While Python and Node.js are popular platforms for writing scraping scripts, Jaunt provides similar capabilities for Java.
Jaunt is a Java library that provides web scraping, web automation, and JSON querying abilities. It relies on a light, headless browser to load websites and query their DOM. The only downside is that it doesn't support JavaScript—but for that, you can use Jauntium, a Java browser automation framework developed and maintained by the same person behind Jaunt, Tom Cervenka.
In this article, you will learn how to use Jaunt to scrape websites in Java. You'll first see how to scrape a dynamic website like Wikipedia and then learn some of the other powerful features that Jaunt offers, such as form handling, navigation, and pagination.

💡 Interested in web scraping with Java? Check out our guide to the best Java web scraping libraries
Prerequisites
For this tutorial, you will need to have Java installed on your system. You can use any IDE of your choice to follow along.
You will also need to set up a new directory for your project and install the Jaunt package.
Note: You could consider setting up a full-fledged Maven/Gradle project to see how to install and use this library in real-world projects, but this tutorial will use single-file Java programs to keep management simple and allow you to focus on understanding how the Jaunt library works.
To get started, run the following command to create a new directory for your project and change your terminal's working directory to inside it:
mkdir scraper
cd scraper
Next, you need to install the Jaunt library. Unlike most other libraries, the Jaunt library isn't available as a Maven or Gradle dependency that you can add in your project using your build manager. Instead, it is distributed as a JAR package, and you need to add this JAR file to your project manually.
If you are following along with a Maven/Gradle project, you can find instructions on how to add a JAR package as a dependency in your Maven and Gradle projects.
For this tutorial, however, you only need to download the release files from the download page, extract them, and copy the JAR file (named something like jaunt1.6.1jar) to your newly created scraper directory.
You will now use the classpath argument -cp for passing in the Jaunt classpath to your java commands to run the Java programs successfully.
For Windows, use the following command to compile and run the Java programs:
java -cp '.;jaunt1.6.1.jar' Program.java
For Unix-like operating systems, use the following command:
java -cp '.:jaunt1.6.1.jar' Program.java
Basic Web Scraping with Jaunt
Jaunt works great when it comes to static websites. It provides you with powerful methods like findEvery() and findAttributes() to cherry-pick the information you need from the DOM of the website you're scraping.
In this section, you will see how to scrape the Wikipedia page on web scraping. While there is a lot of information you can scrape from this page, you will focus on extracting the title (to learn how to find an element in an HTML page) and the list of hyperlinks from the References section (to learn how to extract data that is embedded deep within multiple layers of HTML).
To start, create a new file with the name WikipediaScraper.java and paste the following code in it:
import com.jaunt.Element;
import com.jaunt.Elements;
import com.jaunt.JauntException;
import com.jaunt.UserAgent;
public class WikipediaScraper {
public static void main(String[] args) {
try {
} catch (JauntException e) {
e.printStackTrace();
}
}
}
This boilerplate code defines a new public class, WikipediaScraper, and defines a main() method in it. Inside the main() method, it defines a try-catch block to catch Jaunt-related exceptions. This is where you will write the code for scraping the Wikipedia page.
Begin by creating a Jaunt UserAgent:
UserAgent userAgent = new UserAgent();
Next, navigate to the target website using the visit() method:
userAgent.visit("https://en.wikipedia.org/wiki/Web_scraping");
Extracting the Title
As the first step, you will find and extract the title of the page using Jaunt's findFirst() method. Here's how you can find the title of the page:
Element title = userAgent.doc.findFirst("<span class=\"mw-page-title-main\">");
The selector query passed to the findFirst() was written by looking at the HTML structure of the website. You can find it by opening the website in a browser like Chrome or Firefox and inspecting its elements. (You can use the F12 key or right-click and choose Inspect from the context menu.) Here's what you will find:
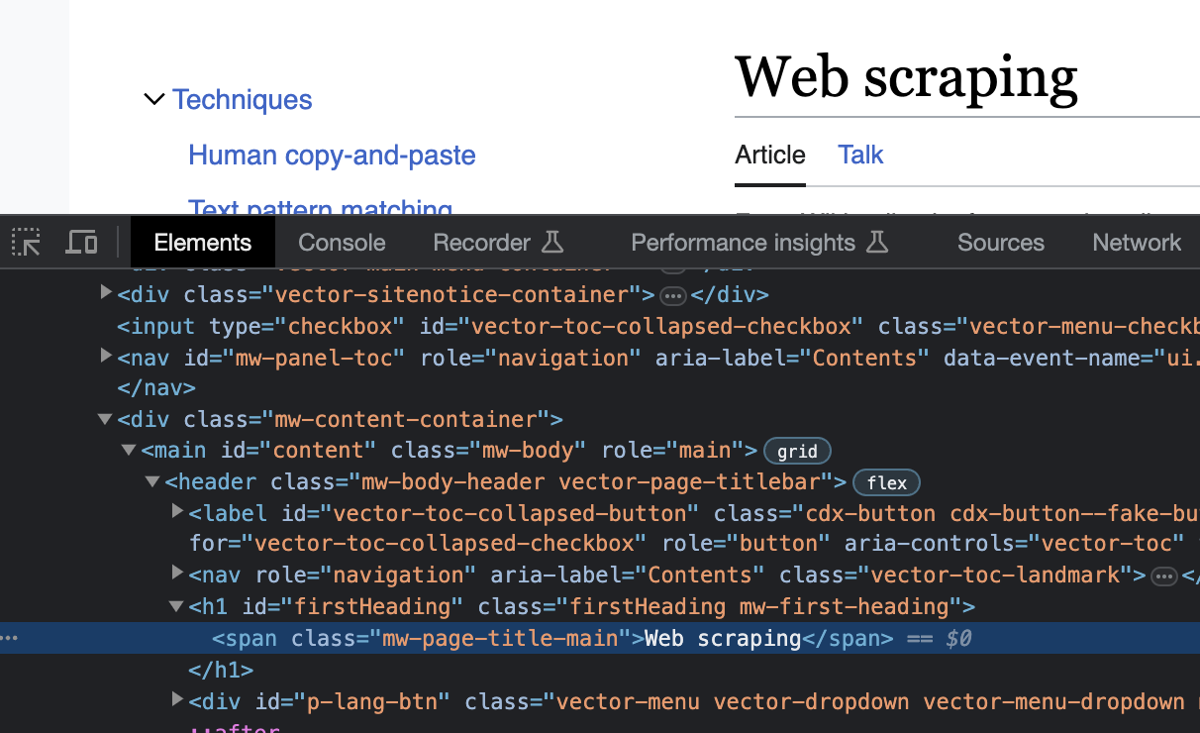
Next, extract the value from the Jaunt Element object and print it:
System.out.println("Page title: " + title.innerHTML());
Here's what the WikipediaScraper.java file should look like at this point:
import com.jaunt.Element;
import com.jaunt.Elements;
import com.jaunt.JauntException;
import com.jaunt.UserAgent;
public class WikipediaScraper {
public static void main(String[] args) {
try {
// Create a UserAgent instance
UserAgent userAgent = new UserAgent();
// Visit the Wikipedia page
