In this tutorial, you will learn how to learn how to scrape websites using Visual Basic.
Don't worry—you won't be using any actual scrapers or metal tools. You'll just be using some good old-fashioned code. But you might be surprised at just how messy code can get when you're dealing with web scraping!
You will start by scraping a static HTML page with an HTTP client library and parsing the result with an HTML parsing library. Then, you will move on to scraping dynamic websites using Puppeteer, a headless browser library. The tutorial also covers basic web scraping techniques, such as using CSS selectors to extract data from HTML pages.
By the end of this article, you will have gained a strong understanding of web scraping with Visual Basic.

Understand the Site to Be Scraped
Before starting the web scraping process, you must understand the structure and content of the website you want to scrape to help you determine what data to extract and how to extract it. For example, you may want to extract all the links, images, or text on a page. Understanding the HTML structure of the page will help you identify the appropriate tags or attributes to extract this data.
In the first part of this tutorial, you'll scrape this Wikipedia page, so let's discuss its structure and content to give you an idea of what to look out for.
Wikipedia articles typically have several sections, including the article text, table of contents, and reference section. Each of those sections follows a typical HTML structure, which helps you to determine the relevant information for extraction. Some sections contain information as unordered lists, with each list item (li) containing a hyperlink (a) element with the usual hyperlink settings: a URL and a descriptive text; the URL points to another page with further information and can be accessed via the href attribute and the text summarises the content. Other sections contain tables with row (tr) and table heading (th) elements that have a class name of sidebar-heading. The table data (td) elements contain the unordered lists of topics related to that section.
Set Up a Visual Basic Project
Next, you have to set up a Visual Basic project.
If you haven't installed Visual Studio yet, you can download it from Microsoft's website. You need Visual Studio because it provides the necessary environment for creating Visual Basic Windows Forms Applications.
Next, open Visual Studio and select Create a new project from the start menu. In the new project window, select Visual Basic as the language then Windows Forms App (.NET Framework) as the project type, as shown in the screenshot below:
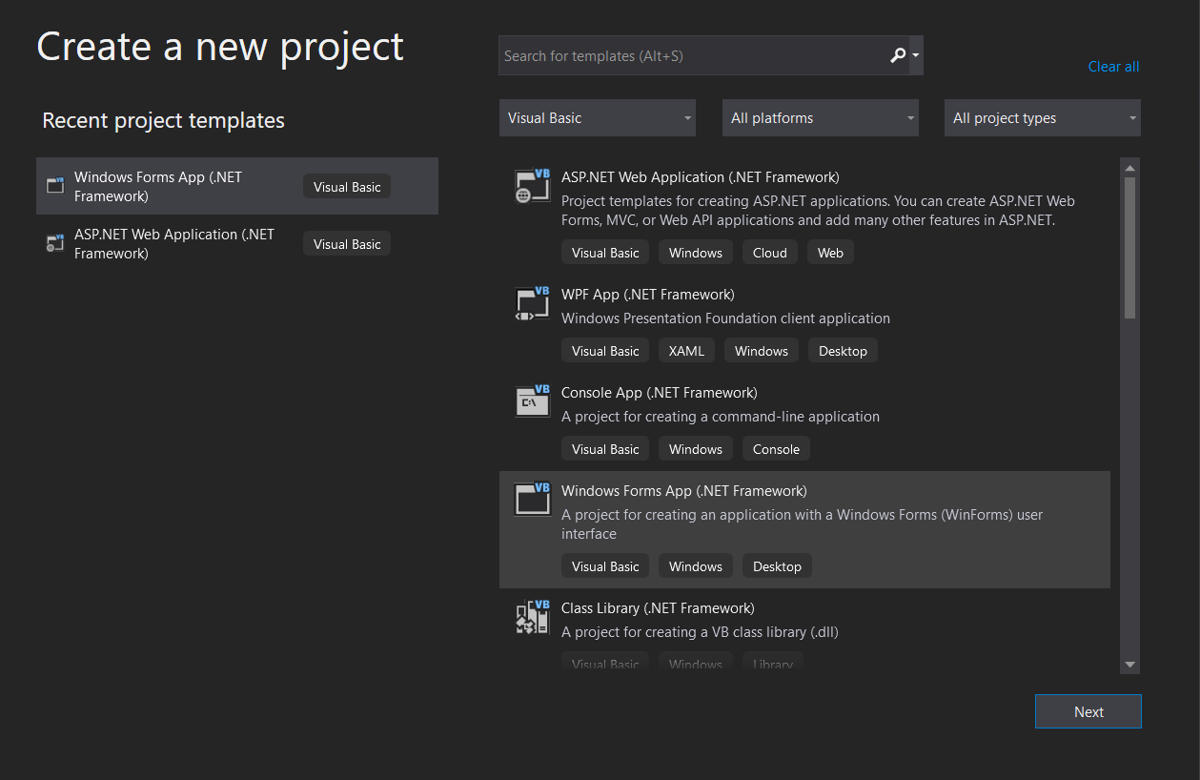
Choose a name for your project and select a location on your computer where you want to save it.
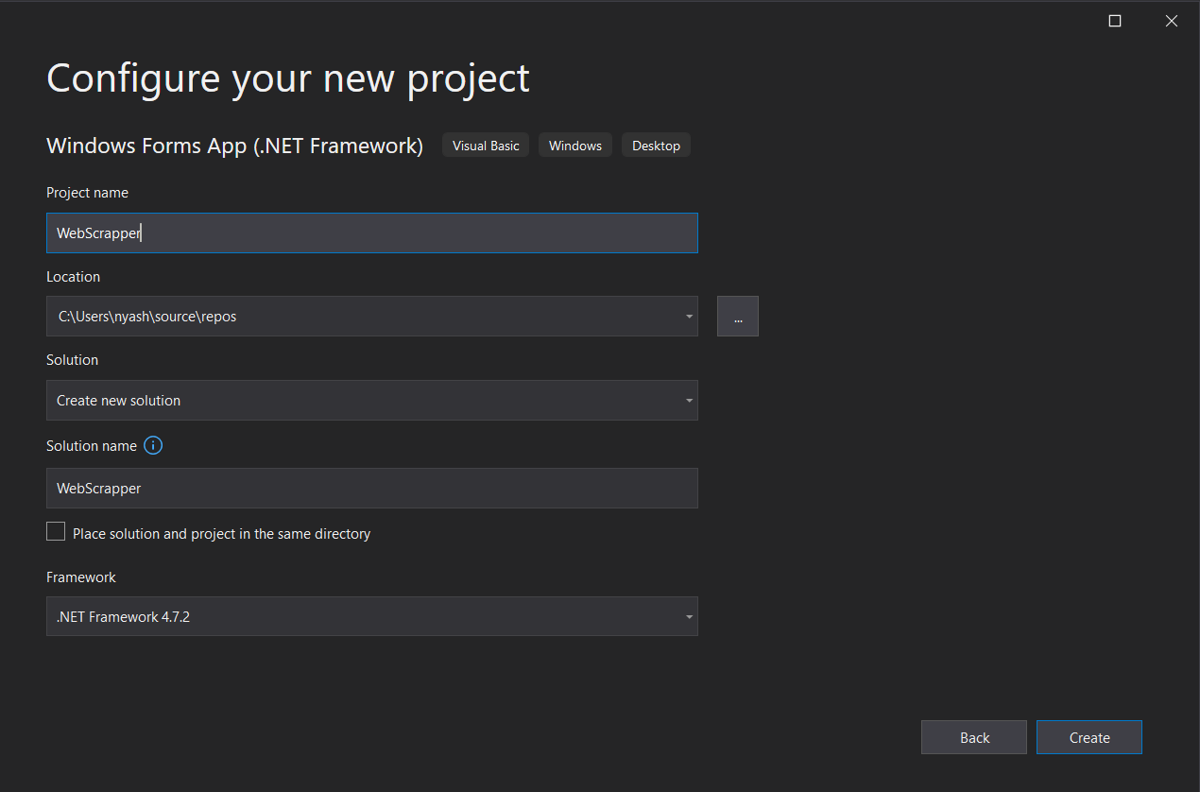
Lastly, you have to add the HtmlAgilityPack NuGet package to your project, an HTML parsing library that provides a convenient way to parse HTML pages and extract information from them. It allows you to access HTML nodes and manipulate their properties and contents, making it an essential tool for web scraping.
To use the HtmlAgilityPack library in your Visual Basic project, add the NuGet package to your project as follows:
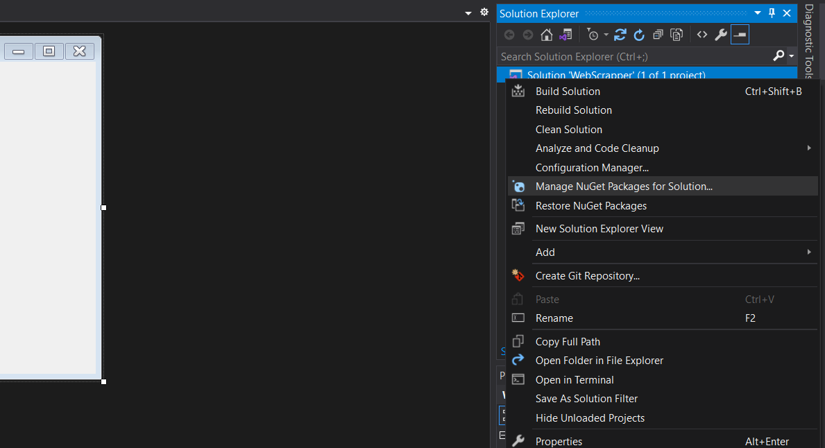
- In the Solution Explorer, right-click on your project.
- Select Manage NuGet Packages from the context menu.
- In the Browse tab, search for HtmlAgilityPack.
- Click Install.
Create the User Interface
The last thing you need to do before you can start scraping is create a user interface (UI) for your project to provide an interactive way for users to input the URL of the website they want to scrape and see the results. The UI can also be used to display any errors or issues that arise during the scraping. A well-designed UI makes web scraping more user-friendly and efficient.
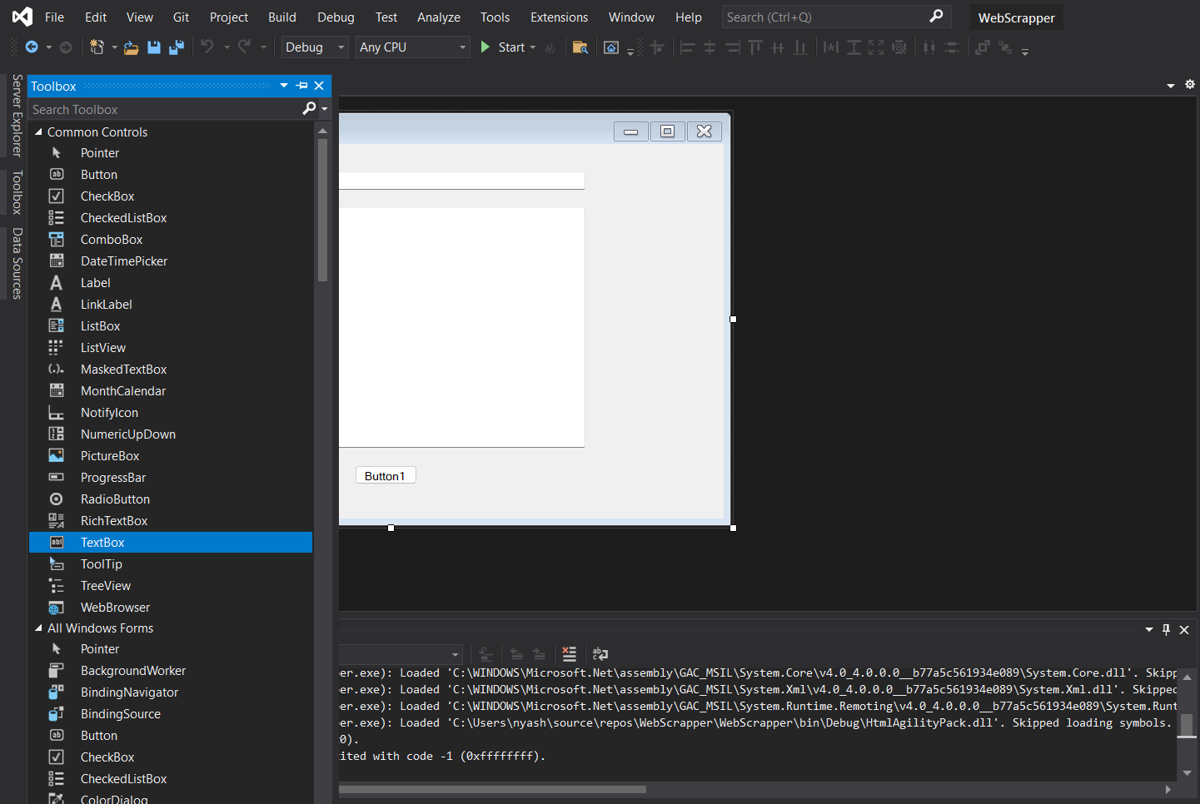
To add the controls needed for the scraping process, follow these steps:
- Double-click on the form (usually called Form1.vb) in the Solution Explorer to open it in the designer.
