Web scraping, or crawling, is the process of fetching data from a third-party website by downloading and parsing the HTML code to extract the data you need.
"But why don't you use the API for this?"
Not every website offers an API, and those that do might not expose all the information you need. Therefore, scraping often becomes the only viable solution to extract website data.
There are numerous use cases for web scraping:
- E-commerce price monitoring
- News aggregation
- Lead generation
- SEO (search engine result page monitoring)
- Bank account aggregation (Mint in the US, Bankin' in Europe)
- Individuals and researchers building datasets otherwise unavailable
The primary challenge is that most websites do not welcome scraping and will attempt to block it. They prefer serving content to real users on actual web browsers—except when it comes to Google, as these sites generally accommodate Google's scrapers because they want to appear in Google's search results. Thus, when scraping, it's crucial to avoid detection as a robot. There are two main strategies to appear human-like: using human-like tools and emulating human behavior.
This post will guide you through the various tools websites use to block scraping and the strategies you can employ to successfully overcome these anti-bot barriers.
Web scraping without getting blocked 2025 best solution
If you're seeking a straightforward way to scrape web data without getting blocked and the hassle of managing proxies yourself or handling complex scraping rules, consider using a web scraping API like ScrapingBee. Our tool simplifies the entire process by managing all the infrastructure and unblocking tactics, letting you focus purely on extracting the data you need.
To start, sign up for a free ScrapingBee trial; no credit card is needed, and you'll receive 1000 credits to begin. Each request costs approximately 25 credits.
Upon logging in, navigate to your dashboard and copy your API token; you'll need this to send requests.
Next, install the ScrapingBee Python client:
pip install scrapingbee
Alternatively, you can add it to your project's dependencies if you are using a tool like Poetry:
scrapingbee = "^2.0"
Now, you're ready to use the following Python snippet to start scraping:
from scrapingbee import ScrapingBeeClient
client = ScrapingBeeClient(api_key="YOUR_API_KEY")
response = client.get(
YOUR_URL_HERE,
params={
'premium_proxy': True, # Use premium proxies for tough sites
'country_code': 'gb',
"block_resources": True, # Block images and CSS to speed up loading
'device': 'desktop',
"wait": "1500", # Milliseconds to wait before capturing data
'js_scenario': {
"instructions": [ # Automate interactions with the webpage
{"wait_for": "#slow_button"},
{"click": "#slow_button"},
{"scroll_x": 1000},
{"wait": 1000},
{"scroll_x": 1000},
{"wait": 1000},
]
},
headers={"key": "value"}, # Custom headers
cookies={"name": "value"} # Custom cookies
# Optional screenshot settings:
# "screenshot": True,
# "screenshot_full_page": True,
}
)
print(response.content)
This script utilizes ScrapingBee's capabilities to manage proxies, headers, and cookies, as well as to execute dynamic interactions with JavaScript-heavy sites. For more advanced scraping projects, you might also consider leveraging the ScrapingBee integration with Scrapy.
Using a web scraping API like ScrapingBee saves you from dealing with various anti-scraping measures, making your data collection efficient and less prone to blocks.
Check out our dedicated tutorials on how to unblock and bypass different anti-scraping technology
Tips for web scraping without getting blocked
1. Use proxies
When web scraping, if you're making a high number of requests from the same IP address, websites might recognize and block you. This is where proxies come in. Proxies allow you to use different IP addresses, making your requests seem like they're coming from various locations globally. This helps avoid detection and blocking.
While proxies are relatively affordable, around $1 per IP, costs can escalate if you're making tens of thousands of requests daily. Frequent monitoring is necessary since proxies can often become inactive, requiring replacements.
Rotate your proxies
Detecting patterns in IP addresses is a common way websites identify and block scrapers. By using IP rotation services like ScrapingBee, you can distribute your requests across a pool of IPs. This masks your real IP and makes your scraping activity look more like regular user behavior. Although most websites can be scraped using this method, some with sophisticated detection systems might require residential proxies.
Check out our guides on how to set up a Rotating Proxy in both Selenium and Puppeteer.
Use residential/stealth proxies
Residential proxies are IP addresses provided by internet service providers to homeowners, making them seem like typical user IPs. They are less likely to be identified and blocked compared to data center proxies. For tasks that require higher security and less detectability, consider using stealth proxies, which are designed to be undetectable as proxies. These are especially useful for scraping websites with aggressive anti-scraping measures.
Another world of networking not to miss would be the mobile world. Mobile 3G and 4G proxies run off of IP address blocks assigned to mobile network operators and offer a beautiful native-like approach for any sites and services which cater predominantly to mobile-first or mobile-only users.
Create your own proxies
Setting up your own proxies can be an efficient solution, and CloudProxy is a robust tool for this. It's a Docker image that lets you manage cloud-hosted proxies across platforms like AWS and Google. These custom proxies, although based in data centers, can use ISP-based addresses to mimic typical user behavior more closely, enhancing your scraping activities' stealth.
Manage your proxies in one place
While many services offer proxy management, paid options like Scrapoxy and SmartProxy are generally more reliable than free proxies, which are often slow and quickly blocked. Paid proxies provide quality and reliability essential for effective web scraping.
Remember, the quality of your proxies significantly impacts your scraping success, making investment in a good proxy service worthwhile. Check out our comprehensive list of rotating proxy providers.
2. Use a headless browser
Headless browsers are an ideal solution for interacting with webpages that employ JavaScript to unlock or reveal content. They operate like regular browsers but without a graphical user interface, allowing you to automate and manipulate webpage interactions programmatically.
How do headless browsers work?
Headless browsers are essentially full browsers stripped of their user interface. They are able to render web pages and execute JavaScript just like regular browsers but are operated entirely through scripts. This means they can programmatically navigate pages, interact with DOM elements, submit forms, and even capture screenshots without needing a visible UI.
This capability makes them highly effective for web scraping because they can accurately emulate human user interactions on a webpage. This includes complex tasks like dealing with AJAX-loaded content, handling cookies, and managing sessions. They also handle SSL certificates and execute complex JavaScript-heavy sites, which might otherwise be inaccessible through simpler HTTP requests.
The power of headless browsers lies in their ability to be scripted and controlled remotely, allowing for automation of web interactions at scale. Additionally, they offer more precise control over the browsing context, such as setting custom user agents, manipulating the viewport size, and even spoofing geolocations, which can be crucial for testing geo-specific or responsive designs.
Their ability to seamlessly integrate with various programming environments and frameworks adds to their versatility, making them a preferred choice for developers needing to automate testing or perform extensive web scraping while mimicking real user behaviors.
Camoufox
Camoufox is a stealthy, minimalistic, custom build of Firefox designed specifically for web scraping. Unlike traditional automation tools that rely on Chromium-based browsers, Camoufox leverages Firefox’s flexibility to remain undetectable by anti-bot systems. It includes built-in fingerprint spoofing, stealth patches, and proxy support, making it a powerful tool for scraping highly protected websites. Since it is fully compatible with the Playwright API, transitioning existing Playwright scripts to Camoufox requires minimal effort. If you need an anti-bot solution that bypasses browser fingerprinting tools like CreepJS, Camoufox is one of the most effective choices available. Check out our expert level Camoufox tutorial
Selenium
Selenium is a powerful tool for automating browsers. It supports a wide array of browsers and provides a comprehensive API for all kinds of testing and scraping tasks. For more information on how to utilize Selenium for web scraping, check out our detailed Selenium tutorial and learn about its R integration with RSelenium.
Check out our guide on a fortified version of Selenium's chrome driver called undetected_chromedriver which is designed to try and bypass anti-bot tech, but for more up-to-date anti-bot tech go with Nodriver, undetected_chromedriver's official successor.
Playwright
Playwright is another excellent choice for web scraping and automation. It supports multiple browsers and offers robust features for handling modern web applications. Learn more about webscraping with Playwright.
Puppeteer
Puppeteer is a Node.js library that provides a high level of control over Chrome or Chromium. Puppeteer is ideal for tasks that require manipulating web pages that heavily rely on JavaScript. Enhance your Puppeteer usage with Puppeteer Stealth and learn about setting up rotating proxies in Puppeteer.
Cloudscraper
Cloudscraper, a Python library specifically designed to bypass Cloudflare's anti-bot measures, allows scraping of Cloudflare-protected sites effectively. Check out our comprehensive tutorial on how to use Cloudscraper.
Nodriver
Nodriver offers a fast and flexible solution for web automation and scraping without relying on WebDriver or Selenium. It's designed for high-speed operations and minimal setup.
Although using these tools on a local computer is straightforward, scaling them for larger projects can pose challenges. For scalable web scraping solutions that offer smooth, natural browsing behavior, consider using a service like ScrapingBee.
💡 Check out our tutorial on How to bypass cloudflare antibot technology at scale.
3. Understand browser fingerprinting
Web developers know that different browsers can act differently. This could be in how they show CSS, run JavaScript, or even in smaller details. Because these differences are well-known, it's possible to check if a browser is really what it says it is. In simple terms, a website can check if a browser's features and actions match what the browser claims to be.
This knowledge leads to a constant battle between web scrapers trying to look like real browsers and websites trying to spot these fake browsers. Usually, web scrapers have the advantage. Here's why:
Often, JavaScript code tries to find out if it's running in a fake browser mode, mostly to avoid detection by anti-malware systems. In these situations, the JavaScript will behave harmlessly in a test environment but will perform its real tasks in a typical browser setting. This is why the creators of Chrome's fake browser mode work hard to make it look just like a regular browser, to prevent malware from using these differences. Web scrapers benefit from these efforts.
It's also worth noting that while it's easy to run 20 cURL sessions at once, using Chrome in a headless mode for big tasks can be tough because it uses a lot of memory, making it hard to manage more than 20 instances.
If you're interested in learning more, check out these resources:
For those interested in exploring further, consider these two resources:
- Our in-depth guide on How to use a proxy with cURL.
- Visit Antoine Vastel's blog, which focuses on browser fingerprinting and detecting bots.
4. Understand TLS fingerprinting
TLS, short for Transport Layer Security, is what evolved from SSL, forming the backbone of HTTPS security.
This protocol is key to keeping data private and unchanged while it moves between two apps, such as a web browser and a server. TLS fingerprinting works to uniquely identify browsers through their specific TLS setups. This involves two main steps:
- TLS handshake: This is the initial setup where a client and server exchange details to verify identities and set up key aspects of their connection.
- Data encryption and decryption: Once the handshake is successful, they use the protocol to encrypt and decrypt data they exchange. For more on this, you can check out a detailed guide by Cloudflare.
The critical information for a TLS fingerprint comes from the handshake phase. You can see examples of TLS fingerprints at this online database. Currently, the most common fingerprint there is 133e933dd1dfea90, which is mostly used by Safari on iOS.
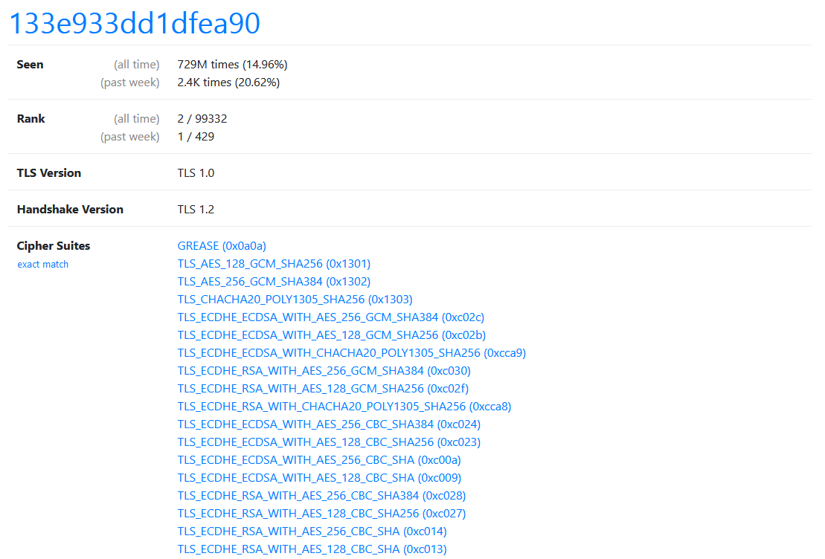
This method is even more selective than typical browser fingerprinting because it relies on fewer data points such as:
- TLS version
- Handshake version
- Supported cipher suites
- TLS extensions
To check your browser's TLS fingerprint, visit SSL Labs for a detailed analysis.
How do I change it?
To stay under the radar while web scraping, it's a good idea to change your TLS settings. But, this isn't as easy as it sounds:
- Since there aren't many TLS fingerprints available, just mixing up these settings might make your fingerprint so unique that it stands out as suspicious.
- TLS settings are deeply tied to your system's setup, so changing them isn't straightforward. For example, the Python
requestsmodule doesn't let you tweak the TLS fingerprint by default.
Here are some guides on how to adjust your TLS version and cipher suite in different programming languages:
- Python with HTTPAdapter and requests
- NodeJS with the TLS package
- Ruby with OpenSSL
💡 Tip: Most of these tools rely on your system's SSL and TLS setups, usually OpenSSL. You may need to update OpenSSL itself to really change your fingerprint.
5. Set request headers and change your user agent
When accessing a webpage, your browser sends a request to an HTTP server. A crucial part of these requests are the HTTP headers, which carry key information about your browser and device to the server. One of the most significant headers in terms of web scraping is the "User-Agent" header.
Why modify user agents?
The User-Agent header identifies the browser type and version to the website. Servers can use this information to tailor content or, in some cases, block suspicious or non-standard user agents. Default user agents from command-line tools like cURL can be a dead giveaway that the request isn't coming from a typical web browser. For example, a simple curl www.google.com request makes it very easy for Google to identify that the request didn't originate from a human using a browser, largely due to the basic user agent string that cURL uses. To see what headers your request is sending, you can use tools like httpbin.org, which displays the headers of your incoming requests.
