Charles proxy is an HTTP debugging proxy that can inspect network calls and debug SSL traffic. With Charles, you are able to inspect requests/responses, headers and cookies. Today we will see how to set up Charles, and how we can use Charles proxy for web scraping. We will focus on extracting data from Javascript-heavy web pages and mobile applications. Charles sits between your applications and the internet:
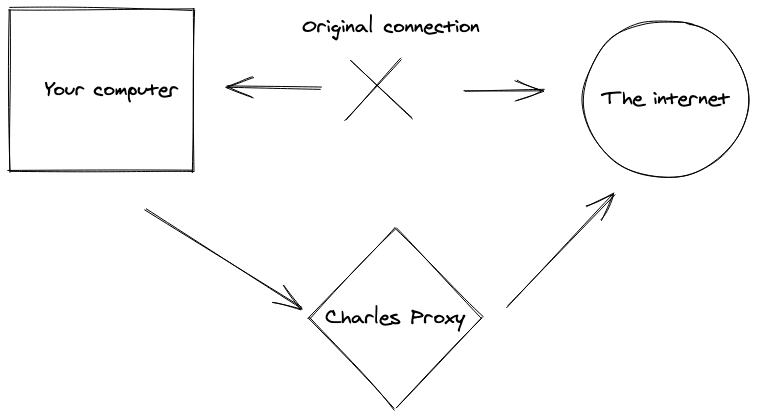
Charles is like the Chrome dev tools on steroids. It has many incredible features:
- Bandwidth throttling to emulate slow internet connection
- Request editing (the test the behavior of a back-end API for example)
- Repeat requests
- Full-text search on a list of request (very interesting for web-scraping)
- Many more
Charles is a very interesting tool when debugging Single Page application or mobile applications.

Installation and set-up
We are going to see how to install and configure Charles on macOS, but there is also a Windows and Linux version.
First visit https://www.charlesproxy.com/download/ and download Charles.
After installing Charles, you need to install its root certificate. This will allow Charles to intercept and decrypt the SSL traffic.
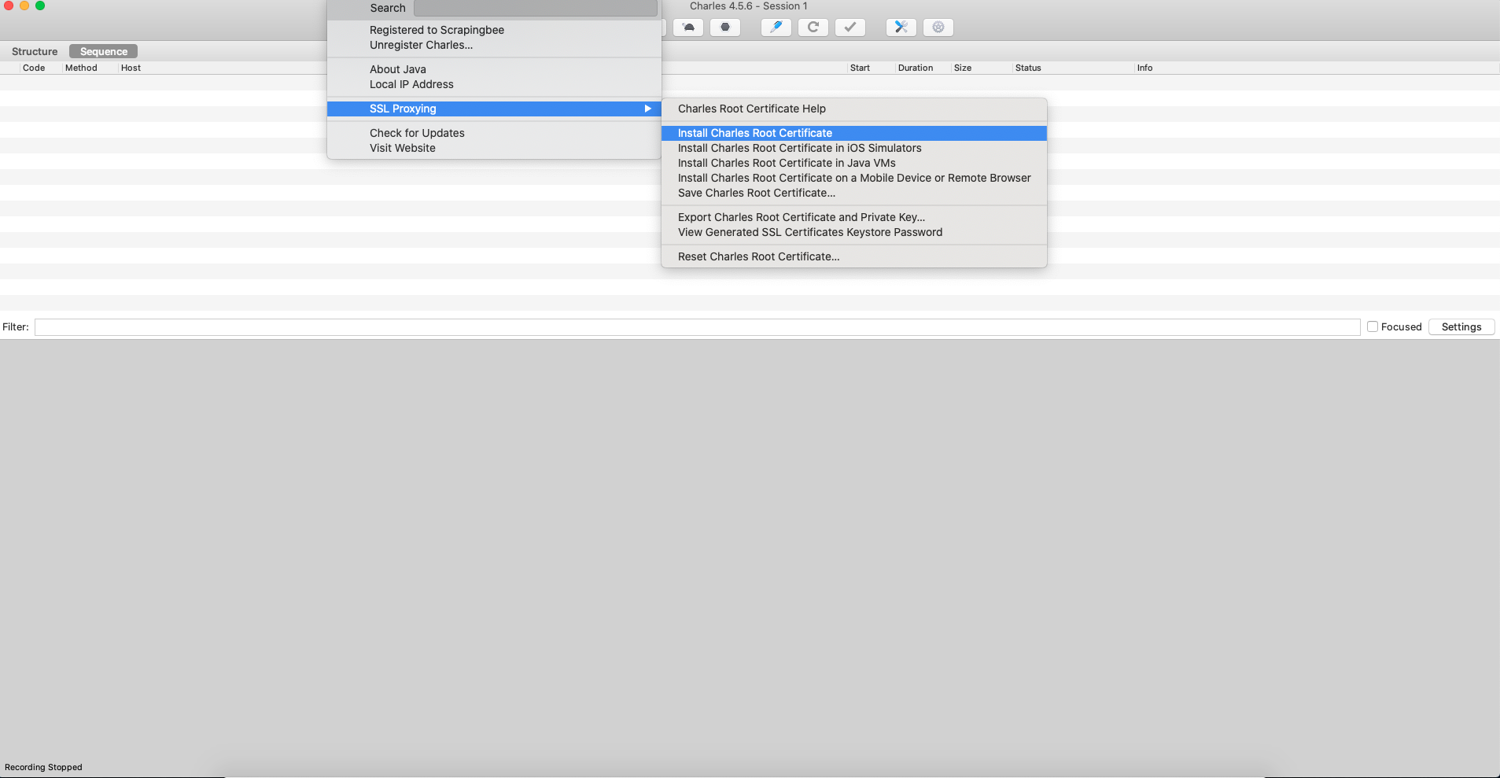
After clicking on Install Root Certificate, it will open your macOS Keychain Access, and you will have to open the Trust menu and click on "Always trust".
This will ask you for your system password.
Now you will need to go to Proxy > SSL Proxying Settings and add "*" or the domain you want to inspect SSL on.
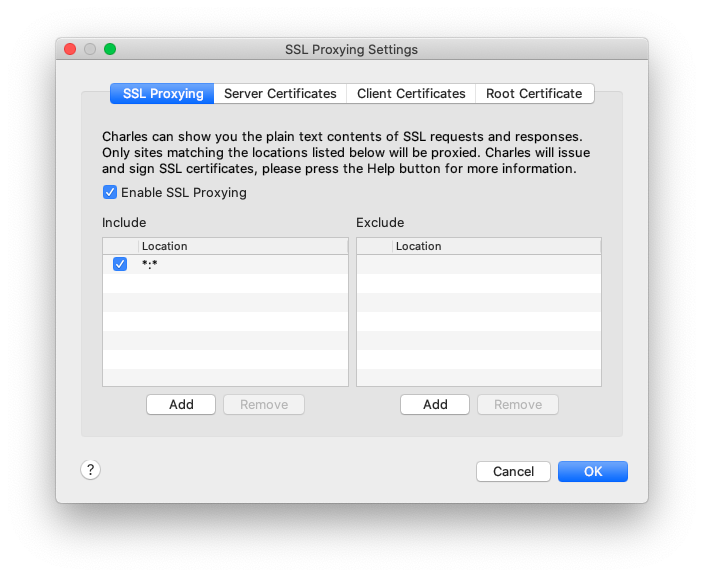
Charles will now capture the HTTPS traffic on the domain you've selected.
Finding hidden APIs on Single Page Applications
In a traditional server-side rendered website, the HTML code is built by the backend service, and the full page is returned to the HTTP client (generally your browser). Over the past 10 years, more and more websites are rendered client-side using a Single Page Application framework like React.js, Vue.js or Angular.
Those framework are sending many requests to a back-end API, and it can be a great idea to consume those APIs directly instead of scraping the site and rendering the Javascript with a headless browser to extract the data you want. It will be much faster, you don't need expensive hardware (headless browser needs a lot of RAM and powerful CPUs.).
We are going to look at different Single Page Application to see how Charles proxy can help you discover and extract data from back-end APIs.
Let's start with ProductHunt
ProductHunt is a famous website to launch products online. It's very popular in the tech ecosystem. There are dozens of projects launched every day, so the front page only loads the products of the day. There is an infinite scroll to look at previous days products.
We are going to use Charles proxy to analyze the backend API call and reproduce it with some Python code.
Now open Charles proxy and go to the Producthunt home page, scroll several times to the bottom of the page.
By default, Charles will capture every HTTP request made by your system, not only your browser. So you will get a lot of "pollution". You can filter that by entering the domain you're interested in:
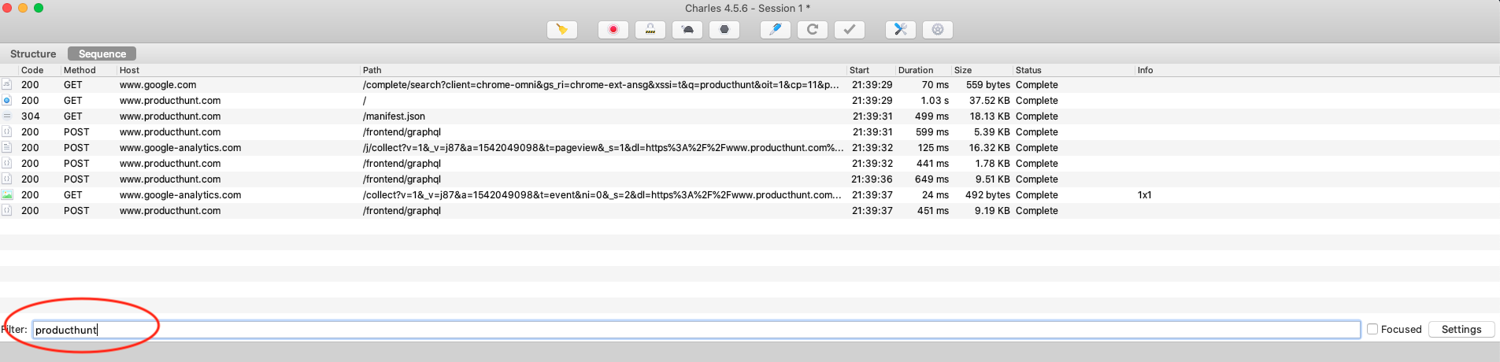
If you click on one of the POST requests to the /frontend/graphql endpoint, you can inspect both the request and the response.
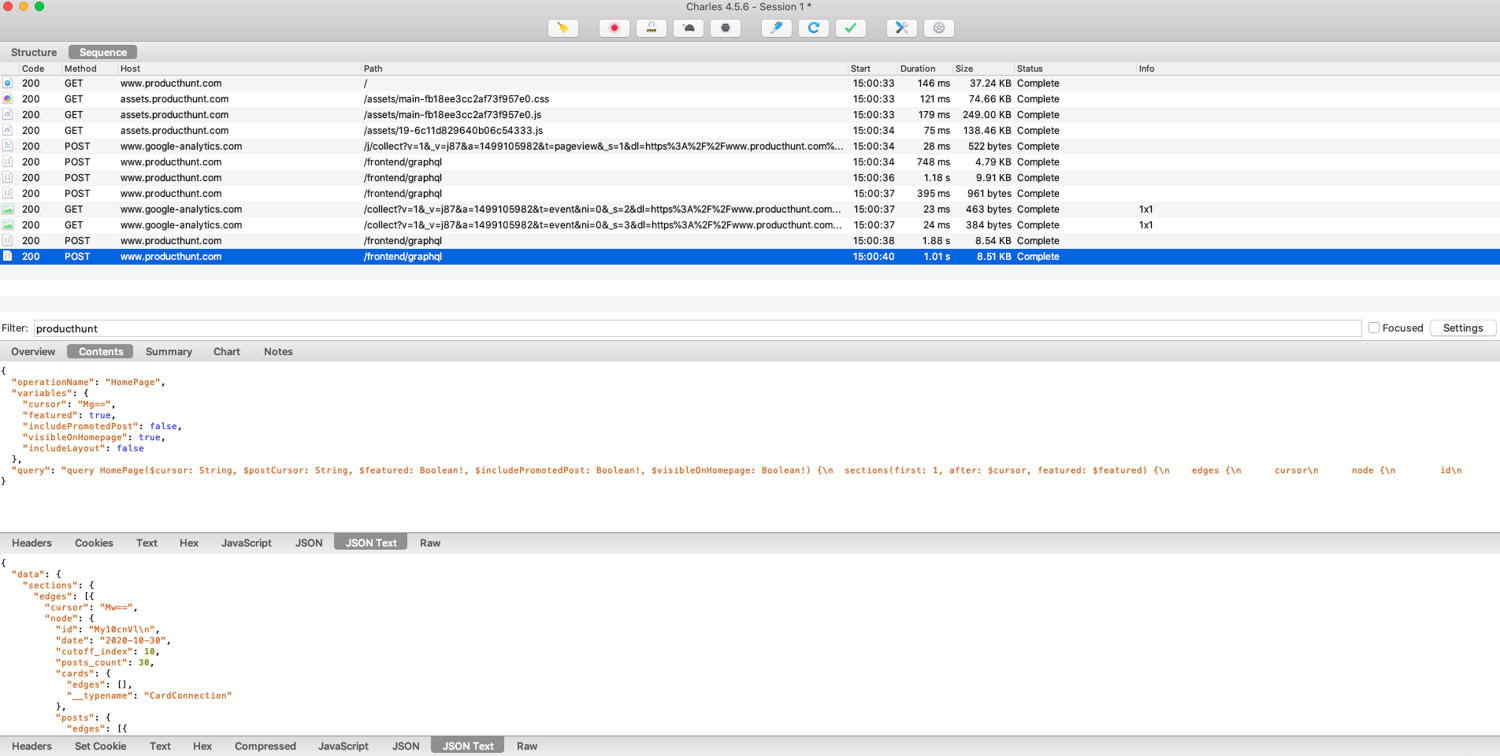
There are many things going on with these requests, but if you compare the content being sent to the GraphQL API, it seems the only thing that changes is the cursor parameter.
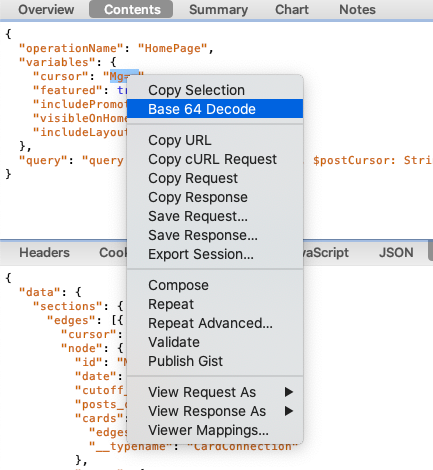
It is base64 encoded, but luckily, Charles has a feature to quickly decode Base64 content. You just have to select it and right-click:
One of the killer features Charles offers is the ability to edit any request and replay. In our case it's really great because there are many headers/cookies values inside the request, so it would be a nightmare to try to reproduce the request with an HTTP client or inside your code.
In order to do that, you can right-click on the request and click on Compose.
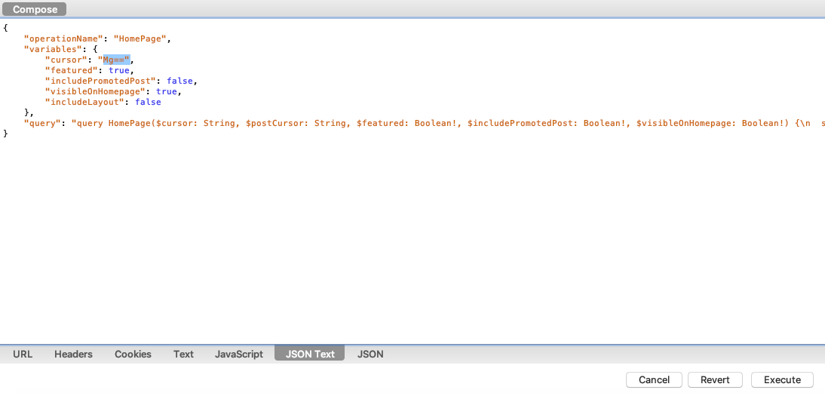
You can then play with the cursor value and replace it with a different page number encoded in base64. Then click on Execute.
You can also try deleting the different cookies (it will work). It's great news because if cookies were mandatory to use this endpoint, it would have been more complicated to reproduce the request with our Python code.
Now you can export the request to cURL:
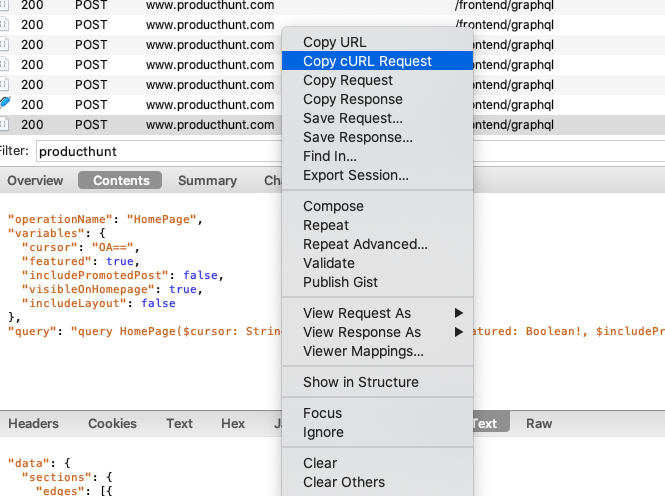
Then you can use a tool like this one to convert the cURL command to Python code (using the wonderful Requests package): https://curl.trillworks.com/
I just added the verify=False parameter to avoid SSL warnings with Requests.
import requests
headers = {
'Host': 'www.producthunt.com',
'accept': '*/*',
'x-requested-with': 'XMLHttpRequest',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36',
'content-type': 'application/json',
'origin': 'https://www.producthunt.com',
'sec-fetch-site': 'same-origin',
'sec-fetch-mode': 'cors',
'sec-fetch-dest': 'empty',
'referer': 'https://www.producthunt.com/',
'accept-language': 'en-US,en;q=0.9',
}
data = '{"operationName":"HomePage","variables":{"cursor":"OA==","featured":true,"includePromotedPost":false,"visibleOnHomepage":true,"includeLayout":false},"query":"query HomePage($cursor: String, $postCursor: String, $featured: Boolean!, $includePromotedPost: Boolean!, $visibleOnHomepage: Boolean!) {\\n sections(first: 1, after: $cursor, featured: $featured) {\\n edges {\\n cursor\\n node {\\n id\\n date\\n cutoff_index\\n posts_count\\n cards(first: 1, after: $cursor) {\\n edges {\\n node {\\n ...FeedCards\\n __typename\\n }\\n __typename\\n }\\n __typename\\n }\\n posts(after: $postCursor, visible_on_homepage: $visibleOnHomepage) {\\n edges {\\n node {\\n ...PostItemList\\n featured_comment {\\n id\\n body: body_text\\n user {\\n id\\n ...UserImageLink\\n __typename\\n }\\n __typename\\n }\\n __typename\\n }\\n __typename\\n }\\n pageInfo {\\n endCursor\\n hasNextPage\\n __typename\\n }\\n __typename\\n }\\n __typename\\n }\\n __typename\\n }\\n pageInfo {\\n endCursor\\n hasNextPage\\n __typename\\n }\\n __typename\\n }\\n ad(kind: \\"feed\\") @include(if: $includePromotedPost) {\\n ...AdFragment\\n __typename\\n }\\n promoted_email_campaign(promoted_type: HOMEPAGE) @include(if: $includePromotedPost) {\\n id\\n abTestName\\n abVariant {\\n id\\n ...PromotedEmailAbTestVariantFragment\\n __typename\\n }\\n ...PromotedEmailCampaignFragment\\n __typename\\n }\\n daily_newsletter {\\n id\\n subject\\n __typename\\n }\\n viewer {\\n id\\n email\\n has_newsletter_subscription\\n __typename\\n }\\n ph_homepage_og_image_url\\n}\\n\\nfragment FeedCards on Card {\\n ...NewPostsCard\\n ...BestProductsFromLastWeekCard\\n ...MakersDiscussionCardFragment\\n ...GoldenKittyCardFragment\\n __typename\\n}\\n\\nfragment NewPostsCard on NewPostsCard {\\n is_dismissed\\n kind\\n posts {\\n ...PostItemList\\n __typename\\n }\\n __typename\\n}\\n\\nfragment PostItemList on Post {\\n id\\n ...PostItem\\n __typename\\n}\\n\\nfragment PostItem on Post {\\n id\\n _id\\n comments_count\\n name\\n shortened_url\\n slug\\n tagline\\n updated_at\\n topics {\\n edges {\\n node {\\n id\\n name\\n slug\\n __typename\\n }\\n __typename\\n }\\n __typename\\n }\\n ...PostThumbnail\\n ...PostVoteButton\\n __typename\\n}\\n\\nfragment PostThumbnail on Post {\\n id\\n name\\n thumbnail {\\n id\\n media_type\\n ...MediaThumbnail\\n __typename\\n }\\n ...PostStatusIcons\\n __typename\\n}\\n\\nfragment MediaThumbnail on Media {\\n id\\n image_uuid\\n __typename\\n}\\n\\nfragment PostStatusIcons on Post {\\n name\\n product_state\\n __typename\\n}\\n\\nfragment PostVoteButton on Post {\\n _id\\n id\\n featured_at\\n updated_at\\n created_at\\n disabled_when_scheduled\\n has_voted\\n ... on Votable {\\n id\\n votes_count\\n __typename\\n }\\n __typename\\n}\\n\\nfragment BestProductsFromLastWeekCard on BestProductsFromLastWeekCard {\\n posts {\\n ...PostItemList\\n __typename\\n }\\n __typename\\n}\\n\\nfragment MakersDiscussionCardFragment on MakersDiscussionCard {\\n isDismissed\\n discussion {\\n _id\\n id\\n ...DiscussionThreadListItem\\n __typename\\n }\\n __typename\\n}\\n\\nfragment DiscussionThreadListItem on DiscussionThread {\\n _id\\n id\\n title\\n description\\n descriptionHtml\\n slug\\n commentsCount\\n can_comment: canComment\\n discussionPath\\n canEdit\\n votesCount\\n hasVoted\\n createdAt\\n poll {\\n ...PollFragment\\n __typename\\n }\\n user {\\n id\\n name\\n username\\n headline\\n avatar\\n __typename\\n }\\n __typename\\n}\\n\\nfragment PollFragment on Poll {\\n id\\n answersCount\\n hasAnswered\\n options {\\n id\\n text\\n imageUuid\\n answersCount\\n answersPercent\\n hasAnswered\\n __typename\\n }\\n __typename\\n}\\n\\nfragment GoldenKittyCardFragment on GoldenKittyCard {\\n is_dismissed\\n category_for_voting {\\n id\\n slug\\n __typename\\n }\\n __typename\\n}\\n\\nfragment PromotedEmailCampaignFragment on PromotedEmailCampaign {\\n id\\n _id\\n title\\n tagline\\n thumbnail\\n ctaText\\n __typename\\n}\\n\\nfragment PromotedEmailAbTestVariantFragment on PromotedEmailAbTestVariant {\\n id\\n _id\\n title\\n tagline\\n thumbnail\\n ctaText\\n __typename\\n}\\n\\nfragment AdFragment on LegacyAdsUnion {\\n ... on PromotedPost {\\n id\\n ...LegacyPromotedPostItem\\n __typename\\n }\\n ... on AdChannel {\\n id\\n post {\\n id\\n slug\\n name\\n updated_at\\n comments_count\\n ...PostVoteButton\\n __typename\\n }\\n ctaText\\n dealText\\n adName: name\\n adTagline: tagline\\n adThumbnailUuid: thumbnailUuid\\n adUrl: url\\n __typename\\n }\\n __typename\\n}\\n\\nfragment LegacyPromotedPostItem on PromotedPost {\\n id\\n deal\\n post {\\n id\\n ...PostItem\\n __typename\\n }\\n name\\n tagline\\n ctaText\\n url\\n thumbnailUuid\\n ...ViewableImpressionSubject\\n __typename\\n}\\n\\nfragment ViewableImpressionSubject on Node {\\n id\\n __typename\\n}\\n\\nfragment UserImageLink on User {\\n id\\n _id\\n name\\n username\\n avatar\\n ...UserImage\\n __typename\\n}\\n\\nfragment UserImage on User {\\n id\\n post_upvote_streak\\n name\\n avatar\\n __typename\\n}\\n"}'
response = requests.post('https://www.producthunt.com/frontend/graphql', headers=headers, cookies=cookies, data=data, verify=False)
And voila! You can now tweak the cursor parameter to get the page number you want, you just have to encode it into base64.
Mobile Application Reverse engineering
The ability to inspect/modify network calls inside a web application is very cool. But you know what is even cooler? Yes, mobile apps! Of course, it can be forbidden in the Terms of Service so make sure to read it before performing any request analysis on a mobile application.
A few years ago it was a bit complicated to make Charles proxy work with your mobile device, you had to use your desktop Charles as a proxy, be on the same wifi network etc. Since 2018, they launched a native iOS application, that you can download on the app store: https://apps.apple.com/us/app/charles-proxy/id1134218562
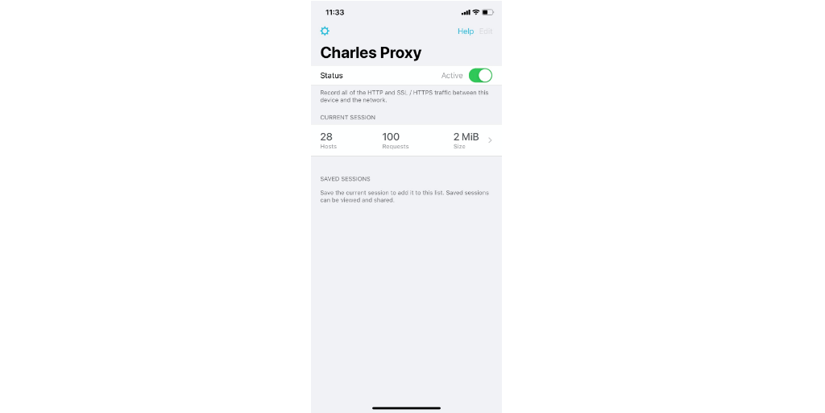
Now it is easier to make Charles intercept your favorite app HTTPS traffic. Install the app, and then activate it on the main screen:
Once you have Charles activated and the VPN configuration set up you need to go to the settings screen and enable SSL proxying (just follow the instructions):
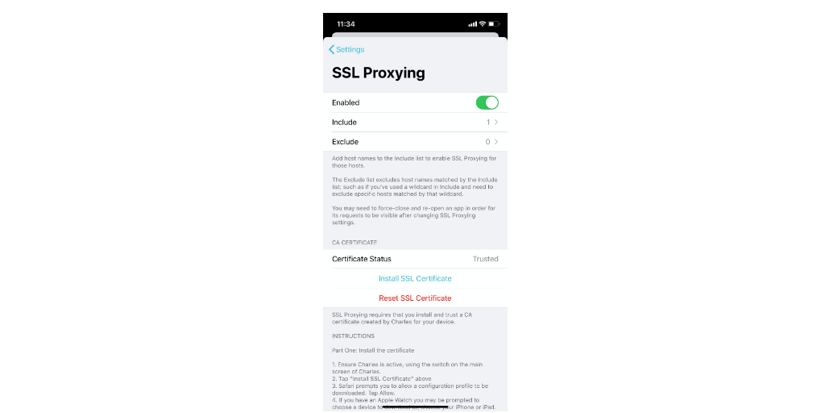
When you turn on SSL proxying, some apps may stop working. When you install Charles, you are also installing a root certificate, so that Charles can inspect your SSL traffic.
It's kind of a "man-in-the-middle" attack (but you're attacking yourself in this case).
Some apps are verifying the root certificate, and won't accept Charles's root certificate. This is called SSL pinning.
The iOS application that we are going to analyze is the https://dev.to one: https://apps.apple.com/us/app/dev-community/id1439094790
Dev.to is a great community website for developers where people can post articles.
This app is very straightforward it allows reading on dev.to with a native experience.
Now open the app with Charles activated, and scroll several times to load more articles.
As with the Charles desktop app you will need to filter the dev.to domain in order to avoid seeing the requests sent by every other app.
Then you can click on the requests sequence, and share it to your Mac for further analysis (no need to analyze the request on your mobile device):
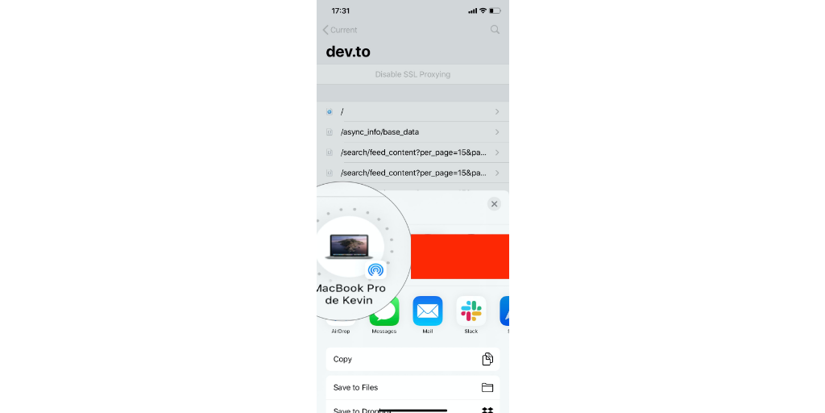
Now we are going to open the request session on Charles desktop application and play with the requests. Double click on the Charles session file in your download folder (it ends with .chlsj):
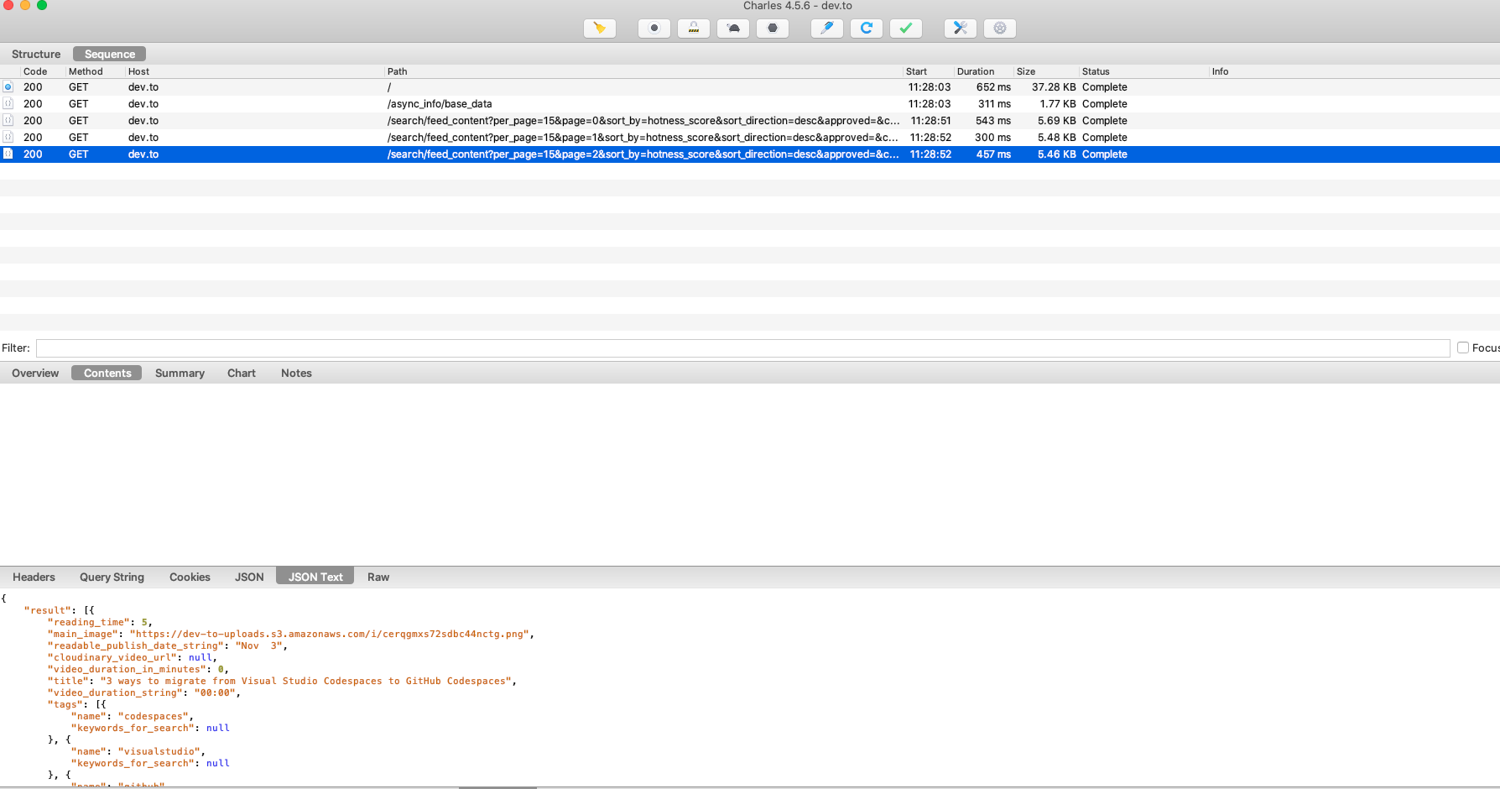
Like on the previous part, you can do exactly the same analysis with this request session.
The interesting requests are the ones on the /search endpoint. This is a standard REST API.
It seems there isn't any authentication/cookies or specific headers needed to get a successful response. You can verify this by:
- Creating a new session with CMD+N
- Filtering on dev.to like on the previous part
- Go back to the mobile dev.to session
- clicking on the
Composebutton and deleting the cookies and headers and thenExecute - Go back to the Desktop session
The interesting parameters are the page number and per_page count. You can play with these values.
After exporting the request to cURL and then converting it to Python:
import requests
params = (
('per_page', '5'),
('page', '1'),
('sort_by', 'hotness_score'),
('sort_direction', 'desc'),
('approved', ''),
('class_name', 'Article'),
)
response = requests.get('https://dev.to/search/feed_content', verify=False, params=params)
print(response.text)
This is one of my favorite techniques to extract data from hard-to-scrape websites. It is much faster than using headless browsers, and parsing a JSON response is much easier than messy HTML code that often changes.
Going further
There are many Charles features that we didn't see in this tutorial. For example, breakpoint and response rewriting. This can be very interesting for people wanting to test/debug Single Page Applications or Mobile applications.
Charles is very handy when you want to extract data from websites or reverse engineer mobile applications, but it is also almost mandatory to do any kind of browser automation on complex websites.
For example, authentication workflows can be very hard to understand with regular browser developer tools. As soon as you start having JWT tokens, CSRF tokens and Oauth, it starts getting messy, and being able to perform a full-text search on a series of requests and replay/modify requests is a must-have.
If you liked this article, you might want to read these:
- Web Scraping with Python To learn about the different ways to scrape in Python
- Web Scraping without getting blocked : this one will show you the different techniques in order to avoid getting blocked while scraping the web
- Best web scraping tools : This article is about the best web scraping tools out there.
I hope you liked this introduction to Charles and reverse engineering in general, and that you will experiment on your favorite apps.
Have fun, and happy scraping!
Before you go, check out these related reads:

Kevin worked in the web scraping industry for 10 years before co-founding ScrapingBee. He is also the author of the Java Web Scraping Handbook.

