OCaml is a modern, type-safe, and expressive functional programming language. Even though it's less commonly used than popular languages like Python or Java, you can create powerful applications like web scrapers with it.
In this article, you'll learn how to scrape static and dynamic websites with OCaml.
To follow along, you'll need to have OCaml installed on your computer, OPAM initialized, and Dune installed. All of these steps are explained in the official installation instructions, so go ahead and set up the development environment before you continue.
Basic Web Scraping
Let's start with baby steps: scraping this simple static website that shows a list of quotes.

For simplicity, you'll scrape only the first page.
Initialize a project with Dune by running the following command:
dune init proj ocaml_scrape_demo
Change into the newly created ocaml_scrape_demo directory:
cd ocaml_scrape_demo
Install the required dependencies with OPAM:
opam install cohttp cohttp-lwt-unix lambdasoup
Edit bin/dune and add cohttp, cohttp-lwt-unix and lambdasoup to the libraries section. The file should look like this:
(executable
(public_name ocaml_scrape_demo)
(name main)
(libraries ocaml_scrape_demo cohttp cohttp-lwt-unix lambdasoup))
Open bin/main.ml to write the scraper code. Start by opening the required modules:
open Lwt
open Cohttp_lwt_unix
open Soup
Add the following code, which makes a request to http://quotes.toscrape.com/ and parses the response into a Lambda Soup node:
let body =
Client.get (Uri.of_string "http://quotes.toscrape.com/") >>= fun (_, body) ->
body |> Cohttp_lwt.Body.to_string >|= parse
Note that this code simply defines the steps to parse the website code, but it doesn't make a request yet. The actual parsing will be done later in the code.
Now comes the actual scraping part. To figure out how to select the element you want, you'll need to snoop into the HTML source code. So, open http://quotes.toscrape.com/ in your browser and press F12 to open the developer tools and then the Inspector/Elements tab.

As you can see in the code, the quotes are contained in divs with the class quote. Each quote has a span with the class text that contains the quote's text and a span with the class author that contains the name of the quote's author.
This means that you can select all the quotes with the .quote selector and the text and author names can be selected from each quote with the .text and .author selector. Lambda Soup provides the infix operators $ and $$ to select elements using the CSS selector. $ returns the first element that matches the selector while $$ returns all the elements that matches the selector, as in this example:
let () =
let body = Lwt_main.run body in
let quotes = body $$ ".quote" in
quotes
|> iter (fun quote ->
let text = quote $ ".text" |> R.leaf_text |> String.trim in
let author = quote $ ".author" |> R.leaf_text |> String.trim in
Printf.printf "%s - %s\n" text author
)
Here, Lwt_main.run is responsible for running the steps defined in body. As mentioned before, it makes a request to http://quotes.toscrape.com/ and parses the response into a Lambda Soup node, also named body. body $$ ".quote" selects all elements with the .quote class. The code iterates over all quotes and extracts the text and the author name using quote $ ".text" and quote $ ".author".
Here's what the full code looks like:
open Lwt
open Cohttp_lwt_unix
open Soup
let body =
Client.get (Uri.of_string "http://quotes.toscrape.com/") >>= fun (_, body) ->
body |> Cohttp_lwt.Body.to_string >|= parse
let () =
let body = Lwt_main.run body in
let quotes = body $$ ".quote" in
quotes
|> iter (fun quote ->
let text = quote $ ".text" |> R.leaf_text |> String.trim in
let author = quote $ ".author" |> R.leaf_text |> String.trim in
Printf.printf "%s - %s\n" text author
)
You can now run the code:
dune build
dune exec ocaml_scrape_demo
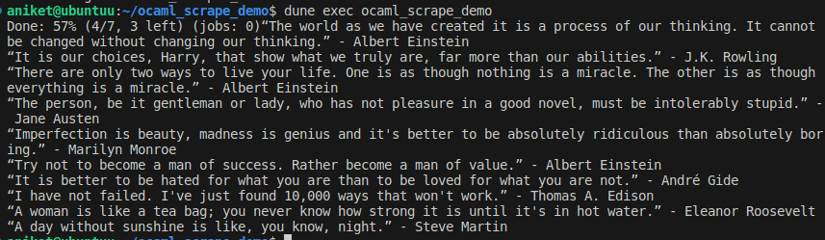
It should print all the quotes on the first page:
Complex CSS Selectors
The previous example shows you how to use the simple class selector in CSS. However, Lambda Soup supports all CSS3 selectors except the following:
:link, :visited, :hover, :active, :focus, :target, :lang, :enabled,
:disabled, :checked, :indeterminate, ::first-line, ::first-letter,
::selection, ::before, ::after
As an example, what if you want to select only the first quote? While you can select it by taking the first element of the quotes list in the previous example, you can also use the :first-child CSS selector.
Here's what the code would look like:
let first_quote = body $ ".quote:first-child .text" |> R.leaf_text |> String.trim in
Printf.printf "First quote: %s\n" first_quote
And here's what the code looks like in full:
open Lwt
open Cohttp_lwt_unix
open Soup
let body =
Client.get (Uri.of_string "http://quotes.toscrape.com/") >>= fun (_, body) ->
body |> Cohttp_lwt.Body.to_string >|= parse
let () =
let body = Lwt_main.run body in
let quotes = body $$ ".quote" in
quotes
|> iter (fun quote ->
let text = quote $ ".text" |> R.leaf_text |> String.trim in
let author = quote $ ".author" |> R.leaf_text |> String.trim in
Printf.printf "%s - %s\n" text author
);
let first_quote = body $ ".quote:first-child .text" |> R.leaf_text |> String.trim in
Printf.printf "First quote: %s\n" first_quote
As output, you'll get the first quote:
💡 For more details on CSS selectors, please check out the article Using CSS Selectors for Web Scraping.
Dynamic Websites
Even though Lambda Soup can employ advanced CSS selectors to help you scrape websites, it's limited to static websites. Lambda Soup can't execute JavaScript, which means you can't use it to scrape dynamic websites and SPAs that load data with JavaScript.
To scrape dynamic websites with OCaml, you can use the WebDriver protocol. It's a set of rules that allows you to remotely control a browser. Your OCaml code can use the WebDriver protocol to execute the scraper inside an actual browser so that the JavaScript code is executed as it happens in a usual browser.
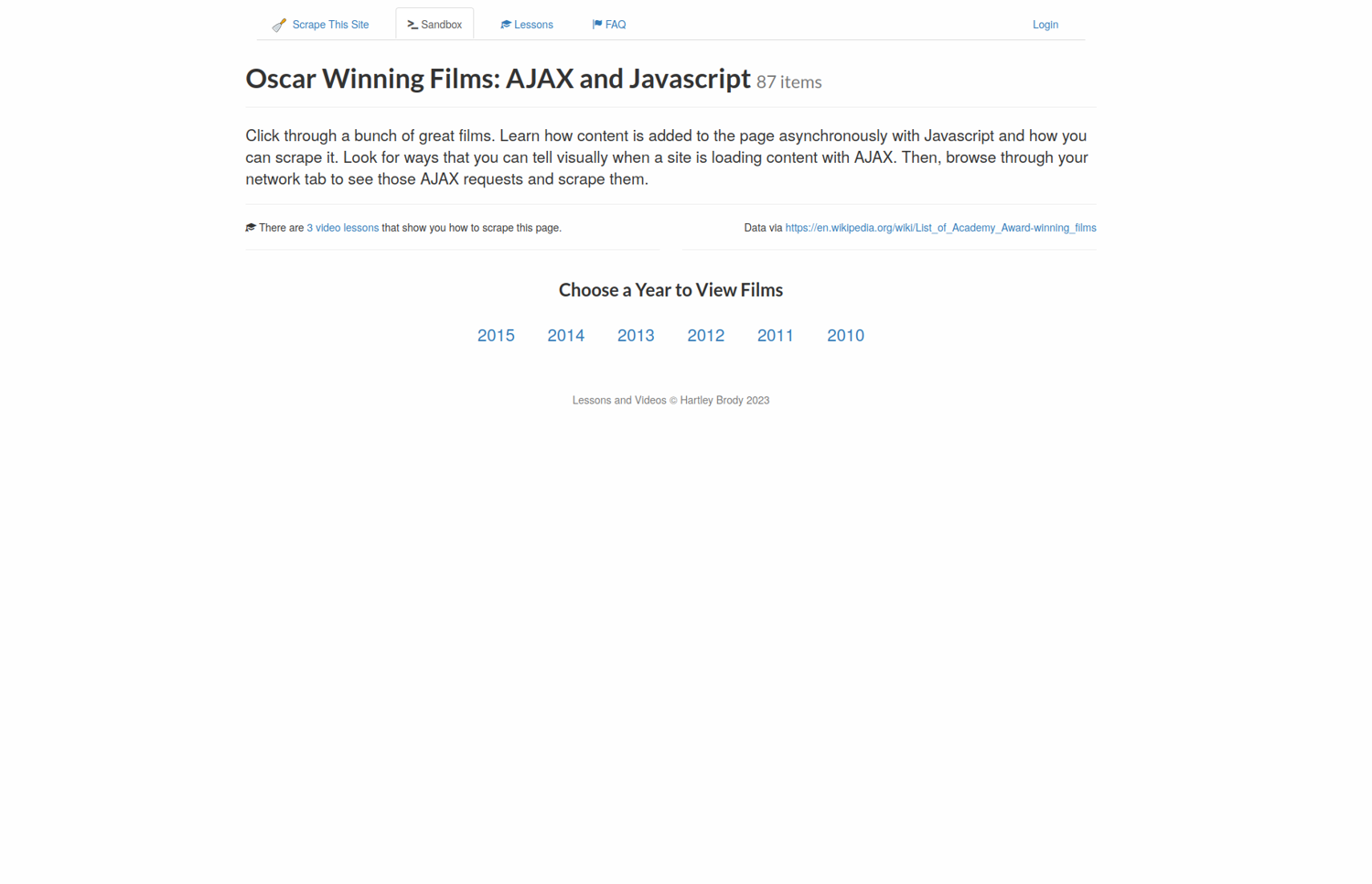
Let's see it in action. Let's say you want to scrape this website that shows a list of Oscar-winning movies. However, the list is empty by default.
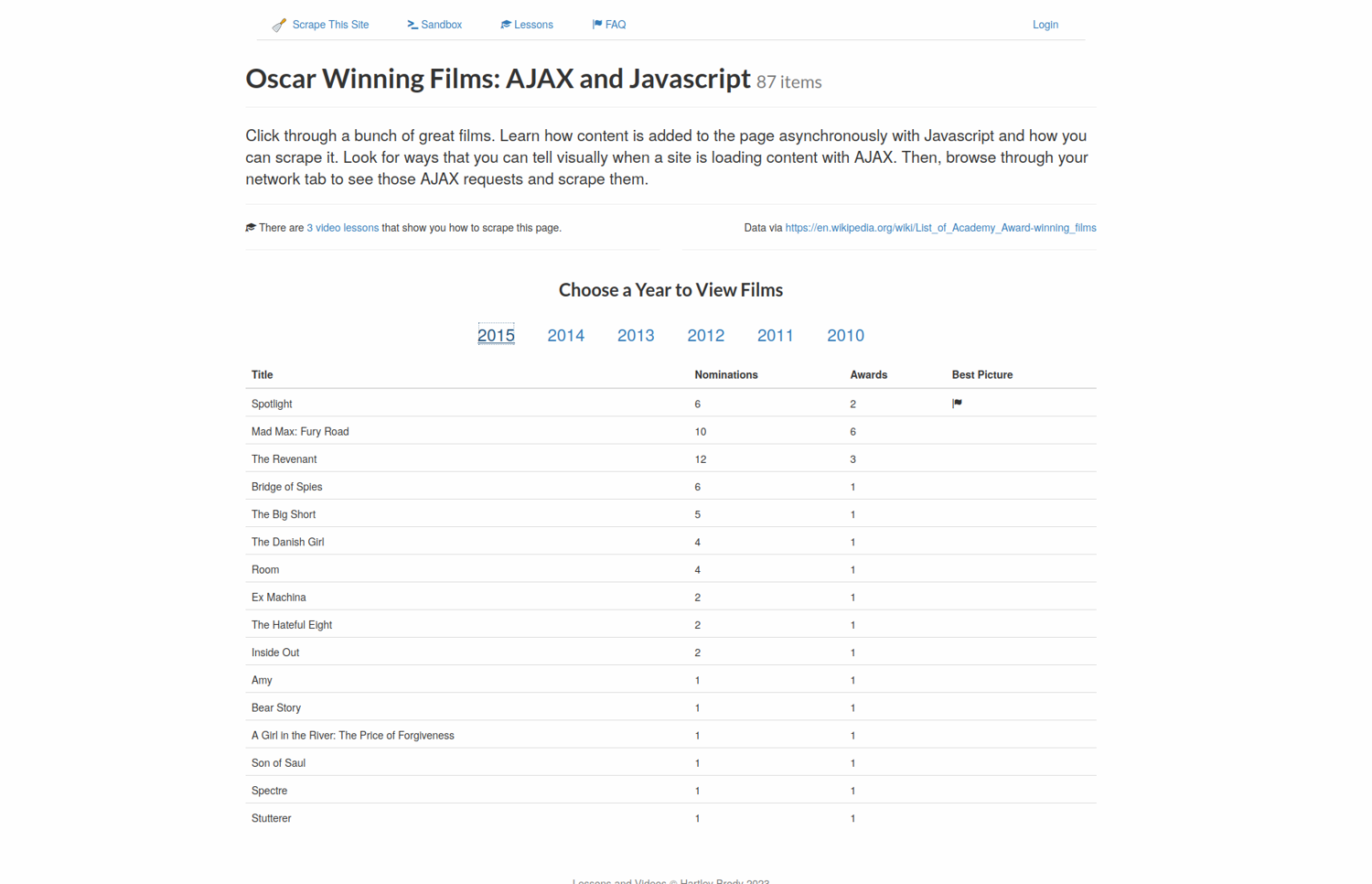
When you click on one of the links—2015 for example—the site loads the data using JavaScript.
To scrape this site, you'll first need to download the WebDriver for your favorite browser:
This article will use GeckoDriver for Firefox.
Remember that you also need to install the actual browser for whichever driver you choose. You can find installation instructions in the links above.
Once you have the driver installed, go ahead and run it. The usage instructions are also given in the links above.
To communicate with the browser, you'll use the ocaml-webdriver library. It isn't available in the OPAM registry, so you'll have to build and install it yourself.
First, clone the ocaml-webdriver Git repo:
git clone https://github.com/art-w/ocaml-webdriver.git
cd ocaml-webdriver
Install the cohttp-async package, which is needed to build the ocaml-webdriver:
opam install cohttp-async
Finally, build and install ocaml-webdriver:
dune build
dune install
You're now ready to write your code. To keep things clean, let's create a separate project:
dune init proj ocaml_advanced_scraper
Enter the ocaml_advanced_scraper directory:
cd ocaml_advanced_scraper
Edit bin/dune and add webdriver_cohttp-lwt-unix to the libraries section:
(executable
(public_name ocaml_advanced_scraper)
(name main)
(libraries ocaml_advanced_scraper webdriver_cohttp-lwt-unix))
Open bin/main.ml. Start by opening the required modules:
open Webdriver_cohttp_lwt_unix
open Infix
You'll need to write a few helper functions that'll make it easy to work with the data types provided by the ocaml-webdriver package. The first such function is the list_iter function, which iterates over a list of HTML elements:
let rec list_iter f = function
| [] -> return ()
| x :: xs ->
let* () = f x in
list_iter f xs
The second one is the wait function, which waits until an element appears on the page:
let rec wait cmd =
Error.catch (fun () -> cmd)
~errors:[`no_such_element]
(fun _ -> sleep 100 >>= fun () -> wait cmd)
Finally, define the action that'll spell out the steps to take:
let action =
let* () = goto "https://www.scrapethissite.com/pages/ajax-javascript" in
let* link =
find_first
`css
"a.year-link"
in
let* () = click link in
let* _ = wait (find_first `css "tr.film") in
let* movies =
find_all
`css
"tr.film .film-title" in
list_iter (fun movie_name ->
let* name = text movie_name in
Printf.printf "%s\n" name;
return ()
) movies
Here's what's happening in the code:
- First,
gotois used to open the webpage. - The first link for 2015 movies is selected using
find_first. The`cssargument specifies that the CSS selectora.year-linkis used to find the element. There are also other selection strategies available. clickis used to click the link.waitis used to wait for an element with the CSS selectortr.filmto be available.- Once such an element is available, all the elements with CSS selector
tr.film .film-titleare selected. list_iteris used to iterate over the list of movies.textis used to extract the movie name, and it is printed.
The final step required is to connect to a WebDriver and execute the code.
The following code connects to http://127.0.0.1:4444, which is the default address that the GeckoDriver listens to. You'll need to change it if you're using a different driver. You'll also need to change the Capabilities.firefox_headless value to one of the accepted values:
let host = "http://127.0.0.1:4444"
let () =
try Lwt_main.run (run ~host Capabilities.firefox_headless action)
with Webdriver e ->
Printf.fprintf stderr "[FAIL] Webdriver error: %s\n%!" (Error.to_string e) ;
Printexc.print_backtrace stderr ;
Printf.fprintf stderr "\n%!"
Here's the full code:
open Webdriver_cohttp_lwt_unix
open Infix
let rec list_iter f = function
| [] -> return ()
| x :: xs ->
let* () = f x in
list_iter f xs
let rec wait cmd =
Error.catch (fun () -> cmd)
~errors:[`no_such_element]
(fun _ -> sleep 100 >>= fun () -> wait cmd)
let action =
let* () = goto "https://www.scrapethissite.com/pages/ajax-javascript" in
let* link =
find_first
`css
"a.year-link"
in
let* () = click link in
let* _ = wait (find_first `css "tr.film") in
let* movies =
find_all
`css
"tr.film .film-title" in
list_iter (fun movie_name ->
let* name = text movie_name in
Printf.printf "%s\n" name;
return ()
) movies
let host = "http://127.0.0.1:4444"
let () =
try Lwt_main.run (run ~host Capabilities.firefox_headless action)
with Webdriver e ->
Printf.fprintf stderr "[FAIL] Webdriver error: %s\n%!" (Error.to_string e) ;
Printexc.print_backtrace stderr ;
Printf.fprintf stderr "\n%!"
Build and execute your OCaml code:
dune build
dune exec ocaml_advanced_scraper
You should see the names of the movies in the output:
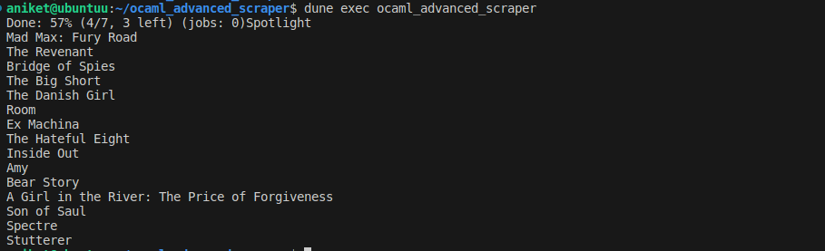
Conclusion
OCaml is a powerful language that makes it easy to scrape static and dynamic websites using libraries like Lambda Soup and ocaml-webdriver. In the first part of this article, you learned how to use Lambda Soup to scrape basic static websites. In the second part, you used ocaml-webdriver to scrape a dynamic site.
You can find the code for this tutorial on GitHub.
If you prefer not to have to deal with rate limits, proxies, user agents, and browser fingerprints, though, check out Scrapingbee's no-code web scraping API. The first 1,000 calls are free!
Before you go, check out these related reads:

Aniket is a student doing a Master's in Mathematics and has a passion for computers and software. He likes to explore various areas related to coding and works as a web developer using Ruby on Rails and Vue.JS.