Updating and rotating user agents
To avoid detection:
- Set a popular user agent: Use a user agent string from a well-known browser. This can be extracted from the latest version of browsers like Google Chrome, Safari, or Firefox. Alternatively, you can find popular user agents on the following resource. Finally, you can use solutions like Fake-Useragent (for Python), User Agents (for JS), Faker (for Ruby), Fake User Agent (for Rust) that can generate a user-agent string for you.
- Keep user agents updated: Browser versions update frequently. Using an outdated user agent can make your scraper stand out. Regularly updating the user agents in your scraping scripts can help mimic a regular user more effectively.
- Rotate user agents: To further disguise your scraping activity, rotate through several user agents. This prevents patterns such as too many requests coming from the same user agent, which is easily detectable.
Beyond user agents
While changing the user agent is fundamental, it's often not enough on its own. Consider these additional headers for more sophisticated scraping:
- Referrer header: This header indicates the previous webpage from which a link was followed. Including a referrer can make requests appear more natural, as if they are coming from a genuine user browsing the web.
- Accept-Language: This header can help in presenting your requests as coming from a specific region, matching the language preferences of typical users from that locale.
Setting headers in cURL is straightforward. For example, to set a User-Agent, you would use the -H option:
curl -H "User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36" www.example.com
Alternatively, you can use the -A option:
curl -A "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36" www.example.com
And to include a referrer:
curl -H "Referer: http://www.previouswebsite.com" -H "User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36" www.example.com
By carefully managing these headers, you can enhance your chances of successfully scraping data without being blocked, ensuring your requests are indistinguishable from those of regular users.
6. Use a CAPTCHA solving service
Changing your IP address alone often isn't enough because of the common use of CAPTCHAs, tests that are easy for humans but hard for machines.
CAPTCHAs usually appear for IP addresses that look suspicious. Using different proxies might help avoid them. But if CAPTCHAs keep showing up, you'll need to solve them.
While some CAPTCHAs can be solved with software like OCR, others require human effort.
For these tougher versions, services like 2Captcha and Death by Captcha use real people to solve CAPTCHAs for a fee.
Even with these solutions and changing proxies, websites might still detect unusual patterns that suggest non-human activity.
ℹ️ Interested in learning more about CAPTCHAs and reCAPTCHA?
Check out our detailed guide on How to bypass reCAPTCHA & hCaptcha when web scraping.
7. Randomise your request rate
Sending web requests at exact one-second intervals for extended periods is a clear giveaway of scraping activities. No real user browses a website that uniformly, and such behavior is easily detected by anti-scraping technologies.
Imagine you need to scrape product data from a URL like https://www.myshop.com/product/[ID] for IDs from 1 to 10,000. Going through these IDs at a constant rate is an obvious sign of scraping. Instead, try these more subtle methods:
- Randomize ID access: Mix up the order of IDs to mimic the random access patterns of human browsing.
- Vary tequest timing: Introduce random delays between requests, varying from a few seconds to several minutes, to avoid detection.
Additionally, use these advanced strategies to further disguise your scraping:
- Diverse user agents: Switch between different user agents to appear as various devices and browsers.
- Behavioral mimicry: Occasionally click on random links or linger on pages as if reading, to mimic real user actions.
These tactics help mask your scraping activities and create more human-like interactions with the website, minimizing the chances of setting off anti-bot defenses.
8. Be kind to the server, understand the rate limit
When deploying web scrapers, it's crucial to act courteously towards the servers you interact with. Bombarding a server with rapid requests can not only degrade the service for others but might also lead to your scraper being blocked or banned.
As you notice your requests beginning to slow down, this is a signal to adjust your pace. Slowing down your request rate can prevent the server from becoming overloaded and maintain a smoother operation for both your scraper and other users.
Additionally, understanding and respecting the rate limits set by websites is essential. Many sites use rate limiting to control the amount of incoming and outgoing traffic to ensure fair usage among all users. Here are some strategies to comply with these limits:
- Adapt to server feedback: Pay attention to HTTP response headers that indicate how many requests you can safely make in a given period. Adjust your scraping speed accordingly.
- Implement backoff strategies: If you encounter error codes like 429 (Too Many Requests), implement a backoff strategy. This involves progressively increasing the delay between requests if repeated attempts fail, allowing the server time to recover.
- Monitor server performance: Keep an eye on the server's response times. A sudden increase in latency might suggest that the server is struggling, prompting you to further reduce your request frequency.
By applying these practices, you'll be able to scrape data more responsibly, minimizing the risk of getting blocked and promoting a more sustainable interaction with web resources.
