Please brace yourselves, we'll be going deep into the world of Unix command lines and shells today, as we are finding out more about how to use the Bash for scraping websites.
Let's fasten our seatbelts and jump right in 🏁
Why Scraping With Bash?
If you happened to have already read a few of our other articles (e.g. web scraping in Python or using Chrome from Java), you'll be probably already familiar with the level of convenience those high-level languages provide when it comes to crawling and scraping the web. And, while there are plenty of examples of full-fledged applications written in Bash (e.g. an entire web CMS, an Intel assembler, a TLS validator, a full web server), probably few people will argue that Bash scripts are the most ideal environment for large, complex programs. So the question why somebody would suddenly use Bash, is not completely out of the blue and may be a justified question.
High-level languages typically do come with broad support and a rich ecosystem for webscraping, but there's a lot to install, maintain, and learn when it comes to the languages, their runtimes, as well as all the involved libraries. That is precisely where a Bash scraper may be able to shine, as a Unix system will (almost) always have a shell (e.g. Bash) and even the tools, we are going to discuss, will be typically pre-installed. At this point, we will only need to follow the Unix philosophy and combine the different tools with a bit of shell glue and we have a working Bash scraper.
Advantages
Particularly for more trivial scraping tasks, a quick implementation in Bash can often get you data faster than if you wrote an entire program in a high-level language or framework.
For example, if you just need to quickly extract some data from a JSON URL, you may be faster with curl and jq than if you fired up an entire headless browser in a Python runtime.
Limitations
On the other hand, should the scraping job be more demanding and include complex session management, the need for parallel execution (multi-threading), or involve JavaScript-heavy sites, then you may encounter more obstacles 🚧 with a Bash implementation than with traditional language platforms and the latter, with their dedicated scraping libraries and frameworks, might be a better choice. You typically also get better integration support for headless browsers.
Another typical limitation is database access. While most databases do provide a command line interface which allows you to interact with the database from the shell (thus, from a script as well), it may be more cumbersome, especially when you want to take SQL injections into account. Using prepared statements or escaping strings on the shell is, unfortunately, not particularly fun.
Scraping Tools For The Shell
All right, we have decided Bash is our choice of poison for scraping, however we still wouldn't want to implement everything as Bash script. Everything in this context means
- Sending HTTP requests
- Parsing strings
- Handling JSON and HTML
Luckily, we don't need to either, because Unix already comes with an exquisite selection of such tools. Let's take a closer look.
Running HTTP requests with curl
curl is the main tool most of our examples in this article will revolve around.
It's a regular command line application, which sends an HTTP request and provides you with the server's response. It's highly configurable (GETs, POSTs, PUTs, you name it) and is an immensely popular tool with native library support across many language (e.g. PHP).
HTTP on the command line without curl is (almost) unthinkable (well, we shouldn't forget wget 😇).
You can download the curl binaries from their website at https://curl.se or install it (on Linux systems) via apt-get install curl (on Debian-based systems) or yum install curl (on Red Hat-based systems).
Handling text strings with grep, sed, head, and tail
These are all standard Unix tools, which typically are already pre-installed with your Linux setup. Should they not be installed, then you can quickly do so with the respective package manager (apt, yum, etc.).
grep is a popular tool to search a set of text for a given string match. As it focuses primarily on regular expressions, it's extremely versatile in this context.
sed takes grep a step further and not only allows you to search for text, but also allows for (in-place) substitution.
Last but not least, head & tail are typically used to limit text output to the first or last N lines.
Parsing JSON with jq
There's a reason why jq compares itself to sed. Very much like sed for plain text, jq is a universal manipulation tool for JSON input.
You can use jq to filter JSON documents for certain data, extract specific fields, re-map values, and transform the overall JSON structure. If you work with JSON on the shell, jq really is your go-to tool.
To install jq, you can either download it from https://stedolan.github.io/jq/ or use (for Linux) apt-get install jq or yum install jq.
Debug JSON queries with jqp
When debugging your jq queries, you may find jqp particularly useful. jqp is a visual debugger and analyzer for jq queries and allows you to interactively evaluate your queries and their output.
It is a command line UI application (greetings from Norton Commander) and accepts any valid JSON document, either passed via file argument or from standard input.
For example, the following command downloads the list of newest postings of the "r/json" subreddit and passes it to jqp.
curl https://www.reddit.com/r/json/new.json | jqp
Once jqp has started, you have
- on top, the input field for your jq expression/query
- on the left, the original JSON document
- on the right, the output jq assembled based on your query
Let's filter for the titles of the last ten postings:
limit(10; .data.children[].data.title)

In this screenshot, you find our query on top, the original Reddit response on the left, and the ten posting titles on the right.
💡 Important, to exit jqp, simply press Ctrl + C.
We don't necessarily need to have a vim experience, do we? 😉
You can download binaries for Linux, Windows, and macOS from https://github.com/noahgorstein/jqp/releases/latest.
Handling XML and HTML with Xidel
What jq is to JSON, Xidel is to HTML and XML. It allows you to parse XML documents and extract data based on XPath expressions, as well as CSS selectors.
Xidel is available at https://github.com/benibela/xidel (with pre-compiled binaries at https://www.videlibri.de/xidel.html#downloads).
Extracting the page text with html2text
If you are not after specific elements in a web page, but rather want to extract the whole text, without the HTML tags, you may want to check out html2text.
html2text strips an HTML document of all its tags and provides you with the plain text from <body>. It's available as source code at https://github.com/grobian/html2text. Alternatively, pre-compiled binaries can be installed with apt-get install html2text or yum install html2text.
Scraping Examples
ℹ️ All our examples assume Bash to be installed under
/bin/bashand our scripts to have the executable flag set.If necessary, please adjust the shebang and make sure you set the right flag with
chmod, or alternatively run the script withbash SCRIPTFILE.
Getting the current IP address
Let's start off with an easy example.
#!/bin/bash
my_ip=$(curl https://api.ipify.org)
echo "My IP address is: $my_ip" > myip.data
Paste this code into the file myip.sh, make sure the executable flag is set (chmod +x myip.sh), and run it with ./myip.sh. You should now have - more or less instantly - a file "myip.data" with the following content and your current public IP address.
My IP address is: xxx.xxx.xxx.xxx
Beautiful, but what exactly did we do here? Well, let's check out each line individually, shall we?
#!/bin/bashis the famous Unix shebang, which tells the system which interpreter to use for the following script. In our case we provided the standard path to Bash.my_ip=$(curl ....)does two things. First,$()tells Bash to run the string under parentheses as shell command in a secondary sub-shell and return its output. Second, it assigns that output to a Bash variable calledmy_ip.- Finally,
echo "My IP ...."prints the provided text with the data from ourmy_ipvariable (variable expansion), which gets redirected with the>operator to our filemyip.data.
Scraping Reddit's JSON API
With our next example we are going to scrape the, appropriately named, subreddit #!/bin/bash for the latest 100 postings.
For starters, Reddit makes that relatively easy with their dedicated web API, however at the same time they are not too happy when we use curl's default user agent identifier and respond with a 429 (Too Many Requests) status code, even if we hadn't sent a single request before. Fortunately, we can easily "fix" that by sending a standard browser user agent identifier (e.g. Chrome's) with curl's -H parameter.
Scraping the subreddit is quite straightforward and does not require any special authentication, all we need to do is append the file extension .json to our base URL and Reddit will provide us with a JSON response. As we always want the latest postings, we are going to use https://www.reddit.com/r/bash/new/ as our base URL.
All right, time for some Bash coding. Let's assemble what we have got so far into the following script, save that to reddit.sh, change its executable flag (remember, chmod), and run it.
#!/bin/bash
BASE_URL='https://www.reddit.com/r/bash/new/.json'
USER_AGENT='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
content=$(curl -H "User-agent: $USER_AGENT" $BASE_URL)
echo $content
Once we run our script (either via ./reddit.sh or bash reddit.sh), we should get a beautiful JSON output similar to this
{
"kind": "Listing",
"data": {
"after": "t3_ewz3xu",
"before": null,
"children": [ LOTS_OF_DATA_HERE],
EVEN_MORE_DATA
}
}
What's particularly interesting for our purpose here, are the elements after and children. While children contains our data, after will be used for pagination.
As we, incidentally 😁, have the JSON document in our content variable as well, we can easily pass that to jq and extract what we want. Let's do that!
after=$(echo $content | jq -r '.data.after')
urls=$(echo $content | jq -r '.data.children[].data.url')
At this point, we have all our posting URLs in urls and even the pagination value (for a subsequent call) in after. Speaking of pagination, let's check that out next.
As we already have the overall fetch and parse logic in place, we just need to wrap it into a loop, adjust our URL with the pagination value, and make sure we have a solid exit clause (infinite loops ain't cool on the shell either). So, without further ado, here the whole script:
#!/bin/bash
BASE_URL='https://www.reddit.com/r/bash/new/.json'
USER_AGENT='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
MAX_ITERATION=5
DATA_FILE=reddit.urls
current_url=$BASE_URL
data=()
iteration=1
while :; do
content=$(curl -s -H "User-agent: $USER_AGENT" $current_url)
after=$(echo $content | jq -r .data.after)
urls=$(echo $content | jq -r '.data.children[].data.url')
for url in $urls; do data+=($url); done
if [ ${#data[@]} -gt 100 ] || [ "$after" = "null" ] || [ $iteration -ge $MAX_ITERATION ]; then
break
fi
current_url="$BASE_URL?after=$after"
((iteration+=1))
done
for url in "${data[@]}"; do
# Check if URL is already present
if grep -sc $url $DATA_FILE > /dev/null; then
continue
fi
# Append URL
echo $url >> $DATA_FILE
done
Here, we introduced the variables current_url (which we initialize with our base URL) and data (as array for our data) and wrapped our earlier curl and jq calls into a while loop. When we have our first batch of data, we add each individual URL to data and check if we have (A) more than 100 entries, (B) no more data to fetch (after is null), or (C) covered already five iterations. If neither is the case, we simply continue our loop and set current_url to the new URL with the value from after.
Once we are done with the data extraction, we just quickly run through our data array, check for duplicates, and persist all new data in our data file.
That was quite a sweet example but, to be fair, we dealt with quite some well-structured data in JSON. What about real-world scraping with "messy" HTML, you may (obviously) ask? Well, let's check that out next, with Xidel.
Scraping individual Wikipedia pages from a list of URLs
For our next example we would like to crawl the names and dates of birth of famous actors from their respective Wikipedia pages.
Let's start by creating a file with our URL sources: actors.urls
https://en.wikipedia.org/wiki/Al_Pacino
https://en.wikipedia.org/wiki/Bill_Murray
https://en.wikipedia.org/wiki/Colin_Firth
https://en.wikipedia.org/wiki/Daniel_Day-Lewis
https://en.wikipedia.org/wiki/Dustin_Hoffman
https://en.wikipedia.org/wiki/Gary_Oldman
https://en.wikipedia.org/wiki/Geoffrey_Rush
https://en.wikipedia.org/wiki/Hugh_Grant
https://en.wikipedia.org/wiki/Kevin_Spacey
https://en.wikipedia.org/wiki/Sean_Connery
Lovely, but we also need to know a bit more about the pages. For that, we take a look at their HTML structure next, which should allow us to establish the right XPath expressions for accessing the data.
Let's start with the page of the great, national icon of Scotland: Sir Sean Connery
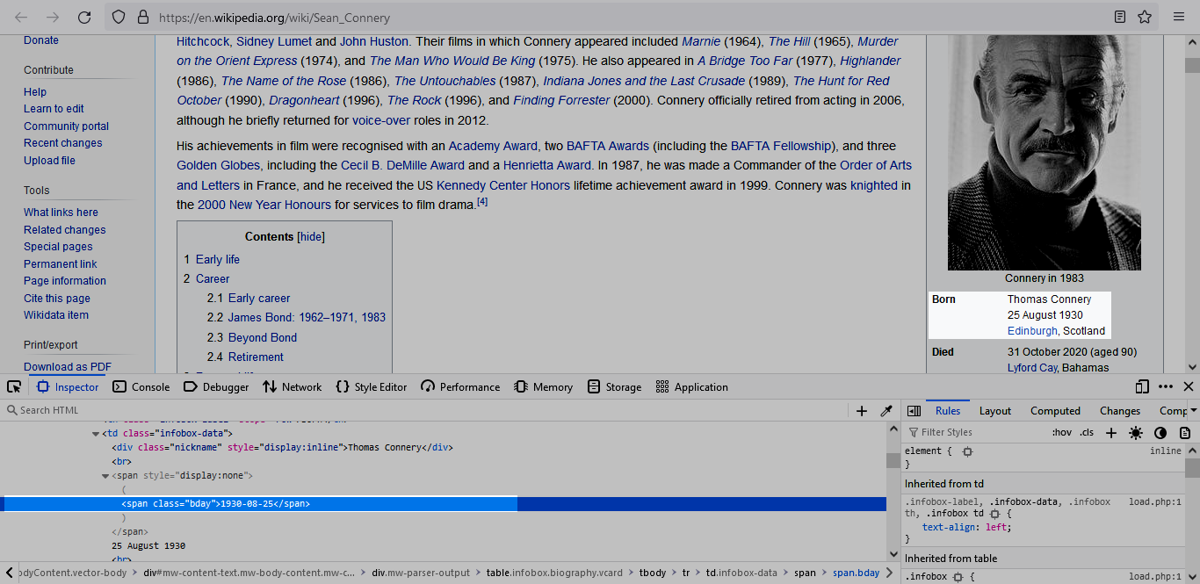
On the right side, you will notice Wikipedia's typical info box with people's data. In our case, the "Born" section is naturally of our interest. Let's right click it and select Inspect from the context menu. This should open the browser's developer tools and immediately jump to the right DOM element. In our example, that should be a <td class="infobox-data"> tag. There we should find Connery's name (did you know, he was actually named "Thomas"? 😲) and his birthday. While we could already work with that, Wikipedia actually has one more tag up its sleeve.
If we check out the DOM just a second longer, we will find a "hidden" <span> tag (display: none) with one <span class="bday"> child. Hooray, we found an element with the rather descriptive class name "bday". That should make things even easier.
Now that we have the right element, we can easily use the following XPath expression to get the birthdate already beautifully pre-set as ISO 8601 date.
//span[@class="bday"]
The actor's name, we can easily get from the pages title -> //span[@class="mw-page-title-main"].
Jolly good, with that information, we can now really start scraping. So, let's
- read our data file line-by-line
- download the page of each URL
- pass it to Xidel
- use XPath expressions to access the data
- append everything to a CSV file
All right, sounds straightforward, doesn't it? Let's check out the script code.
#!/bin/bash
IFS=$'\n'
while read -r line; do
# Load HTML content
content=$(curl -s $line)
# Extract data with XPath expressions into content array
content=($(echo $content | ./xidel - -s -e '//span[@class="mw-page-title-main"]' -e '//span[@class="bday"]'))
echo ${content[0]},${content[1]} >> actors.csv
done < actors.urls
For starters, we set our IFS variable to \n (newline) to properly split the response of our subsequent Xidel calls. In the next step, we feed the content of our input file actors.urls to a while loop, where we are going to iterate over each line. At this point, our loop should provide us on each iteration with a new URL, which we are going to download with curl and pass the response to Xidel, where we use our two XPath expressions to extract the data from the DOM tree and save it as array in content.
Last, but not least, we simply use echo with our two array values to create a CSV line and append it with >> to actors.csv.
Sounds fantastic, but a bit theoretical, right? So let's put our script to action. For that we paste it into a file scrape_actors.sh, set the executable flag, and make sure our Xidel binary is in the same directory. Now we should be able to run our scraper with ./scrape_actors.sh and after a few seconds we should have got a new file actors.csv with all the names and date of births of our actors.
That wasn't too difficult, was it? But do you know what's even easier? Not having to use an additional HTTP client nor having to set up an input file. Xidel makes both possible and that's precisely what we are going to check out in our next example.
Crawling and scraping Wikipedia with Xidel
In our previous example, we first set up an input file with all the URLs we wanted to scrape and then used curl to download each page and passed the content to Xidel. Even though curl is an extremely powerful HTTP client (and will be your first choice for many projects) you can also directly use the built-in HTTP client of Xidel. For many tasks this will work just fine and requires one fewer dependency. On top of that, Xidel also comes with a built-in web crawler, which takes a base URL and will follow child links based on certain criteria.
All of that combined, allows us to run our previous example in a much more dynamic fashion. Instead of having to pre-define URLs, we can now actually crawl Wikipedia and scrape the linked articles dynamically. Let's have a look at the code first.
#!/bin/bash
IFS=$'\n'
data=($(./xidel 'https://en.wikipedia.org/wiki/Category:Best_Actor_BAFTA_Award_winners' -s -f '//div[@class="mw-category-group"]/h3/../ul/li/a' -e '//span[@class="mw-page-title-main"]' -e '//span[@class="bday"]'))
for ((i=0; i < ${#data[@]}; i+=2));
do
echo ${data[i]},${data[i+1]} >> bafta_winners.csv
done
Once again we define our IFS variable and run the web request in a subshell, though, this time we pass our Wikipedia URL of BAFTA winners directly to Xidel. We also convert the response to an array again. In this case, we have a variable number of elements in the array, so we use a for loop to iterate over the array and append every data tuple to our CSV file. Looks pretty good, right?
Hang on a second. If we run that code we notice that our output will break after the entry for Philippe Noiret, which is easily explained by the fact that his article does not have a <span class="bday"> element. The easiest workaround here will be to simply skip articles where we don't have that element. Unfortunately, Xidel won't allow us to directly check for missing elements, so we simply let it print JSON first, then use jq to normalize the output, after which we can simply add a "null" check.
#!/bin/bash
IFS=$'\n'
url='https://en.wikipedia.org/wiki/Category:Best_Actor_BAFTA_Award_winners'
crawl_elems='//div[@class="mw-category-group"]/h3/../ul/li/a'
xpath_name='//span[@class="mw-page-title-main"]'
xpath_bday='//span[@class="bday"]'
data=($(./xidel "$url" -s -f "$crawl_elems" -e "$xpath_name" -e "$xpath_bday" --output-format=json-wrapped | jq -r .[]))
for ((i=0; i < ${#data[@]}; i+=2));
do
if [ "${data[i+1]}" = "null" ]; then continue; fi
echo ${data[i]},${data[i+1]} >> bafta_winners.csv
done
Scheduling The Scraper
Web scraping typically means to automate as much as possible and running our scraper each time manually might not be much fun. Fortunately, Linux got us covered here with cron jobs.
Simply run one of those commands (depending on your Linux distribution)
# For Debian
apt-get install crontab
# For Red-Hat
yum install vixie-cron
and you should have a working cron scheduler running in no time.
Now, all you need to do is to run crontab -e and your default editor should open, where you could add the following line:
0 * * * * /path/to/your/scraper/script.sh
With this syntax, the cron daemon will run your script at the top of every hour.
The cron syntax allows for highly flexible and custom job scheduling and you can run tasks with intervals ranging from one minute to once a year.
Cron is an extremely useful tool and also widely used outside of the scraping scope. Should you want to dive deeper into this subject, you may want to check out https://en.wikipedia.org/wiki/Cron, as that article covers the syntax very much in detail.
Summary
What we have learned in this article, is that the Bash can definitely also serve as a reasonable platform for your crawling and scraping needs. As we mentioned in the introduction, it probably will not be the one, single environment for all your data scraper projects (there probably is no such language to begin with) and does come with certain limitations, but there still are quite a few arguments in favor of Bash scripting, especially if your project does not require the handling of complex JavaScript code (i.e. with headless browsers) and you'd like to
💡 Do you want to scrape sites, which have lots of JavaScript?
Check out ScrapingBee's data extraction API and its documention. ScrapingBee supports both, traditional scraping and headless browsers, and comes with full management for request throttling, ad-blocking, premium proxies, as well as support for screenshots and API JSON responses.
There's a free trial with 1,000 API requests entirely on the house.
While we looked at data scraping with the Bash from different angles, there's still one important aspect which we haven't addressed yet, and that's how to run and configure your scraper in a way for it not to get caught up in security layers. Especially with larger sites, this can often be an issue and we have quite a nice and comprehensive article on that subject and how to avoid common pitfalls at Web Scraping without getting blocked. Definitely worth checking out 👍.
ScrapingBee's SaaS scraping platform also comes with a fully customizable set of tools, which will assist you in making sure your scraping tasks run successfully on every run.
As always, we hope you enjoyed this insight into how you can crawl the web from your Unix command line and should you have any questions or any doubts about your scraping project and how to approach it best, please don't even hesitate a second to reach out to us. We'll be delighted to answer your questions and guide you through on how to best use ScrapingBee for your scraping projects.
Before you go, check out these related reads:

Alexander is a software engineer and technical writer with a passion for everything network related.