userAgent.visit("https://en.wikipedia.org/wiki/Web_scraping");
// Find the title by its HTML tag
Element title = userAgent.doc.findFirst("<span class=\"mw-page-title-main\">");
// Print the title of the page
System.out.println("Page title: " + title.innerHTML());
} catch (JauntException e) {
e.printStackTrace();
}
}
}
You can run the program using the following command:
java -cp '.:jaunt1.6.1.jar' WikipediaScraper.java
Here's what the output will look like:
Page title: Web scraping
Extracting the References
Next, you will locate and extract the hyperlinks from the References section of the Wikipedia page. To do that, first take a look at the HTML structure of the References section of the page:
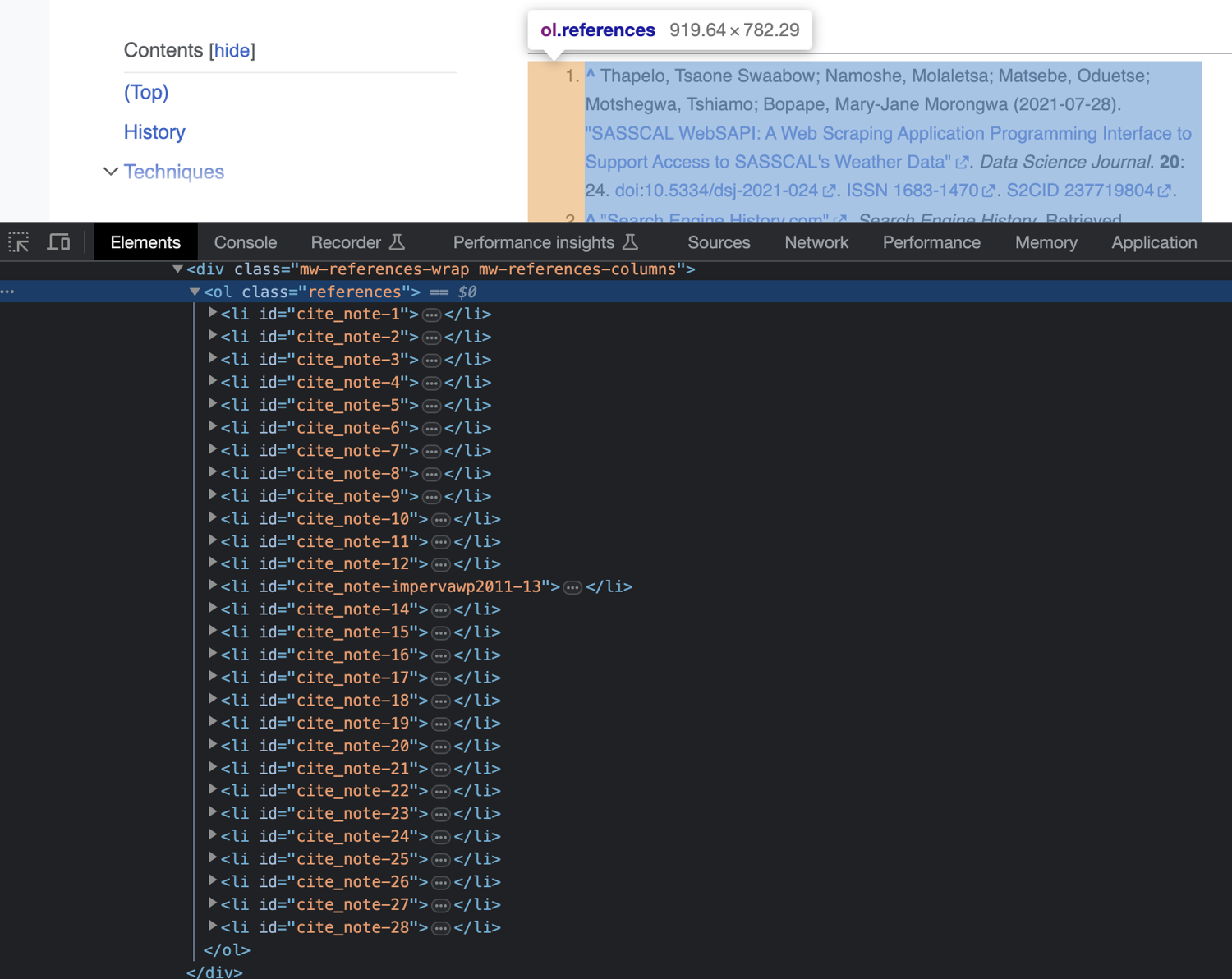
As you can see, all references are inside an <ol> tag with the class name "references". You can use this to extract the list of references. To do that, add the following line of code to the file:
Element referencesSection = userAgent.doc.findFirst("<ol class=\"references\">");
At this point, you can extract all hyperlinks that are inside the referencesSection tag using Jaunt's findAttributeValues() method. However, if you take a closer look at the structure of the references section, you will notice that it also contains backlinks to the parts of the article where the reference was cited.
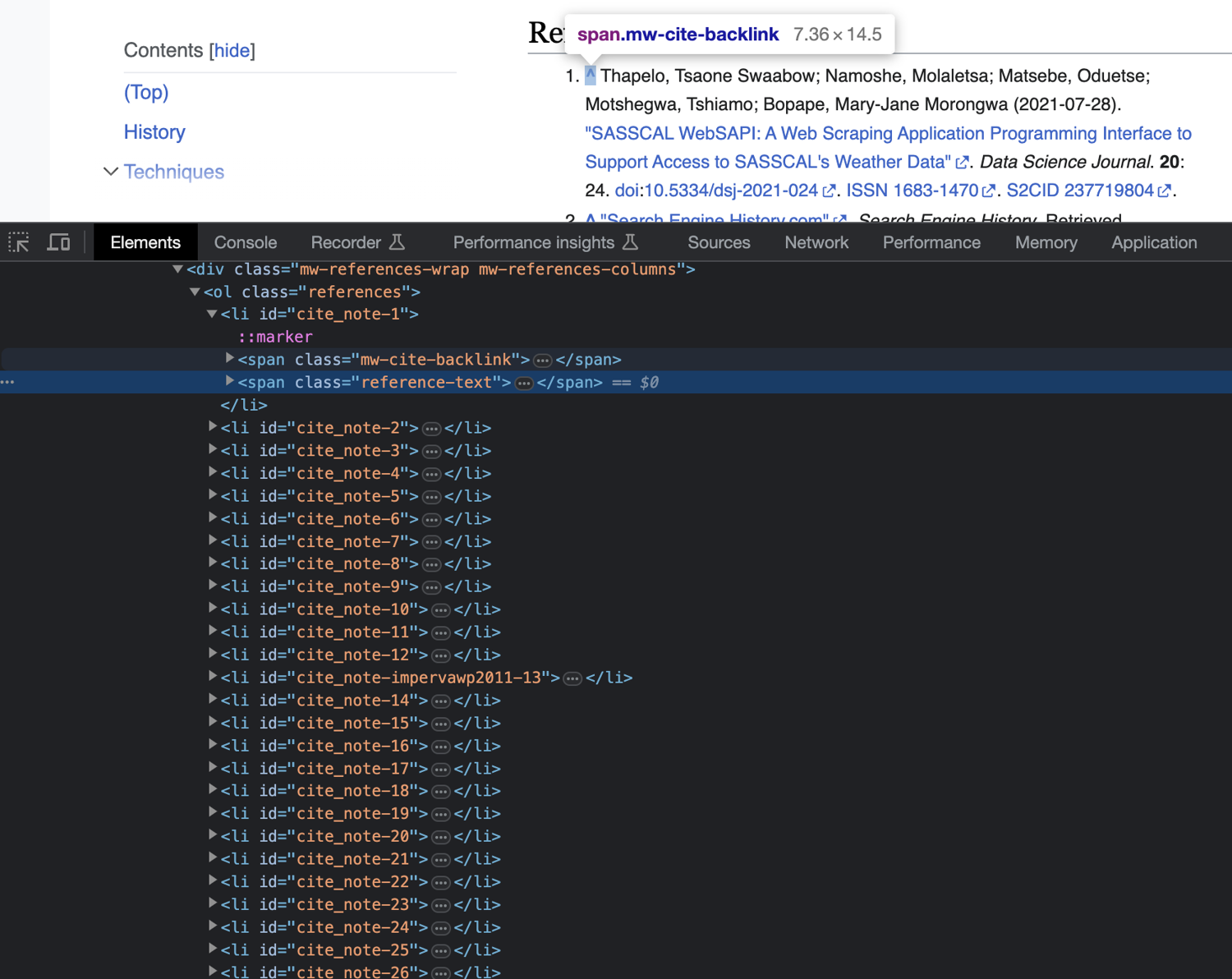
If you query all anchor links from the referencesSection, you will also receive all backlinks as part of your results. To avoid that, first query and extract all <span class="reference-text"> tags from the referencesSection to get rid of the backlinks using this line of code:
Elements referencesList = referencesSection.findEvery("<span class=\"reference-text\">");
Now, you can query and print all anchor links from inside the referencesList variable using findAttributeValues():
System.out.println(referencesList.findAttributeValues("<a href>"));
This is what your WikipediaScraper.java file should look like now:
import com.jaunt.Element;
import com.jaunt.Elements;
import com.jaunt.JauntException;
import com.jaunt.UserAgent;
public class WikipediaScraper {
public static void main(String[] args) {
try {
// Create a UserAgent instance
UserAgent userAgent = new UserAgent();
// Visit the Wikipedia page
userAgent.visit("https://en.wikipedia.org/wiki/Web_scraping");
// Find the title by its HTML tag
Element title = userAgent.doc.findFirst("<span class=\"mw-page-title-main\">");
// Print the title of the page
System.out.println("Page title: " + title.innerHTML());
// Find the "References" section by its HTML tag
Element referencesSection = userAgent.doc.findFirst("<ol class=\"references\">");
// Extract the list of references within the section
Elements referencesList = referencesSection.findEvery("<span class=\"reference-text\">");
System.out.println(referencesList.findAttributeValues("<a href>"));
} catch (JauntException e) {
e.printStackTrace();
}
}
}
Try running it using the following command:
java -cp '.:jaunt1.6.1.jar' WikipediaScraper.java
Here's what the output will look like:
Page title: Web scraping
[http://datascience.codata.org/articles/10.5334/dsj-2021-024/, ...46 items ommitted..., https://s3.us-west-2.amazonaws.com/research-papers-mynk/Breaking-Fraud-And-Bot-Detection-Solutions.pdf]
Advanced Web Scraping with Jaunt
Now that you know how to scrape simple, static websites using Jaunt, you can learn how to use it to scrape dynamic multipage websites.
To begin, create a new file named DynamicScraper.java and store the following boilerplate code in it:
import com.jaunt.Element;
import com.jaunt.Elements;
import com.jaunt.JauntException;
import com.jaunt.UserAgent;
import java.io.FileWriter;
import java.io.IOException;
public class DynamicScraper {
public static void main(String[] args) {
try {
} catch (JauntException e) {
e.printStackTrace();
}
}
}
