Imagine you're a developer who needs to keep track of the latest news from multiple sources for a project you're working on. Instead of manually visiting each news website and checking for updates, you want to automate this process to save time and effort. You need a news crawler.
In this article, you'll see how easy it can be to build a news crawler using Python Flask and the ScrapingBee API. You'll learn how to set up ScrapingBee, implement crawling logic, and display the extracted news on a web page.

Prerequisites
To follow along with this tutorial, you need the following:
- A free ScrapingBee account
- Python
- Flask
- APScheduler
This tutorial uses Python 3.11.0 and APScheduler 3.10.1. If you use different versions, some functionalities may vary.
Setting Up Your Environment
Start by logging in to your ScrapingBee account and obtaining your API key from the API key management page. The Python application you'll build later on in this tutorial will use the API key to make use of the ScrapingBee API.
Next, you'll install the ScrapingBee library, which you'll use to extract and gather data from news sites.
Start by creating a directory to organize your project. Open your terminal or command prompt and execute the following command:
mkdir news-crawler
Move into this directory by running the following command:
cd news-crawler
It's best to use a virtual environment to keep your project dependencies isolated. Run the following command to create a virtual environment named newsenv:
python -m venv newsenv
Activate the virtual environment using the appropriate command for your operating system:
On Mac/Linux:
source newsenv/bin/activate
On Windows:
newsenv\Scripts\activate
Now that your virtual environment is active, you can install the ScrapingBee library by executing the following command:
pip install scrapingbee
Identifying Websites to Scrape
Before you build your crawler, it's important to identify the websites you'll be scraping. This tutorial will use three popular news sources: CNN, NBC, and Yahoo.
Each of these websites has its own structure and HTML elements that contain the news headlines you're after. Consequently, you'll use different extract_rules to extract the headlines from each website. They specify the HTML elements' selectors and the desired output format (e.g., text).
By using different extract_rules for each news source, you will learn how to adapt the scraping process based on the website's structure and extract the relevant information effectively. This will allow you to adapt this tutorial to other websites if you would wish to do so.
Here are the specific URLs you'll be using in this tutorial:
- CNN: https://edition.cnn.com/business
- NBC: https://www.nbcnews.com/tech-media
- Yahoo: https://sports.yahoo.com
Building a News Crawler with Python
You're now ready to build your news crawler.
In this section, you will create a command line application that scrapes and displays the news in the terminal. In the next section, you'll enhance it by incorporating Flask to display the news on a web page.
To get started, create a new Python file named news_crawler.py inside the news-crawler directory using your favorite text editor or integrated development environment (IDE). In this file, import the necessary modules and set up the basic structure of your crawler using the code block below:
from scrapingbee import ScrapingBeeClient
client = ScrapingBeeClient(api_key='YOUR_API_KEY')
# CNN scraping
cnn_url = 'https://edition.cnn.com/business'
cnn_extract_rules = {
"headlines": {
"selector": ".container_lead-plus-headlines__headline span",
"type": "list",
"output": "text"
}
}
# Yahoo scraping
yahoo_url = 'https://sports.yahoo.com/'
yahoo_extract_rules = {
"headlines": {
"selector": "h3 a",
"type": "list",
"output": "text"
}
}
# NBC scraping
nbc_url = 'https://www.nbcnews.com/tech-media'
nbc_extract_rules = {
"headlines": {
"selector": ".styles_headline__ice3t a",
"type": "list",
"output": "text"
}
}
def scrape_and_display_news(url, extract_rules, source_name):
response = client.get(url, params={"extract_rules": extract_rules})
data = response.json()
headlines = data["headlines"]
print(f"{source_name} Headlines:")
for headline in headlines:
print(headline + "\n\n")
scrape_and_display_news(cnn_url, cnn_extract_rules, "CNN")
scrape_and_display_news(nbc_url, nbc_extract_rules, "NBC")
scrape_and_display_news(yahoo_url, yahoo_extract_rules, "Yahoo")
This code snippet imports the ScrapingBeeClient from the ScrapingBee module and creates a client object using your ScrapingBee API key. You then define the URLs and extract_rules for the three news sources mentioned before. The extract_rules specify the CSS selectors for the headlines and define the output format.
Next, it defines the scrape_and_display_news() function, which takes a URL, extract_rules, and source name as parameters. This function sends a GET request to ScrapingBee's API, passing the URL and extract_rules as parameters. It retrieves the response, extracts the headlines from the JSON data, and displays them in the terminal along with the source name.
Finally, it calls the scrape_and_display_news() function for each news source, passing the respective URL, extract_rules, and source name. This will scrape the news headlines and display them in the terminal.
To run the application, open your terminal or command prompt, navigate to the directory where news_crawler.py is located, and execute the following command:
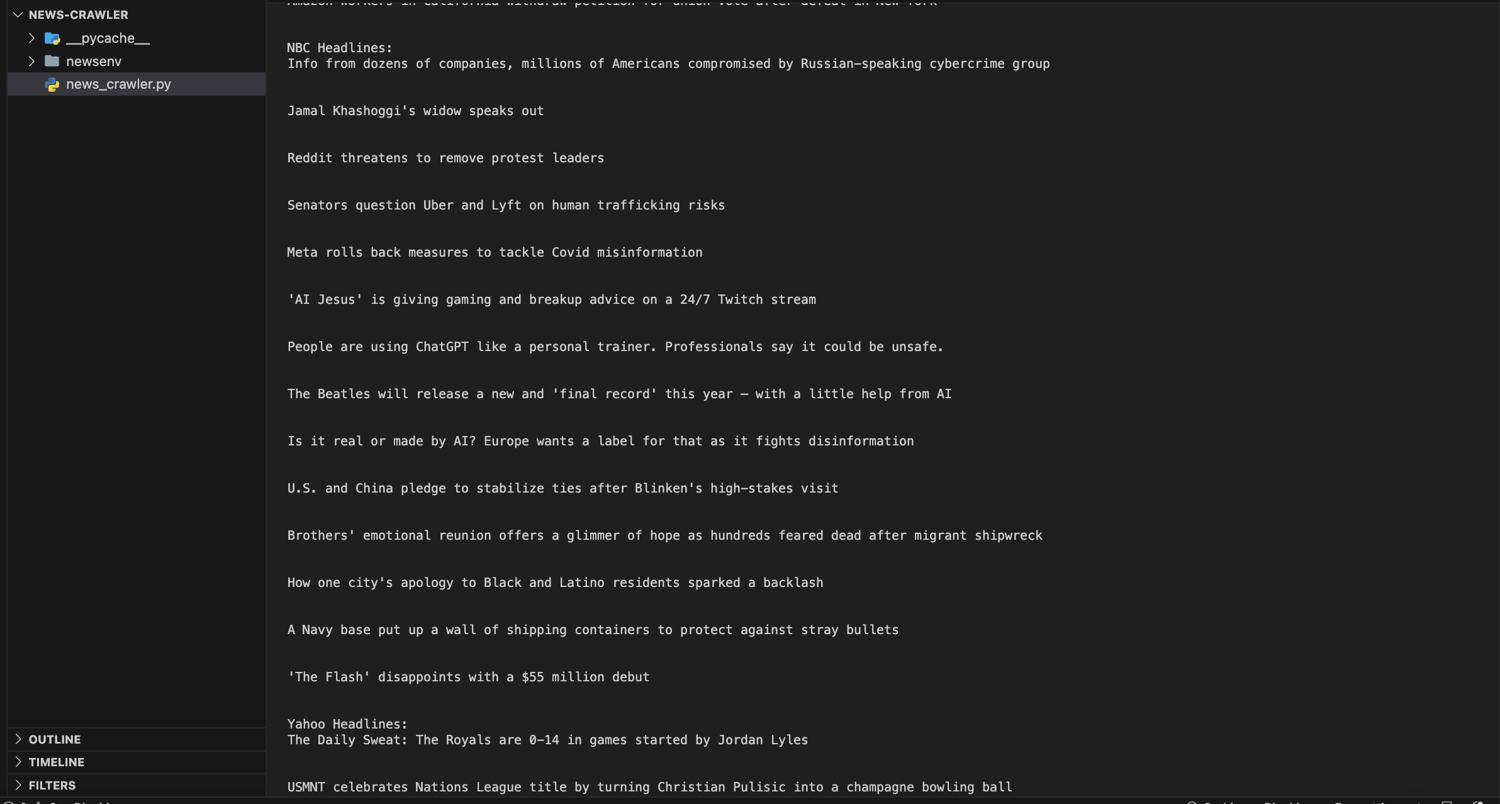
python news_crawler.py
You should see the news headlines from CNN, NBC, and Yahoo displayed in the terminal with their respective source names.
Scheduling and Displaying News on a Web Page with Flask
The only thing left to do is to enhance your command line news crawler by incorporating scheduling and displaying the news on a web page using Flask.
To do this, you'll use the Flask web framework for the web application and the APScheduler library for scheduling the crawling process.
Start by installing the required dependencies:
pip install flask
pip install APScheduler==3.10.1
Then, import the necessary modules:
from flask import Flask, render_template
from apscheduler.schedulers.background import BackgroundScheduler
from scrapingbee import ScrapingBeeClient
from datetime import datetime
from pytz import utc
Next, create an instance of the Flask application and a scheduler object:
app = Flask(__name__)
scheduler = BackgroundScheduler(timezone=utc)
Set up the ScrapingBee client by providing your API key:
client = ScrapingBeeClient(api_key='YOUR_API_KEY')
Define the URLs and extract_rules for the news sources as a dictionary:
cnn_url = 'https://edition.cnn.com/business'
cnn_extract_rules = {
"headlines": {
"selector": ".container_lead-plus-headlines__headline span",
"type": "list",
"output": "text"
}
}
yahoo_url = 'https://sports.yahoo.com/'
yahoo_extract_rules = {
"headlines": {
"selector": "h3 a",
"type": "list",
"output": "text"
}
}
nbc_url = 'https://www.nbcnews.com/tech-media'
nbc_extract_rules = {
"headlines": {
"selector": ".styles_headline__ice3t a",
"type": "list",
"output": "text"
}
}
Create an empty dictionary to store the headlines:
cnn_headlines = []
nbc_headlines = []
yahoo_headlines = []
Implement the get_headlines() function to retrieve the headlines for a given URL and extract_rules:
def get_headlines(url, extract_rules):
response = client.get(url, params={"extract_rules": extract_rules})
data = response.json()
headlines = data["headlines"]
return headlines
Define the run_crawling() function to update the headlines by scraping the news sources:
last_crawl_time = None
def run_crawling():
global cnn_headlines, nbc_headlines, yahoo_headlines, last_crawl_time
with app.app_context():
cnn_headlines = get_headlines(cnn_url, cnn_extract_rules)
nbc_headlines = get_headlines(nbc_url, nbc_extract_rules)
yahoo_headlines = get_headlines(yahoo_url, yahoo_extract_rules)
last_crawl_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
Next, define another function called crawling_onstartup() that runs the crawling process only once at startup:
has_run_crawling_onstartup = False
@app.before_request
def crawling_onstartup():
global has_run_crawling_onstartup
if not has_run_crawling_onstartup:
run_crawling()
has_run_crawling_onstartup = True
The code above ensures that the headlines are fetched from the news sources and stored in the cnn_headlines, nbc_headlines, and yahoo_headlines lists on the first request to the app. This way, when a user visits the web page, they immediately see the latest news headlines without any delay.
Create a Flask route to display the news on a web page:
@app.route('/')
def display_news():
global last_crawl_time
if last_crawl_time is None:
last_crawl_time = "No crawl has been scheduled yet."
return render_template('news.html', cnn_headlines=cnn_headlines, nbc_headlines=nbc_headlines, yahoo_headlines=yahoo_headlines, last_crawl_time=last_crawl_time)
Add the following code to start the scheduler and run the Flask application:
if __name__ == "__main__":
scheduler.add_job(run_crawling, 'interval', minutes=1)
scheduler.start()
app.run()
Create a new directory called templates and add an HTML template file named news.html to define the structure and layout of the news page:
<!-- templates/news.html -->
<!DOCTYPE html>
<html>
<head>
<title>News Headlines</title>
</head>
<body>
<h1>News Headlines</h1>
<p>Last Updated: {{ last_crawl_time }}</p>
<h2>CNN</h2>
<ul>
{% for headline in cnn_headlines %}
<li>{{ headline }}</li>
{% endfor %}
</ul>
<h2>NBC</h2>
<ul>
{% for headline in nbc_headlines %}
<li>{{ headline }}</li>
{% endfor %}
</ul>
<h2>Yahoo</h2>
<ul>
{% for headline in yahoo_headlines %}
<li>{{ headline }}</li>
{% endfor %}
</ul>
</body>
</html>
You can customize this file to suit your needs and use the {{ headlines }} variable to access the headlines data in the template.
With this setup, the crawling process is scheduled to run every minute, and the updated headlines will be displayed on the web page. Feel free to customize the Flask routes, HTML template, and scheduling interval according to your requirements.
To access the news page, run this command:
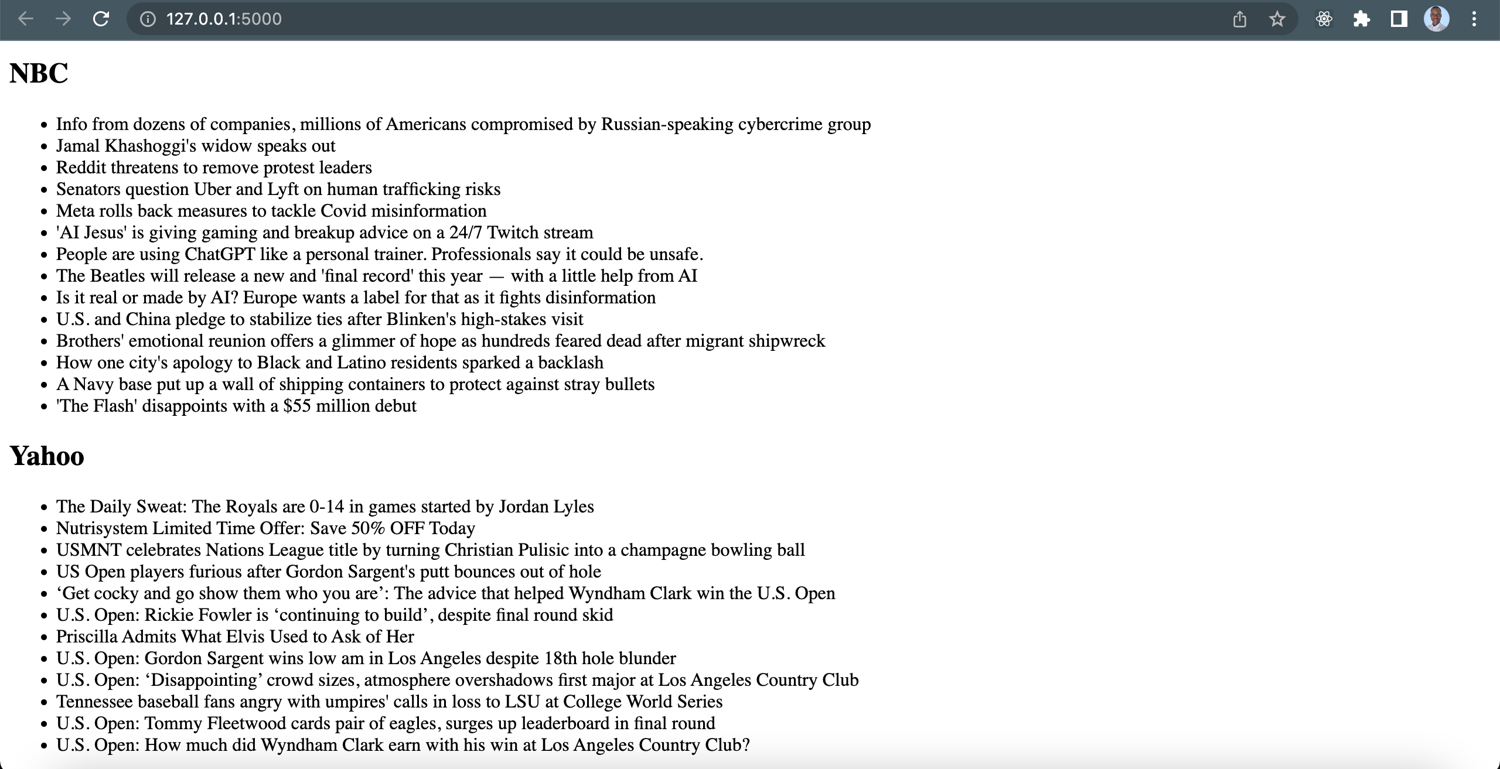
python news_crawler.py
Navigate to http://localhost:5000/ in your browser to see what it looks like.
Conclusion
Congratulations! You've successfully built a news crawler using Python Flask and ScrapingBee. You can find the code for this tutorial in this GitHub repo.
As you saw in this tutorial, ScrapingBee and Flask make it pretty straightforward to scrape and display news from various websites. ScrapingBee gives you a hassle-free crawling experience where you don't have to deal with rate limits, proxies, user agents, and browser fingerprints.
To explore the full range of ScrapingBee's features, functionalities, and advanced usage, check out the ScrapingBee API documentation.
Before you go, check out these related reads:



