chromedp is a Go library for interacting with a headless Chrome or Chromium browser.
The chromedp package provides an API that makes controlling Chrome and Chromium browsers simple and expressive, allowing you to automate interactions with websites such as navigating to pages, filling out forms, clicking elements, and extracting data. It's useful for simplifying web scraping as well as testing, performance monitoring, and developing browser extensions.
This article provides an overview of chromedp's advanced features and shows you how to use it for web scraping.

Prerequisites
To use chromedp, you must set up your Go environment and import the chromedp package. Ensure that the Chrome or Chromium browser as well as the chromedp library are installed.
Basic Scraping: Extracting Data from a Static Website
To start, let's see how you can use chromedp to extract data from a static website, like Wikipedia or a static blog.
First, you must import the necessary packages to give you access to the functions and types you'll need for web scraping. It ensures that the code has the necessary dependencies to compile and execute successfully.
Let's now explore an example that shows you how to extract data from a static website using chromedp:
import (
"context"
"fmt"
"github.com/chromedp/chromedp"
)
Here we are importing three packages:
context- used to create a context for managing the lifecycle of chromedp operations. It allows you to create and manage contexts, representing Chrome browser instances.fmt- allows us to print to the console.chromedp- gives us access to utility functions that simplify web scraping tasks, making it easier to interact with dynamic web pages, navigate websites, interact with forms, wait for specific conditions, handle cookies, capture network traffic, and perform high-level operations.
Next, you need to create a new context and Chrome instance:
ctx, cancel := chromedp.NewContext(context.Background())
defer cancel()
Creating a new context allows you to manage the lifecycle of chromedp operations and to control the behavior and settings of the Chrome browser instance used for scraping. In the code block above, the defer cancel() statement ensures that the context is properly closed and resources are released, preventing resource leaks.
Next, you'll navigate to the target website, toscrape.com:
url := "https://toscrape.com"
err := chromedp.Run(ctx, chromedp.Navigate(url))
if err != nil {
fmt.Println("Error navigating to the website:", err)
return
}
The code above uses chromedp.Navigate() to load the desired URL in the controlled Chrome browser. It is the initial step for interacting with the web page and extracting data from it.
In order not to run into errors when scraping, it's advisable to wait for the elements you want to scrape to load before proceeding with data extraction. You can use the chromedp.WaitVisible() chromedp property to do that, like so:
var res string;
err := chromedp.Run(ctx, chromedp.WaitVisible("body"), chromedp.TextContent(`body`, &res));
if err != nil {
fmt.Println("Error waiting for the page to load:", err)
}
fmt.Println("Website loaded successfully:", res)
You can then finally use chromedp.TextContent() to get all the available text content from within the body element found on the website and print it out.
After following the steps above, your code should look like this:
package main
import (
"context"
"fmt"
"github.com/chromedp/chromedp"
)
func main() {
ctx, cancel := chromedp.NewContext(context.Background())
defer cancel()
var res string
url := "https://toscrape.com"
err := chromedp.Run(ctx, chromedp.Navigate(url), chromedp.WaitVisible("body"), chromedp.TextContent(`body`, &res))
if err != nil {
fmt.Println("Error navigating to the website:", err)
return
}
fmt.Println("Website loaded successfully:", res)
}
Here is the output of the code:
Website loaded successfully: Web Scraping Sandbox
Books
A fictional bookstore that desperately wants to be scraped. It's a safe place for beginners learning web scraping and for developers validating their scraping technologies as well. Available at: books.toscrape.com
Details
Amount of items 1000
Pagination ✔
Items per page max 20
Requires JavaScript ✘
Quotes
A website that lists quotes from famous people. It has many endpoints showing the quotes in many different ways, each of them including new scraping challenges for you, as described below.
Endpoints
Default Microdata and pagination
Scroll infinite scrolling pagination
JavaScript JavaScript generated content
Delayed Same as JavaScript but with a delay (?delay=10000)
Tableful a table based messed-up layout
Login login with CSRF token (any user/passwd works)
ViewState an AJAX based filter form with ViewStates
Random a single random quote
Scraping a Dynamic Web Page Using chromedp
Dynamic web pages rely heavily on JavaScript for content rendering and user interactions. To scrape such pages, you need to interact with elements, trigger events, and handle changes in the page's state.
Let's explore chromedp's capabilities to scrape dynamic web pages.
Clicking Buttons
Dynamic websites often have buttons that must be clicked to load more content or execute certain actions. Thankfully, chromedp allows you to simulate button clicks programmatically.
For this example, let's say you want to interact with the official golang documentation.
Here's an example of how to click a button using chromedp:
package main
import (
"context"
"log"
"time"
"github.com/chromedp/chromedp"
)
func main() {
ctx, cancel := chromedp.NewContext(context.Background())
defer cancel()
var data string
err := chromedp.Run(ctx,
chromedp.Navigate(`https://go.dev`),
// Wait for the body element to be visible on the page.
chromedp.WaitVisible(`body`),
// Click on the `Get Started` button to navigate.
chromedp.Click(`.Hero-actions a.Primary`, chromedp.ByQuery),
// Wait for the body element to be visible on the page.
chromedp.WaitVisible(`body`),
// Retrieve the HTML content from the page by the query class (.Learn-hero).
chromedp.OuterHTML(`.Learn-hero`, &data),
)
if err != nil {
log.Fatal(err)
}
log.Printf("%s", data)
}
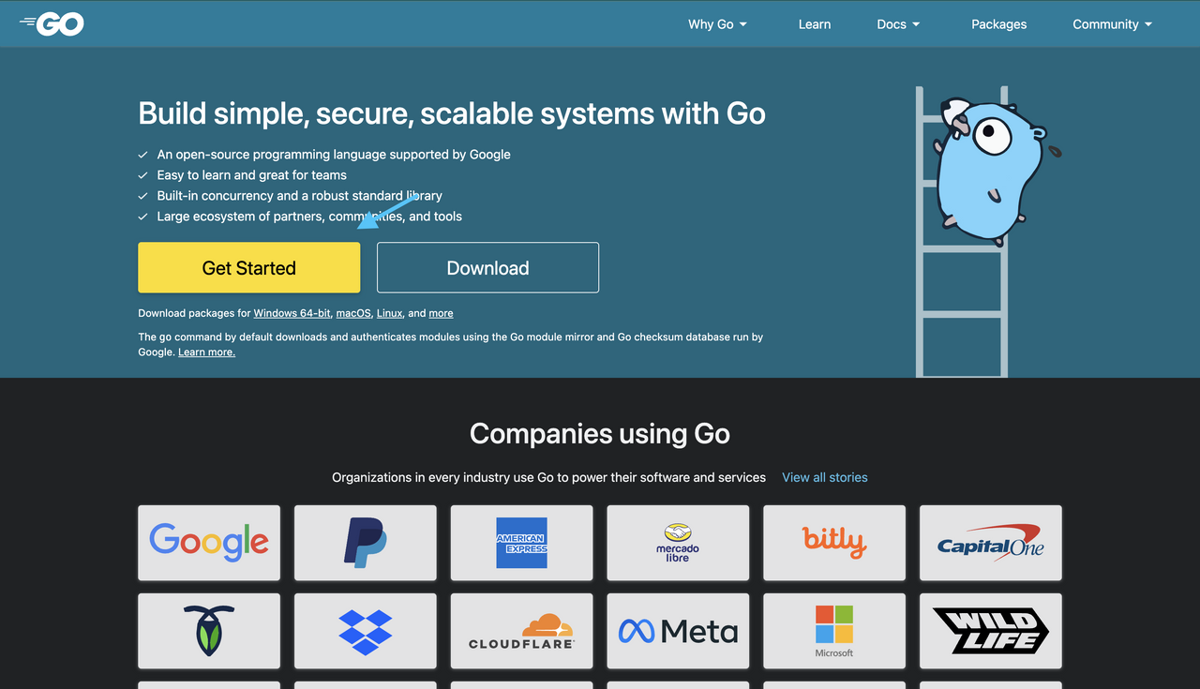
The code snippet above navigates to a web page and simulates a button click using the chromedp.Click action. This action triggers the corresponding event handler associated with the button, allowing you to load more content or perform actions. In this case, the click event allows you to navigate to https://go.dev/learn/ to view and interact with the page's content.
Notice that the snippet above uses the log statement and not fmt. They are both useful for logging and printing output, but log is safer from concurrent goroutines, and it also provides time information to printouts, which can be useful.
Here is the output:
2023/06/07 16:33:04 <section class="Learn-hero">
<div class="Container">
<div class="Learn-heroInner">
<div class="Learn-heroContent">
<ol class="SiteBreadcrumb">
<li class="BreadcrumbNav-li active">
<a class="BreadcrumbNav-link" href="/learn/">
Learn
</a>
</li>
</ol>
<h1>Install the latest version of Go</h1>
<p>
Install the latest version of Go. For instructions to download and install
the Go compilers, tools, and libraries,
<a href="/doc/install" target="_blank" rel="noopener">
view the install documentation.
</a>
</p>
<div class="Learn-heroAction">
<div data-version="" class="js-latestGoVersion">
<a class="js-downloadBtn" href="/dl" target="_blank" rel="noopener">
<span class="GoVersionSpan">Download</span>
</a>
</div>
</div>
</div>
<div class="Learn-heroGopher">
<img src="/images/gophers/motorcycle.svg" alt="Go Gopher riding a motorcycle">
</div>
</div>
</div>
</section>
Filling Out Forms
Dynamic pages also often require filling out forms to input data and interact with various features on the page. chromedp allows you to programmatically set the values of such fields.
Let's see how you can use it to fill out an HTML form on W3Schools.
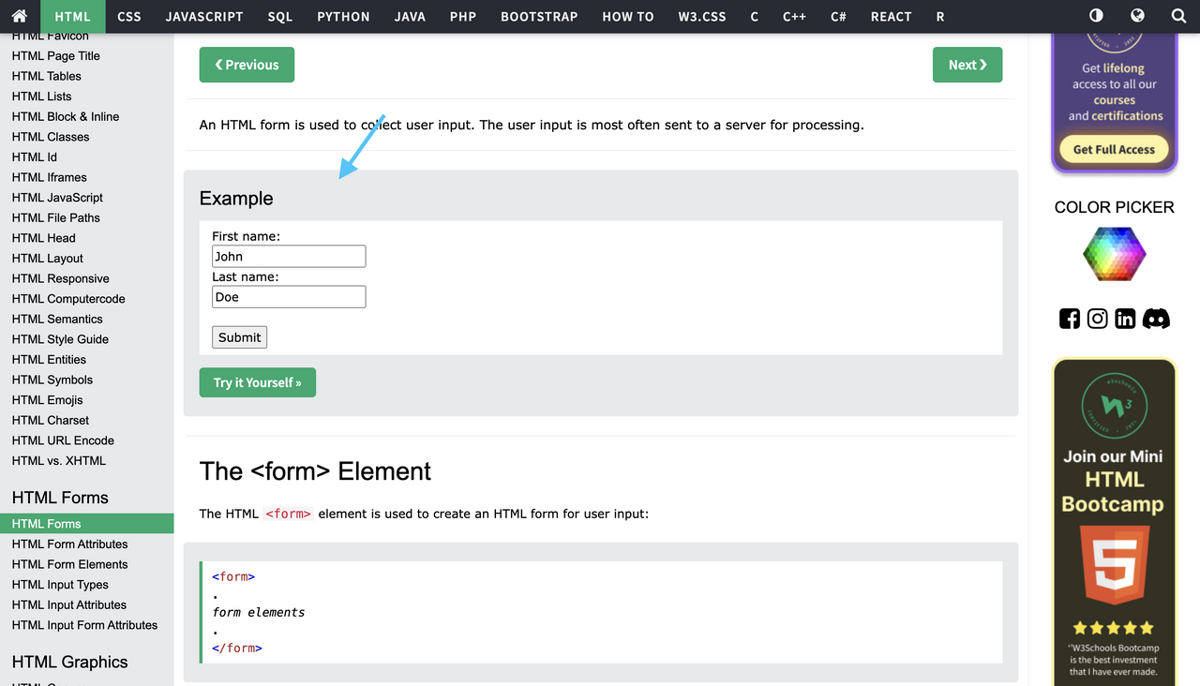
Here's an example of how you can fill and submit a form using chromedp:
package main
import (
"context"
"log"
"strings"
"github.com/chromedp/cdproto/target"
"github.com/chromedp/chromedp"
)
type Info struct {
URL string
}
func main() {
// Define options to pass into initial context.
opts := append(chromedp.DefaultExecAllocatorOptions[:],
chromedp.Flag("headless", false),
)
// Create a context with options.
initialCtx, cancel := chromedp.NewExecAllocator(context.Background(), opts...)
// Create new context off the initial context.
ctx, cancel := chromedp.NewContext(initialCtx, chromedp.WithDebugf(log.Printf))
defer cancel()
// Wait / Listen for new target (opened new tab).
ch := chromedp.WaitNewTarget(ctx, func(info *target.Info) bool {
return info.URL != ""
})
// Run task list.
var res string
err := chromedp.Run(ctx, fillForm(`https://www.w3schools.com/html/html_forms.asp`, `form:first-of-type`, res))
if err != nil {
log.Fatal(err)
}
// Run a new task list based on the new target.
newCtx, cancel := chromedp.NewContext(ctx, chromedp.WithTargetID(<-ch))
defer cancel()
var urlstr string
if err := chromedp.Run(newCtx, getSubmittedForm(urlstr, &res)); err != nil {
log.Fatal(err)
}
// Log submitted form.
log.Printf("Submitted Form: `%s`", strings.TrimSpace(res))
}
func fillForm(urlstr string, sel string, res string) chromedp.Tasks {
return chromedp.Tasks{
// Navigate to the page.
chromedp.Navigate(urlstr),
// Wait for the initial form to appear.
chromedp.WaitVisible(sel, chromedp.ByQuery),
// Fill it out form
chromedp.SetValue(sel+` #fname`, "Carl", chromedp.ByQuery),
chromedp.SetValue(sel+` #lname`, "Jones", chromedp.ByQuery),
// Submit the form
chromedp.Submit(`.w3-example form`, chromedp.ByQuery),
}
}
func getSubmittedForm(urlstr string, res *string) chromedp.Tasks {
return chromedp.Tasks{
// Wait for the submitted form to appear.
chromedp.WaitVisible(`body.w3-container`, chromedp.ByQuery),
// Get the inner html content of the submitted form.
chromedp.InnerHTML(`body.w3-container`, res, chromedp.ByQuery),
}
}
The code snippet above uses the SetValue() function to set the values of the indicated form elements. The first argument is a CSS selector for the element in question, while the second argument is the value we'd like to set. The last argument (chromedp.ByQuery) eventually tells SetValue to search by CSS selector.
Similarly, the Submit() function takes a CSS selector as well and fires a submit event for the element in question. In our example, we used our <form> element.
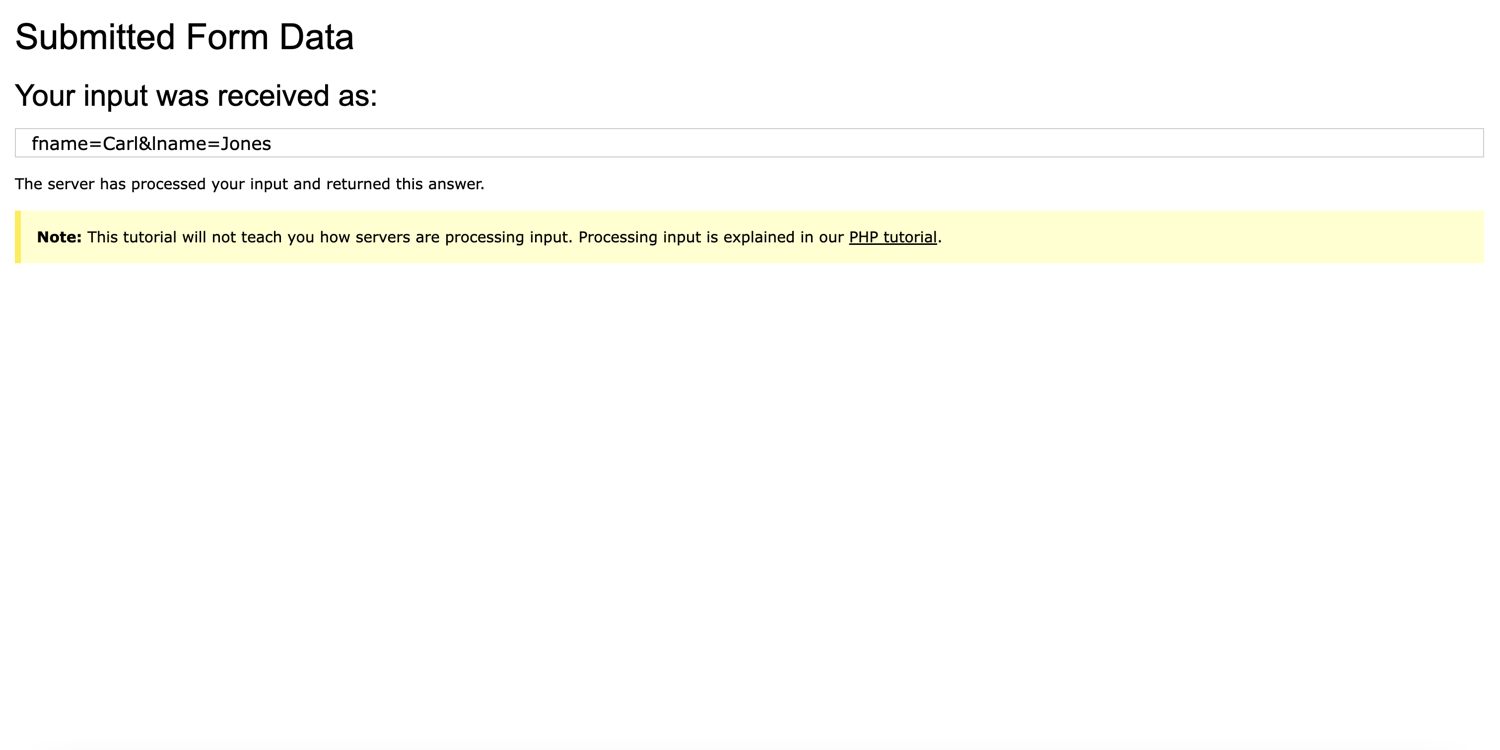
After these actions have been performed, a new tab - containing the response - is loaded and its content logged to the console. The WaitNewTarget() function found in the code snippet above is used to listen for newly opened tabs, in your case, the page with the form data you submitted from the previous page.
Here is the output:
2023/06/19 01:36:23 Submitted Form: `
<h1>Submitted Form Data</h1>
<h2>Your input was received as:</h2>
<div class="w3-container w3-large w3-border" style="word-wrap:break-word">
fname=Carl&lname=Jones </div>
<p>The server has processed your input and returned this answer.</p>
<div class="w3-panel w3-pale-yellow w3-leftbar w3-border-yellow">
<p><strong>Note:</strong> This tutorial will not teach you how servers are processing input.
Processing input is explained in our <a href="/php/default.asp" target="_blank">PHP tutorial</a>.
</p>
</div>`
Navigating Web Pages
Scraping dynamic web pages also requires you to navigate between different pages and handle redirects effectively.
Here's an example of how chromedp can help. To demonstrate, you'll click the Download button to navigate to the release page of Golang's official documentation using chromedp.Click to simulate the clicking event.
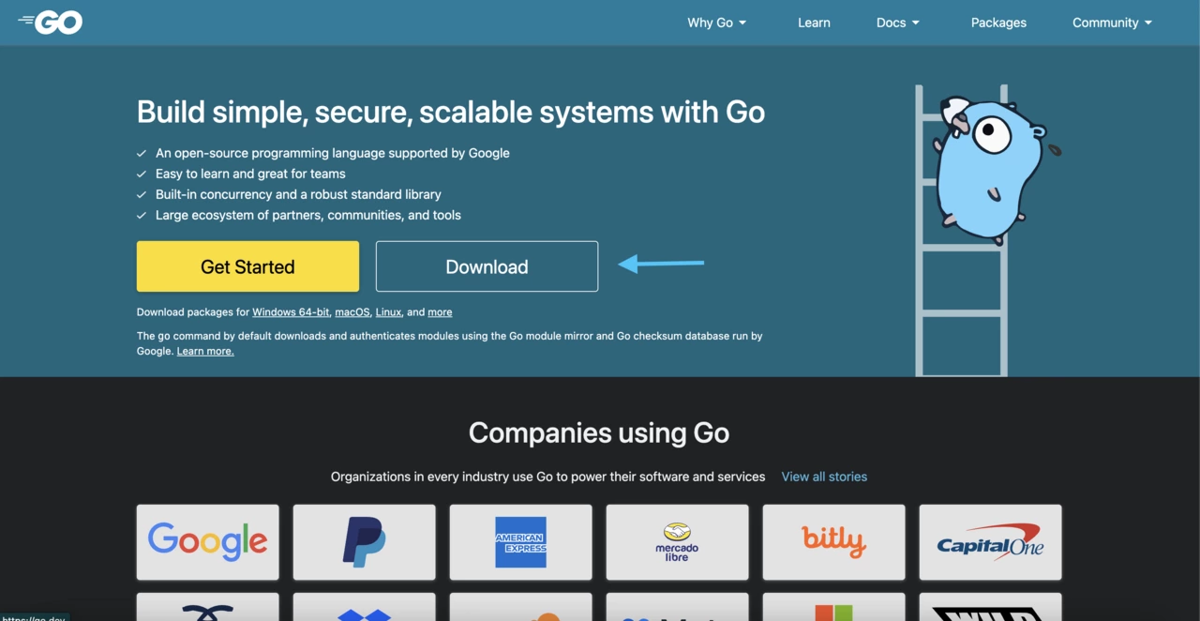
Here's an example of how you can navigate through a website using chromedp:
package main
import (
"context"
"log"
"strings"
"github.com/chromedp/chromedp"
)
func main() {
// create context
ctx, cancel := chromedp.NewContext(context.Background(), chromedp.WithDebugf(log.Printf))
defer cancel()
// run task list
var releasePage string
err := chromedp.Run(ctx, navigateToReleaseDocs(`https://go.dev`, `form:first-of-type`, &releasePage))
if err != nil {
log.Fatal(err)
}
log.Printf("Release: `%s`", strings.TrimSpace(releasePage))
}
func navigateToReleaseDocs(urlstr, sel, releasePage *string) chromedp.Tasks {
return chromedp.Tasks{
chromedp.Navigate(urlstr),
chromedp.WaitVisible(sel, chromedp.ByQuery),
// click on the `Download` button to navigate.
chromedp.Click(`.Hero-actions a.Secondary`, chromedp.ByQuery),
// wait for the body element to be visible on the page.
chromedp.WaitVisible(`body`),
// retrieve the release documentation data.
chromedp.OuterHTML(`.Downloads`, releasePage, chromedp.ByQuery),
}
}
The code snippet above lets you navigate to a web page and simulate clicking on a link using chromedp.Click. This action triggers the navigation to the release page of Golang's official documentation.
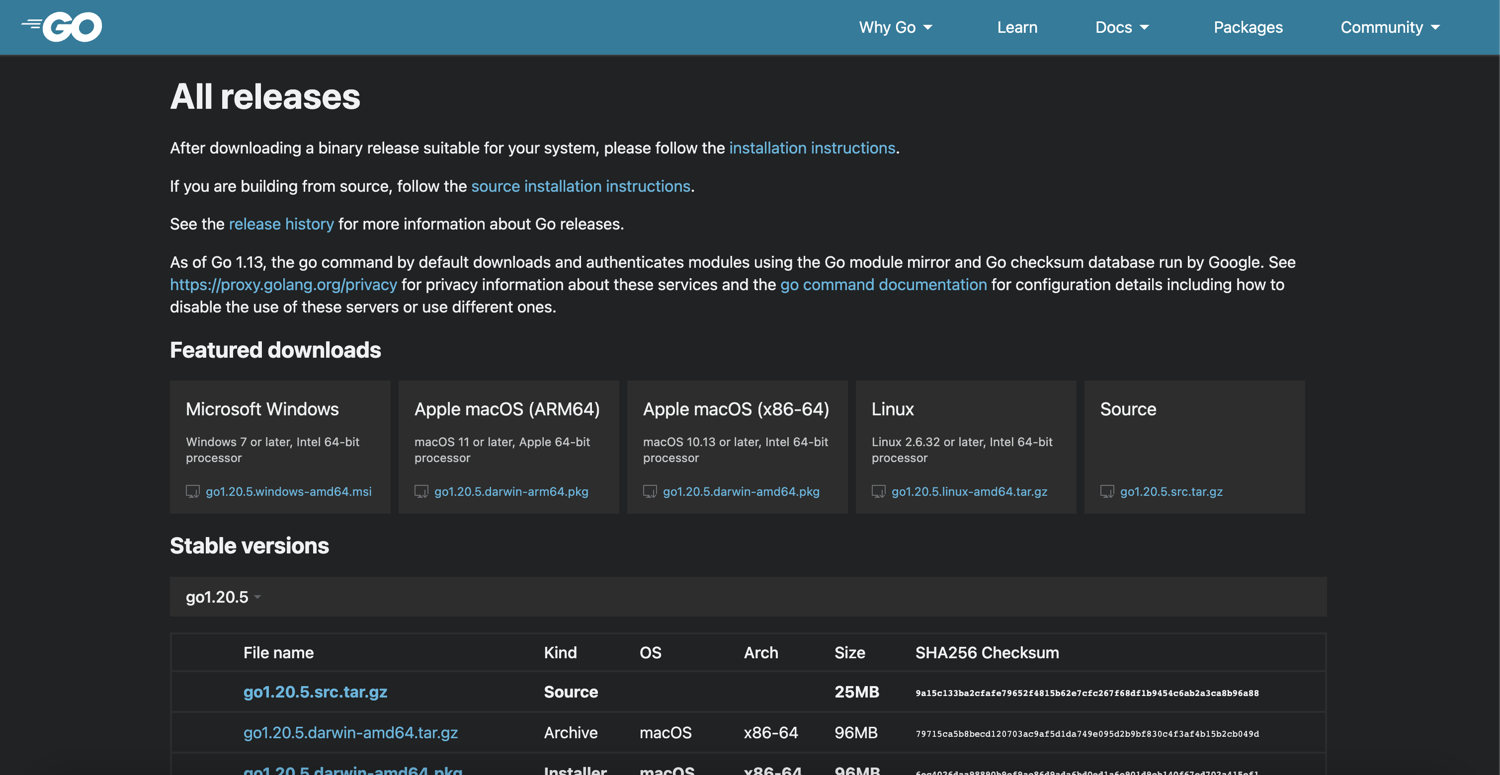
From there, you can continue extracting data or performing any further scraping tasks you require.
Conclusion
As you've seen in this article, chromedp is a powerful tool for web scraping and automating intricate browser tasks.
However, it has its drawbacks. chromedp runs a full Chrome browser instance, making it more resource-intensive than simpler HTTP-based tools. Changes in the protocol or the browser itself could also require frequent code updates. And lastly, chromedp can be slower than simpler tools due to its reliance on a full browser instance and JavaScript execution.
If you prefer not to deal with rate limits, proxies, user agents, and browser fingerprints, check out our no-code web scraping. With our API, you can focus on extracting the data you need while we handle the complexities of managing rotating proxies, headless browsers, and CAPTCHAs. Did you know the first 1,000 calls are on us?
Before you go, check out these related reads:



