorial. However, to follow along, make sure to install puppeteer and proxy-chain using the following commands first.
npm install puppeteer@22.0.0
npm install proxy-chain@2.4.0
Be sure to replace the IP address and port number with your own.
const puppeteer = require('puppeteer');
const proxyChain = require('proxy-chain');
// Array of proxy server URLs
const proxyUrls = [
'http://20.210.113.32:80',
'http://43.132.172.26:3128',
// Add more proxy URLs here
];
// Function to fetch data using a random proxy
async function fetchData() {
const maxRetries = 3; // Maximum number of retries
let currentRetry = 0;
let anonymizedProxyUrl;
// Loop until maximum retries are reached
while (currentRetry < maxRetries) {
try {
// Select a random proxy URL
const randomProxyUrl = proxyUrls[Math.floor(Math.random() * proxyUrls.length)];
// Anonymize the proxy
anonymizedProxyUrl = await proxyChain.anonymizeProxy({
url: randomProxyUrl
});
// Launch Puppeteer with the anonymized proxy
const browser = await puppeteer.launch({
args: [`--proxy-server=${anonymizedProxyUrl}`]
});
const page = await browser.newPage();
// Handle request failures
page.on('requestfailed', request => {
console.error(`Request failed: ${request.url()}`);
});
const timeout = 30000; // Timeout for page navigation
await page.goto('https://httpbin.org/ip', { timeout });
// Wait for body element to be present
const bodyElement = await page.waitForSelector('body');
const ipText = await bodyElement.getProperty('textContent');
const ipAddress = await ipText.jsonValue();
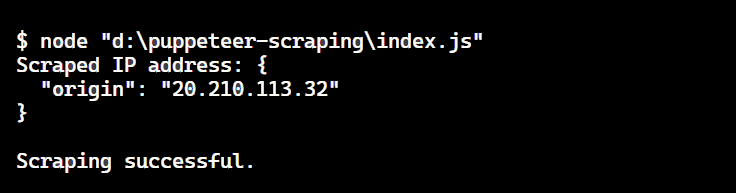
console.log('Scraped IP address:', ipAddress);
await browser.close();
console.log('Scraping successful.');
return; // Exit the function after successful scraping
} catch (error) {
console.error('Error during scraping:', error);
currentRetry++; // Increment retry count
} finally {
// Close the anonymized proxy after each attempt
if (anonymizedProxyUrl) {
await proxyChain.closeAnonymizedProxy(anonymizedProxyUrl);
}
}
}
console.error('Scraping failed after multiple retries.');
process.exit(); // Exit the process after all retries are exhausted
}
fetchData();
The result is:
🤖 Check out how Pyppeteer performs vs other headless browsers when trying to go undetected by browser fingerprinting technology in our How to Bypass CreepJS and Spoof Browser Fingerprinting face-off.
How to Set up Rotating Proxies in Puppeteer
While scraping the web, I soon realized that a single proxy's IP address gets blocked after some scraping activity. Therefore, to avoid getting blocked and scraping effectively at scale, I need to use a pool of proxies and switch them continuously.
This is what proxy rotation is all about. In short, proxy rotation involves changing proxies after a specified time interval or a certain number of requests, making it difficult for the server to track you.
Prerequisites
Before you start, make sure you meet all the following requirements:
- Download the latest version of NodeJS from the official website. For this blog, we’re using NodeJS v20.9.0.
- Choose a code editor, such as Visual Studio Code.
- Initialize a NodeJS project and add the
puppeteernpm package to its dependencies.
npm install puppeteer@22.0.0
Steps for Rotating Proxy
Let's see how proxy rotation is an excellent choice for scenarios where you need to change your IP address to avoid IP-based restrictions frequently. Follow the steps below to set up rotating proxies.
Step 1. Choose a Reliable Proxy Provider
Select a reliable proxy provider that offers a list of proxies. These proxies will assign a new IP address for each request or after a certain time interval.
Step 2. Obtain Credentials from the Proxy Provider
Obtain the necessary credentials from your chosen proxy provider, including the IP address, port, username, and password, to connect to the proxy server.
Step 3. Verify Connection (Optional)
Once you’ve the credentials, you can use tools like cURL to verify that you can connect to the proxy server and receive responses. This is an optional step before integrating the proxy server with Puppeteer.
Step 4. Select a Proxy for Each Puppeteer Launch
For each Puppeteer launch, select one proxy URL randomly from the list of proxies provided by the chosen provider.
Step 5. Use the --proxy-server Argument
Pass the selected proxy URL to the --proxy-server argument when launching Puppeteer.
Adding Rotating Proxy to Puppeteer
To use a proxy with Puppeteer, use the puppeteer.launch() function and specify the proxy server's IP address and port using the --proxy-server argument.
const puppeteer = require('puppeteer');
const proxyUrls = [
'http://20.210.113.32:80',
'http://43.132.172.26:3128',
// Add more proxy URLs here
];
async function fetchData() {
const randomProxyUrl = proxyUrls[Math.floor(Math.random() * proxyUrls.length)];
const browser = await puppeteer.launch({
args: [`--proxy-server=${randomProxyUrl}`]
});
const page = await browser.newPage();
await page.goto('https://httpbin.org/ip');
const bodyElement = await page.waitForSelector('body');
const ipText = await bodyElement.getProperty('textContent');
const ipAddress = await ipText.jsonValue();
console.log(ipAddress);
await browser.close();
}
fetchData();
In the code, we’ve defined an array named proxyServers, containing URLs of proxy servers. Within the fetchData function, a random proxy server URL is selected from the proxyServers array using math.random() and math.floor(). Then, the launch() function is called with the randomly selected proxy server URL.
By rotating residential proxies, I was able to scrape data from various websites at scale without getting IP banned.
Here are some guidelines to help you determine how often you should rotate your proxies:
- Adapting to Anti-Scraping Measures: If a website has more aggressive anti-scraping measures, you should rotate your proxies more frequently, ideally with every request or every few requests. However, for websites with less strict anti-scraping measures, you can rotate your proxies every few minutes.
- Proxy Pool Size: The size of your proxy pool also determines how often you should rotate your proxies. If you’ve a larger pool of high-quality proxies, you can rotate them less frequently. But if you’ve a smaller pool, you’ll need to rotate them more often to avoid reusing the same ones.
- Data Volume and Complexity: If you're scraping a large amount of data or performing complex tasks, you may need to rotate your proxies more frequently to avoid triggering anti-scraping mechanisms.
Configuring Authentication
Many premium proxy services require Puppeteer authentication. This ensures that only authorized users connect to their servers. The proxy URL in such cases looks like this:
<PROXY_PROTOCOL>://<USERNAME>:<PASSWORD>@<PROXY_IP_ADDRESS>:<PROXY_PORT>
However, chrome ignores username and password information embedded directly in the proxy URL. To address this, Puppeteer provides the authenticate() method for basic HTTP authentication with proxies.
await page.authenticate({ username: 'abc', password: '<secret-pasword>'});
Here is the code:
const puppeteer = require('puppeteer');
const proxyUrls = [
'http://20.210.113.32:80',
'http://43.132.172.26:3128',
// Add moreteer.launch({
args: [`--proxy-server=${randomProxyUrl}`]
});
const page = await browser.newPage();
await page.authenticate({
username: proxyUsername,
password: proxyPassword,
});
await page.goto('https://httpbin.org/ip');
const bodyElement = await page.waitForSelector('body');
const ipText = await bodyElement.getProperty('textContent');
const ipAddress = await ipText.jsonValue();
console.log(ipAddress);
await browser.close();
}
fetchData();
Note: If your credentials are invalid, the proxy server will respond with a 407: Proxy Authentication Required error, and your Puppeteer script will fail with an ERR_HTTP_RESPONSE_CODE_FAILURE error. Ensure you use valid username and password credentials.
Handling Errors and Timeouts
While scraping web pages using rotating proxies, you need to handle invalid proxies and timeouts to prevent your program from crashing. Here are the steps to follow:
- Wrap your scraping code in a
try-catchblock. This catches any errors that might occur during the scraping process, including those related to invalid proxies or timeouts - Implement a retry mechanism for failed proxy connections. If a connection attempt fails, try with another proxy from your pool up to a certain number of attempts.
- Set appropriate timeouts for different operations, like page navigation and HTTP requests. Adjust these timeouts based on typical response times and your network conditions.
Here's the code for handling errors and retrying failed proxy connections (up to 3 times).
const puppeteer = require('puppeteer');
const proxyUrls = [
'http://20.210.113.32:80',
'http://43.132.172.26:3128',
// Add more proxy URLs here
];
async function fetchData() {
const maxRetries = 3; // Maximum number of retries
let currentRetry = 0;
while (currentRetry < maxRetries) {
try {
const proxyUsername = 'abc';
const proxyPassword = '<secret-password>';
const randomProxyUrl = proxyUrls[Math.floor(Math.random() * proxyUrls.length)];
const browser = await puppeteer.launch({
args: [`--proxy-server=${randomProxyUrl}`]
});
const page = await browser.newPage();
// Authenticate with proxy server
await page.authenticate({
username: proxyUsername,
password: proxyPassword
});
page.on('requestfailed', request => {
console.error(`Request failed: ${request.url()}`);
});
// Set timeout for the page load
const timeout = 30000; // 30 seconds
await page.goto('https://httpbin.org/ip', { timeout });
const bodyElement = await page.waitForSelector('body');
const ipText = await bodyElement.getProperty('textContent');
const ipAddress = await ipText.jsonValue();
console.log(ipAddress);
await browser.close();
console.log('Scraping successful.');
return; // Exit the function after successful scraping
} catch (error) {
console.error('Error during scraping:', error);
// Retry with another proxy
currentRetry++;
}
}
console.error('Scraping failed after multiple retries.');
}
fetchData()
Proxy Chaining
The proxy-chain module is used to manage proxies, particularly for anonymizing and chaining them together. It launches an intermediary local proxy server through which you can route your Puppeteer requests.
Install the proxy-chain using the following command:
npm install proxy-chain@2.4.0
Here is the code:
const puppeteer = require('puppeteer');
const proxyChain = require('proxy-chain');
const proxyUrls = [
'http://20.210.113.32:80',
'http://43.132.172.26:3128',
// Add more proxy URLs here
];
async function fetchData() {
const maxRetries = 3;
let currentRetry = 0;
let anonymizedProxyUrl;
while (currentRetry < maxRetries) {
try {
const randomProxyUrl = proxyUrls[Math.floor(Math.random() * proxyUrls.length)];
anonymizedProxyUrl = await proxyChain.anonymizeProxy({
url: randomProxyUrl
});
const browser = await puppeteer.launch({
args: [`--proxy-server=${anonymizedProxyUrl}`]
});
const page = await browser.newPage();
page.on('requestfailed', request => {
console.error(`Request failed: ${request.url()}`);
});
const timeout = 30000;
await page.goto('https://httpbin.org/ip', { timeout });
const bodyElement = await page.waitForSelector('body');
const ipText = await bodyElement.getProperty('textContent');
const ipAddress = await ipText.jsonValue();
console.log('Scraped IP address:', ipAddress);
await browser.close();
console.log('Scraping successful.');
return;
} catch (error) {
console.error('Error during scraping:', error);
currentRetry++;
} finally {
if (anonymizedProxyUrl) {
await proxyChain.closeAnonymizedProxy(anonymizedProxyUrl);
}
}
}
console.error('Scraping failed after multiple retries.');
}
fetchData();
The proxyChain.anonymizeProxy() function anonymizes the original proxy URL by generating a new one that hides the source, providing an extra layer of anonymity. This anonymized URL is then passed to Puppeteer as an argument when launching a new browser instance. Puppeteer uses this proxy to route all network requests.
After Puppeteer operations are completed and the browser instances are closed, proxyChain.closeAnonymizedProxy() is called to close the proxy server associated with the anonymized URL. This ensures resources are released efficiently and connections are terminated.
Note: The free proxies used in this blog are unreliable, short-lived, and can quickly become outdated. However, we’ll explore a better alternative.
Alternatives to rotating proxies in Puppeteer
To simplify your web scraper and achieve scalability, you might want to get rid of the infrastructure headaches and just focus on the data extraction. ScrapingBee API offers a solution that allows you to scrape the target page with just one API call.
It provides a fresh pool of proxies that can handle even the most challenging websites. All the proxy rotation and headless Chrome rendering are already handled on the API side, so you can just focus on what you want to achieve - extracting the data.
To use this pool, you simply need to add stealth_proxy=True to your API calls. The ScrapingBee NodeJS SDK makes it easier to interact with the ScrapingBee API. Don't forget to replace "Your_ScrapingBee_API_Key" with your actual API key, which you can retrieve from here.
Before using an SDK, we’ll have to install the SDK. And we can do that using this command:
npm install scrapingbee
Here’s the quick start code:
const scrapingbee = require('scrapingbee');
const puppeteer = require('puppeteer');
async function getScreenshot(url) {
var client = new scrapingbee.ScrapingBeeClient('YOUR_SCRAPINGBEE_API_KEY');
try {
const browser = await puppeteer.launch();
const page = await browser.newPage();
const response = await client.get({
url: url,
params: {
'stealth_proxy': 'True',
},
});
const text = new TextDecoder().decode(response.data);
await page.setContent(text, "html");
await page.screenshot({ path: 'screenshot.png' });
console.log('Screenshot saved as screenshot.png');
await browser.close();
} catch (e) {
console.error('Error:', e);
}
}
getScreenshot('https://www.g2.com/products/gitlab/reviews');
The result is:
💡Interested in rotating proxies in other languages, check out our guide on Rotating proxies in Python with Selenium.
Wrapping Up
You've learned what a Puppeteer proxy is, how to use rotating proxies in Puppeteer, handle authenticated proxies, deal with invalid proxies and timeouts, and configure Puppeteer for advanced techniques like proxy chaining. Finally, you've explored why free proxies are a bad idea and discovered an alternative solution: making a single API call to scrape data at scale without getting blocked.