Similar to the previous file's boilerplate, this code defines the new class, imports the Jaunt classes and a few other necessary classes, and defines a try-catch block to handle Jaunt-related exceptions.
Before you proceed with writing the code, it's important to understand the target website first. You will scrape a dummy website meant for scraping called Scrape This Site.
You will start by navigating to the home page:
Next, you will navigate to the Sandbox page using the link in the navigation bar:
From this page, you will navigate to the "Hockey Teams: Forms, Searching, and Pagination" link:
On this page, you will use the search box to search for teams that have the word "new" in their name. You will extract two pages of data from the search results.
To start, create a new Jaunt UserAgent:
UserAgent userAgent = new UserAgent();
Next, navigate to the Scrape This Site home page:
userAgent.visit("https://www.scrapethissite.com/");
Navigation
For navigating through websites, you will need to locate and extract hyperlinks from HTML elements on the page. To proceed to the Sandbox page, first find its link from the navigation bar using the following code:
// Find the sandbox link element from the nav links
Element sandboxNavLink = userAgent.doc.findFirst("<li id=\"nav-sandbox\">");
// Extract the sandbox page link
String sandboxLink = sandboxNavLink.findAttributeValues("<a href>").get(0);
Now that you have the link for the Sandbox page, you can navigate to it using the visit() method:
userAgent.visit(sandboxLink);
The user agent is now on the Sandbox page.
On this page, you will need to locate the Hockey Teams: Forms, Searching and Pagination link. Instead of using the text to search for it—which might change if a website updates its content—you should use the internal HTML structure to locate it.
If you inspect the page, you will find that each of the links is inside <div class="page"> tags:
With that information, you now know that you first query all these divs, identify the second div (since the hockey teams link is second in the list), and then make use of the findAttributeValues method to extract the anchor link. Here's the code to do that and navigate to the extracted link:
// List all links on the sandbox page
Elements sandboxListItems = userAgent.doc.findEvery("<div class=\"page\">");
// Find the hockey teams sandbox list item from the list
Element hockeyTeamsListItem = sandboxListItems.toList().get(1);
// Extract the hockey teams sandbox link
String formsSandboxLink = hockeyTeamsListItem.findAttributeValues("<a href>").get(0);
// Navigate to the hockey teams sandbox
userAgent.visit(formsSandboxLink);
This brings your user agent to the hockey teams information page.
