If you're looking to buy or sell a house or other real estate property, Zillow is an excellent resource with millions of property listings and detailed market data.
In addition to traditional real estate purposes, the data available on Zillow comes in handy for market analysis, tracking housing trends, or building a real estate application.
This tutorial will guide you to effectively scrape Zillow's real estate data at scale using Python, BeautifulSoup, and the ScrapingBee API.

TL;DR: Full Zillow Listings Python Scraper
For those in a hurry, here's the scraper we'll build in this tutorial. Here, we're sending our requests using ScrapingBee's Python SDK to bypass Zillow's anti-scraping mechanisms and handle any technical complexities when scaling the project.
Remember to swap out "Your_ScrapingBee_API_Key" with your actual ScrapingBee API key, you can retrieve this API key here. For more details on how to use the API and its features, refer to the official ScrapingBee Documentation.
from bs4 import BeautifulSoup
import json
from scrapingbee import ScrapingBeeClient
def scrape_listing_details(listing_url, client):
print(f"Making request for URL: {listing_url}")
response = client.get(
listing_url,
params={
"stealth_proxy": "True",
},
)
details = {"Price History": [], "Zestimate": None}
if response.status_code == 200:
print("Request successful")
soup = BeautifulSoup(response.content, "lxml")
# Scrape the Zestimate value
zestimate_element = soup.find("p", {"data-testid": "primary-zestimate"})
if zestimate_element:
zestimate = zestimate_element.get_text(strip=True)
details["Zestimate"] = zestimate
# Scrape the Price History table
price_history_table = soup.find("table", class_="StyledTableComponents__StyledTable-sc-shu7eb-2")
if price_history_table:
rows = price_history_table.find("tbody").find_all("tr")
for row in rows:
# Extracting the details from each row
cells = row.find_all("td")
if len(cells) == 3: # Making sure the row matches the expected format
date = cells[0].get_text(strip=True)
event = cells[1].get_text(strip=True)
price_text = cells[2].get_text(strip=True)
if "$" in price_text:
try:
price = price_text.split('$')[1] # Split and access the price part
price = f"${price}" # Reformat to include the dollar sign
except IndexError:
price = "N/A" # if the expected part is not found
else:
price = "N/A"
details["Price History"].append({"Date": date, "Event": event, "Price": price})
return details
def scrape_zillow_listings(base_url, num_pages_to_scrape, json_filename):
# Initialize a list to store the scraped data
scraped_data = []
for page_number in range(1, num_pages_to_scrape + 1):
# Construct the URL for the current page
page_url = f"{base_url}/{page_number}_p/"
client = ScrapingBeeClient(api_key="Your_ScrapingBee_API_Key")
print(f"Making Request for page {page_number} ... ")
response = client.get(
page_url,
params={
"stealth_proxy": "True",
"wait_browser": "load",
},
)
# Check if the request was successful
if response.status_code == 200:
soup = BeautifulSoup(response.content, "lxml")
# Find all the listing elements on the current page
listing_elements = soup.find_all("li", class_="ListItem-c11n-8-84-3__sc-10e22w8-0")
# Iterate through each listing element
for listing in listing_elements:
# Check edge case
if listing.find("div", {"data-renderstrat": "timeout"}):
continue
# Extract the URL from the 'a' tag within the listing
url_element = listing.find("a", {"data-test": "property-card-link"})
url = url_element.get("href") if url_element else "N/A"
if url != "N/A":
details = scrape_listing_details(url, client)
else:
details = {"Price History": "N/A", "Zestimate": "N/A"}
# Extract information from other elements with conditional checks
address = listing.find("address", {"data-test": "property-card-addr"})
address = address.text.strip() if address else "N/A"
price = listing.find("span", {"data-test": "property-card-price"})
price = price.text.strip() if price else "N/A"
# Extract bed, bath, and size using CSS selectors
beds_element = listing.select_one("ul.StyledPropertyCardHomeDetailsList-c11n-8-84-3__sc-1xvdaej-0 li:-soup-contains('bds') b")
beds = beds_element.text.strip() if beds_element else "N/A"
baths_element = listing.select_one("ul.StyledPropertyCardHomeDetailsList-c11n-8-84-3__sc-1xvdaej-0 li:-soup-contains('ba') b")
baths = baths_element.text.strip() if baths_element else "N/A"
size_element = listing.select_one("ul.StyledPropertyCardHomeDetailsList-c11n-8-84-3__sc-1xvdaej-0 li:-soup-contains('sqft') b")
size_sqft = size_element.text.strip() if size_element else "N/A"
status_element = listing.find(
"div", class_="StyledPropertyCardDataArea-c11n-8-84-3__sc-yipmu-0 dbDWjx"
)
status_text = status_element.get_text(strip=True) if status_element else "N/A"
status = status_text.split('-')[-1].strip() if "-" in status_text else status_text
listing_by_element = listing.find(
"div", class_="StyledPropertyCardDataArea-c11n-8-84-3__sc-yipmu-0 jretvB"
)
listing_by = listing_by_element.text.strip() if listing_by_element else "N/A"
# Store the extracted information as a dictionary
listing_data = {
"URL": url,
"Address": address,
"Price": price,
"Beds": beds,
"Baths": baths,
"Size (sqft)": size_sqft,
"Status": status,
"Listing By": listing_by,
}
listing_data.update(details)
# Append the listing data to the list
scraped_data.append(listing_data)
# Export the scraped data to a JSON file
with open(json_filename, "w") as json_file:
json.dump(scraped_data, json_file, indent=4)
print(f"Scraped Results successfully saved to {json_filename}!")
# Specify the base URL, number of pages to scrape, and preffered filename
base_url = "https://www.zillow.com/brooklyn-new-york-ny"
num_pages_to_scrape = 5
json_filename = "zillow_listings.json"
# Call the scraping function
scrape_zillow_listings(base_url, num_pages_to_scrape, json_filename)
Understanding Zillow's Website Structure
To efficiently scrape the Zillow web application, it is important to understand the website's structure. This helps to identify the elements we want to scrape and familiarise ourselves with them.
To do this, navigate to www.zillow.com and input a city or ZIP code into the search bar.
In this tutorial, we will be looking at properties in Brooklyn, New York.
Once you see the property listings, right-click on one of the property cards. From the context menu that appears, select the "Inspect" option. This action opens the browser's developer tools, which allow you to inspect the underlying HTML code of the webpage.
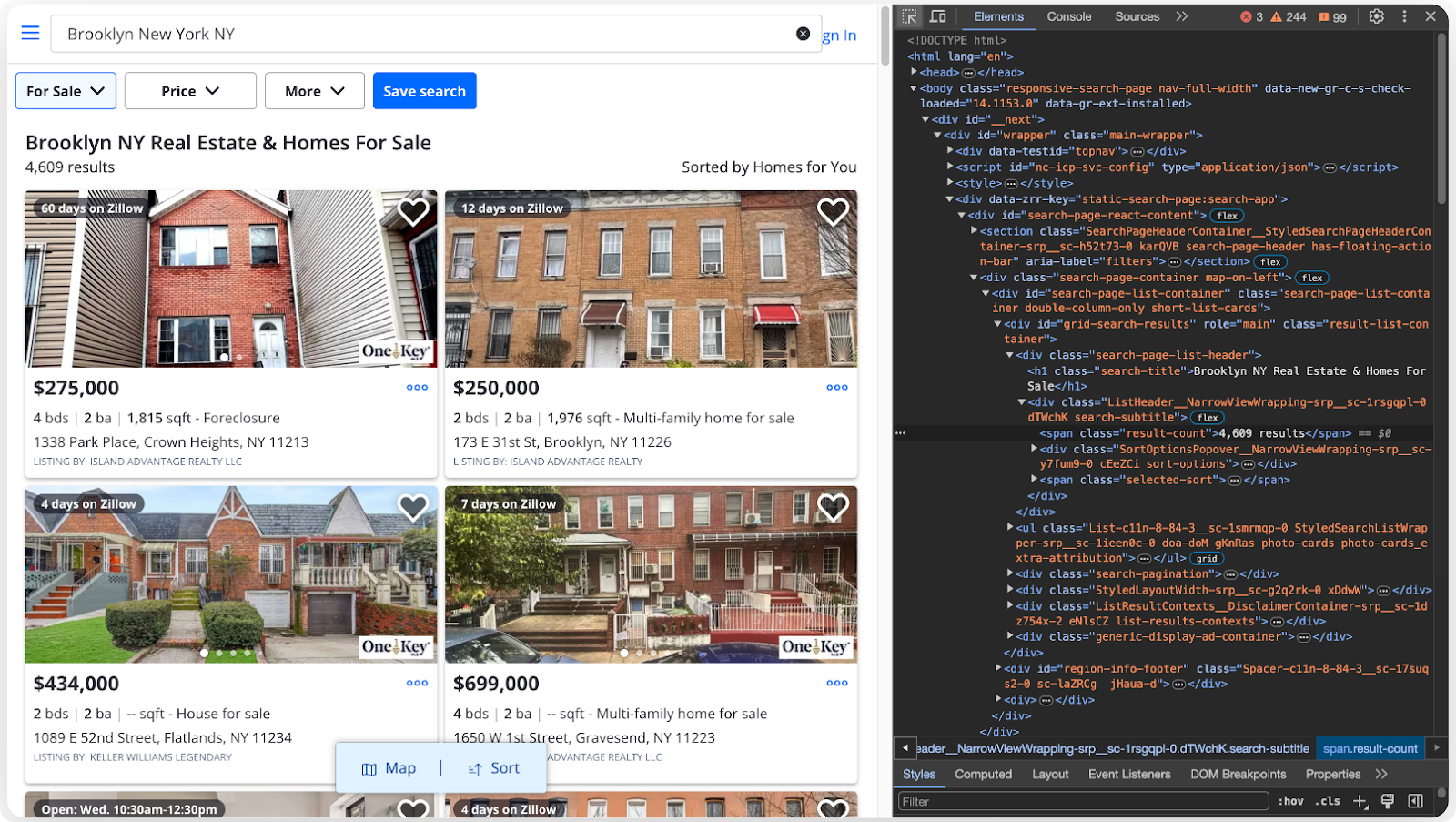
The developer tools make it easier to analyze the HTML structure of the property card. Look for the HTML tags containing the data you wish to scrape. Also, take note of the attributes of those tags.
Most tags are given attributes that correspond to the information they contain. This information may include the property's address, price, number of bedrooms and bathrooms, square footage, status, and listing agency.
Note: Web applications, including Zillow, often update their layout and structure. As a result, the specific HTML tags and attributes you're currently scraping may change over time. It's crucial to periodically check your scraping code to ensure it continues to function effectively.
Scraping Zillow Listings with Python
Prerequisites
To gather Zillow data, we'll use Python to interact with ScrapingBee's API. Install Python, BeautifulSoup, and lxml.
Moving on, create a virtual environment ( for example using virtualenv ) and then run the following commands in your terminal:
pip install beautifulsoup4 lxml
Beautiful Soup simplifies the process of extracting data from web pages by parsing HTML and XML documents, providing a convenient way to navigate and search your HTML documents. When combined with the "lxml" parser package, Beautiful Soup offers superior performance and efficiency in handling extensive volumes of data.
Avoid Getting Blocked with ScrapingBee
Many websites, including Zillow, use anti-scraping measures to prevent automated data extraction from their websites. These measures include CAPTCHAs, IP address blocking, and honeypot traps.
CAPTCHAs are specifically designed puzzles used to differentiate between humans and bots. CAPTCHA works by blocking IP addresses associated with bots that fail to solve its puzzles.
Honeypot traps are hidden elements on a webpage that can only be detected by bots. Any interaction with these traps can trigger an automatic block.
We help you handle these anti-scraping measures effectively by rotating proxies to avoid IP bans. We also have some automatic mechanisms to solve CAPTCHAs, ensuring uninterrupted data extraction. This allows you to concentrate on extracting and analyzing the data while our web scraper API handles most of the heavy lifting for you.
Setting Up ScrapingBee
You'll need to install the ScrapingBee Python SDK to start:
pip install scrapingbee
Once installed, proceed to sign up for an account. After signing up, you get an API key and you are also rewarded with 1000 free credits!
Navigate to your dashboard to copy your ScrapingBee API key.
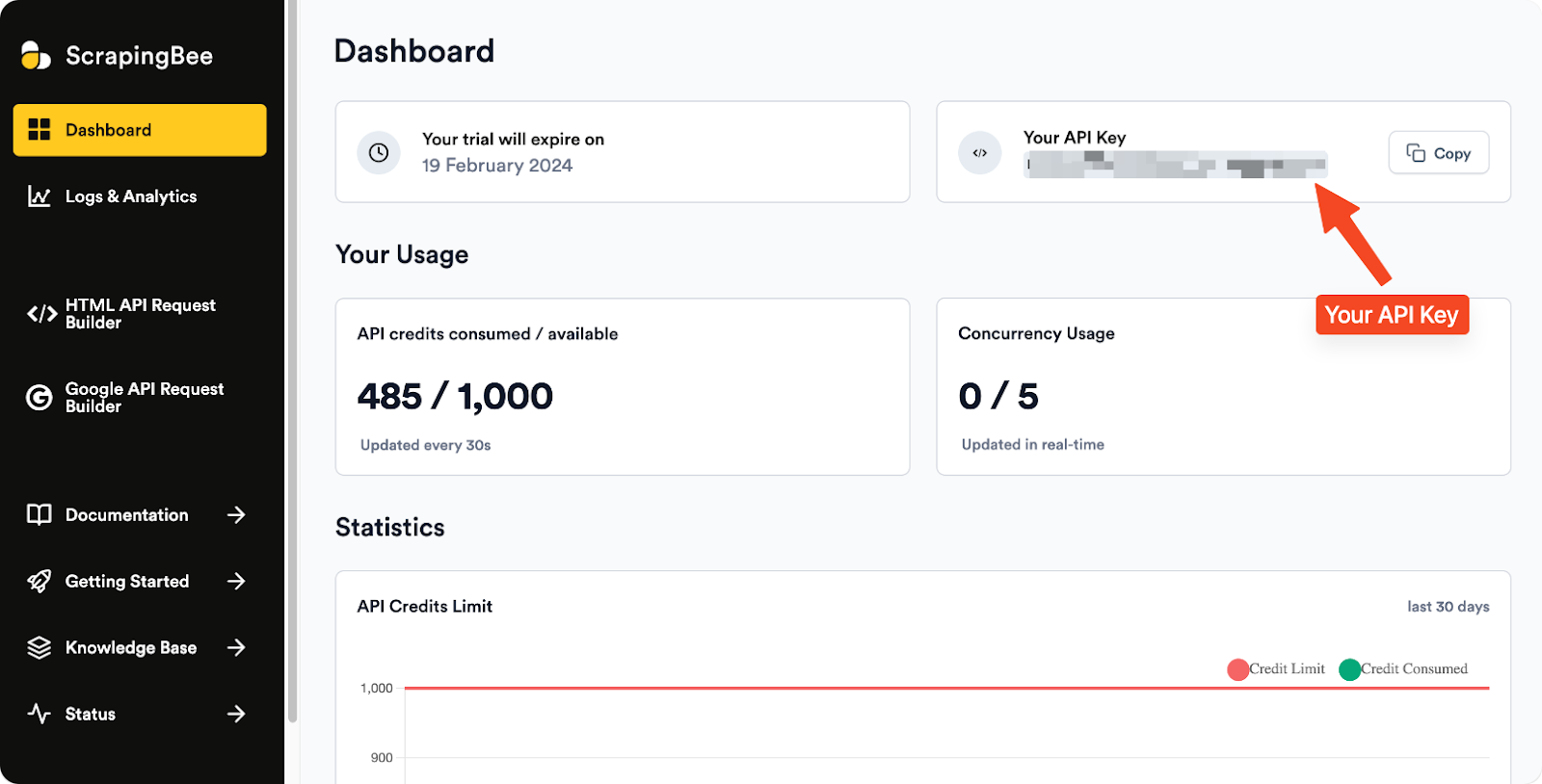
Then you can proceed to integrate ScrapingBee into your web scraping project!
Step-by-step Guide
Step 1: Import Libraries and Set Up the Client
In this step, we will import the necessary libraries and initialize the ScrapingBee client. BeautifulSoup will also be used to parse the HTML content.
from bs4 import BeautifulSoup
import json
from scrapingbee import ScrapingBeeClient
Step 2: Define the Scraping Function
Create a function scrape_zillow_listings that takes the base URL of Zillow's listings, the number of pages you wish to scrape, and the name of the JSON file where the scraped data will be stored:
def scrape_zillow_listings(base_url, num_pages_to_scrape, json_filename):
Step 3: Loop Through Pages
To scrape Zillow listings at scale, we will use a for loop to iterate through the number of pages you intend to scrape:
for page_number in range(1, num_pages_to_scrape + 1):
page_url = f"{base_url}/{page_number}_p/"
The for loop iterates over each page number within the specified range. The page_url variable holds the URL for the current page, which is constructed by appending the page number to the base URL.
To scrape the next page, you can construct the URL by adding a path like this --- "https://www.zillow.com/brooklyn-new-york-ny/2_p/" and keep changing the page number based on how many pages you need to scrape for your project. This method allows you to easily scrape multiple pages of Zillow's real estate data at scale.
Step 4: Make Requests with ScrapingBee
Initialize the ScrapingBeeClient with your API key and make a GET request to the constructed URL:
client = ScrapingBeeClient(api_key="YOUR_API_KEY")
response = client.get(page_url, params={"stealth_proxy": "True", "wait_browser": "load"})
The client.get() method sends a GET request to the given page_url. The params dictionary contains parameters that modify the behavior of the request.
The stealth_proxy parameter ensures that each request is sent from a pool of proxies that should be enough to scrape even the most impregnable websites. This is crucial for avoiding being blocked by Zillow's anti-bot mechanisms.
The wait_browser parameter tells the client to wait for the page to load completely before returning the response.
Note: Don't forget to replace "Your_API_Key" with your actual ScrapingBee API key.
Step 5: Parse the HTML Content
First, check if the response status code is 200, indicating a successful HTTP request. Then, parse the HTML content using BeautifulSoup:
if response.status_code == 200:
soup = BeautifulSoup(response.content, "lxml")
Here, "response.content" contains the raw HTML content of the page, and "lxml" specifies the parser to be used.
Step 6: Find Listing Elements
The next step involves finding all the listing elements on the page. These elements contain the data we're interested in scraping.
listing_elements = soup.find_all("li", class_="ListItem-c11n-8-84-3__sc-10e22w8-0")
The find_all method is called on the soup object and searches for all specified tag and class occurrences. These properties are part of a list with the class name "ListItem-c11n-8-84-3__sc-10e22w8-0". Hence, it looks for all 'li' elements with the class "ListItem-c11n-8-84-3__sc-10e22w8-0"
Step 7: Extract Information from Each Listing
Next, iterate through each listing element and extract the necessary information. Use conditional checks to handle any missing information.
Use a ternary conditional operator for each information piece to check if the element exists. If it does not exist, assign the string "N/A" as the value.
Extracting the Listing URL
To extract each property listing's URL, loop through each listing element.
for listing in listing_elements:
url_element = listing.find("a", {"data-test": "property-card-link"})
url = url_element.get("href") if url_element else "N/A"
The ".find" method is used to locate the first occurrence of an "a" element with the "data-test" attribute set to "property-card-link" within each listing element. The "get" method is then used to retrieve the "href" attribute from the "a" element, which is the URL of the property listing.
Extracting the Listing Address
Next, extract the address of the property from the "address" element within each listing.
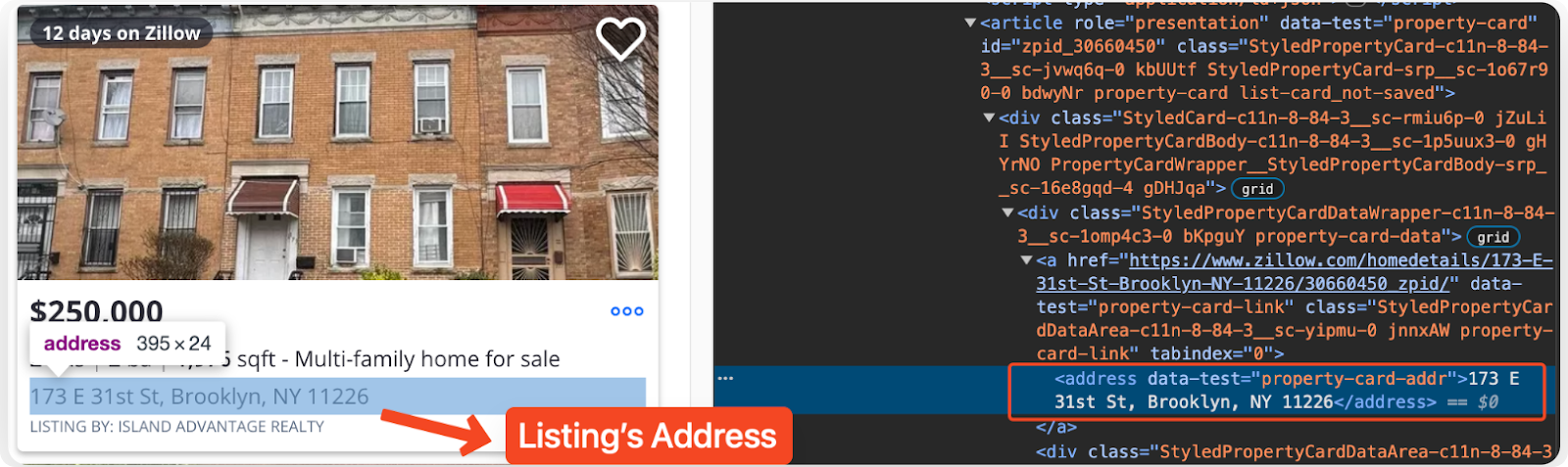
address = listing.find("address", {"data-test": "property-card-addr"})
address = address.text.strip() if address else "N/A"
The find method locates the "address" element with the data-test attribute set to property-card-addr.
Proceed to get the text content of the "address" element, which represents the address of the property.
Extracting the Listing Price
Then, proceed to extract the property price from the "span" element with the data-test attribute set to property-card-price.
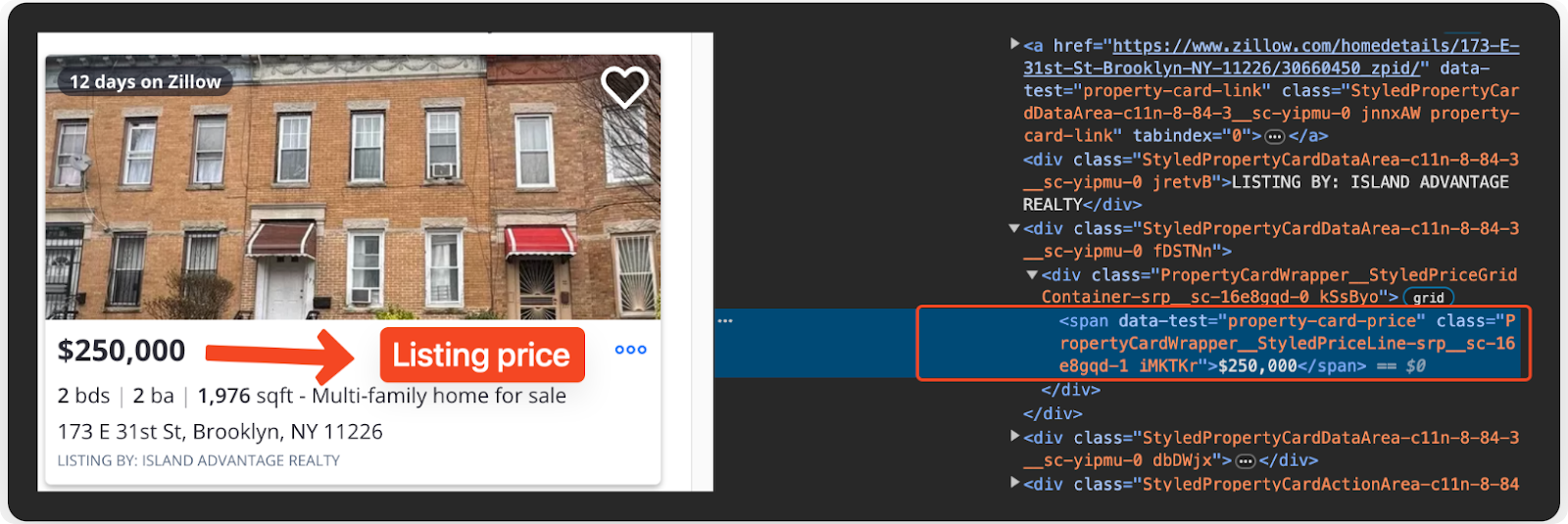
price = listing.find("span", {"data-test": "property-card-price"})
price = price.text.strip() if price else "N/A"
Extracting the Listing's Number of Beds and Baths
To extract the number of beds and baths, use CSS selectors to find the appropriate "li" items within the "ul" tag.
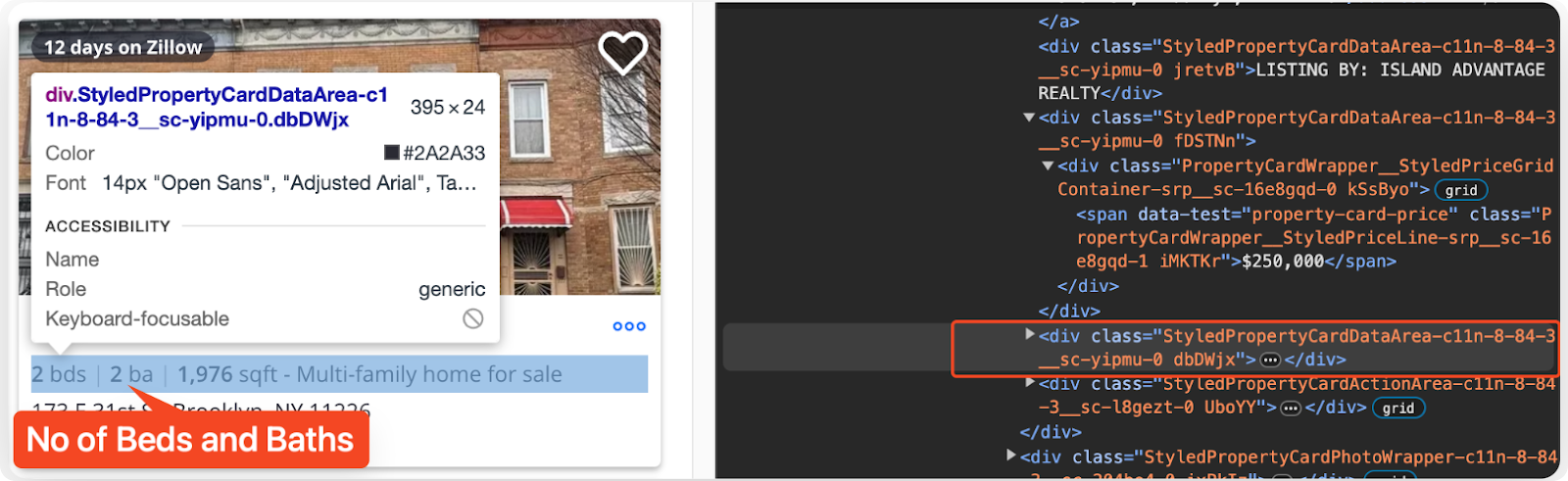
beds_element = listing.select_one("ul.StyledPropertyCardHomeDetailsList-c11n-8-84-3__sc-1xvdaej-0 li:-soup-contains('bds') b")
beds = beds_element.text.strip() if beds_element else "N/A"
baths_element = listing.select_one("ul.StyledPropertyCardHomeDetailsList-c11n-8-84-3__sc-1xvdaej-0 li:-soup-contains('ba') b")
baths = baths_element.text.strip() if baths_element else "N/A"
The "select_one" method uses the specified CSS selector to find the first matching element. The ":soup-contains()" pseudo-class is a custom filter introduced in BeautifulSoup 4.7.1 and later versions, which selects elements if their text contains a specified substring.
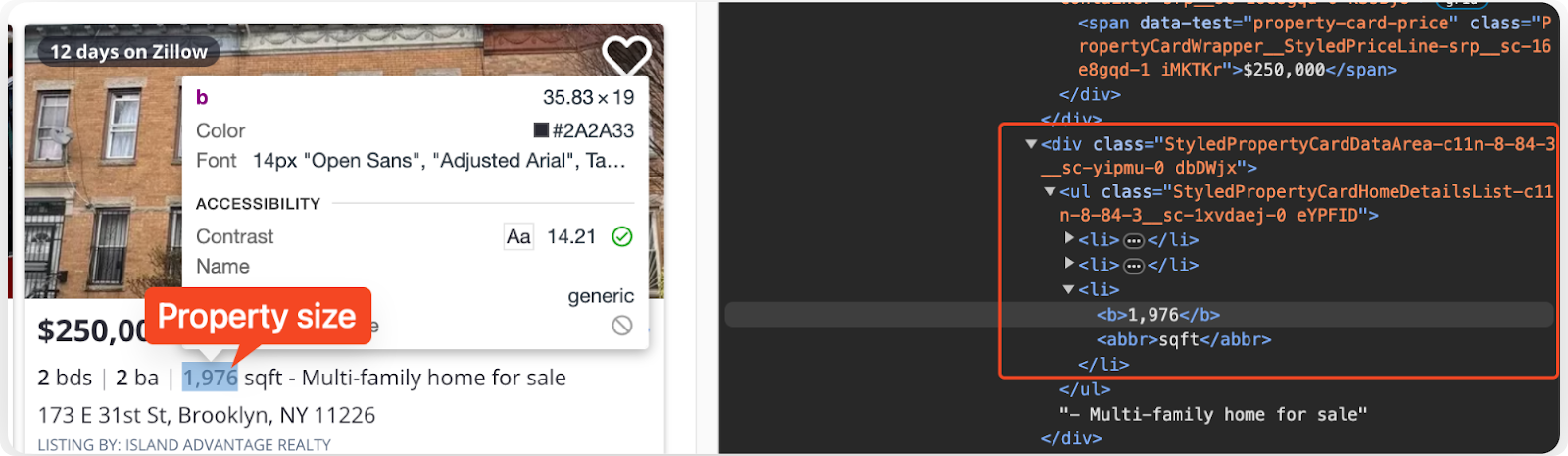
Extracting the Property Size
Continuing with the extraction process, extract the size of the property in square feet from the HTML by adding the following code to the script:
size_element = listing.select_one("ul.StyledPropertyCardHomeDetailsList-c11n-8-84-3__sc-1xvdaej-0 li:-soup-contains('sqft') b")
size_sqft = size_element.text.strip() if size_element else "N/A"
Extracting the Property Description
Extract the property description, which includes the status and the listing agent information. Add the following code to the script:
status_element = listing.find(
"div", class_="StyledPropertyCardDataArea-c11n-8-84-3__sc-yipmu-0 dbDWjx"
)
status_text = status_element.get_text(strip=True) if status_element else "N/A"
status = status_text.split('-')[-1].strip() if "-" in status_text else status_text
listing_by_element = listing.find(
"div", class_="StyledPropertyCardDataArea-c11n-8-84-3__sc-yipmu-0 jretvB"
)
listing_by = listing_by_element.text.strip() if listing_by_element else "N/A"
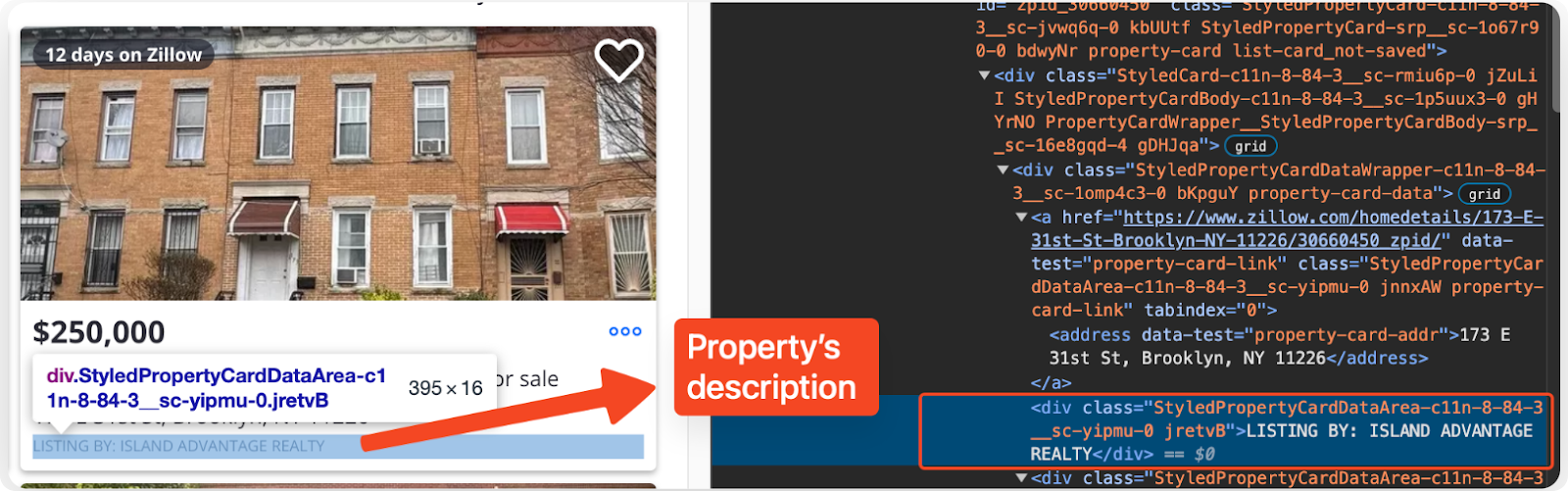
The find method is used to locate the "div" elements with the specified classes containing the status and listing agent information. The "get_text" method retrieves the text content of these elements, and string manipulation methods are applied to extract the relevant parts.
Extracting the Price History and Zestimate
In addition to the basic property details, we can enhance our scraping by fetching additional data such as the price history and the Zestimate for each listing. To achieve this, define a new function "scrape_listing_details" that takes the listing URL and the ScrapingBee client as arguments.
Here's the function:
def scrape_listing_details(listing_url, client):
print(f"Making request for URL: {listing_url}")
response = client.get(
listing_url,
params={
"stealth_proxy": "True",
},
)
details = {"Price History": [], "Zestimate": None}
if response.status_code == 200:
print("Request successful")
soup = BeautifulSoup(response.content, "lxml")
# Scrape the Zestimate value
zestimate_element = soup.find("p", {"data-testid": "primary-zestimate"})
if zestimate_element:
zestimate = zestimate_element.get_text(strip=True)
details["Zestimate"] = zestimate
# Scrape the Price History table
price_history_table = soup.find("table", class_="StyledTableComponents__StyledTable-sc-shu7eb-2")
if price_history_table:
rows = price_history_table.find("tbody").find_all("tr")
for row in rows:
# Extract the details from each row
cells = row.find_all("td")
if len(cells) == 3: # Ensuring the row matches the expected format
date = cells[0].get_text(strip=True)
event = cells[1].get_text(strip=True)
price_text = cells[2].get_text(strip=True)
if "$" in price_text:
try:
price = price_text.split('$')[1] # Split and access the price part
price = f"${price}" # Reformat to include the dollar sign
except IndexError:
price = "N/A"
else:
price = "N/A"
details["Price History"].append({"Date": date, "Event": event, "Price": price})
return details
This function sends a request to the listing URL, parses the response, and looks for the "Zestimate" and the price history table. It extracts the Zestimate value and iterates over the rows of the price history table, storing each entry in a list. The function then returns a dictionary with the price history and Zestimate.
Now, integrate this function into the main scraping script by calling the scrape_listing_details function after extracting each listing URL:
for listing in listing_elements:
url_element = listing.find("a", {"data-test": "property-card-link"})
url = url_element.get("href") if url_element else "N/A"
if url != "N/A":
details = scrape_listing_details(url, client)
else:
details = {"Price History": "N/A", "Zestimate": "N/A"}
Step 8: Save the Data to a JSON File
After extracting the listing data, save it to a JSON file:
with open(json_filename, "w") as json_file:
json.dump(scraped_data, json_file, indent=4)
print(f"Scraped Results successfully saved to {json_filename}!")
Step 9: Run the Scraper
Lastly, call the "scrape_zillow_listings" function with the required arguments. To run the scraper, provide a URL for a Zillow search results page. The URL should look like this: https://www.zillow.com/homes/{city-or-zip}_rb/, where {city-or-zip} will be replaced with the name of the city or the ZIP code to be scraped.
base_url = "https://www.zillow.com/brooklyn-new-york-ny"
num_pages_to_scrape = 5
json_filename = "zillow_listings.json"
scrape_zillow_listings(base_url, num_pages_to_scrape, json_filename)
After running this code, you should have a JSON file named zillow_listings.json containing the scraped data in your project directory.
Full Zillow Scraper Code
Here's the full code for the scraper we built in this tutorial. Don't forget to replace "Your_ScrapingBee_API_Key" with your unique ScrapingBee API key, you can retrieve this API key here.
from bs4 import BeautifulSoup
import json
from scrapingbee import ScrapingBeeClient
def scrape_listing_details(listing_url, client):
print(f"Making request for URL: {listing_url}")
response = client.get(
listing_url,
params={
"stealth_proxy": "True",
},
)
details = {"Price History": [], "Zestimate": None}
if response.status_code == 200:
print("Request successful")
soup = BeautifulSoup(response.content, "lxml")
# Scrape the Zestimate value
zestimate_element = soup.find("p", {"data-testid": "primary-zestimate"})
if zestimate_element:
zestimate = zestimate_element.get_text(strip=True)
details["Zestimate"] = zestimate
# Scrape the Price History table
price_history_table = soup.find("table", class_="StyledTableComponents__StyledTable-sc-shu7eb-2")
if price_history_table:
rows = price_history_table.find("tbody").find_all("tr")
for row in rows:
# Extracting the details from each row
cells = row.find_all("td")
if len(cells) == 3: # Making sure the row matches the expected format
date = cells[0].get_text(strip=True)
event = cells[1].get_text(strip=True)
price_text = cells[2].get_text(strip=True)
if "$" in price_text:
try:
price = price_text.split('$')[1] # Split and access the price part
price = f"${price}" # Reformat to include the dollar sign
except IndexError:
price = "N/A" # if the expected part is not found
else:
price = "N/A"
details["Price History"].append({"Date": date, "Event": event, "Price": price})
return details
def scrape_zillow_listings(base_url, num_pages_to_scrape, json_filename):
# Initialize a list to store the scraped data
scraped_data = []
for page_number in range(1, num_pages_to_scrape + 1):
# Construct the URL for the current page
page_url = f"{base_url}/{page_number}_p/"
client = ScrapingBeeClient(
api_key="Your_ScrapingBee_API_Key"
)
print(f"Making Request for page {page_number} ... ")
response = client.get(
page_url,
params={
"stealth_proxy": "True",
"wait_browser": "load",
},
)
# Check if the request was successful
if response.status_code == 200:
soup = BeautifulSoup(response.content, "lxml")
# Find all the listing elements on the current page
listing_elements = soup.find_all("li", class_="ListItem-c11n-8-84-3__sc-10e22w8-0")
# Iterate through each listing element
for listing in listing_elements:
# Check edge case
if listing.find("div", {"data-renderstrat": "timeout"}):
continue
# Extract the URL from the 'a' tag within the listing
url_element = listing.find("a", {"data-test": "property-card-link"})
url = url_element.get("href") if url_element else "N/A"
if url != "N/A":
details = scrape_listing_details(url, client)
else:
details = {"Price History": "N/A", "Zestimate": "N/A"}
# Extract information from other elements with conditional checks
address = listing.find("address", {"data-test": "property-card-addr"})
address = address.text.strip() if address else "N/A"
price = listing.find("span", {"data-test": "property-card-price"})
price = price.text.strip() if price else "N/A"
# Extract bed, bath, and size using CSS selectors
beds_element = listing.select_one("ul.StyledPropertyCardHomeDetailsList-c11n-8-84-3__sc-1xvdaej-0 li:-soup-contains('bds') b")
beds = beds_element.text.strip() if beds_element else "N/A"
baths_element = listing.select_one("ul.StyledPropertyCardHomeDetailsList-c11n-8-84-3__sc-1xvdaej-0 li:-soup-contains('ba') b")
baths = baths_element.text.strip() if baths_element else "N/A"
size_element = listing.select_one("ul.StyledPropertyCardHomeDetailsList-c11n-8-84-3__sc-1xvdaej-0 li:-soup-contains('sqft') b")
size_sqft = size_element.text.strip() if size_element else "N/A"
status_element = listing.find(
"div", class_="StyledPropertyCardDataArea-c11n-8-84-3__sc-yipmu-0 dbDWjx"
)
status_text = status_element.get_text(strip=True) if status_element else "N/A"
status = status_text.split('-')[-1].strip() if "-" in status_text else status_text
listing_by_element = listing.find(
"div", class_="StyledPropertyCardDataArea-c11n-8-84-3__sc-yipmu-0 jretvB"
)
listing_by = listing_by_element.text.strip() if listing_by_element else "N/A"
# Store the extracted information as a dictionary
listing_data = {
"URL": url,
"Address": address,
"Price": price,
"Beds": beds,
"Baths": baths,
"Size (sqft)": size_sqft,
"Status": status,
"Listing By": listing_by,
}
listing_data.update(details)
# Append the listing data to the list
scraped_data.append(listing_data)
# Export the scraped data to a JSON file
with open(json_filename, "w") as json_file:
json.dump(scraped_data, json_file, indent=4)
print(f"Scraped Results successfully saved to {json_filename}!")
# Specify the base URL, number of pages to scrape, and preffered filename
base_url = "https://www.zillow.com/brooklyn-new-york-ny"
num_pages_to_scrape = 5
json_filename = "zillow_listings.json"
# Call the scraping function
scrape_zillow_listings(base_url, num_pages_to_scrape, json_filename)
Zillow Scraping Results
The output will be stored in a JSON file, zillow_listings.json.
{
"URL": "https://www.zillow.com/homedetails/1338-Park-Pl-Brooklyn-NY-11213/68310361_zpid/",
"Address": "1338 Park Place, Crown Heights, NY 11213",
"Price": "$275K",
"Beds": "4",
"Baths": "2",
"Size (sqft)": "1,815",
"Status": "Auction",
"Listing By": "ISLAND ADVANTAGE REALTY LLC",
"Price History": [
{
"Date": "9/10/2010",
"Event": "Sold",
"Price": "$175,000-41.8%"
},
{
"Date": "12/3/2009",
"Event": "Sold",
"Price": "$300,500-53.8%"
},
{
"Date": "8/28/2008",
"Event": "Sold",
"Price": "$650,000+364.3%"
},
{
"Date": "1/20/2005",
"Event": "Sold",
"Price": "$140,000"
}
],
"Zestimate": "$274,700"
},
{
"URL": "https://www.zillow.com/homedetails/173-E-31st-St-Brooklyn-NY-11226/30660450_zpid/",
"Address": "173 E 31st St, Brooklyn, NY 11226",
"Price": "$250,000",
"Beds": "2",
"Baths": "2",
"Size (sqft)": "1,976",
"Status": "family home for sale",
"Listing By": "LISTING BY: ISLAND ADVANTAGE REALTY",
"Price History": [
{
"Date": "1/24/2024",
"Event": "Listed for sale",
"Price": "$250,000-54.5%"
},
{
"Date": "12/11/2015",
"Event": "Listing removed",
"Price": "$1,850"
},
{
"Date": "10/21/2015",
"Event": "Listed for rent",
"Price": "$1,850"
},
{
"Date": "5/1/2008",
"Event": "Listing removed",
"Price": "$549,000"
},
{
"Date": "4/11/2008",
"Event": "Listed for sale",
"Price": "$549,000+5.7%"
}
],
"Zestimate": "$252,500"
},
... More listing data
Each listing in the JSON file includes key details such as the URL, address, price, number of bedrooms and bathrooms, square footage, listing status, price history, zestimate, and the entity responsible for the listing.
The JSON data format allows for easy integration with data analysis tools and applications. This also enables you to perform in-depth market research, trend analysis, or any other project requiring real estate data.
Wrapping Up
You've learned to scrape Zillow's real estate data at scale with Python, BeautifulSoup, and ScrapingBee's API. With this powerful combination, you were able to programmatically access and extract valuable information from one of the largest real estate platforms.
You've learned to understand Zillow's site structure, identify data points for scraping, and how to automate data extraction with Python. You've also learned about Zillow's anti-scraping methods and how ScrapingBee's features, like stealth proxies and CAPTCHA solving, help overcome these challenges.
If you have any questions or uncertainties about scraping public data from Zillow, our support team is here to help. You can reach out to us via email or live chat on our website. Our professional team will gladly consult you on any matter related to scraping public data from Zillow
Frequently Asked Questions
Why Should I Scrape Zillow?
To obtain comprehensive information on property prices, locations, features, and trends. With Zillow's data, you can perform market analysis, stay updated on the industry, evaluate competition, and make data-driven decisions that align with your goals.
Why use ScrapingBee?
ScrapingBee handles JavaScript rendering and can bypass anti-bot measures, making it a reliable tool for your web scraping projects.
💡Interested in scraping more property data? Check out our guide on How to scrape Airbnb data


