Web crawling with Python sounds fancy, but it's really just teaching your computer how to browse the web for you. Instead of clicking links and copying data by hand, you write a script that does it automatically: visiting pages, collecting info, and moving on to the next one.
In this guide, we'll go step by step through the whole process. We'll start with a tiny script using requests and BeautifulSoup, then level up to a scalable Python web crawler built with Scrapy. You'll also see how to clean your data, follow links safely, and use ScrapingBee to handle tricky sites with JavaScript or anti-bot rules.
The goal is simple: by the end, you'll understand how web crawling works, have real code that runs, and follow a Python web crawler tutorial that shows how to scale it without turning into a full-time sysadmin.

Quick answer (TL;DR)
Here's a simple starter for web crawling with Python. It uses ScrapingBee to fetch pages (so you get JavaScript-rendered HTML and automatic proxy handling), collects links, keeps a per-domain visit limit, and writes titles to CSV.
import csv
import time
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin, urlparse
from collections import defaultdict, deque
# Paste ScrapingBee key here
API_KEY = "YOUR_SCRAPINGBEE_API_KEY"
MAX_PAGES_PER_DOMAIN = 5
def fetch(url: str) -> str:
"""Fetch HTML using ScrapingBee (handles JS, rotating IPs, etc.)."""
params = {
"api_key": API_KEY,
"url": url,
"render_js": "true",
}
resp = requests.get("https://app.scrapingbee.com/api/v1/", params=params, timeout=20)
resp.raise_for_status()
return resp.text
def extract_links(base_url: str, html: str):
"""Return the page title and a list of absolute links found on the page."""
soup = BeautifulSoup(html, "html.parser")
page_title = soup.title.get_text(strip=True) if soup.title else ""
links = []
for a in soup.select("a[href]"):
href = a.get("href", "").strip()
abs_url = urljoin(base_url, href)
links.append(abs_url)
return page_title, links
def crawl(seed_urls):
# Collect already seen links
# to avoid visiting same pages
seen = set()
per_domain_count = defaultdict(int)
queue = deque(seed_urls)
results = []
while queue:
url = queue.popleft()
domain = urlparse(url).netloc
if url in seen:
continue
if per_domain_count[domain] >= MAX_PAGES_PER_DOMAIN:
continue
try:
html = fetch(url)
except Exception as e:
print(f"skip {url} ({e})")
continue
seen.add(url)
per_domain_count[domain] += 1
title, links = extract_links(url, html)
results.append({"url": url, "title": title})
# enqueue new links (same domain only, to keep it polite)
for link in links:
if urlparse(link).netloc == domain and link not in seen:
queue.append(link)
# Be nice about crawling speed
# This is a bit naive though
time.sleep(1)
return results
if __name__ == "__main__":
seeds = ["https://news.ycombinator.com/"]
data = crawl(seeds)
with open("crawl_output.csv", "w", newline="", encoding="utf-8") as f:
writer = csv.DictWriter(f, fieldnames=["url", "title"])
writer.writeheader()
writer.writerows(data)
print("Saved crawl_output.csv")
This quick script shows a minimal but real crawler setup that works out of the box — just replace YOUR_SCRAPINGBEE_API_KEY with your own key from ScrapingBee. It uses ScrapingBee to fetch pages safely (with JavaScript support and proxy rotation), extracts links, limits how many pages it visits per domain, and saves everything into a neat CSV file.
In the sections below, we'll look at how to build your own Python website crawler from scratch using Python's requests, BeautifulSoup, and then scale it up properly with Scrapy.
What is web crawling in Python
Web crawling with Python is basically making a script that explores the web for you. You give it a starting URL, it grabs the page, finds a few links, follows them, and keeps going. Like a chill bot that never gets bored or distracted by memes.
Python makes this easy with tools like requests and BeautifulSoup. And when you're ready to go bigger, Scrapy has your back.
Difference between web crawling and scraping
People mix these up all the time. Crawling is about finding pages, like exploring a maze of links. Scraping is about grabbing data from those pages (titles, prices, reviews, whatever).
So, the crawler discovers stuff, and the scraper digs in.
If you want to go deeper into scraping itself, check this out: What is Web Scraping?
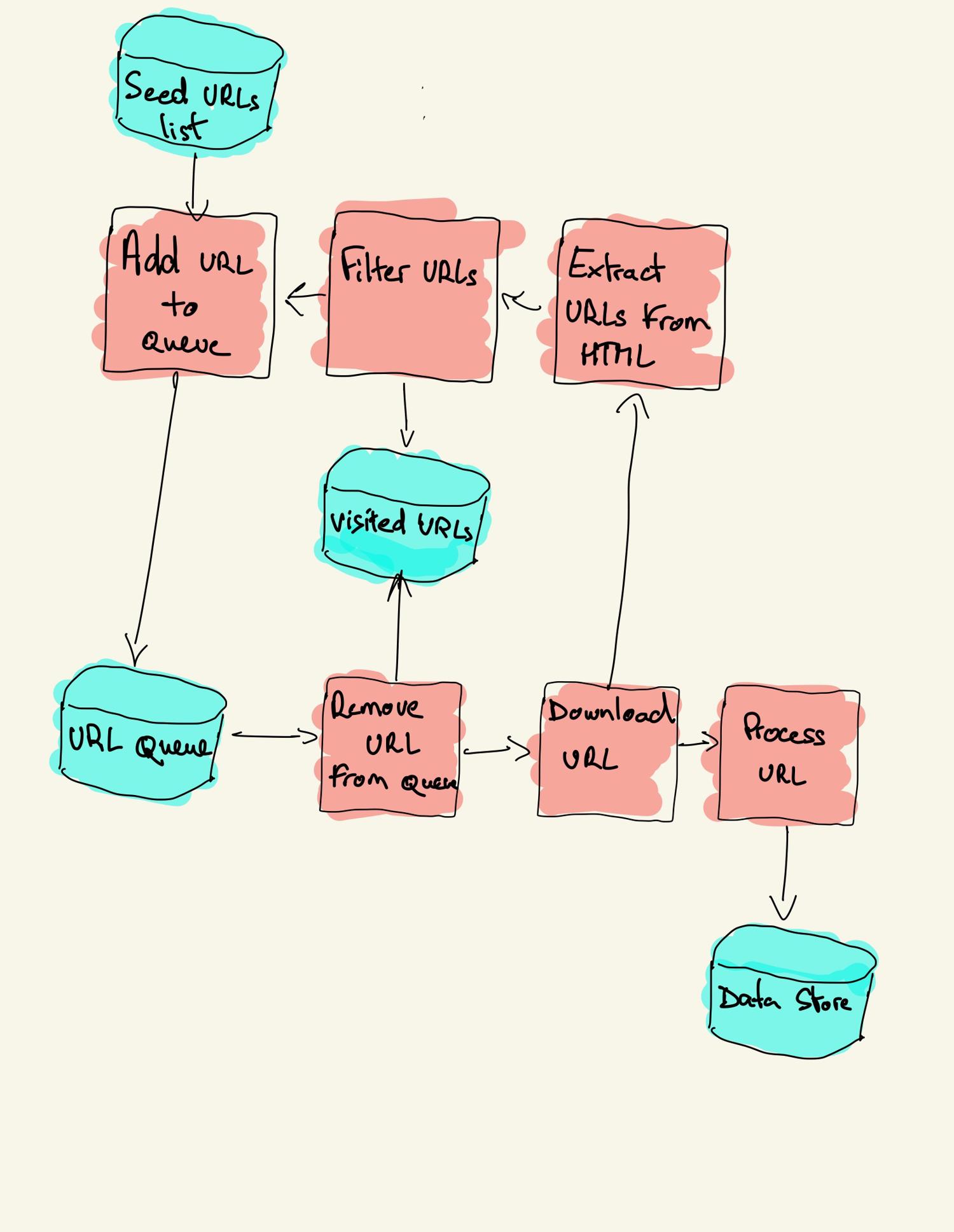
How web crawlers work behind the scenes
A crawler doesn't do magic; it just loops smartly. Here's the gist of web crawling with Python:
- Start from one or more seed URLs
- Fetch the page HTML
- Pull out all the links
- Add new ones to a queue (so you don't miss anything)
- Keep looping until there's nothing new left to visit or you decide to stop
That's the whole engine. A good crawler just does this efficiently, politely (so websites don't hate you), and maybe logs or saves stuff as it goes.
Common use cases for Python web crawler
A Python web crawler isn't just for search engines and big tech companies. You can use it right now with Python to collect data, watch competitors, or build your own datasets without endless copy/paste sessions. The whole point is simple: instead of opening a browser and checking 50 pages by hand, you let your crawler do that for you on repeat.
Here are a few real-life situations where web crawling with Python actually makes sense:
Search engine indexing
Search engines use crawlers to discover and understand the web. A crawler starts from known URLs, visits each page, finds all the links, and keeps going. While doing that, it also saves page content so the search engine can figure out what each page is about and who should see it.
That's how a new blog post or product page becomes "visible" online. Smaller teams sometimes build mini versions of this for internal search like "crawl our docs and make them searchable."
SEO and backlink analysis
SEO folks crawl websites to map who links to who. You can use a Python web crawler to go through blogs, partner sites, or news pages and find links pointing to your domain. That gives you a list of backlinks you already have and a hit list for outreach. You can also crawl your own site to check internal links, fix broken ones, and make sure key pages aren't buried five clicks deep. Handy during audits, redesigns, or migrations.
For example, I once needed to check whether our own resource hub had any broken internal links after a big content migration. I ran a quick Python crawler that fetched every page, logged 404s, and flagged missing redirects. It saved us days of manual checking plus it revealed a few hidden content gaps we wouldn't have noticed otherwise.
Price monitoring and product tracking
In e-commerce and SaaS, people crawl competitor pages to track pricing, plans, discounts, stock levels, and shipping times. If your rival drops a price by 20%, you want to know fast. A Python crawler can just hit those pages on a schedule and log the changes automatically.
A lot of modern product pages use JavaScript to load data, which makes plain HTML fetching tricky. That's where services like ScrapingBee save your sanity as they render JavaScript remotely, so you can just focus on extracting clean data instead of fighting headless Chrome setups. Here's their JavaScript rendering feature if you're curious.
Academic and research data collection
A lot of research is basically "collect public data, then analyze it." Crawlers are perfect for that. You can gather housing listings for economics studies, company statements for finance research, job postings for labor trends, or government pages for policy tracking.
Journalists do this too by building timelines, comparing claims, or watching edits on public sites.
Simple Image Downloading
Another common use case for a Python web crawler is downloading images from the web. With the requests library, you can fetch binary data (like images) and save it locally in just a few lines of code:
import requests
url = "https://example.com/image.jpg"
response = requests.get(url)
if response.status_code == 200:
with open("image.jpg", "wb") as f:
f.write(response.content)
Here’s what’s happening: response.content gives you the raw binary data of the image, not text. To save it correctly, you must open the file in binary write mode ("wb"), otherwise the file may get corrupted.
This approach works for any file type (images, PDFs, or videos) and is often the first step before building a more advanced Python web crawler.
If you want to go further, check out how to scrape Google Images or scrape images from a website.
Basic web crawler using Requests and BeautifulSoup
Let's build a small crawler that grabs data from Hacker News. It's a classic example because the site's structure is clean, static, and friendly for learning. Honestly, sometimes it feels like Hacker News was built specifically so beginners could learn web crawling basics without breaking anything.
The crawler will fetch the front page and print the first ten story titles with their URLs. A nice demo of web crawling with Python in action.
Installing required libraries
We'll use uv, a modern Python package manager that's quick and painless.
Run this in your terminal:
uv init scraping-example
cd scraping-example
uv add requests beautifulsoup4
That's all you need for now — no venv juggling, no slow installs, just a clean start.
Writing a simple crawler script
Now we're going to write a crawler in Python that does three things:
- Downloads the HTML from Hacker News
- Parses the page
- Prints the top 10 story titles and links
Open a file called main.py in the project root and drop this in:
import requests
from bs4 import BeautifulSoup
from typing import List, Tuple
HEADERS = {
"User-Agent": (
"Mozilla/5.0 (X11; Linux x86_64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/122.0.0.0 Safari/537.36"
)
}
def fetch_page(url: str) -> str:
"""
Download a page and return its raw HTML as text.
We send a User-Agent header so we don't look like some empty default bot.
We also raise if the request failed.
"""
response = requests.get(url, headers=HEADERS, timeout=10)
response.raise_for_status()
return response.text
def parse_front_page(html: str) -> List[Tuple[str, str]]:
"""
Parse the Hacker News front page HTML and extract (title, link)
for each story.
"""
soup = BeautifulSoup(html, "html.parser")
# each story title lives in a <span class="titleline">
title_nodes = soup.select(".titleline")
items: List[Tuple[str, str]] = []
for node in title_nodes:
main_link = node.find("a")
if not main_link:
continue
title = main_link.get_text(strip=True)
href = main_link.get("href", "")
items.append((title, href))
return items
def crawl_hacker_news() -> None:
"""
Fetch the Hacker News homepage, grab the first 10 stories,
and print them in a clean format.
"""
url = "https://news.ycombinator.com/"
html = fetch_page(url)
stories = parse_front_page(html)
for i, (title, href) in enumerate(stories[:10], start=1):
print(f"{i}. {title} → {href}")
if __name__ == "__main__":
crawl_hacker_news()
# 💡 Example: Using ScrapingBee's premium proxy instead of direct requests.
# Replace `fetch_page()` with the snippet below to fetch pages via ScrapingBee's API.
# This helps when sites block requests or require proxy rotation.
"""
def fetch_page(url: str) -> str:
API_KEY = "YOUR_SCRAPINGBEE_API_KEY"
api_url = "https://app.scrapingbee.com/api/v1"
params = {
"api_key": API_KEY,
"url": url,
"premium_proxy": True, # enables premium proxy routing
"render_js": False, # set to true for JS-heavy sites
}
response = requests.get(api_url, params=params, timeout=30)
response.raise_for_status()
return response.text
"""
Understanding the code
So, what's actually happening here?
First, we use requests to fetch the Hacker News homepage. It's our crawler's "eyes": it downloads the HTML so we can read it. We also send a User-Agent header that makes us look like a normal browser instead of a silent Python script. Some sites block bots with blank headers, so this is just polite crawling behavior.
Next, BeautifulSoup takes that HTML and turns it into a tree we can search. The magic line is:
stories = soup.select(".titleline")
That grabs every element on the page with the titleline class (those are the story titles). From there, we just loop through the first ten, grab the link text and the href, and print them nicely.
We wrapped the logic into a few small functions so things stay clean:
fetch_page()handles network stuff by downloading HTML safely, with timeouts and error checks.parse_front_page()extracts the data; a simple example of parsing and filtering.crawl_hacker_news()runs the whole flow and prints the results.
That's the basic pattern of web crawling with Python: "fetch — parse — repeat". Once you understand that loop, you can crawl just about anything.
Checking the result
Run your scraper with:
uv run python main.py
You'll see output like:
1. Let's Help NetBSD Cross the Finish Line Before 2025 Ends → https://mail-index.netbsd.org/netbsd-users/2025/10/26/msg033327.html
2. 10k Downloadable Movie Posters From The 40s, 50s, 60s, and 70s → https://hrc.contentdm.oclc.org/digital/collection/p15878coll84/search
...
Great job!
If you ever need to convert a complex curl command into Python code, use the Curl Converter to save time.
Extracting and filtering links
Sometimes pages contain all sorts of extra links like login pages, ads, or trackers. You can add quick filters to keep only what you want. For example, to only show links pointing to external domains:
import requests
from bs4 import BeautifulSoup
from urllib.parse import urlparse
from typing import List
from pathlib import Path
HEADERS = {
"User-Agent": (
"Mozilla/5.0 (X11; Linux x86_64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/122.0.0.0 Safari/537.36"
)
}
def is_external(href: str) -> bool:
"""
Return True if the link looks like a real external URL
(http/https and not an internal Hacker News link like "item?id=12345").
"""
if not href:
return False
if href.startswith("item?id="):
return False
parsed = urlparse(href)
return parsed.scheme in ("http", "https")
def fetch_front_page() -> str:
"""
Fetch the Hacker News front page HTML.
"""
url = "https://news.ycombinator.com/"
response = requests.get(url, headers=HEADERS, timeout=10)
response.raise_for_status()
return response.text
def extract_external_links(html: str) -> List[tuple[str, str]]:
"""
Parse the page and collect (title, href) for external links only.
"""
soup = BeautifulSoup(html, "html.parser")
stories = soup.select(".titleline")
results: List[tuple[str, str]] = []
for story in stories:
main_link = story.find("a")
if not main_link:
continue
href = main_link.get("href", "").strip()
title = main_link.get_text(strip=True)
if is_external(href):
results.append((title, href))
return results
def save_links(lines: List[tuple[str, str]], path: Path) -> None:
"""
Save filtered links to a text file so you can reuse them later.
"""
with path.open("w", encoding="utf-8") as f:
for title, href in lines:
f.write(f"{title} -> {href}\n")
def main() -> None:
html = fetch_front_page()
links = extract_external_links(html)
for i, (title, href) in enumerate(links[:10], start=1):
print(f"{i}. {title} → {href}")
# also save to disk for later processing
save_links(links, Path("hn_links.txt"))
if __name__ == "__main__":
main()
Understanding the code
This upgraded crawler adds filtering and saving. Here's what's happening:
is_external()skips internal Hacker News links likeitem?id=12345, keeping only realhttporhttpsURLs.fetch_front_page()grabs the HTML withrequests.get(), using a timeout and politeUser-Agent.extract_external_links()finds story titles, filters them throughis_external(), and keeps only valid links.save_links()writes everything tohn_links.txtso you can reuse or analyze the data later.
It's still simple, but now your web crawling with Python also includes data cleaning and persistence.
💡Want more methods for gathering all the URLs on a website? Then check out our guide on multiple methods for finding all the URLs on a website
Web Crawling and Parsing JSON Data with Python
When people think about web crawling with Python, they often imagine scraping HTML pages. But a lot of modern websites actually load their data from APIs that return JSON. If you can find these endpoints, your Python crawler becomes much simpler and more reliable.
Here’s a basic example using the requests library:
import requests
url = "https://api.example.com/data"
response = requests.get(url)
if response.status_code == 200:
data = response.json() # convert JSON to Python dict
print(data)
The key part here is response.json(). Instead of dealing with raw text or HTML, this method parses the JSON response and turns it into a Python dictionary (or list), which makes it easy to access specific fields.
For example, if the API returns a list of items, you can loop through it:
for item in data:
print(item.get("name"), item.get("price"))
This approach is often faster and more stable than parsing HTML, since APIs usually return structured data by design. It’s also a core technique if you’re learning how to crawl a website efficiently, especially for dynamic sites that rely heavily on JavaScript.
A typical Python crawler will combine both methods: use APIs when available, and fall back to HTML scraping when needed. Knowing when to use each approach is what separates a basic script from a more robust web crawling with Python setup.
If you want a deeper dive into working with JSON, check out this guide on how to read and parse JSON data with Python.
Limitations of basic crawlers
Our little Hacker News crawler is suitable for learning, but it's not built for the messy, noisy real web. Real sites are bigger, slower, and sometimes actively hostile to simple scripts. Before you try to crawl hundreds or thousands of pages, know what this basic approach can't handle and what will push you toward Scrapy or a managed API like ScrapingBee.
No parallelism or retries
The script fetches one page at a time and dies if a request fails. That's fine for a demo, but painfully slow for real work. You want:
- Retries with backoff for flaky requests
- Rate limiting so you don't hammer a server
- Parallelism (threads, asyncio, or Scrapy's reactor) to speed things up
Handling duplicate and broken links
Simple crawlers often re-visit the same pages or get stuck following repeated links. You might also hit broken URLs or 404 errors that crash the script. A more complete crawler keeps a "visited" set, skips duplicates, and logs failed links for review later. This makes large crawls more efficient and reliable.
Ignoring robots.txt and crawl delays
Our basic crawler doesn't check robots.txt or respect crawl-delay rules. That's risky because some sites specify how often and how deep you're allowed to crawl. Ignoring that can get your IP blocked or trigger anti-bot measures like CAPTCHAs or rate limits.
Always check a site's robots policy before running your crawler. It's good manners and keeps your script from accidentally turning into a mini DDoS machine.
Building a scalable crawler with Scrapy
Once your simple script starts feeling slow or messy, it's time to level up. Enter Scrapy, a Python framework built specifically for web crawling at scale. It handles concurrency, retries, deduplication, and proxy management out of the box. Basically, it takes care of all the boring parts so you can focus on what to crawl and what data to extract.
If you ever need to deal with JavaScript-heavy pages or rotate proxies, check out this guide on Scrapy proxy integration. It shows how to combine Scrapy with Playwright and ScrapingBee for reliable, scalable fetching — even on tricky, modern websites.
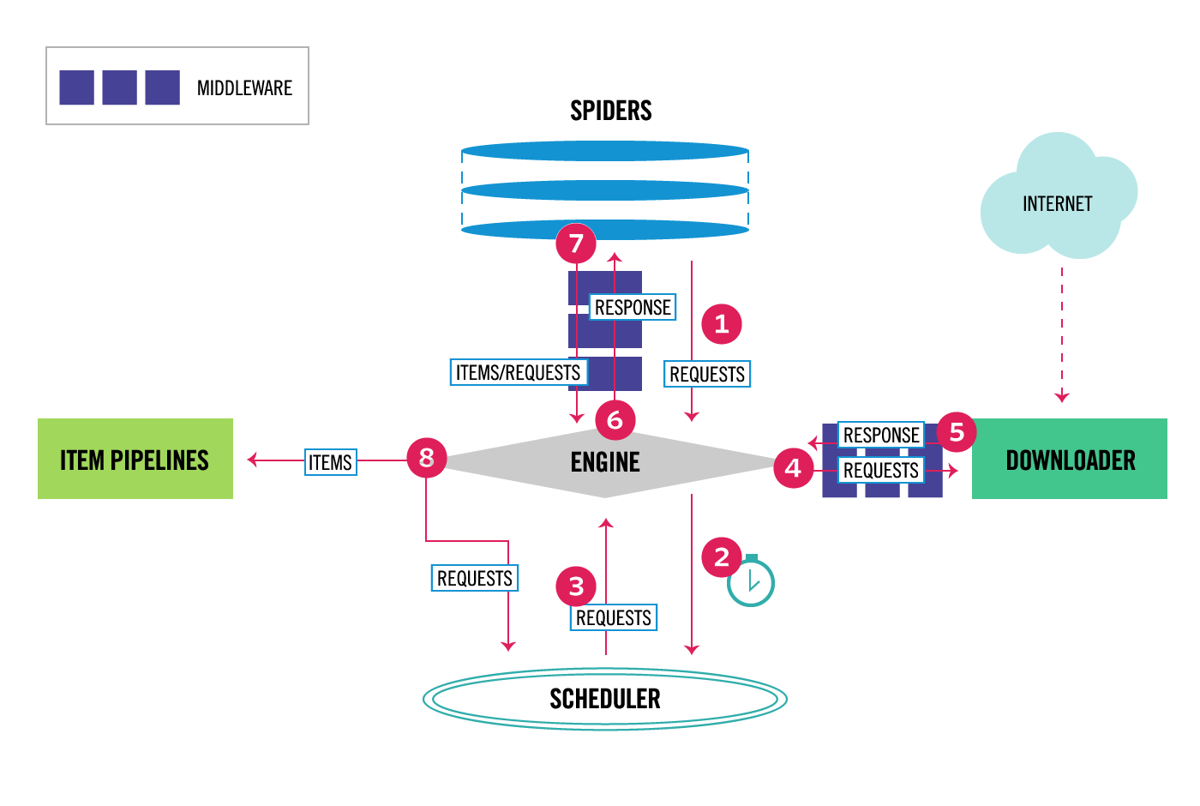
Scrapy architecture overview
Scrapy is more like a full engine than a small script. Here's the general idea:
- Spiders define what to crawl and how to parse it
- Schedulers decide which URLs to visit next
- Downloaders fetch pages (optionally through proxies or headless browsers)
- Pipelines clean, transform, and save the scraped data
- Middlewares handle retries, headers, user-agents, and delays automatically
All these parts work together so you can crawl thousands of pages without writing any low-level async logic. It's built for large and efficient web crawling with Python.
Creating a Scrapy project and spider
Scrapy ships with its own command-line tool that bootstraps your entire project: folders, settings, and sample code included. Using uv here keeps your environment clean and fast, so you don't clutter your global Python setup.
Run the following commands in your terminal:
uv init scrapy-example
cd scrapy-example
uv add scrapy
# create a new Scrapy project inside this folder
uv run scrapy startproject hackernews_crawler
cd hackernews_crawler
# generate a spider named "hackernews" for the domain "news.ycombinator.com"
uv run scrapy genspider hackernews news.ycombinator.com
This creates a directory structure like:
hackernews_crawler/
├── hackernews_crawler/
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders/
└── __init__.py
│ └── hackernews.py
└── scrapy.cfg
Now let's update the hackernews_crawler/spiders/hackernews.py file:
import scrapy
class HackernewsSpider(scrapy.Spider):
name = "hackernews"
allowed_domains = ["news.ycombinator.com"]
start_urls = ["https://news.ycombinator.com/"]
def parse(self, response):
# each story title is inside <span class="titleline"><a>...</a></span>
for box in response.css(".titleline"):
link = box.css("a:first-child")
title = link.css("::text").get()
href = link.attrib.get("href")
if title and href:
yield {
"title": title.strip(),
"url": href.strip(),
"source": "hackernews",
}
Understanding the code
This Scrapy spider is the grown-up version of our earlier script. At the top, we define a HackernewsSpider class that inherits from scrapy.Spider. Every Scrapy spider needs a few basics:
name— a short ID for your spider. You'll use it when running the crawl command.allowed_domains— keeps the crawler focused on one domain so it doesn't wander off the web.start_urls— the initial pages to crawl. Scrapy will fetch these automatically when the spider starts.
The main action happens in the parse() method. Scrapy passes a response object for each downloaded page, and you use CSS selectors to grab the bits you care about. Here, response.css(".titleline") finds all the story title containers, then we pick the first <a> inside each to get the link and its text.
The yield statement returns each item as a dictionary. Scrapy collects these items as it goes and can automatically save them to a file or database, depending on the output format you choose.
Checking the result
Now run your spider:
uv run scrapy crawl hackernews -O stories.json
Scrapy will crawl the Hacker News front page, extract story titles and links, and save them into stories.json. The -O flag overwrites the file each run, so you always get a clean snapshot.
Using Scrapy spiders to follow links
If you want your crawler to follow links automatically (for example, go from the Hacker News front page into each comment thread and also walk through the "More" pages) you can teach Scrapy to do that.
Below is an improved spider that does two things:
- Walks story listings (with pagination)
- Follows some comment threads and extracts basic discussion info
It also includes soft limits so you don't accidentally crawl the entire site.
import scrapy
class HackernewsSpider(scrapy.Spider):
name = "hackernews"
allowed_domains = ["news.ycombinator.com"]
start_urls = ["https://news.ycombinator.com/"]
# safety limits so we don't run off into infinity
max_listing_pages = 2 # how many "More" pages to follow
max_threads_to_follow = 5 # how many comment threads to open total
# internal counters (Scrapy creates a new spider instance per run,
# so simple instance vars are fine here)
listing_pages_seen = 0
threads_followed = 0
def parse(self, response):
"""
Parse the main listing page:
- collect story data
- (optionally) follow each story's discussion thread
- (optionally) follow the "More" link for pagination
"""
self.listing_pages_seen += 1
# each story row on HN is <tr class="athing" id="...">
for row in response.css("tr.athing"):
story_id = row.attrib.get("id")
title_node = row.css(".titleline a:first-child")
title = title_node.css("::text").get(default="").strip()
url = title_node.attrib.get("href", "").strip()
# the row after each story row has metadata, including the comments link
subtext_row = row.xpath("following-sibling::tr[1]")
comments_rel = subtext_row.css("a[href^='item?id=']::attr(href)").get()
# output story info
if story_id and title and url:
yield {
"type": "story",
"story_id": story_id,
"title": title,
"url": url,
"source": "hackernews",
}
# follow the discussion thread, but don't go over our limit
if (
comments_rel
and self.threads_followed < self.max_threads_to_follow
):
self.threads_followed += 1
yield response.follow(
comments_rel,
callback=self.parse_discussion,
cb_kwargs={
"story_id": story_id,
"story_title": title,
"story_url": url,
},
)
# handle pagination: follow the "More" link if we're still under the limit
if self.listing_pages_seen < self.max_listing_pages:
more_link = response.css("a.morelink::attr(href)").get()
if more_link:
yield response.follow(more_link, callback=self.parse)
def parse_discussion(self, response, story_id, story_title, story_url):
"""
Parse a single story's discussion thread:
- count comments
- emit metadata about that thread
"""
comment_nodes = response.css(".commtext")
comment_count = len(comment_nodes)
yield {
"type": "discussion",
"story_id": story_id,
"story_title": story_title,
"story_url": story_url,
"discussion_url": response.url,
"comment_count": comment_count,
}
Understanding the code
This web crawler with Python goes beyond one page: it walks through Hacker News listings, follows a few “More” pages, and dives into some comment threads.
At the top, we set safety limits:
max_listing_pageslimits how many “More” pages we follow.max_threads_to_followcaps how many comment threads we open.
Inside parse(), Scrapy gives a response for each page. We extract all tr.athing rows (stories), then look at the next row for author, score, and comments. For each story:
- Yield a story item with title, URL, and ID.
- Optionally follow the comments link with
response.follow()and handle it inparse_discussion().
parse_discussion() counts comments and yields an updated item with comment_count. If there's a “More” link, the spider follows it until the page limit is hit.
Checking the result
Run the script once again:
uv run scrapy crawl hackernews -O stories.json
The stories.json file will contain two types of content. An actual story:
{"type": "story", "story_id": "45706792", "title": "Show HN: Diagram as code tool with draggable customizations", "url": "https://github.com/RohanAdwankar/oxdraw", "source": "hackernews"},
Or a discussion:
{"type": "discussion", "story_id": "45710065", "story_title": "Asbestosis", "story_url": "https://diamondgeezer.blogspot.com/2025/10/asbestosis.html", "discussion_url": "https://news.ycombinator.com/item?id=45710065", "comment_count": 93}
Cool!
Extracting and storing data with Scrapy
Now that our spider can safely follow links without going berserk, let's talk about actually extracting and saving data. Scrapy makes this part almost effortless. You can pick elements from HTML, clean them, and export everything to a file in one go.
Using XPath and CSS selectors
Scrapy supports both CSS selectors and XPath for finding stuff in HTML. You've already seen CSS examples like .titleline a:first-child. XPath does the same job but can reach deeper into complex structures when needed.
Here's a quick example you can drop into your parse() method:
def parse(self, response):
# CSS selector version
titles = response.css(".titleline a:first-child::text").getall()
# XPath version (does the same thing)
titles_xpath = response.xpath("//span[@class='titleline']/a[1]/text()").getall()
# print or yield a few just to test
for title in titles[:5]:
yield {"title": title.strip()}
Both methods return a list of strings, so use whichever feels more natural. CSS is shorter and cleaner for simple layouts, while XPath gives you laser precision when you need to move up or sideways in the HTML tree.
Pro tip: when testing selectors, always limit your output. Dumping a thousand elements just to check one selector is pure chaos. Start small, then scale once you're sure it's correct.
Exporting data to JSON or CSV
Scrapy can save your scraped data straight to a file. No open(), no manual loops, no JSON dumps.
To export results as JSON:
uv run scrapy crawl hackernews -O stories.json
To export as CSV:
uv run scrapy crawl hackernews -O stories.csv
The -O flag overwrites the file each time you run the spider (think "O for overwrite"). If you'd rather keep adding new results, use lowercase -o instead, and Scrapy will append to the file instead of replacing it.
Behind the scenes, Scrapy automatically converts each dictionary you yield in the spider into structured JSON or CSV rows. That means as long as you yield clean Python objects, your exports will stay tidy without any extra work.
Using pipelines for data transformation
By default, your spider just yields raw Python dicts like {"title": "...", "url": "..."}. Pipelines are where you clean that data before it gets written to JSON/CSV or sent to a database. Think of the pipeline as a final filter: every item the spider yields goes through it.
This is useful because real world data is messy. Titles have random whitespaces, links can be relative, and sometimes you scrape half-empty items you don't even want to keep.
Here's what we're about to build:
- Normalize titles (strip weird spacing)
- Turn relative links into absolute URLs
- Drop useless items (like missing title)
1. Spider that yields items
Here's a small Scrapy spider that collects story info and yields structured items. We'll keep limits so it doesn't crawl forever.
Edit the spiders/hackernews.py file:
import scrapy
from urllib.parse import urljoin
class HackernewsSpider(scrapy.Spider):
"""
Crawl the Hacker News front page, grab story info,
and (optionally) follow each story's discussion thread.
"""
name = "hackernews"
allowed_domains = ["news.ycombinator.com"]
start_urls = ["https://news.ycombinator.com/"]
# crawl safety limits so we don't go infinite
max_listing_pages = 1 # how many "More" pages we walk
max_threads_to_follow = 5 # how many discussions we dive into
# internal counters
listing_pages_seen = 0
threads_followed = 0
def parse(self, response):
"""
Parse a listing page:
- extract story metadata
- optionally follow its discussion thread
- optionally follow the "More" pagination link
"""
self.listing_pages_seen += 1
for row in response.css("tr.athing"):
story_id = row.attrib.get("id", "").strip()
# main story link (title + outbound URL)
title_node = row.css(".titleline a:first-child")
title = title_node.css("::text").get(default="").strip()
raw_url = title_node.attrib.get("href", "").strip()
# subtext row lives right after this row
subtext_row = row.xpath("following-sibling::tr[1]")
# find all links that look like item?id=..., last one is usually "X comments"
thread_links = subtext_row.css("a[href^='item?id=']")
comments_rel = None
comment_count = 0
discussion_url = None
if thread_links:
comments_a = thread_links[-1]
comments_rel = comments_a.attrib.get("href", "").strip() # e.g. "item?id=12345"
comments_text_raw = comments_a.css("::text").get(default="").strip()
# comments_text_raw might be "29 comments" or "discuss"
first_token = comments_text_raw.split("\xa0")[0].split(" ")[0]
# try to parse number of comments
if first_token.isdigit():
comment_count = int(first_token)
# build absolute discussion URL
if comments_rel:
discussion_url = urljoin("https://news.ycombinator.com/", comments_rel)
# item we emit for this story
story_item = {
"story_id": story_id,
"title": title,
"url": raw_url,
"discussion_url": discussion_url,
"comment_count": comment_count,
}
# yield story from the listing page
yield story_item
# follow the thread page (but don't overdo it)
if (
comments_rel
and self.threads_followed < self.max_threads_to_follow
):
self.threads_followed += 1
yield response.follow(
comments_rel,
callback=self.parse_discussion,
cb_kwargs={"story_item": story_item},
)
# pagination: follow "More" if we're still under the page limit
if self.listing_pages_seen < self.max_listing_pages:
more_link = response.css("a.morelink::attr(href)").get()
if more_link:
yield response.follow(more_link, callback=self.parse)
def parse_discussion(self, response, story_item):
"""
Parse the comments page for a single story.
We update/override comment_count with the actual count we see.
"""
comment_nodes = response.css(".commtext")
real_count = len(comment_nodes)
yield {
"story_id": story_item["story_id"],
"title": story_item["title"],
"url": story_item["url"],
"discussion_url": response.url,
"comment_count": real_count,
}
Understanding the spider
This spider crawls the Hacker News front page, grabs stories, and optionally follows their discussion threads.
HackernewsSpider inherits from scrapy.Spider, and Scrapy runs its parse() method automatically for each page.
In the parse() function:
- Loop through each story row (
tr.athing). - Extract ID, title, story URL, comment link, and count.
- Yield each as a dictionary.
- Optionally follow the comment link to
parse_discussion()if under limit.
parse_discussion() just counts comments and yields updated data. If there's a “More” button, the spider follows it until the page limit is hit.
The key idea: the spider only finds and reports data. Cleanup happens later in the pipeline.
2. Cleaning data with a pipeline
Now that the spider is doing its job, it's time for the pipeline to step in and clean things up. Pipelines are great for transforming or validating data before it's written to a file or database.
Here's what this one does:
- trims weird spacing in titles
- turns all URLs into absolute URLs
- ensures missing fields don't crash the export
- drops any useless items (like ones with no title)
The pipeline lives in hackernews_crawler/pipelines.py (inside the same folder as settings.py).
from itemadapter import ItemAdapter
from urllib.parse import urljoin
from scrapy.exceptions import DropItem
class HackernewsCrawlerPipeline:
def process_item(self, item, spider):
adapter = ItemAdapter(item)
# clean up title
title = adapter.get("title")
if not title:
raise DropItem(f"Missing title for story {adapter.get('story_id')}")
adapter["title"] = title.strip()
# normalize main URL to absolute
raw_url = adapter.get("url", "")
if raw_url:
adapter["url"] = urljoin("https://news.ycombinator.com/", raw_url)
# normalize discussion URL if it exists
discussion_url = adapter.get("discussion_url")
if discussion_url:
adapter["discussion_url"] = urljoin(
"https://news.ycombinator.com/",
discussion_url,
)
# coerce comment_count to int
count_val = adapter.get("comment_count", 0)
try:
adapter["comment_count"] = int(count_val)
except (TypeError, ValueError):
adapter["comment_count"] = 0
return item
What's happening here:
ItemAdaptermakes it easy to handle both plain dicts and ScrapyItemobjects in the same way.- We validate and clean each field in a consistent, predictable order.
- If something looks broken (like a missing title),
DropItemstops it from going further — this prevents garbage data from polluting your final output. - URLs are made absolute using
urljoin, which helps avoid relative paths likeitem?id=12345showing up in your dataset.
This pipeline now guarantees that every exported record has clean, consistent data.
3. Enabling the pipeline
Scrapy won't automatically run your pipeline; you need to enable it in your project's settings.py. Add this near the bottom of the file:
ITEM_PIPELINES = {
"hackernews_crawler.pipelines.HackernewsCrawlerPipeline": 300,
}
A few quick notes:
- The string
"hackernews_crawler.pipelines.HackernewsCrawlerPipeline"must match your actual module path. If your Scrapy project folder has a different name, update it accordingly. - The number
300is the pipeline's priority. Lower numbers run first, higher ones run later. If you stack multiple pipelines, Scrapy processes them in ascending order, like:
ITEM_PIPELINES = {
"hackernews_crawler.pipelines.CleanPipeline": 300,
"hackernews_crawler.pipelines.SaveToDBPipeline": 800,
}
4. Checking the result
Run the scraping as usual:
uv run scrapy crawl hackernews -O stories.json
In your JSON file you'll see something like:
{"story_id": "45711279", "title": "Let's Help NetBSD Cross the Finish Line Before 2025 Ends", "url": "https://mail-index.netbsd.org/netbsd-users/2025/10/26/msg033327.html", "discussion_url": "https://news.ycombinator.com/item?id=45711279", "comment_count": 55}
Optimizing your Python web crawler
By now, you've got a fully working Scrapy project that crawls and cleans data. Next step is making it smarter, faster, and friendlier to the web.
Crawling responsibly and at scale
When you scale up, crawling isn't just about speed, it's also about respect. Websites aren't built to handle hundreds of requests per second from a single script. Crawling responsibly means balancing efficiency with politeness.
A few golden rules before you hit "go" on a big crawl:
- Always check
robots.txtto see what's allowed. - Add delays between requests to avoid hammering a server.
- Identify yourself clearly in your
User-Agent. - If you need large-scale crawling, distribute the load across multiple machines instead of one huge bot.
Scrapy already gives you everything you need for this, so it's just about tweaking the right knobs.
Respecting robots.txt and rate limits
Every decent crawler checks a site's robots.txt file before fetching pages. It's the website's way of saying, "You can crawl this, but please don't touch that." Scrapy has a built-in switch for it enabled by default in settings.py:
ROBOTSTXT_OBEY = True
You can also slow down your requests using a few key settings:
# settings.py
DOWNLOAD_DELAY = 1.5 # seconds between requests
CONCURRENT_REQUESTS_PER_DOMAIN = 4
AUTOTHROTTLE_ENABLED = True
DOWNLOAD_DELAYsets how long to wait between requests.CONCURRENT_REQUESTS_PER_DOMAINlimits how many parallel requests go to the same site.AUTOTHROTTLE_ENABLEDlets Scrapy adjust speeds automatically based on server response times.
Using user agents and throttling
Most websites block bots that look suspicious or anonymous. Adding a real, honest user agent helps. In settings.py:
USER_AGENT = "MyFriendlyCrawler (+https://example.com/contact)"
You can also rotate multiple user agents or proxies for heavier crawls, but start simple. Scrapy's AutoThrottle and middleware system can handle dynamic delays and retries for you.
If you need to go beyond polite crawling, like handling JavaScript-heavy sites, pair Scrapy with a service like ScrapingBee to fetch pre-rendered pages without managing browsers yourself.
Distributed crawling and anti-bot strategies
Once you're comfortable with single-machine crawling, scaling out is the next step. Scrapy can easily run across multiple instances or even clusters using tools like:
- Scrapyd for running and monitoring multiple spiders remotely
- Scrapy-Redis for distributed crawling with shared queues
- Cloud workers or containerized crawlers (Docker + EC2, etc.)
But remember: more bots don't mean more freedom. Always respect site limits and use APIs when available.
In short:
- Start small and polite
- Use built-in Scrapy throttling features
- Scale horizontally when needed
- Let proxy and rendering APIs handle the tough parts
Simplifying Complex Crawling Tasks with ScrapingBee
Learning how to crawl a website is fun when you're dealing with static pages. But once JavaScript, rate limits, browser fingerprints, and anti-bot systems show up, things get messy fast. That’s usually the point where a simple script turns into a whole infrastructure project.
ScrapingBee is built to remove that pain. Instead of spending time wiring up headless browsers, rotating proxies, and retry logic, you send a request to the API and get back the page content or structured data you need. If you're trying to create web crawler workflows that actually scale, that tradeoff can save a lot of engineering time.
This is especially useful for Python web crawling projects. You can keep your code simple while offloading the hard parts: JavaScript rendering, IP rotation, anti-bot handling, and browser management. So rather than maintaining a fragile stack, you focus on the extraction logic and the data you actually care about.
It also works well if you want to create web crawler with Python for more than just toy examples. Maybe you're scraping product pages, news sites, search results, or any site that loads data dynamically. In those cases, ScrapingBee gives you a cleaner path from “this page is annoying to scrape” to “this data is in my app.”
Another nice part is flexibility. You can use ScrapingBee as a full replacement for browser-based scraping, or mix it into an existing pipeline only when pages get difficult. That makes it a practical upgrade path when you're learning how to crawl a website and want something more reliable without rebuilding everything from scratch.
If you want a more advanced option for structured extraction, check out ScrapingBee’s AI Web Scraping API.
Ready to crawl at scale? Try ScrapingBee
With the default settings, Scrapy crawls about 600 pages per minute for a website like IMDb. Crawling 130 million pages would take about half a year at that speed with a single robot. If you need to crawl multiple websites, it can be better to launch separate crawlers for each big website or group of websites. If you are interested in distributed web crawls, you can read how a developer crawled 250M pages with Python in less than two days using 20 Amazon EC2 machine instances.
ScrapingBee is an API that handles the heavy lifting for you:
- it fetches pages with a real browser (so JS-heavy sites render perfectly)
- rotates IPs and user agents automatically
- respects rate limits and keeps your requests stable
- integrates easily with your existing Scrapy or
requestssetup
If you're serious about growing your Python crawler into a production-grade data pipeline, ScrapingBee saves you the pain of dealing with captchas, throttling, and infrastructure. Plug it in, focus on your data, and let it handle the rest. Give it a try at scrapingbee.com, and your crawler will thank you.
Conclusion
And that's the full ride from a tiny requests script to a scalable Scrapy setup with proper pipelines, throttling, and all the good habits baked in.
You've learned how to build a working crawler, clean up your data, and keep things polite while exploring the web. Most importantly, you've seen how to grow from a few lines of code to something you could actually run at scale.
Python makes web crawling surprisingly easy, and Scrapy takes it to another level. When you hit bigger challenges like JavaScript rendering or proxy management, tools like ScrapingBee fit right in to keep your crawler fast and reliable.
So start small, experiment, and build your own mini search engine or data collector.
FAQ
What is the difference between web crawling and web scraping?
Web crawling is about finding pages by following links automatically. Web scraping is about extracting data from those pages, like titles, prices, or reviews.
What are some common use cases for Python web crawlers?
Python web crawlers are often used for indexing pages, monitoring prices, tracking SEO changes, collecting research data, and building datasets for AI or analytics.
How can I build a basic web crawler in Python?
You can start with requests and BeautifulSoup: fetch a page, extract links, and loop through them. If you need something more scalable, Scrapy is the usual next step.
What are the advantages of using Scrapy for web crawling?
Scrapy is fast, asynchronous, and built for scale. It also handles retries, scheduling, deduplication, and data pipelines out of the box.
Do I need permission to crawl a website?
Not always, but you should still be careful. Check the site's robots.txt, respect rate limits, and avoid crawling private, sensitive, or login-protected content without permission.
How do I handle JavaScript-heavy websites?
For JavaScript-heavy sites, a basic HTTP request often isn’t enough. You can use browser tools like Playwright or an API like ScrapingBee to render the page first.
Can I use AI or machine learning with crawled data?
Yes. Once your data is structured and cleaned, you can analyze it with pandas, train models, or use it in LLM and analytics workflows.
How do I avoid getting blocked while crawling?
Use polite request rates, realistic headers, and delays between requests. For tougher sites, rotating proxies or a service like ScrapingBee can make crawling more reliable.


