Web scraping describes the ability to extract or “scrape” data from the internet using an automated program. These programs conduct web queries and retrieve HTML data, which is then parsed to obtain the required information.
Whether you need to collect large amounts of data, data from multiple sources, or data not available through APIs, automating the extraction of this information can save you a lot of time and effort.
In this tutorial, you’ll learn how to use the Parsel Python library to create your own web scraping scripts. Specifically, you’ll learn how to parse HTML documents using Selectors and how to extract data from HTML markup using CSS and XPath. You’ll also learn about removing the elements using the selector object. By the end of the article, you’ll be able to create your own scraping scripts and complex expressions to retrieve data from a web page using the Parsel library.

Implementing Parsel
To use the Parsel library, you must first install it in a virtual environment ; this is required to keep your development environment separate.
To install venv, run the following command in your terminal:
pip install venv
Next, create a new virtual environment named env:
python -m venv env
Then use the following command to activate your virtual environment:
source env\Scripts\activate
You will see (env) in the terminal, which indicates that the virtual environment is activated.
Now install the Parsel library in the newly created virtual environment with the following command:
pip install parsel
To get website content, you also need to install the requests HTTP library:
pip install requests
After installing both the Parsel and Requests libraries, you’re ready to start writing some code.
Starting with Parsel
Here, you’ll create a new file called my_scraper.py, import the appropriate modules, and then use Requests to acquire the website HTML code. You will use the https://quotes.toscrape.com/ site to run the scraping script on:
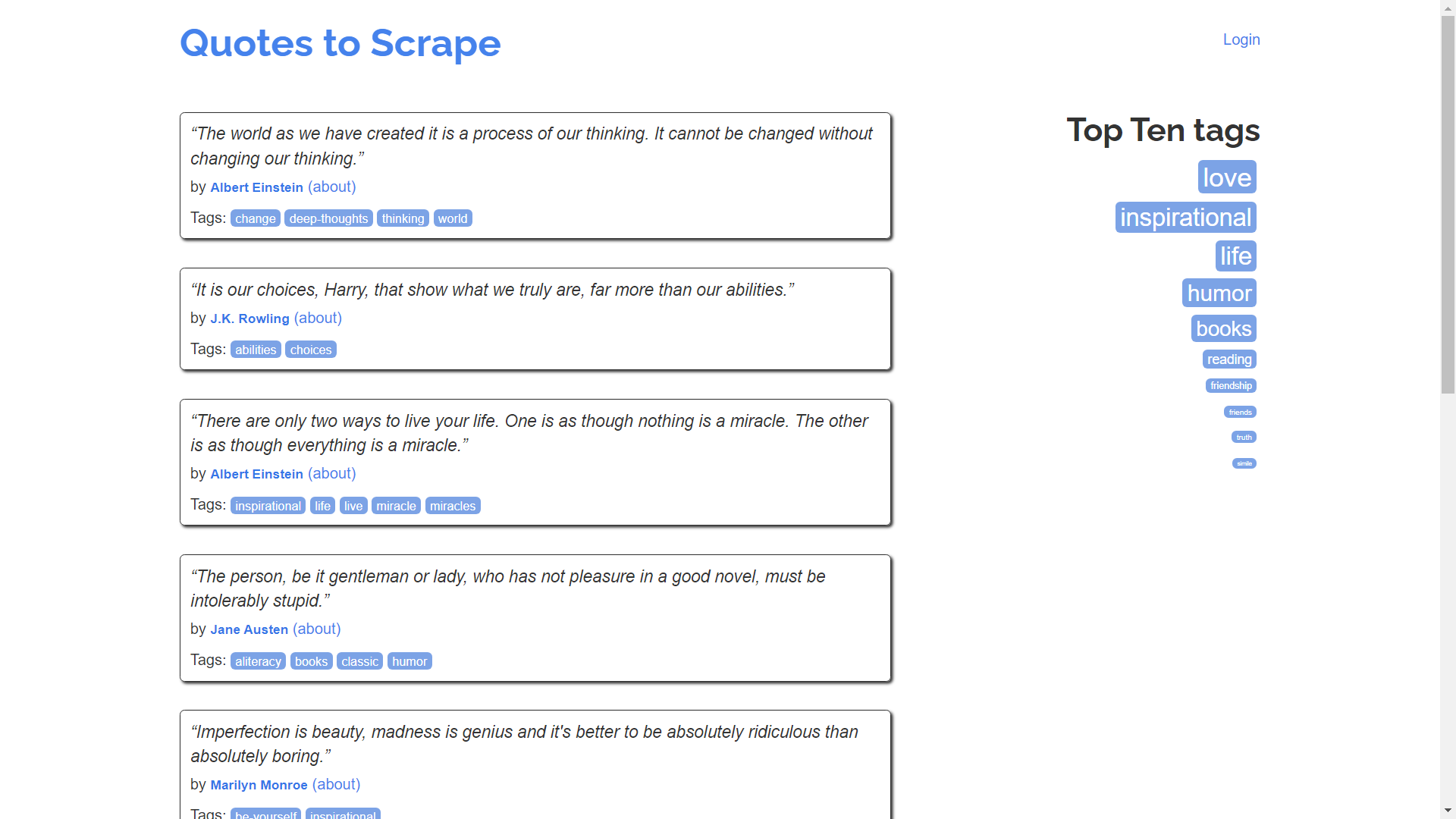
For reference, you will look at the HTML code of the web page using view-source:https://quotes.toscrape.com/:
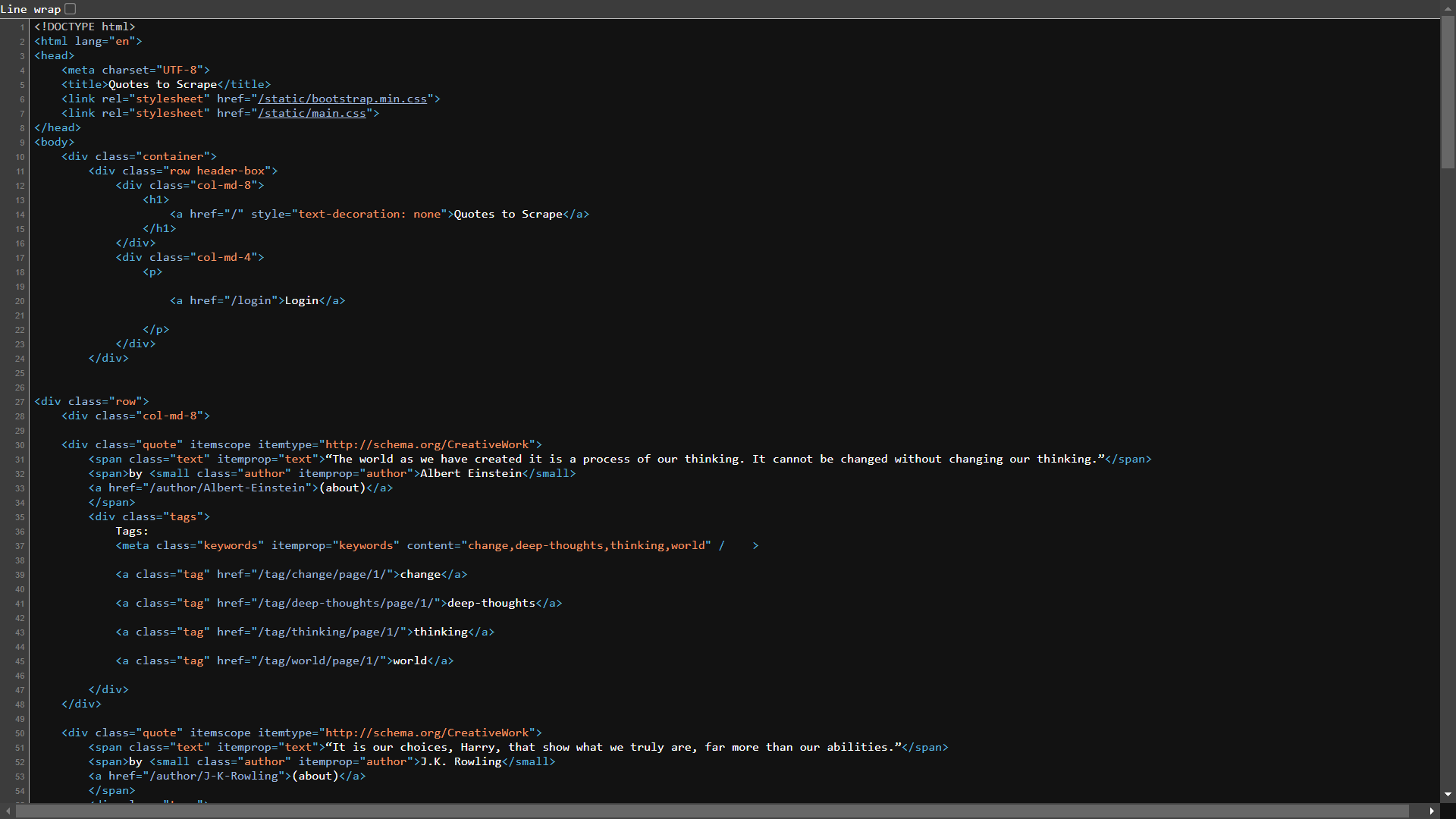
Type the following code into your new my_scraper.py file:
import parsel
import requests
URL = "https://quotes.toscrape.com/"
response = requests.get(URL).text
Creating Selectors
Now you will create an instance of the built-in Selector class using the response returned by the Requests library. The Selector class allows you to extract data from HTML or XML documents using CSS and XPath by taking a required argument called text. After creating the selector object, the HTML document is parsed in such a way that then you can query it using the CSS and XPath expressions. Append your file with following line of code to create a selector object:
selector = parsel.Selector(text=response)
In order to play with Parsel’s Selector class, you’ll need to run Python in interactive mode . This is important because it saves you from writing several print statements just to test your script. To enter the REPL , run the Python file with the -i flag in the terminal:
python -i my_scraper.py
After running the above command, you will see >>> in your terminal, which indicates that you have successfully entered interactive mode.
Extracting Text Using CSS Selectors
Type the following code in the shell to extract the title of the page:
>>> selector.css('title')
[<Selector xpath='descendant-or-self::title' data='<title>Quotes to Scrape</title>'>]
>>>
Here, a query argument is passed to the css function, which can be the name of a tag, class, or id. You picked the title tag from the HTML document in the preceding code, which returned a SelectorList object; this is nothing more than a list of all the tags that matched your query. In this case, there was only one title tag. If you look at the output, you’ll notice that it doesn’t reveal the contents of the title tag. The Parsel library includes functions called get() and getall() to show the contents of the title tag. These functions serialize the Selector element to show only the content of the object.
Run the following line of code in the shell:
>>> selector.css('title::text').get()
You will see the following output:
'Quotes to Scrape'
The ::text CSS pseudo-element is used to select the inner text node of an element. Similarly, you can use . for class, # for id selection, and [attrib=value] to search using the tag’s attribute and its value. Below are some examples for each; run the following code in the REPL to see the output for each scenario.
To get all the <small> tags with class author and get only the inner text node, run this code:
>>> selector.css('small.author::text').getall()
To get the first tag with id keyword and get only the inner text node, run the following:
>>> selector.css('#keyword::text').get()
Finally, to get all the tags with the itemprop attribute with value text, run this code:
>>> selector.css('[itemprop=text]').getall()
It is worth noting that the get() function serializes the first element in the SelectorList object, while the getall() function goes through each Selector in SelectorList and returns the list with serialized data for each Selector.
Extracting Text Using XPath Selectors
In Parsel, XPath selectors can also be used to extract text. CSS selectors are extremely powerful and effective, and they are generally easier to read than XPath selectors. The choice between XPath and CSS is a matter of personal preference. The primary distinction is that CSS selectors can only move within the hierarchical sequence, but XPath selectors can go both up and down the markup hierarchy.
Type the following code in the shell to get all the div tags with the quotes class on the web page:
>>> selector.xpath("//div[@class='quote']")
You should get something like this after running the above code:
[<Selector xpath="//div[@class='quote']" data='<div class="quote" itemscope itemtype...'>,
<Selector xpath="//div[@class='quote']" data='<div class="quote" itemscope itemtype...'>,
<Selector xpath="//div[@class='quote']" data='<div class="quote" itemscope itemtype...'>,
<Selector xpath="//div[@class='quote']" data='<div class="quote" itemscope itemtype...'>]
In XPath, every query must begin with //, and // must be added to get into the child element. The attribute and values are passed in the [], with @ in front of the attribute name. To extend the above query, type the following code in the shell. This returns all the quote statements in the <span> tag that have a class of text within the<div> tag with class quote.
>>> selector.xpath("//div[@class='quote']//span[@class='text']//text()").getall()
You will see the following output:
['“The world as we have created it is a process of our thinking. It cannot be '
'changed without changing our thinking.”',
'“It is our choices, Harry, that show what we truly are, far more than our '
'abilities.”',
'“There are only two ways to live your life. One is as though nothing is a '
'miracle. The other is as though everything is a miracle.”',
'“A day without sunshine is like, you know, night.”']
The inner text of the element is obtained using the text() method. This function can also be used to match text.
To acquire all of “Albert Einstein’s” quotes, type the following Parsel query in the shell:
>>> selector.xpath("//div[@class='quote']//small[text()='Albert Einstein']/../../span[@class='text']//text()").getall()
In the query above, you can see that you’re using XPath to navigate up the hierarchy. First, you picked the elements with author “Albert Einstein,” and then you went up the hierarchy to see all of the quotes. Finally, the getall() function was used to serialize the selector object to show only the quote’s statement. This is the most significant distinction between CSS and XPath selectors.
Removing Elements
The Parsel library also has a function to remove elements from the selector object. The delete() function should be used with caution since once elements have been removed, they cannot be recovered. However, the remove() function could be useful to reduce the size of the response in the memory.
First, you’ll have to check if the selector object has a <div> with class tags:
>>> selector.css('div.tags')
The above code will generate the following output:
[<Selector xpath="descendant……………] # Output Hidden
Now you can remove the <div> with class tags using the remove() function:
>>> selector.css('div.tags').remove()
After running the preceding code, checking the selector object with the following code will result in an empty list because the element has been removed from the selector object.
>>> selector.css('div.tags')
[]
Creating Your Web Scraping Script
Until now, you’ve been working in a REPL to test Parsel’s CSS and XPath selections. In this section, you will create a program that scrapes each quote from the web page and stores the quotes in a nicely formatted text file.
Here, you’ll scrape each quote section one by one and get the quote’s inner text, author, and tags. Since you are storing all the quotes in a text file, you’ll have to open a file in write mode using the with block. Type the following code in your Python file:
import parsel
import requests
URL = "https://quotes.toscrape.com/"
response = requests.get(URL).text
selector = parsel.Selector(text=response)
with open("amazing quotes.txt", 'w') as file:
file.write("AMAZING QUOTES\n\n")
file.write("*=*"*30)
file.write('\n\n')
for quote_section in selector.css('div.quote'):
quote = quote_section.xpath('.//span[@class="text"]//text()').get()
author = quote_section.xpath('.//small[@class="author"]//text()').get()
tags = quote_section.xpath('.//div[@class="tags"]//a[@class="tag"]//text()').getall()
tags = ', '.join(tags)
file.write(f'\n\n{quote}\n\nBy: {author}\n\nTags: {tags}\n\n')
file.write("*=*"*30)
file.write('\n\n')
Using the code above, the quote information will be extracted and saved in the text file. It’s worth noting that the XPath query contains a dot (.) in the beginning. This is important because it’s used to query the instance of Selector in a relative fashion rather than searching the entire web page.
When you run this code, an amazing quotes.txt file will be created after the quotes have successfully been extracted.
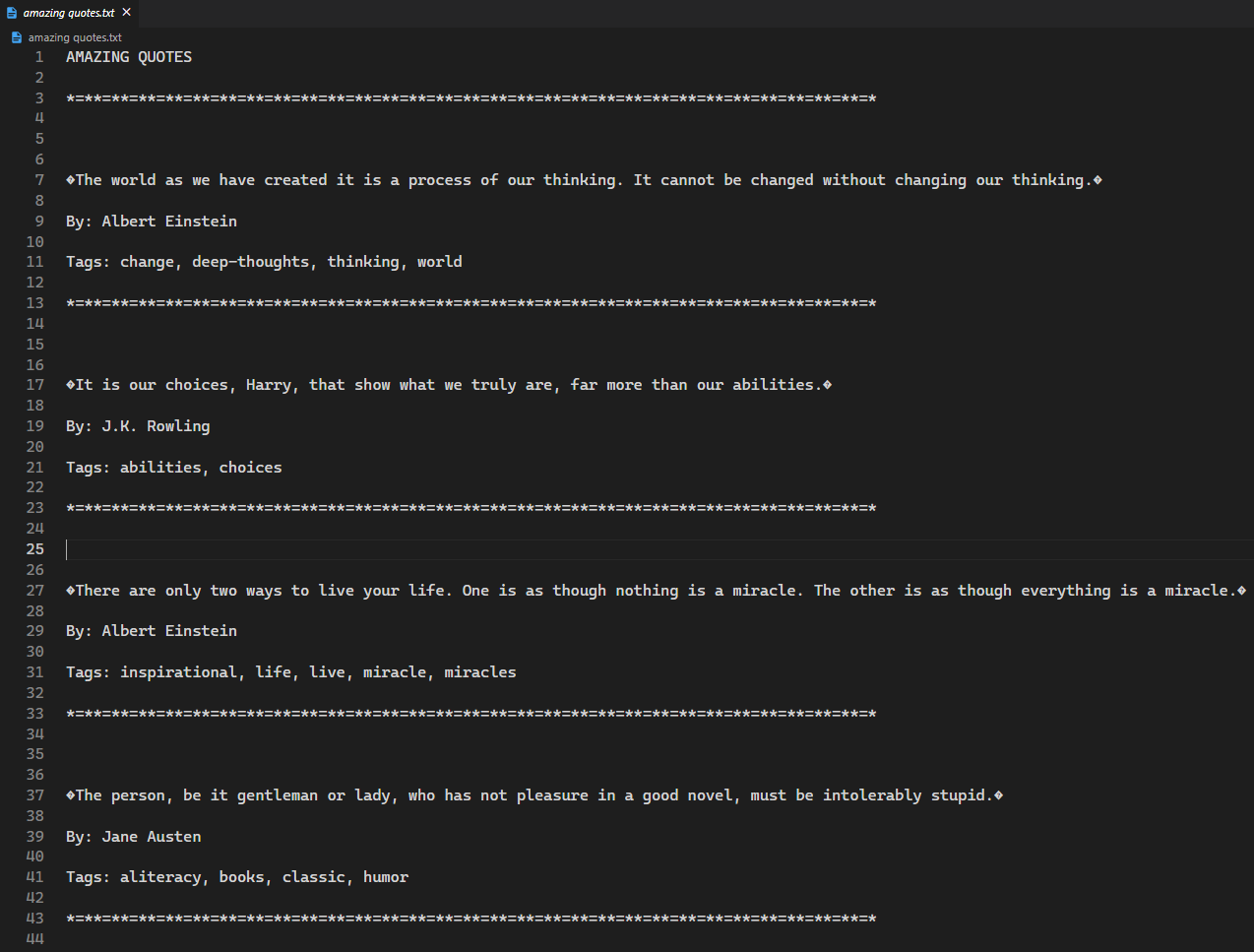
If you see a file with the above content, then congratulations on creating your first web scraper using the Parsel library! Parsel has a variety of useful functions; for a full list, check out the Parsel documentation .
Conclusion
While libraries like Beautiful Soup , Scrapy , and Selenium might be overkill, Parsel is a great option for simple web scraping. Parsel’s simple methods and Selectors provide all of the functionality required for basic scraping scripts, whereas other libraries contain a slew of features that you’ll never use in a simple scraping script—such as browser automation, telnet console, logging, and emails, which aren’t required when all you want to do is extract content from a static website.
In this post, you learned about the Parsel library’s key features, including the Selector class and the two methods for extracting elements from your selector object: CSS and XPath. You also looked at how the serializer functions get() and getall() extract the readable form of the elements and covered text searches and element hierarchical order. Finally, you used the Parsel library and Python’s file-handling capabilities to develop a full-fledged web scraper that extracted all of the quotes in a text file. Now that you’ve learned the basics, take some time to play with the Parsel library by developing more complex scrapers.

I am a Python/Django Developer always ready to learn and teach new things to fellow developers.