Strategic rate limiting
Understanding and respecting the server's rate limit is crucial for discreet web scraping. Maintaining a moderate pace helps your scraper blend in with normal traffic and avoid detection. Web crawlers often move through content faster than humans, which can overload server resources and affect other users, especially during busy times.
How to determine a server's rate limits
Knowing a server's rate limits is key to avoiding anti-scraping measures. Here's how you can figure them out:
- Read the website's terms of service and API documentation: Often, rate limits are stated clearly here.
- Observe response headers: Look for headers like
RateLimit-Limit,RateLimit-Remaining, andRateLimit-Resetthat provide rate limit info. - Monitor server response times and error codes: Increase your request frequency until you notice slower responses or get HTTP 429 errors, indicating you've hit the limit.
- Contact the website administrators: If unsure, ask the admins directly for guidance on acceptable request rates.
Optimal crawling times
Choosing the best time to scrape can vary by website, but a good rule is to scrape during off-peak hours. Starting just after midnight, local time to the server, usually means less user activity and lower risk of impacting the server or attracting attention to your scraping.
By following these guidelines, you promote ethical scraping, improve the effectiveness of your data collection, and ensure you respect the server and other users.
9. Consider your location
Location plays a crucial role in web scraping without drawing undue attention. Many websites target specific geographic demographics, and accessing these sites from IPs outside their main service area can raise suspicions.
For example, a Brazilian food delivery service mainly serves customers within Brazil. Using proxies from the U.S. or Vietnam to scrape this site would likely trigger anti-scraping measures, as it would stand out. Websites often monitor for such geographic inconsistencies as part of their security efforts to protect their data.
A notable case involved a company blocking all IP ranges from a certain country after detecting excessive scraping activities originating from there. Such severe actions emphasize the need to align your scraping efforts with the expected usage patterns of the target site.
Here are some strategies to align with geographic norms:
- Use localized proxies: Utilize proxies corresponding to the website's primary user base to blend in with legitimate traffic, reducing the likelihood of being flagged as an outsider.
- Understand local behavior: More than just using local IPs, mimic how local users typically interact with the site—considering browsing times, page interactions, and language settings.
- Monitor for geo-blocking techniques: Keep up with common geo-blocking methods and develop strategies to bypass them, ensuring uninterrupted access while respecting the site's operations.
By considering these factors and planning your scraping activities strategically, you can greatly decrease the risk of detection and blocking. Adopting these practices not only makes your data collection efforts more respectful but also ensures they remain sustainable and under the radar.
10. Move your mouse
When scraping websites, one effective way to avoid detection as a bot is to simulate human-like interactions, such as mouse movements. Websites often track user behavior to identify automated scripts, which typically do not exhibit irregular or human-like interactions like random mouse movements.
Moving the mouse helps make your scraping activities appear more human. Many advanced websites use sophisticated techniques to detect scraping, such as analyzing cursor movements, click patterns, and typing speeds. By simulating these behaviors, you can reduce the risk of being flagged as a bot, which can lead to your IP being blocked or served misleading data.
Simulating mouse movements can bypass certain types of bot detection systems. These systems look for consistent patterns or the absence of certain expected interactions that are typical of human users. By adding randomized mouse movements and clicks, your scraper can imitate the non-linear and unpredictable patterns of a real user, thus blending in more effectively.
Using Selenium, an automation tool designed primarily for testing but also highly effective for web scraping, you can easily simulate mouse movements. Selenium provides a comprehensive API for mouse interactions, including moving the cursor, dragging-and-dropping elements, and performing complex click sequences. Check the Selenium documentation on how to implement these actions.
This approach not only helps in avoiding detection but also enables interaction with pages that require hover states to display content or trigger JavaScript events based on mouse location. Implementing these strategies can significantly enhance the capability of your scraping scripts to access content as if they were being navigated by a human user.
11. Scrape their content API
Increasingly, websites are not just delivering plain HTML but are also providing API endpoints. These are often unofficial and undocumented but offer a more standardized way of interacting with the site. APIs can simplify scraping tasks because they typically involve less complex elements like JavaScript.
Reverse engineering of an API
The primary steps involved include:
- Analyzing web page behavior: Watch how the website behaves during user interactions to identify relevant API calls.
- Forging API calls: Replicate these API calls in your code to programmatically fetch data.
For example, if you want to extract all comments from a popular social network, you might click the "Load more comments" button and observe the network traffic in your browser's developer tools. You'll likely see an XHR request that fetches the comments.
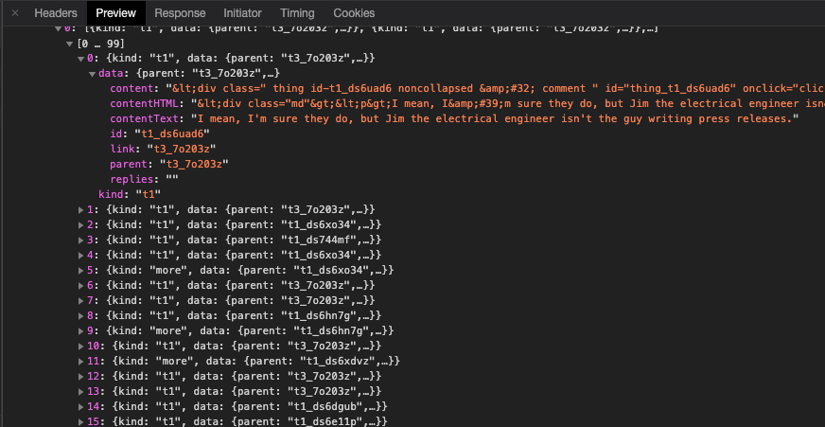
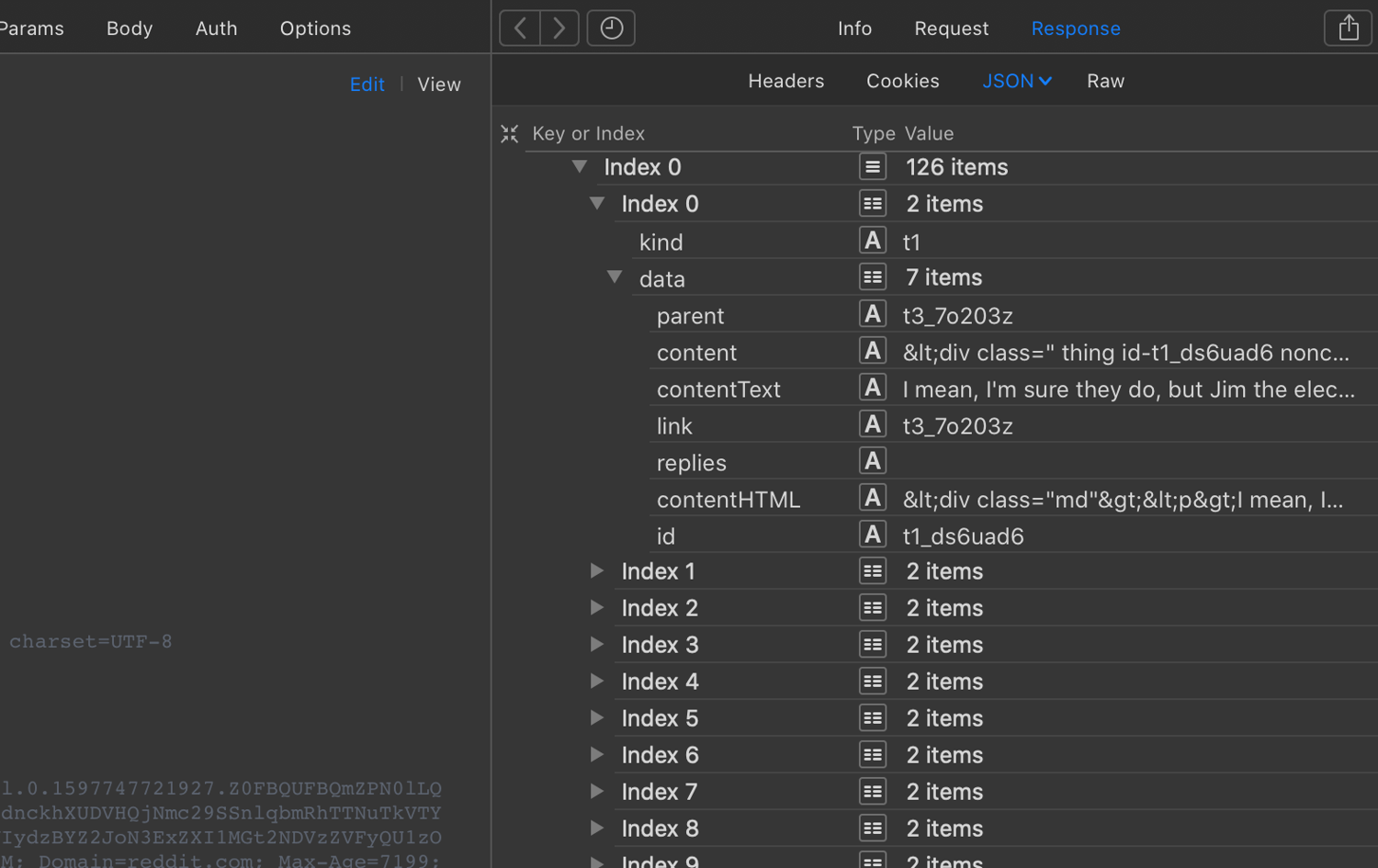
In this case, the response is usually a JSON object with all the data you need. By checking the Headers tab, you can gather the details necessary to replicate the request. Understanding the parameters and their values is essential and may take several attempts to perfect, especially if the API uses single-use tokens to prevent simple replays.
Use your browser's developer tools for this analysis. Exporting requests as a HAR file can help you examine them more deeply in tools like Paw or Postman.
Reverse engineering mobile apps
API debugging techniques also apply to mobile apps. You might need to intercept and replicate requests made by mobile apps, which can be tricky for a couple of reasons:
- Intercepting requests: This often involves using a Man-In-The-Middle (MITM) proxy, such as Charles.
- Request obfuscation: Mobile apps tend to hide their requests more effectively than web apps, making analysis more challenging.
A well-known example is Pokemon Go, where Niantic identified and banned players who used cheat tools that overlooked additional, hidden parameters in the API requests.
Another interesting example is the reverse engineering of Starbucks's unofficial API. This API employed advanced methods like device fingerprinting, encryption, and single-use requests, adding layers of complexity to the reverse engineering process.
12. Avoid honeypots
Web crawlers can easily trigger traps known as honeypots set by website administrators to catch and block unauthorized scrapers. These traps are typically invisible to human users.
Honeypots often take the form of links invisible to users but detectable by bots. Here's how to identify and avoid these setups:
- Invisible links: Stay away from links styled with CSS properties like
display: none,visibility: hidden, or those positioned off-screen (e.g.,position: absolute; left: -9999px). - Camouflaged links: Be wary of links that match the background color (e.g.,
color: #ffffffon a white background). Your scraper should ignore these links. - Link relevance: Only follow links that are relevant to your scraping objectives. Irrelevant links might be decoys.
To effectively bypass honeypots, consider these best practices:
- Respect robots.txt: Adhering to the guidelines in this file helps avoid areas likely to contain honeypots.
- Analyze content reliability: Validate the data collected by your scraper against trusted sources to ensure accuracy, as some honeypots provide false information.
- Simulate human behavior: Mimic human browsing patterns by varying the pace of requests and not following every link on a page.
- Regularly update scraping logic: Continuously refine your scraping methods to adapt to new types and techniques of honeypots.
By following these guidelines, you can more effectively evade honeypots, enhancing the sustainability and effectiveness of your web scraping efforts.
13. Scrape Google's cached version
When scraping highly protected websites or looking for data that doesn't change often, utilizing Google's cached version of a webpage can be a useful approach. This involves accessing the backup copy of the website stored by Google.
To use Google's cached content, add this prefix to the webpage URL you want to scrape:
https://webcache.googleusercontent.com/search?q=cache:https://example.com/
This method is particularly beneficial for scraping sites that are hard to access due to strong anti-bot measures or those that dynamically load content.
Consider the following when using Google's cache:
- Data freshness: The cached version might not be current. The frequency with which Google updates its cache depends on the site's popularity and how often its content changes. For less popular or seldom-updated sites, the cache could be quite old.
- Availability: Not all sites allow their pages to be cached by Google. For example, LinkedIn prevents Google from storing their data. Verify if a cached version is available and suitable for your needs.
- Reliability: Although scraping from Google's cache can circumvent some anti-scraping measures, it's not guaranteed to be complete. The data might be missing or incomplete if Google hasn't recently crawled the page.
While using Google's cache can be advantageous, remember to consider the ethical and legal aspects of scraping, even from cached versions. Ensure that your scraping practices adhere to the website's terms of service and are compliant with local laws.
Understanding these points can help you effectively use Google's cache as a strategic tool in your scraping arsenal, particularly when tackling challenging sites or when you need a snapshot of occasionally updated content.
14. Route through Tor
When it comes to web scraping without getting blocked, routing your requests through the Tor network can be a viable strategy. Known as The Onion Router, Tor anonymizes web traffic sources, making network surveillance and traffic analysis extremely challenging.
Tor is celebrated for its robust privacy features, essential for activists in repressive regimes, journalists needing anonymity, and privacy advocates. Though it's also known for facilitating illegal activities due to its anonymizing capabilities, its legitimate uses in preserving privacy and freedom of speech are significant.
In web scraping, Tor functions like traditional proxies by masking your IP address. It changes your IP approximately every 10 minutes, aiding scraping that needs new sessions or geographic diversity. However, there are challenges:
- Public exit nodes: Tor exit nodes' IP addresses are publicly known and often listed in databases, leading many websites to block traffic from these nodes.
- Speed limitations: Tor's intricate routing system, bouncing traffic through multiple relays worldwide, significantly slows down the traffic, affecting scraping efficiency.
Despite these challenges, Tor can be part of your scraping strategy, especially when used with other methods like proxies or changing user agents. Here are some tips if you use Tor for scraping:
- Verify accessibility: Regularly check if the target site blocks Tor exit nodes to avoid futile scraping attempts.
- Combine with other tools: To counter Tor's limitations, consider using it with VPNs or rotating proxy services to stay undetected.
- Respect rate limits: Even with Tor, respecting the target site's rate limits is crucial to avoid anti-scraping mechanisms.
By understanding Tor's strengths and limitations, you can integrate it effectively into your web scraping strategies, ensuring more discreet and responsible data collection. The goal is to scrape ethically while minimizing your digital footprint.
15. Reverse engineer the anti-bot technology
As web technologies evolve, so do the strategies websites use to detect and block automated scraping. These anti-bot technologies can involve complex algorithms designed to analyze user behavior, request patterns, and other hallmarks of automated activity. Understanding Anti-Bot Technologies
Reverse engineering these systems isn't straightforward. Throughout this tutorial, you've learned that websites may employ methods such as behavioral analysis, rate monitoring, scrutinizing request headers and fingerprints, and deploying captcha challenges, among others. Thus, you require a deep understanding of both network security and web technologies.
- Study the JavaScript: Many websites use JavaScript to detect unusual browsing patterns. Studying the JavaScript code that runs on the website can reveal what the site checks for when determining if a user is a bot.
- Monitor network requests: Use tools like Wireshark or browser developer tools to monitor the requests made by your bot and compare them to those made by a regular browser. Look for discrepancies in the request headers, timings, and order of requests.
- Experiment with headers: Modify the headers sent by your scraping tool to see which ones trigger anti-bot responses. This can help you understand which headers are being monitored more closely by the website.
- Captcha analysis: Understanding how CAPTCHAs are integrated and triggered can help in designing strategies to circumvent them, whether by avoiding actions that trigger a CAPTCHA or developing methods to solve them.
At ScrapingBee, we've built our tools with an intimate understanding of these anti-bot measures. Our service handles the intricacies of headers, proxies, and even JavaScript rendering, making your scraping efforts more human-like and less detectable.
Using ScrapingBee means you have a sophisticated ally designed to navigate complex website defenses. We stay updated with the latest in web security trends, so you don't have to continually adjust your strategies.
Remember, the key isn't just about scraping data—it's about doing it in a way that maintains your operations under the radar and in compliance with web standards. With ScrapingBee, you're equipped to adapt to and overcome modern web defenses.
Conclusion
So, that's it for today, folks! I hope this overview helped you to understand better what difficulties a web-scraper may encounter and how to counter or avoid them altogether. Navigating through the complexities of web scraping involves understanding both the technical challenges and ethical considerations. The key to effective scraping is not just about extracting data but doing so in a way that respects the target website's guidelines and maintains the quality of service for all users. This guide provides a comprehensive look at various anti-bot protection measures employed by websites and the strategies you can use to counter them effectively.
Below is a table summarizing the protection measures discussed in this blog post along with the suggested countermeasures:
| Protection Measure | Countermeasure |
|---|---|
| IP Blocking | Use rotating proxies, residential proxies, and manage them effectively. |
| Browser Fingerprinting | Use headless browsers with capabilities to mimic real browsers, adjust user agents, and manage headers. |
| Behavioral Analysis | Simulate human-like interactions, including random mouse movements and varied request timing. |
| Rate Limiting | Respect the server's rate limits, adjust scraping speed, and scrape during off-peak hours. |
| CAPTCHA | Employ CAPTCHA solving services to handle challenges programmatically. |
| TLS Fingerprinting | Modify TLS parameters subtly to avoid creating a suspiciously unique fingerprint. |
| Honeypots | Avoid invisible or suspiciously placed links and check for traps in the website's robots.txt. |
| Geo-blocking | Use proxies from geographically relevant locations to mimic the expected traffic for the target site. |
| Advanced JavaScript Challenges | Utilize sophisticated scraping tools like ScrapingBee that can render JavaScript and manage complex interactions. |
At ScrapingBee, we leverage and combine all of the mentioned techniques, which is why our web scraping API is able to handle thousands of requests per second without the risk of being blocked. If you don't want to lose too much time setting everything up, make sure to try ScrapingBee.
We also recently published a guide about the best web scraping tools on the market, please don't hesitate to take a look!

Ilya is an IT tutor and author, web developer, and ex-Microsoft/Cisco specialist. His primary programming languages are Ruby, JavaScript, Python, and Elixir. He enjoys coding, teaching people and learning new things. In his free time he writes educational posts, participates in OpenSource projects, tweets, goes in for sports and plays music.