Handling Forms and Buttons
To search for teams that contain the word new in their name on the hockey teams page, you will need to fill out the search box and click the Search button. To do that, you will make use of the filloutField and submit methods from Jaunt:
userAgent.doc.filloutField("Search for Teams: ", "new");
userAgent.doc.submit("Search");
The submit command can also be used without any arguments if the target web page contains only one submit button. However, to avoid ambiguity, it's best to be as specific as possible by passing in the title of the button as an argument to the submit() method.
At this point, the results table should now contain only those rows that match the search criteria. The next step is to extract and save the data locally.
Extracting Data from the Table
To extract the data from the table, you will define a new static method in the DynamicScraper class so that you can reuse it to extract data from multiple search queries easily. Here's what the method will look like:
public static void extractTableData(UserAgent userAgent, String fileName) {
try {
// Find the results table
Element results = userAgent.doc.findFirst("<table>");
// Create a FileWriter to write the data into a CSV file
FileWriter csvWriter = new FileWriter(fileName);
// Get the table headers
Elements headers = results.findEvery("<th>");
for (Element header: headers) {
csvWriter.append(header.innerHTML().trim().replaceAll(",", ""));
csvWriter.append(",");
}
// Add a new line after the header row
csvWriter.append("\n");
// Get the table rows
Elements rows = results.findEvery("<tr class=\"team\">");
// Iterate over the rows
for (Element row : rows) {
// Get the table cells within each row
Elements cells = row.findEvery("<td>");
// Iterate over the cells and write their text content to the CSV file
for (Element cell : cells) {
csvWriter.append(cell.innerHTML().trim().replaceAll(",", "")); // Remove commas from cell content
csvWriter.append(",");
}
// Add a new line after each row
csvWriter.append("\n");
}
csvWriter.flush();
csvWriter.close();
} catch (Exception e) {
e.printStackTrace();
}
}
Inside a try-catch block, this method does the following:
- Find the
<table>tag. - Create a new
FileWriterobject to write data into local CSV files. - Write the header row into the CSV file by extracting the header information from
<th>tags. - Write the data rows into the CSV files by iterating over all
<tr>tags. - Close the file writer object once done.
Returning to the try-catch block inside your main() function, you can now use the following command to extract the table data and store it in a CSV file using the method you just defined:
extractTableData(userAgent, "first-page.csv");
Handling Pagination
The Jaunt library can automatically discover pagination on a web page and provide a simple method to navigate across the pages using the userAgent.doc.nextPageLink() method. However, it works best for simple pages like Google search results pages or database-type UIs. You can use the userAgent.doc.nextPageLinkExists() method to check if Jaunt was able to figure out the next page link for a target website.
In the case of Scrape This Site, Jaunt is not able to figure out the pagination buttons at the bottom of the table. Hence, you need to revert to the traditional strategy of locating and clicking on the pagination links manually. Here's the code for that:
// Find the pagination element in the page
Element paginationLinks = userAgent.doc.findFirst("<ul class=\"pagination\">");
// Find the links for pagination
Elements pageLinks = paginationLinks.findEvery("<li>");
// Extract the element which has the link to the 2nd page
Element nextPage = pageLinks.toList().get(1);
// Extract the link from the element
String nextPageLink = nextPage.findAttributeValues("<a href>").get(0);
// Navigate to the next page
userAgent.visit(nextPageLink);
Now that your user agent is on the second page of the results, you can run the extractTableData method once again to extract data from this page:
extractTableData(userAgent, "second-page.csv");
Here's what the DynamicScraper.java file will look like at this point:
import com.jaunt.Element;
import com.jaunt.Elements;
import com.jaunt.JauntException;
import com.jaunt.UserAgent;
import java.io.FileWriter;
import java.io.IOException;
public class DynamicScraper {
public static void main(String[] args) {
try {
// Create a UserAgent instance
UserAgent userAgent = new UserAgent();
// Go to the main page
userAgent.visit("https://www.scrapethissite.com/");
// Find the sandbox link element from the nav links
Element sandboxNavLink = userAgent.doc.findFirst("<li id=\"nav-sandbox\">");
// Extract the sandbox page link
String sandboxLink = sandboxNavLink.findAttributeValues("<a href>").get(0);
// Navigate to the sandbox link
userAgent.visit(sandboxLink);
// List all links on the sandbox page
Elements sandboxListItems = userAgent.doc.findEvery("<div class=\"page\">");
// Find the hockey teams sandbox list item from the list
Element hockeyTeamsListItem = sandboxListItems.toList().get(1);
// Extract the hockey teams sandbox link
String formsSandboxLink = hockeyTeamsListItem.findAttributeValues("<a href>").get(0);
// Navigate to the hockey teams sandbox
userAgent.visit(formsSandboxLink);
// Fill out the search form to find all teams starting with "new"
userAgent.doc.filloutField("Search for Teams: ", "new");
userAgent.doc.submit("Search");
// Extract results table data
extractTableData(userAgent, "first-page.csv");
// Find the pagination element in the page
Element paginationLinks = userAgent.doc.findFirst("<ul class=\"pagination\">");
// Find the links for pagination
Elements pageLinks = paginationLinks.findEvery("<li>");
// Extract the element which has the link to the 2nd page
Element nextPage = pageLinks.toList().get(1);
// Extract the link from the element
String nextPageLink = nextPage.findAttributeValues("<a href>").get(0);
// Navigate to the next page
userAgent.visit(nextPageLink);
// Extract the table data once again
extractTableData(userAgent, "second-page.csv");
} catch (JauntException e) {
e.printStackTrace();
}
}
// Helper method to extract table data and store it in a CSV file
public static void extractTableData(UserAgent userAgent, String fileName) {
try {
// Find the results table
Element results = userAgent.doc.findFirst("<table>");
// Create a FileWriter to write the data into a CSV file
FileWriter csvWriter = new FileWriter(fileName);
// Get the table headers
Elements headers = results.findEvery("<th>");
for (Element header: headers) {
csvWriter.append(header.innerHTML().trim().replaceAll(",", ""));
csvWriter.append(",");
}
// Add a new line after the header row
csvWriter.append("\n");
// Get the table rows
Elements rows = results.findEvery("<tr class=\"team\">");
// Iterate over the rows
for (Element row : rows) {
// Get the table cells within each row
Elements cells = row.findEvery("<td>");
// Iterate over the cells and write their text content to the CSV file
for (Element cell : cells) {
csvWriter.append(cell.innerHTML().trim().replaceAll(",", "")); // Remove commas from cell content
csvWriter.append(",");
}
// Add a new line after each row
csvWriter.append("\n");
}
csvWriter.flush();
csvWriter.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
Try running the program using the following command:
java -cp '.:jaunt1.6.1.jar' DynamicScraper.java
Once the program completes execution, you will find two new files in the scraper directory with the names first-page.csv and second-page.csv. These files should contain the extracted data from the search results.
Here's what a sample from the first-page.csv looks like:
Team Name,Year,Wins,Losses,OT Losses,Win %,Goals For (GF),Goals Against (GA),+ / -,
New Jersey Devils,1990,32,33,,0.4,272,264,8,
New York Islanders,1990,25,45,,0.312,223,290,-67,
New York Rangers,1990,36,31,,0.45,297,265,32,
New Jersey Devils,1991,38,31,,0.475,289,259,30,
New York Islanders,1991,34,35,,0.425,291,299,-8,
And that completes the tutorial for getting started with Jaunt in Java. You can find the complete code for the tutorial in this GitHub repository.
Conclusion
In this article, you learned how to install Jaunt Java in a local environment and use it to scrape websites. You first saw how to scrape simple static websites like Wikipedia and then learned how to use some of Jaunt's advanced features for navigation, form and button handling, table extraction, and pagination handling.
While Jaunt is a great solution for setting up a web scraper manually, you might run into issues like rate limits, geo-blocking, honeypot traps, CAPTCHAs, and other challenges related to web scraping. If you prefer not to have to deal with rate limits, proxies, user agents, and browser fingerprints, check out ScrapingBee's no-code web scraping API. Did you know the first 1,000 calls are free?
Before you go, check out these related reads:


