Dealing with a website that uses lots of Javascript to render their content can be tricky. These days, more and more sites are using frameworks like Angular, React, Vue.js for their frontend.
These frontend frameworks are complicated to deal with because there are often using the newest features of the HTML5 API.
So basically the problem that you will encounter is that your headless browser will download the HTML code, and the Javascript code, but will not be able to execute the full Javascript code, and the webpage will not be totally rendered.
There are some solutions to these problems. The first one is to use a better headless browser. And the second one is to inspect the API calls that are made by the Javascript frontend and to reproduce them.
It can be challenging to scrape these SPAs because there are often lots of Ajax calls and Websockets connections involved. If performance is an issue, you should always try to reproduce the Javascript code, meaning manually inspecting all the network calls with your browser inspector, and replicating the AJAX calls containing interesting data.
So depending on what you want to do, there are several ways to scrape these websites. For example, if you need to take a screenshot, you will need a real browser, capable of interpreting and executing all the Javascript code in order to render the page, that is what the next part is about.

Headless Chrome with Python
PhantomJS was the leader in this space, it was (and still is) heavy used for browser automation and testing. After hearing the news about the release of the headless mode with Chrome, the PhantomJS maintainer said that he was stepping down as maintainer, because I quote “Google Chrome is faster and more stable than PhantomJS [...]” It looks like Chrome in headless mode is becoming the way to go when it comes to browser automation and dealing with Javascript-heavy websites.
Prerequisites
You will need to install the selenium package:
pip install seleniumAnd of course, you need a Chrome browser, and Chromedriver installed on your system.
On macOS, you can simply use brew:
brew install chromedriverTaking a screenshot
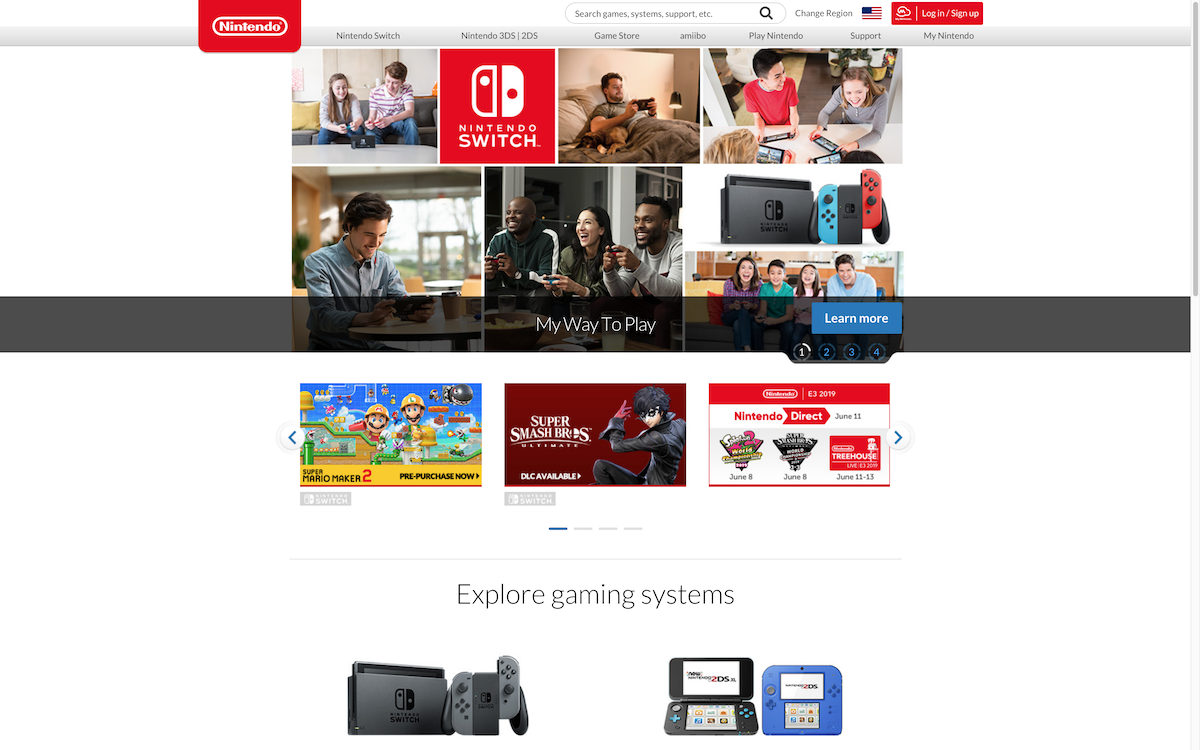
We are going to use Chrome to take a screenshot of the Nintendo's home page which uses lots of Javascript.
> chrome.py
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
options.headless = True
options.add_argument("--window-size=1920,1200")
driver = webdriver.Chrome(options=options, executable_path=r'/usr/local/bin/chromedriver')
driver.get("https://www.nintendo.com/")
driver.save_screenshot('screenshot.png')
driver.quit()The code is really straightforward, I just added a parameter --window-size because the default size was too small.
You should now have a nice screenshot of the Nintendo's home page:
Waiting for the page load
Most of the times, lots of AJAX calls are triggered on a page, and you will have to wait for these calls to load to get the fully rendered page.
A simple solution to this is to just time.sleep() en arbitrary amount of time. The problem with this method is that you are either waiting too long, or too little depending on your latency and internet connexion speed.
The other solution is to use the WebDriverWait object from the Selenium API:
try:
elem = WebDriverWait(driver, delay)
.until(EC.presence_of_element_located((By.NAME, 'chart')))
print("Page is ready!")
except TimeoutException:
print("Timeout")This is a great solution because it will wait the exact amount of time necessary for the element to be rendered on the page.
Conclusion
As you can see, setting up Chrome in headless mode is really easy in Python. The most challenging part is to manage it in production. If you scrape lots of different websites, the resource usage will be volatile.
Meaning there will be CPU spikes, memory spikes just like a regular Chrome browser. After all, your Chrome instance will execute un-trusted and un-predictable third-party Javascript code! Then there is also the zombie-processes problem.
If you want to know how to do this in Javascript, you'll probably like this article about how to scrape infinite scroll with Puppeteer
This is one of the reason we started ScrapingBee, a web scraping api, so that developers can focus on extracting the data they want, not managing Headless browsers and proxies!
I recently wrote "A guide to Web scraping without getting blocked", do not hesitate to check it out.
If you want to know more about the Python web scraping ecosystem, don't hesitate to look at our python web scraping tutorial
And here is a recent article about the best web scraping tools on the market.
Happy Web Scraping :)
Before you go, check out these related reads:

Kevin worked in the web scraping industry for 10 years before co-founding ScrapingBee. He is also the author of the Java Web Scraping Handbook.