- From the Toolbox, drag a TextBox control onto the form. This will be used to input the URL of the Wikipedia page to be scraped.
- Drag another TextBox control onto the form, and set it to Multiline. This will be used to display the scraped data.
- Drag a Button control onto the form. This will be used to initiate the scraping process.
- In the Properties window, change the Name property of each control you just added to something descriptive, like urlTextbox, outputTextbox, and scrapeButton.
- Adjust the position and size of the controls as desired.
Your form should now look something like this:
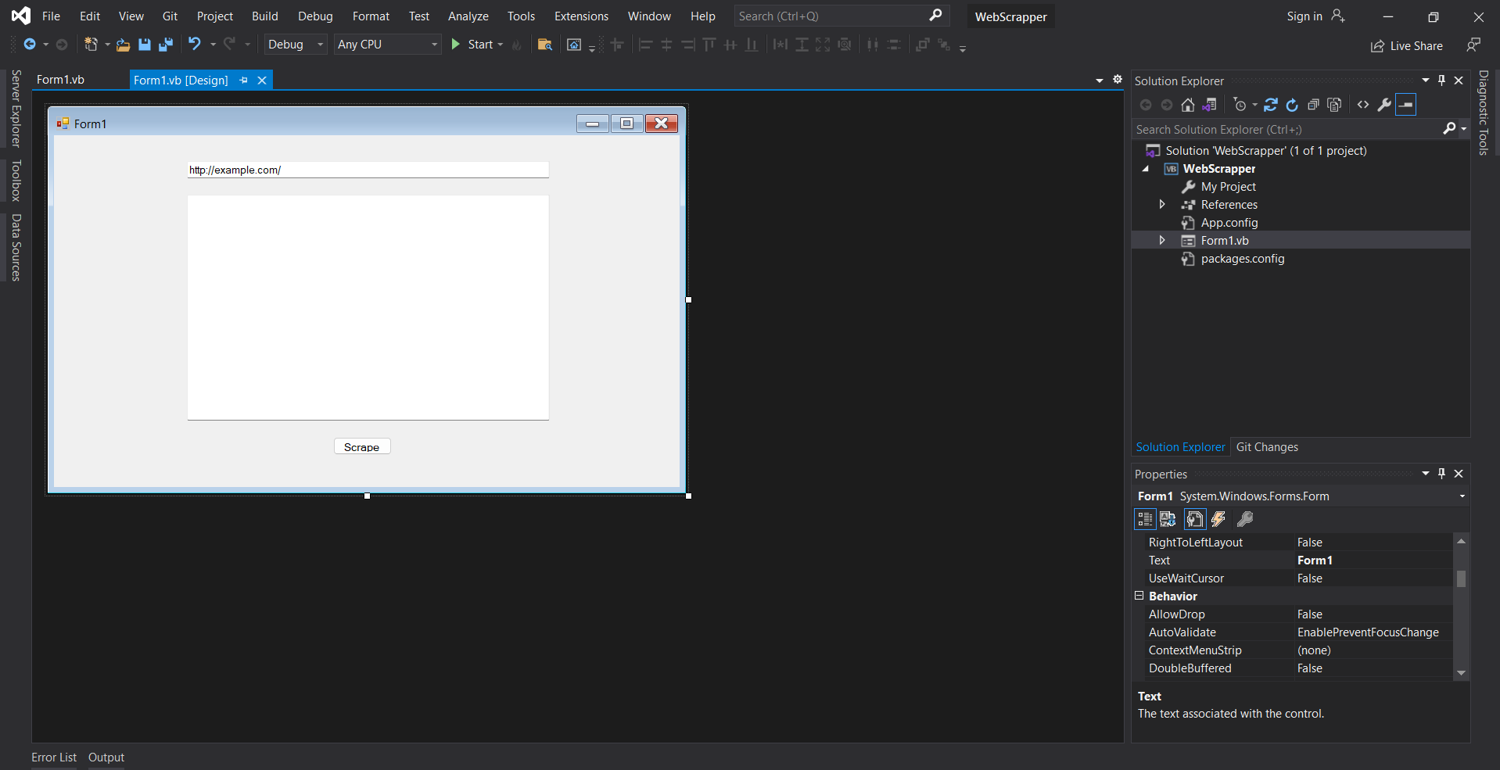
Scrape the Website
And finally, you're ready to do some scraping!
As mentioned earlier, you'll be using HtmlAgilityPack package in the following code to load and parse the site content of the given Wikipedia page:
Public Class Form1
Private Sub Button1_Click(sender As Object, e As EventArgs) Handles scrapeButton.Click
Dim url As String = urlTextbox.Text
Dim webClient As New System.Net.WebClient()
Dim html As String = webClient.DownloadString(url)
Dim htmlDoc As New HtmlAgilityPack.HtmlDocument()
htmlDoc.LoadHtml(html)
Dim headingNode As HtmlAgilityPack.HtmlNode = htmlDoc.DocumentNode.SelectSingleNode("//h1")
Dim paragraphNode As HtmlAgilityPack.HtmlNode = htmlDoc.DocumentNode.SelectSingleNode("//p")
outputTextbox.Text = headingNode.InnerText + vbCrLf + vbCrLf + paragraphNode.InnerText
Dim links As HtmlAgilityPack.HtmlNodeCollection = htmlDoc.DocumentNode.SelectNodes("//div[@class='div-col']//a | //div[@class='div-col']//ul")
If links IsNot Nothing Then
For Each link As HtmlAgilityPack.HtmlNode In links
outputTextbox.AppendText(vbCrLf + link.GetAttributeValue("href", "") + vbCrLf)
Next
Else
outputTextbox.AppendText(vbCrLf + "Links not found." + vbCrLf)
End If
Dim tableHeadingNodes As HtmlAgilityPack.HtmlNodeCollection = htmlDoc.DocumentNode.SelectNodes("//table[contains(@class, 'sidebar')][contains(@class, 'nomobile')][contains(@class, 'nowraplinks')][contains(@class, 'hlist')]//th[contains(@class, 'sidebar-heading')]")
If tableHeadingNodes IsNot Nothing Then
For Each tableHeadingNode As HtmlAgilityPack.HtmlNode In tableHeadingNodes
outputTextbox.AppendText(vbCrLf + tableHeadingNode.InnerText + vbCrLf)
Next
Else
outputTextbox.AppendText(vbCrLf + "Table headings not found." + vbCrLf)
End If
End Sub
End Class
Add this code to your project by following these steps:
- Click on the View menu in Visual Studio.
- Select the Code option from the drop-down menu, or use the shortcut key F7.
- Paste the code into the code editor that appears.
- Save the changes.
When a user enters the URL of a web page to be scraped, the code downloads the HTML content of that page. The downloaded HTML content is then parsed using the HtmlAgilityPack.HtmlDocument class to extract data from it.
The code shows how to extract links and tables from the HTML content using the SelectNodes() method of the HtmlAgilityPack.HtmlDocument class. The XPath selector used to find all links in the document is //div[@class='div-col']//a | //div[@class='div-col']//ul. This selector selects all a elements and unordered lists within elements with class div-col. The links are then appended to the output TextBox control using the AppendText() method.
The code also demonstrates how to use complex CSS selectors like sibling, children, or attribute selectors to extract data from the HTML content. The XPath selector used to find all table headings in the document is //table[contains(@class, 'sidebar')][contains(@class, 'nomobile')][contains(@class, 'nowraplinks')][contains(@class, 'hlist')]//th[contains(@class, 'sidebar-heading')]. This selector selects all th elements within tables that have certain classes. The table headings are then appended to the output TextBox control using the AppendText() method.
💡 Do you want to know more about XPath? Check out the article Practical XPath for Web Scraping.
To run the application, press F5 or click the green Start button in Visual Studio. Once the application is running, enter the URL of the Wikipedia website page you want to scrape into the first TextBox control and then click the scraping button to start the scraping process. The scraped data should appear in the second TextBox control.
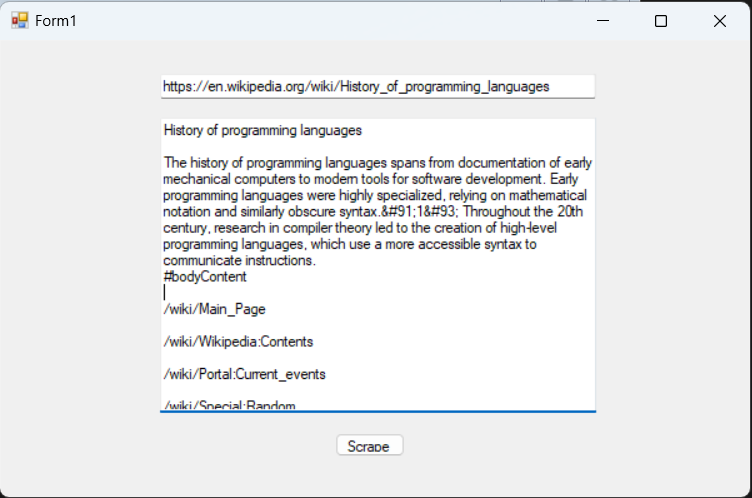
Advanced Scraping with Puppeteer
The limitation of the basic approach above is that it can only scrape static websites. Dynamic websites and single-page applications (SPAs) that load their content asynchronously or dynamically through JavaScript cannot be scraped using this method alone, because the HTML source code obtained from the server does not include the dynamic content, which is loaded or updated on the client side after the initial page load.
To scrape dynamic websites, you need to use a headless browser automation library such as Puppeteer or Playwright. Headless browsers allow you to scrape dynamic websites by executing JavaScript on the web page before parsing its contents. Dynamic websites use JavaScript to manipulate the document object model (DOM) of the webpage, and headless browsers can run this JavaScript code to interact with the webpage and retrieve dynamic content.
We'll take a look at how to use Puppeteer for more advanced scraping, but you can use a similar approach using Playwright.
Set Up Puppeteer in Your Project
To use a headless browser library like Puppeteer in your Visual Basic app, you'll need to first install the library and set it up in your project.
To do so, right-click on your project in the Solution Explorer in Visual Studio and select Manage NuGet Packages. In the NuGet Package Manager, search for PuppeteerSharp for Puppeteer, and click Install.
Scrape a Dynamic Website
Let's imagine that you want to scrape the headlines from the CNN sports page https://edition.cnn.com/sport.
Back in your project, add another button to Form1 and rename it as HeadlessBtn. Then go to the code editor and add the following code:
Imports PuppeteerSharp
Public Class Form1
Private Sub Button1_Click(sender As Object, e As EventArgs) Handles scrapeButton.Click
…code omitted…
End Sub
Private Async Sub HeadlessBtn_Click(sender As Object, e As EventArgs) Handles HeadlessBtn.Click
Dim url As String = "https://edition.cnn.com/sport"
Dim browserFetcher As New BrowserFetcher()
Await browserFetcher.DownloadAsync()
Dim launchOptions As New LaunchOptions()
launchOptions.Headless = True
Dim browser As Browser = Await Puppeteer.LaunchAsync(launchOptions)
Dim page As Page = Await browser.NewPageAsync()
Dim timeoutMilliseconds As Integer = 120000
Await page.GoToAsync(url, New NavigationOptions() With {.Timeout = timeoutMilliseconds})
Await page.WaitForSelectorAsync("div.container_lead-plus-headlines-with-images__headline > span[data-editable='headline']")
Dim headlineNodes As IElementHandle() = Await page.QuerySelectorAllAsync("div.container_lead-plus-headlines-with-images__headline > span[data-editable='headline']")
Dim headlines As New List(Of String)()
For Each headlineNode As ElementHandle In headlineNodes
Dim headlineText As String = Await page.EvaluateFunctionAsync(Of String)("(element) => element.textContent", headlineNode)
headlines.Add(headlineText)
Next
outputTextbox.Text = "Headlines from " + url + ":" + vbCrLf + vbCrLf
For Each headline As String In headlines
outputTextbox.AppendText(headline + vbCrLf)
Next
Await browser.CloseAsync()
End Sub
End Class
The code starts by downloading and installing the PuppeteerSharp library and then instantiates a new Chromium browser using the LaunchAsync method. After creating a new page instance with NewPageAsync(), the script navigates to the URL https://edition.cnn.com/sport using the GoToAsync method with a NavigationOptions object specifying a time-out of 120,000 milliseconds (two minutes). Then, the WaitForSelectorAsync method is called to ensure that the targeted HTML element is present in the page before the script proceeds.
This code snippet has a time-out of two minutes to ensure that the web page has sufficient time to load completely before the code proceeds. If the page takes longer to load, the navigation process will be aborted, and a TimeoutException will be thrown. Using a longer time-out is necessary when a web page takes longer to load than the default time-out duration or when performing an action that takes a longer time to complete, such as waiting for a slow API response or running complex JavaScript code.
After this, the script queries the DOM using the QuerySelectorAllAsync method to select all elements matching the given CSS selector. In this case, it's selecting all span elements with a data-editable attribute set to headline that are inside a div element with class attribute set to container_lead-plus-headlines-with-images__headline.
Finally, the script loops through the selected elements, extracts the text content of each element using EvaluateFunctionAsync, and appends it to a list of headlines. The headlines are then displayed in a text box. The browser instance is closed using the CloseAsync method at the end of the script.
Here are the results of the scraped data with Puppeteer:
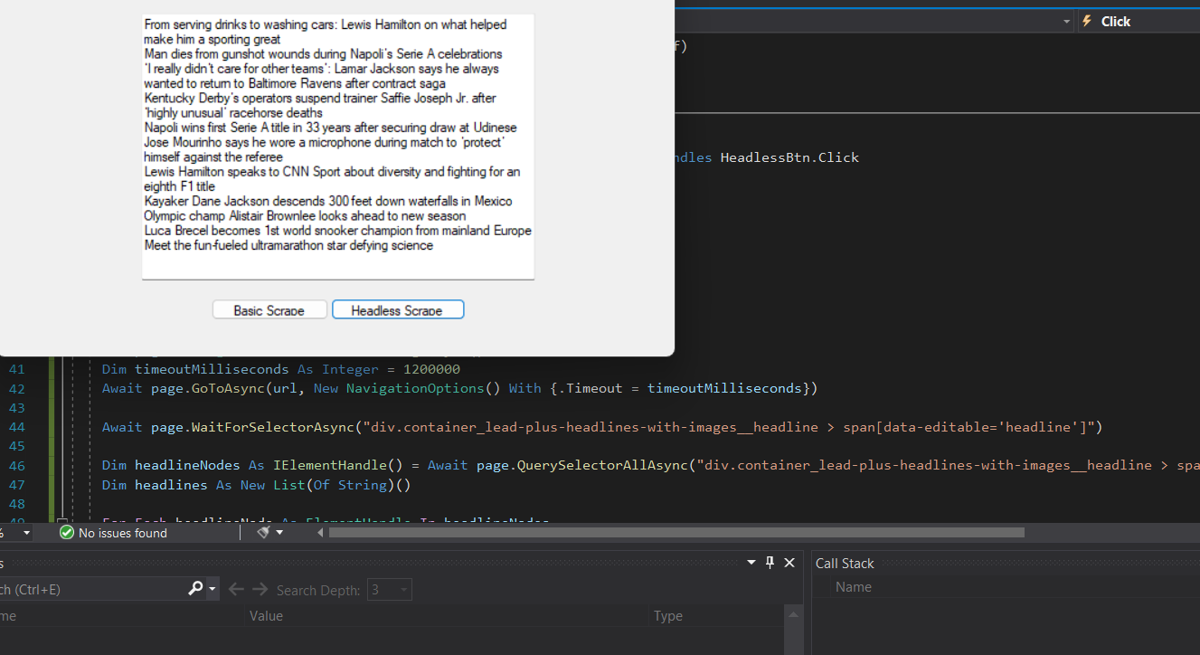
Conclusion
In this tutorial, you learned how to scrape websites with Visual Basic. You started with scraping a static website using an HTTP client library and an HTML parser, then moved on to scraping dynamic websites using the headless browser library Puppeteer. You can find the complete code of this tutorial on GitHub.
However, if you prefer not to deal with rate limits, proxies, user agents, and browser fingerprints, consider using a web scraping API like ScrapingBee. Our no-code API lets you extract data from websites at scale without worrying about technical details. Did you know your first 1,000 API calls are on us?
Before you go, check out these related reads:



