Amazon is most well known as an online shopping website, and among the tech folks for Amazon Web Services. However, it was initially started as an online bookstore. They are also well known for the Kindle eBook and the Audiobook experiences they offer.
The extensive offerings in the literature space have given Amazon so much data about reading patterns on a global scale. They present this data by publishing 4 charts every week. These 4 charts are the most read and the most sold books in fiction and non-fiction categories in the USA.
We obtained the books on the charts for each week, starting on May 14, 2017. For each week's charts, we could obtain the top 20 books, along with their name, author, cover, etc., and also some other data fields such as the chart position and the number of weeks the book has spent on the chart. We then aggregated the data over the 371 weeks we analyzed, for each of the 4 charts to obtain some interesting insights.
I'll discuss the insights first, after which I will cover the technical details of how the task was accomplished. If you are a non-technical reader, please feel free to skip the latter part. Before we delve into the insights, let's first look at what exactly these charts represent. The verbatim definitions of these charts from Amazon's chart pages are below:
Amazon's Most Sold charts rank books according to the number of copies sold and pre-ordered through Amazon.com, Audible.com, Amazon Books stores, and books read through digital subscription programs (once a customer has read a certain percentage – roughly the length of a free reading sample). Bulk buys are counted as a single purchase.
Amazon's Most Read charts rank titles by the average number of daily Kindle readers and Audible listeners each week. Categories not ranked on Most Read charts include dictionaries, encyclopedias, religious texts, daily devotionals, and calendars.
The Fiction Charts
I collected the data on the charts for the 371 weeks since Amazon started publishing. That is a big time span to manually look at, and I had to make some aggregate metrics to make sense of the data. One of the first and quite obvious things I calculated was which books had been on the chart for the longest period. In other words, these are the longest charting books.
Longest Charting Books
For both the most-read and the most-sold charts under fiction, I counted how many weeks each book had spent on the chart. Then I ranked the books by this metric and the top 20 books are in the tables below. Longest Charting Most Read Books:
| Book Name | Weeks |
|---|---|
| Harry Potter and the Deathly Hallows | 371 |
| Harry Potter and the Sorcerer's Stone | 371 |
| Harry Potter and the Goblet of Fire | 371 |
| Harry Potter and the Half-Blood Prince | 370 |
| Harry Potter and the Prisoner of Azkaban | 365 |
| Harry Potter and the Chamber of Secrets | 346 |
| Harry Potter and the Order of the Phoenix | 331 |
| Where the Crawdads Sing | 161 |
| A Game of Thrones | 90 |
| Dune | 88 |
| The Handmaid's Tale | 84 |
| Oathbringer | 80 |
| Lessons in Chemistry | 77 |
| Beneath a Scarlet Sky | 71 |
| Demon Copperhead | 64 |
| Project Hail Mary | 63 |
| A Court of Mist and Fury | 60 |
| American Dirt | 60 |
| Little Fires Everywhere | 59 |
| The Silent Patient | 59 |
| Ready Player One | 59 |
Longest Charting Most Sold Books:
| Book Name | Weeks |
|---|---|
| Harry Potter and the Sorcerer's Stone | 206 |
| Where the Crawdads Sing | 197 |
| It Ends with Us | 114 |
| Verity | 99 |
| The Seven Husbands of Evelyn Hugo | 97 |
| The Silent Patient | 90 |
| The Housemaid | 83 |
| Lessons in Chemistry | 80 |
| Little Fires Everywhere | 74 |
| A Court of Thorns and Roses | 74 |
| The Handmaid's Tale | 69 |
| The Midnight Library | 66 |
| Things We Never Got Over | 65 |
| Beneath a Scarlet Sky | 64 |
| Reminders of Him | 59 |
| Fourth Wing | 59 |
| Before We Were Yours | 58 |
| The Last Thing He Told Me | 58 |
| Haunting Adeline | 55 |
| It Starts with Us | 51 |
The Harry Potter series dominates the most-read charts, with the 7 books of the series taking the top 7 spots leaving the rest behind by a huge margin. The top 3 have been on this chart every week the chart was published. The book trailing the Harry Potter series has spent less than half the time on the charts compared to its predecessor.
However, we see some diversity in the most-sold charts. The top spot in the most-sold section is still held by the first book in the Harry Potter series - Harry Potter and the Sorcerer's Stone, but none of the other books from the series are in this table. One could assume that very few readers who bought the first book made it through to the end to buy the subsequent books in the series.
Another possibility is that they switched to eBooks/Audiobooks afterward. Could this mean the audience prefers eBooks/Audiobooks when it comes to lengthy series or bulkier books? Another data point that supports this hypothesis is "A Game of Thrones".
This occurs in the most-read section but not in the most-sold section. It is also worth mentioning the books that occur in both tables: "Where the Crawdads Sing", "The Handmaid's Tale", "Lessons in Chemistry", and "Beneath a Scarlet Sky".
Stint Analysis
In the previous bit, we looked at the total time the books have spent on the charts. But, this period may or may not be continuous. When we see that Dune has spent 88 weeks on the chart, it does not mean that Dune entered the chart one week, stayed there for 88 weeks, and left to never return again. It has entered and exited the charts several times. In the stint analysis section, I tried to see how books enter, stay in, and exit the charts.
Here, a stint would mean a continuous number of weeks for which a book was on the chart. Now, let's see the longest stints in most-read and most-sold fiction charts.
Longest Stints in the Most Read Charts:
| Book Name | Start Date | Weeks |
|---|---|---|
| Harry Potter and the Goblet of Fire | 2017-05-14 | 371 |
| Harry Potter and the Deathly Hallows | 2017-05-14 | 371 |
| Harry Potter and the Sorcerer's Stone | 2017-05-14 | 371 |
| Harry Potter and the Half-Blood Prince | 2017-12-03 | 342 |
| Harry Potter and the Prisoner of Azkaban | 2018-01-07 | 337 |
| Harry Potter and the Order of the Phoenix | 2017-05-14 | 331 |
| Harry Potter and the Chamber of Secrets | 2018-01-14 | 320 |
| Where the Crawdads Sing | 2018-09-23 | 112 |
| Lessons in Chemistry | 2022-08-14 | 77 |
| Demon Copperhead | 2022-11-27 | 64 |
| Project Hail Mary | 2021-05-09 | 59 |
| The Covenant of Water | 2023-05-21 | 57 |
| Fourth Wing | 2023-06-04 | 55 |
| A Court of Thorns and Roses | 2023-06-25 | 52 |
| A Court of Mist and Fury | 2023-06-25 | 52 |
| Before We Were Yours | 2017-08-06 | 50 |
| Rhythm of War | 2020-11-22 | 50 |
| A Game of Thrones | 2018-10-07 | 49 |
| Dune | 2021-07-04 | 49 |
| The Vanishing Half | 2020-06-28 | 47 |
Longest Stints in the Most Sold Charts:
| Book Name | Start Date | Weeks |
|---|---|---|
| Where the Crawdads Sing | 2018-09-09 | 116 |
| It Ends with Us | 2021-06-20 | 91 |
| Lessons in Chemistry | 2022-07-24 | 79 |
| The Seven Husbands of Evelyn Hugo | 2021-06-27 | 72 |
| Verity | 2021-12-26 | 71 |
| Reminders of Him | 2022-01-09 | 59 |
| Fourth Wing | 2023-05-07 | 59 |
| Harry Potter and the Sorcerer's Stone | 2018-05-06 | 52 |
| Iron Flame | 2023-07-23 | 48 |
| The Housemaid | 2023-01-01 | 47 |
| The Midnight Library | 2020-12-13 | 46 |
| Where the Crawdads Sing | 2022-03-20 | 43 |
| The Last Thing He Told Me | 2021-05-09 | 43 |
| It Starts with Us | 2022-07-24 | 40 |
| The Silent Patient | 2019-12-08 | 39 |
| The Silent Patient | 2019-02-10 | 38 |
| American Dirt | 2020-01-26 | 37 |
| Things We Never Got Over | 2022-01-23 | 37 |
| Haunting Adeline | 2023-03-12 | 37 |
| A Court of Thorns and Roses | 2023-10-15 | 36 |
In the most-read longest stints table, some books are from the corresponding longest charting table, while some books are newly appear on this table. These books are probably the ones that achieved momentary popularity and slowly faded away.
To look at the opposite of this effect, I looked at the books with the most number of stints, i.e., the books enter and exit the charts now and then. We could somewhat say these are the books that stand the test of time but cannot beat the longest charters and move to the top. The books with the most number of stints on both charts are below.
Most Stints in the Most Read Charts:
| Book Name | Stints |
|---|---|
| A Game of Thrones | 10 |
| Oathbringer | 9 |
| Dune | 8 |
| The Silent Patient | 6 |
| Haunting Adeline | 6 |
| The Housemaid | 6 |
| The Handmaid's Tale | 6 |
| The Way of Kings | 5 |
| Harry Potter and the Chamber of Secrets | 5 |
| It Ends with Us | 5 |
| Where the Crawdads Sing | 5 |
| When We Believed in Mermaids | 5 |
| House of Earth and Blood | 4 |
| American Dirt | 4 |
| The Last Thing He Told Me | 4 |
| The Fellowship of the Ring | 4 |
| A Court of Silver Flames | 3 |
| Never Lie | 3 |
| Where the Forest Meets the Stars | 3 |
| Thin Air | 3 |
| It | 3 |
| A Clash of Kings | 3 |
| Ready Player One | 3 |
| A Court of Thorns and Roses | 3 |
| The Storyteller's Secret | 3 |
| Fire & Blood | 3 |
| House of Sky and Breath | 3 |
| Anxious People | 3 |
| A Court of Wings and Ruin | 3 |
| Beneath a Scarlet Sky | 3 |
| Things We Never Got Over | 3 |
| The Letter | 3 |
| Harry Potter and the Prisoner of Azkaban | 3 |
| The Perfect Marriage | 3 |
Most Stints in the Most Sold Charts:
| Book Name | Stints |
|---|---|
| Harry Potter and the Sorcerer's Stone | 27 |
| If Animals Kissed Good Night | 11 |
| Beneath a Scarlet Sky | 11 |
| The Handmaid's Tale | 10 |
| The Silent Patient | 10 |
| Then She Was Gone | 10 |
| The Housemaid's Secret | 9 |
| Oh, the Places You'll Go | 8 |
| When We Believed in Mermaids | 8 |
| Eleanor Oliphant Is Completely Fine | 8 |
| Harry Potter and the Chamber of Secrets | 8 |
| Little Fires Everywhere | 7 |
| The Tattooist of Auschwitz | 7 |
| Demon Copperhead | 7 |
| Remarkably Bright Creatures | 7 |
| Project Hail Mary | 7 |
| The Housemaid | 7 |
| 1984 | 7 |
| The Hobbit | 7 |
| A Court of Thorns and Roses | 6 |
| The Hate U Give | 6 |
| Haunting Adeline | 6 |
| Dune | 6 |
| It's Not Easy Being a Bunny | 6 |
| Before We Were Yours | 6 |
| The Boy, the Mole, the Fox and the Horse | 6 |
| Where the Crawdads Sing | 6 |
| The Invisible Life of Addie LaRue | 6 |
| Mad Honey | 6 |
In these tables, apart from the books also featuring in the longest charting tables, we see some classics such as "1984" and the books that have been (or will be) adapted as movies such as "The Hobbit" and "Eleanor Oliphant is Completely Fine".
Being adapted as a movie is arguably a good measure of a fiction book's popularity though most readers swear by reading the book over watching the movie.
Animated Timelapse
To visually sum up our discussion above, let's look at animated time-lapses of the longest charting books in the two charts for the 371 weeks we analyzed. The growing bars represent the number of weeks each book has spent on the chart as time progresses.
As time progresses we see multiple books entering, staying in, and leaving the table, with some books steadily growing their bars. One observation that caught my eye was how Dune's bar entered the most-read table a few weeks after the first Dune movie was released in late 2021.
It grows for a while and then mostly stays static, and grows again after the second movie was released in early 2024.
This shows a correlation between movie releases and book readership. Having your book adapted into a movie may be good for your book after all. A literature geek with a keener eye than I have can surely make more such observations from the animation.
The Non-Fiction Charts
I performed the same set of analyses on the non-fiction most-read and most-sold charts as I did with the fiction charts. Here too, let's look at the longest charting books, and stints and finish with animated time-lapses.
Longest Charting Books
The top 20 longest charting books for most-read and most-sold non-fiction are in the tables below.
Longest Charting Most Read Books:
| Book Name | Weeks |
|---|---|
| Sapiens | 371 |
| The Subtle Art of Not Giving a F*ck | 339 |
| 12 Rules for Life | 329 |
| Can't Hurt Me | 289 |
| Atomic Habits | 287 |
| The 7 Habits of Highly Effective People | 237 |
| How to Win Friends and Influence People | 231 |
| If You Tell | 198 |
| The Daily Stoic | 177 |
| Born a Crime | 174 |
| Greenlights | 165 |
| Educated | 164 |
| The Body Keeps the Score | 155 |
| The 48 Laws of Power | 153 |
| Becoming | 146 |
| Never Split the Difference | 144 |
| The Power of Now | 123 |
| You Are a Badass | 100 |
| Unfu*k Yourself | 98 |
| A Promised Land | 95 |
Longest Charting Most Sold Books:
| Book Name | Weeks |
|---|---|
| The Subtle Art of Not Giving a F*ck | 292 |
| Atomic Habits | 282 |
| Can't Hurt Me | 224 |
| The Four Agreements | 184 |
| The Body Keeps the Score | 184 |
| 12 Rules for Life | 169 |
| Rich Dad Poor Dad | 164 |
| The 48 Laws of Power | 155 |
| How to Win Friends and Influence People | 146 |
| Educated | 120 |
| Greenlights | 120 |
| The 5 Love Languages | 116 |
| Becoming | 116 |
| Unfu*k Yourself | 101 |
| The 7 Habits of Highly Effective People | 88 |
| You Are a Badass | 79 |
| If You Tell | 76 |
| Girl, Wash Your Face | 75 |
| Sapiens | 69 |
| Killers of the Flower Moon | 69 |
| Untamed | 69 |
From the two tables, the first observation I can make is that most books occurring in the most-read table also occur in the most-sold table. Contrary to the fiction charts, the numbers are somewhat evenly decreasing rather than a single book or series taking the lead by a large margin.
Most of the books in these two tables fall in the self-help category, with notable exceptions of Sapiens, Born a Crime, and Killers of the Flower Moon. Sapiens has stayed on the most-read charts for all the 371 weeks we looked at, but only barely made it to the most-sold table.
This adds as an example to the hypothesis that I described for fiction: the bulkier books tend to appear in the most-read charts over the most-sold charts.
Stint Analysis
In this bit, let's look at which non-fiction books have spent longest continuous periods on the chart, and which books have entered and exited the charts most number of times. Firstly, the longest stints on the most-read and most-sold charts are below. Longest Stints in the Most Read Chart:
| Book Name | Start Date | Weeks |
|---|---|---|
| Sapiens | 2017-05-14 | 371 |
| Can't Hurt Me | 2018-12-09 | 289 |
| Atomic Habits | 2018-12-30 | 286 |
| The 7 Habits of Highly Effective People | 2017-05-14 | 189 |
| 12 Rules for Life | 2020-06-21 | 188 |
| The Subtle Art of Not Giving a F*ck | 2020-12-20 | 183 |
| Educated | 2018-03-04 | 162 |
| Greenlights | 2020-10-25 | 158 |
| The 48 Laws of Power | 2021-08-22 | 148 |
| How to Win Friends and Influence People | 2017-05-14 | 148 |
| The Subtle Art of Not Giving a F*ck | 2017-05-14 | 148 |
| Becoming | 2018-11-18 | 146 |
| The Body Keeps the Score | 2021-06-13 | 133 |
| The Daily Stoic | 2021-12-19 | 131 |
| Born a Crime | 2017-05-14 | 129 |
| 12 Rules for Life | 2018-01-28 | 112 |
| The Power of Habit | 2017-05-14 | 87 |
| A Promised Land | 2021-01-10 | 86 |
| Untamed | 2020-03-15 | 83 |
| If You Tell | 2019-11-03 | 79 |
| Girl, Wash Your Face | 2018-04-15 | 79 |
Longest Stints in the Most Sold Chart:
| Book Name | Start Date | Weeks |
|---|---|---|
| Atomic Habits | 2020-06-21 | 209 |
| The Body Keeps the Score | 2021-01-17 | 150 |
| The Subtle Art of Not Giving a F*ck | 2017-05-14 | 128 |
| Educated | 2018-02-25 | 119 |
| Becoming | 2018-10-14 | 96 |
| Greenlights | 2020-10-25 | 80 |
| The 48 Laws of Power | 2022-12-25 | 78 |
| Girl, Wash Your Face | 2018-04-01 | 72 |
| Outlive | 2023-03-26 | 65 |
| 12 Rules for Life | 2018-01-21 | 64 |
| Untamed | 2020-03-08 | 57 |
| Can't Hurt Me | 2018-12-02 | 52 |
| The 48 Laws of Power | 2021-12-26 | 50 |
| Rich Dad Poor Dad | 2021-12-26 | 48 |
| The Subtle Art of Not Giving a F*ck | 2021-12-12 | 46 |
| Atlas of the Heart | 2021-12-05 | 41 |
| Killers of the Flower Moon | 2023-05-21 | 40 |
| The Four Agreements | 2021-08-01 | 40 |
| Girl, Stop Apologizing | 2019-02-24 | 40 |
| The Subtle Art of Not Giving a F*ck | 2022-12-25 | 39 |
| Unfu*k Yourself | 2018-12-30 | 39 |
On these tables, we see that the pattern is very similar to longest charting tables. Could this mean non-fiction books appear on the charts, stay for however long they can, and then leave the chart almost permanently? Let's look at the most-stints tables to get an idea about this.
Most Stints in the Most Read chart:
| Book Name | Stints |
|---|---|
| The Power of Now | 21 |
| Never Split the Difference | 19 |
| Think and Grow Rich | 14 |
| If You Tell | 11 |
| Extreme Ownership | 10 |
| How to Win Friends and Influence People | 9 |
| The Daily Stoic | 8 |
| The Rise and Fall of the Third Reich | 7 |
| First 100 Words | 7 |
| Killers of the Flower Moon | 7 |
| Unfu*k Yourself | 6 |
| You Are a Badass | 6 |
| Rich Dad Poor Dad | 6 |
| Alexander Hamilton | 5 |
| 12 Rules for Life | 4 |
| Maybe You Should Talk to Someone | 4 |
| Elon Musk | 4 |
| The Mountain Is You | 4 |
| Never Finished | 4 |
| Born a Crime | 4 |
| The 48 Laws of Power | 4 |
| The Subtle Art of Not Giving a F*ck | 4 |
| I'm Glad My Mom Died | 4 |
| The 7 Habits of Highly Effective People | 4 |
Most Stints in the Most Sold Chart:
| Book Name | Stints |
|---|---|
| How to Win Friends and Influence People | 28 |
| The 5 Love Languages | 28 |
| Sapiens | 24 |
| 12 Rules for Life | 22 |
| The Subtle Art of Not Giving a F*ck | 22 |
| Can't Hurt Me | 22 |
| Rich Dad Poor Dad | 22 |
| The 7 Habits of Highly Effective People | 20 |
| The Four Agreements | 20 |
| Born a Crime | 19 |
| You Are a Badass | 14 |
| Killers of the Flower Moon | 14 |
| Never Split the Difference | 13 |
| The Psychology of Money | 13 |
| The 48 Laws of Power | 10 |
| Greenlights | 10 |
| Think and Grow Rich | 10 |
| The Mountain Is You | 10 |
| Unfu*k Yourself | 9 |
| On Tyranny | 8 |
| If You Tell | 8 |
| Atomic Habits | 8 |
We see that the patterns in the most-stints tables for non-fiction are not very different from their fiction counterparts. However, a good number of books appearing here do not appear in the longest charting or longest stints table. This suggests that non-fiction books too have their set of steady sailers that don't rise to the top but stand the test of time.
Animated Timelapse
To summarize our discussion above and see some patterns visually, let's look at animated time-lapses for the most-read and most-sold charts for non-fiction books. These are similar to the ones we saw for fiction books.
Debut Patterns
We analyzed two key parameters associated with the debut of books on these charts. One is the position at which a book debuts and the other is the time between publication and debuting on the charts. I am presenting the debut patterns for fiction and non-fiction charts together as there was not much variation among them.
Debut Position Distributions
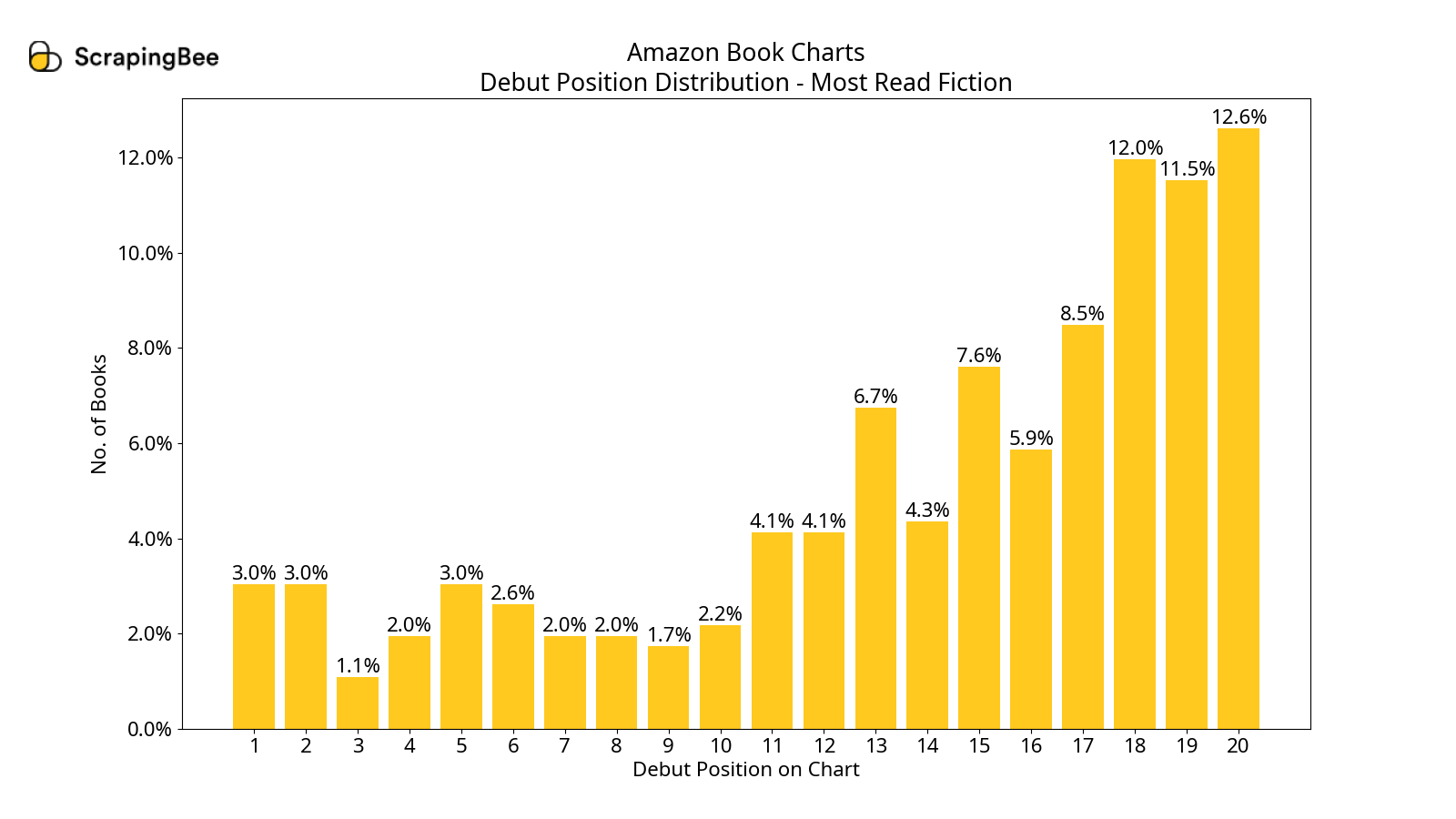
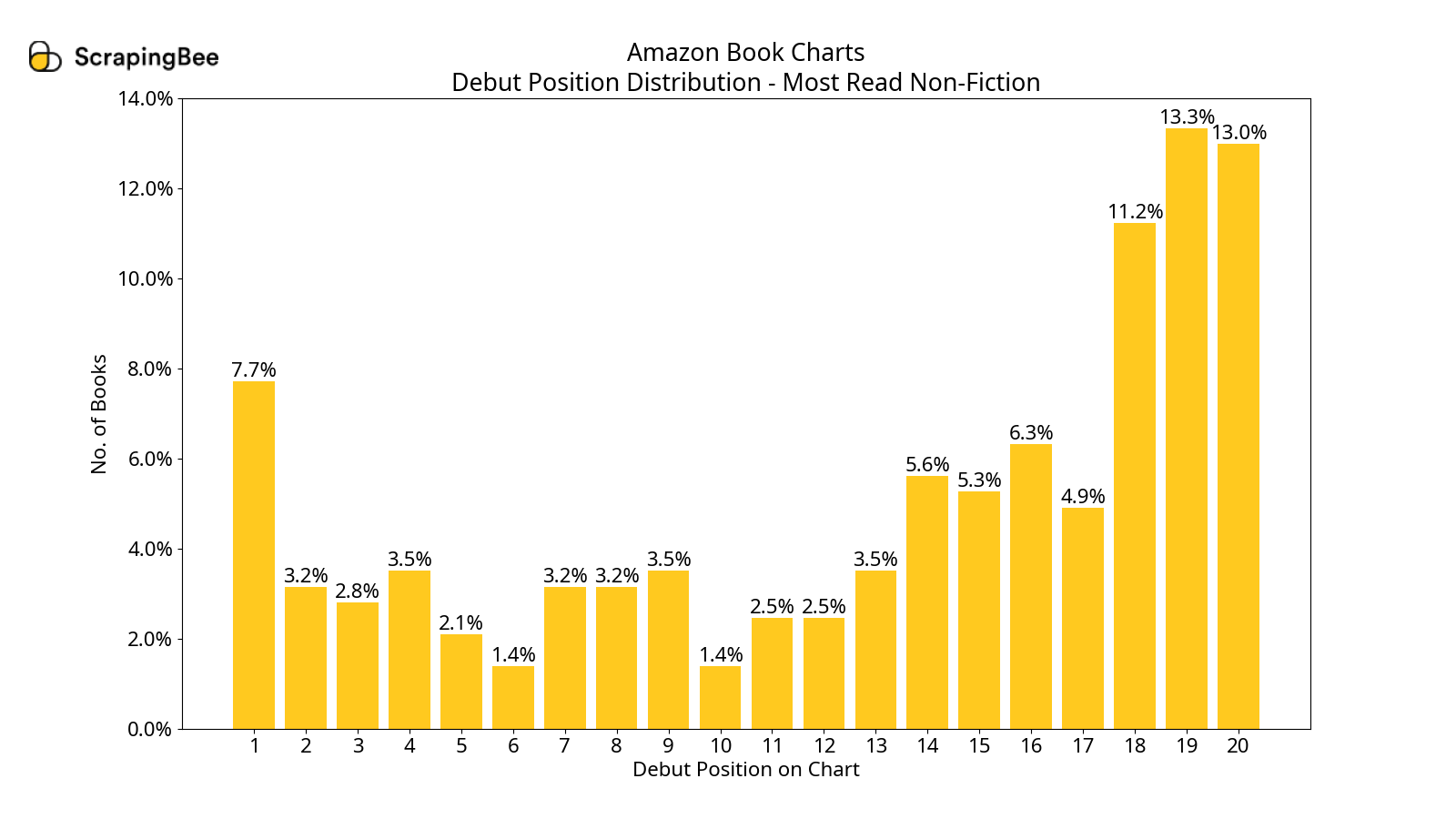
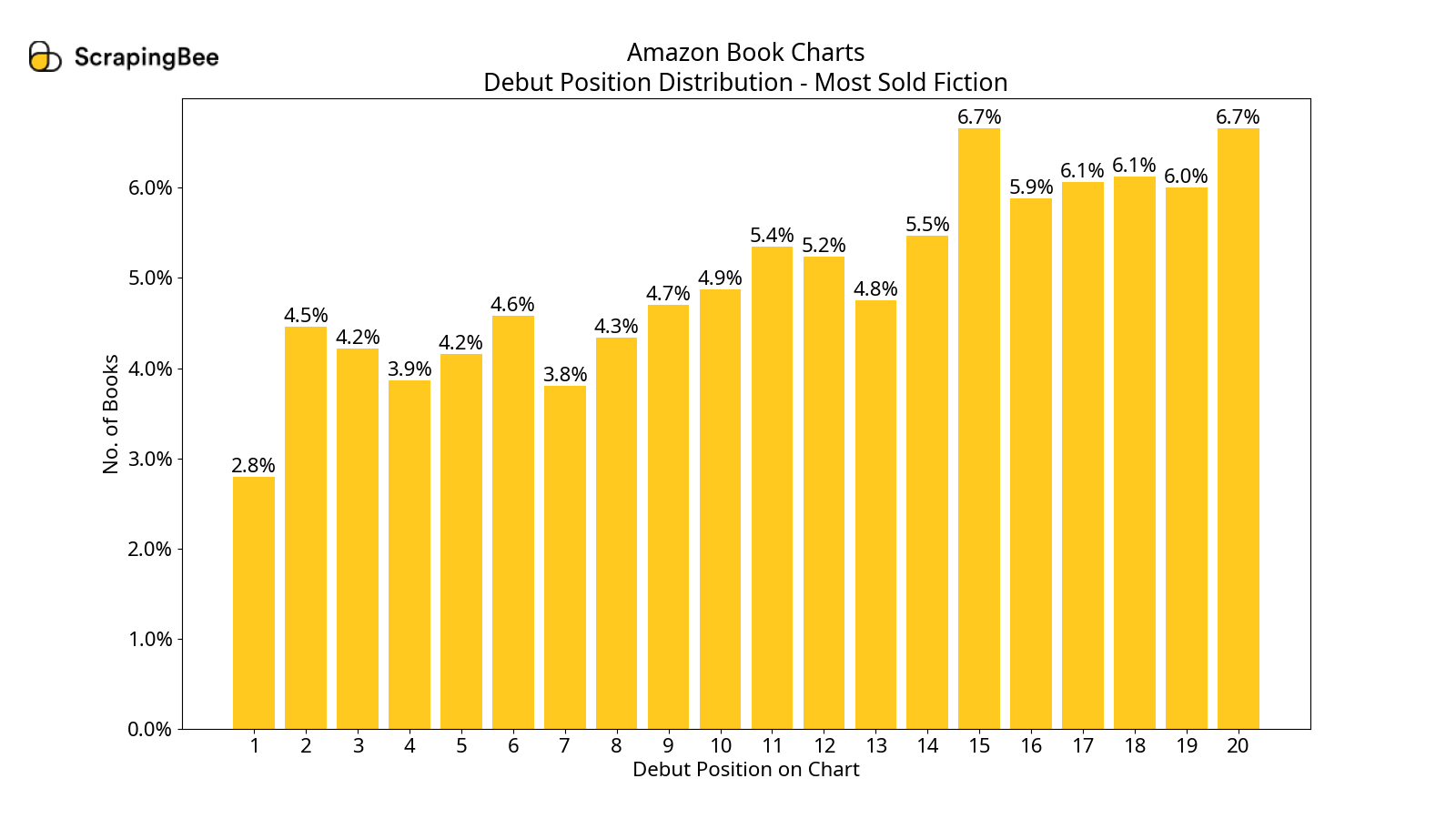
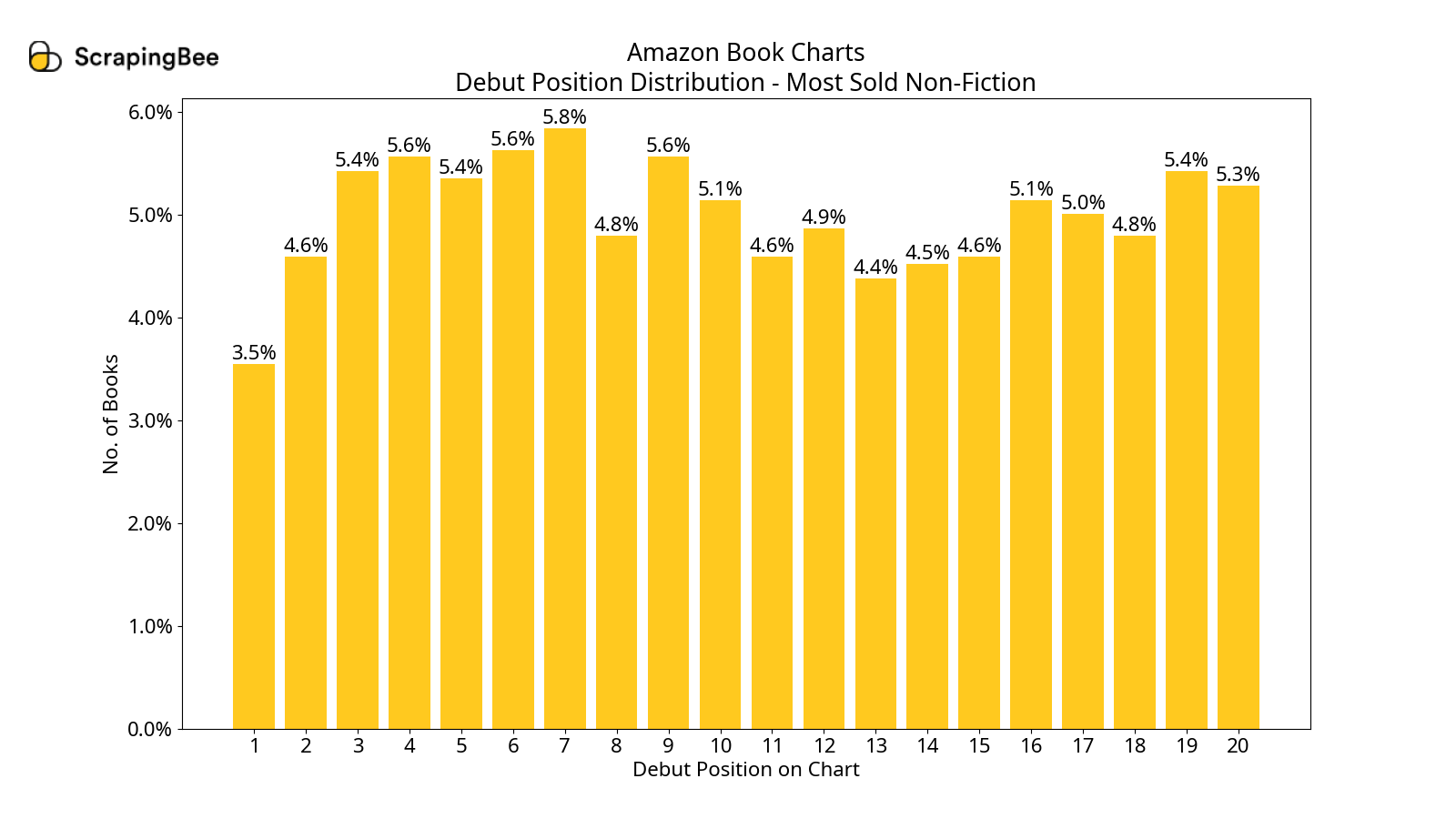
In all the charts, we see that a book is most likely to debut in the second half of the chart. However, only in the most-read charts, if a book makes it to the first half, there is a good chance it will be in the top two.
Time to Debut
I also looked at the time a book takes to debut after it has been published. Essentially, this is the difference (in weeks) between its debut date and its publication date, as seen on Amazon's product page. There were some instances of the publication date occurring after the debut date, for which we do not have a satisfactory explanation. Let's see the cumulative plot for the weeks to debut below.
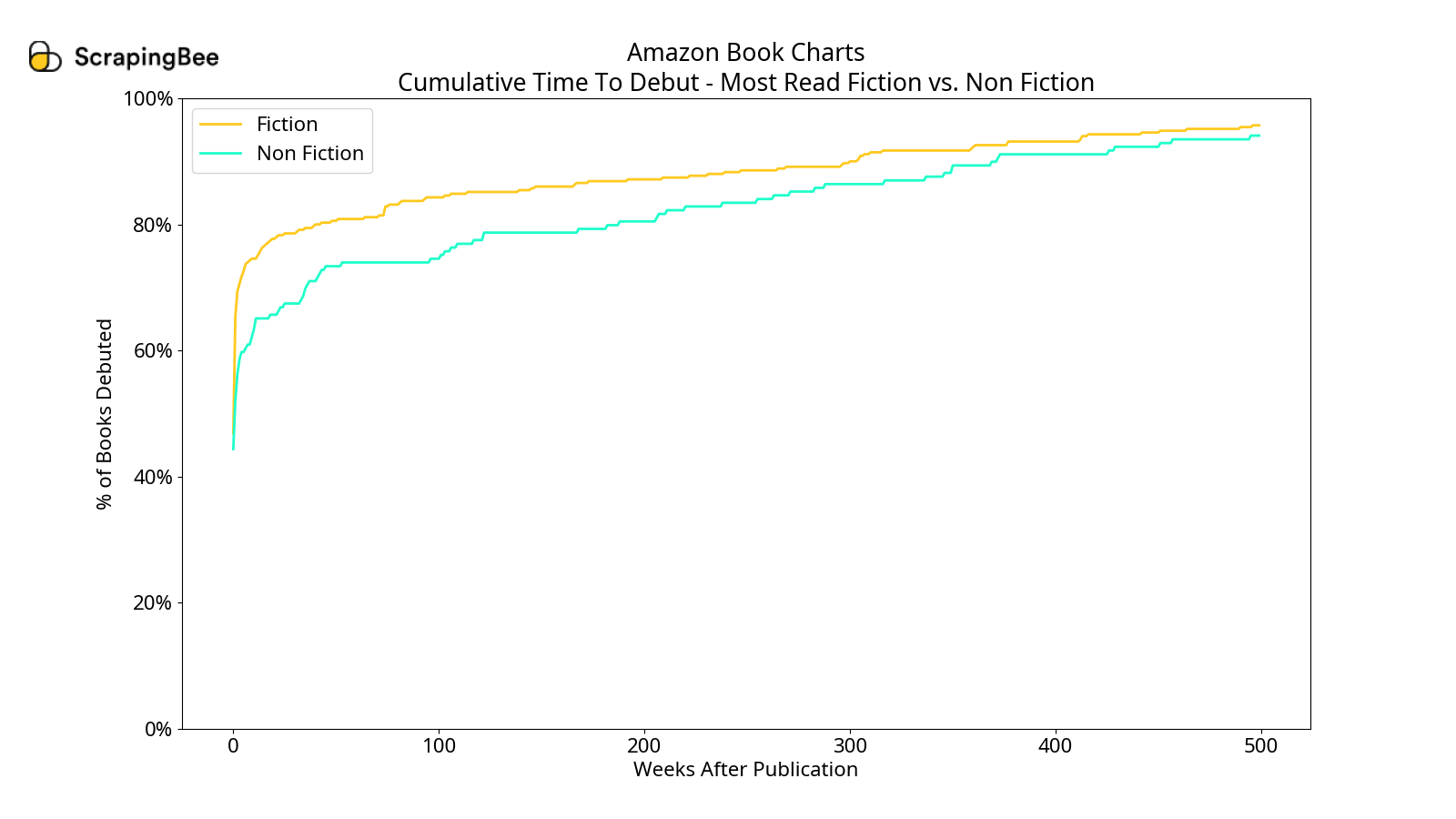
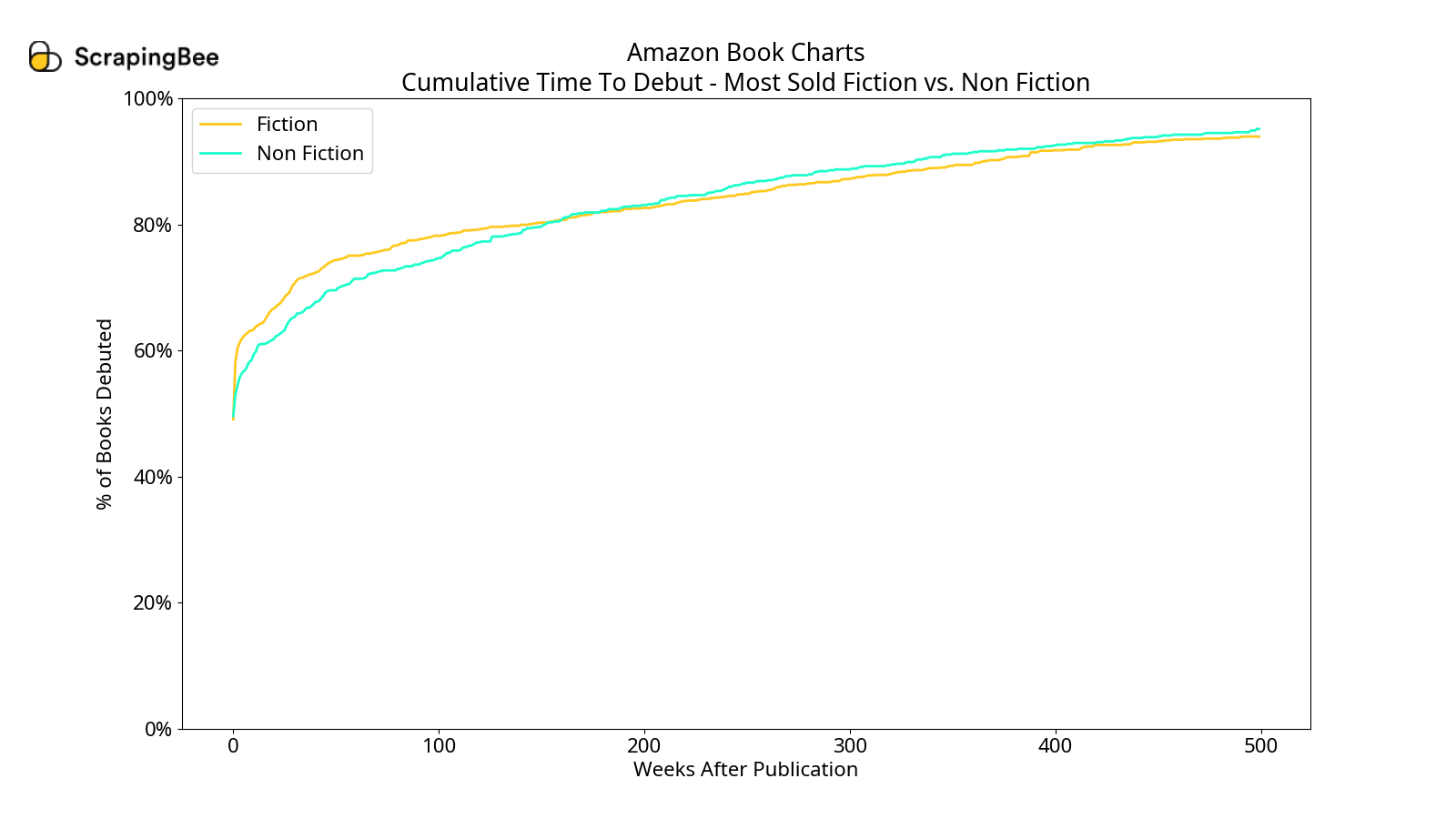
When we compare fiction with non-fiction for times to debut, we see that most fiction books tend to debut slightly quicker than non-fiction books under both most-read and most-sold. Overall, there is no significant variation in this pattern among the 4 charts. We see that around half the books that have been on these charts debut within one week of publication. Around 3/4th of the books have debuted within 3 years of publication. So, most of the 4 charts are filled with newer books.
A Pinch of Salt
Fans of the books featured on these tables and visuals have enough reasons to be excited. However, we cannot see any of this data as an absolute measure of any book's popularity. While the books featured here are surely popular, we cannot say that a book not featured here is not popular. The data from Amazon's charts can be skewed from the overall popularity by many factors.
Firstly, not everyone buys/rents all their books from Amazon. For instance, I prefer the charm of a cozy bookstore for my book buying, while using Amazon for just the obscure or new ones I cannot find in bookstores. Some titles I find in almost every bookstore, like "The Alchemist" by Paulo Coelho are barely seen on Amazon charts.
The size could also play a role; The Alchemist fits in the side pocket of my shorts while Harry Potter does not. The former is the kind of book I'd buy at a train station or a bus stop to read on the way, and probably even sell to a used bookshop at my destination. The latter is something I'd have delivered to my home to read over a few weeks.
Other factors that could skew this chart are the age of books and second-hand sales. The older books go around well in the second-hand market offline, while newer books are easier to find online.
These days, it is easier for an author/publisher to launch a book online, and take all the effort to reach offline stores only if the book performs well. This could also lead to a behavior where readers buy only first-hand books online and second-hand copies of older books offline.
Technical Steps Involved
Python was the language of choice for this analysis. Briefly, the process involved getting the data from the Amazon website, scraping the charts data, individual books data, and putting together the visuals.
Packages Used
- requests: For sending HTTP requests, receiving, and parsing responses.
- beautifulsoup4: For scraping data from HTML responses.
- dataset: For working with SQLite databases. I used SQLite databases to store the scraped data.
- scrapingbee: For scraping pages with bot detection, rate limiting, etc.
- numpy: For numerical analyses, such as frequency distributions.
- pandas: For analyzing data in tabular format.
- matplotlib: For plotting line charts, bar charts, and animated visuals.
Scraping the Charts Data
The chart URLs have the pattern: https://www.amazon.com/charts/{week_start_date}/most{read_or_sold}/{non}fiction. The week start dates range from 14th May 2017 (the earliest available date) to 16th June 2024 (the latest available when we drafted this). This is a total of 371 weeks.
In addition, the next two parts of the URLs can be mostread or mostsold and fiction or nonfiction respectively, giving us 4 charts for each week. In total, I had to scrape 1,484 chart pages (371 x 4 = 1484). Since the charts have 20 positions, I would have 29,680 chart entries in total (1484 x 20 = 29680). Let's look at the chart pages' scraping code below.
from datetime import datetime, timedelta
from bs4 import BeautifulSoup
import dataset
import requests
def _parse_weeks(text):
'''For parsing weeks in text to an integer value
'''
text = text.upper().split(" WEEK")[0]
return 1 if text=="FIRST" else int(text)
# connect to SQLite DB
db = dataset.connect("sqlite:///data.db")
# Creates a new one if data.db does not exist
# iterate over all sundays starting from 2017-05-14
date = datetime(2017, 5, 14)
end_date = datetime(2024, 6, 17)
while date<=end_date:
date_str = date.isoformat().split("T")[0]
# 4 possible chart urls for each date
chart_names = [
"mostread/fiction",
"mostread/nonfiction",
"mostsold/fiction",
"mostsold/nonfiction",
]
# get chart entries for each URL
for chart_name in chart_names:
url = f'https://www.amazon.com/charts/{date_str}/{chart_name}'
print(url)
# check if URL was scraped before
last_key = chart_name + "-" + date_str + "-20"
exists = db["chart_entries"].find_one(key=last_key)
if exists:
# if URL was already scraped, books were added
# so, skip this URL
print("SKIPPING: ALREADY PROCESSED")
continue
# if URL wasn't scraped before, go ahead
# send HTTP request to URL
r = requests.get(url)
# convert response into a Soup
soup = BeautifulSoup(r.text, features="html5lib")
# each chart entry is within a div of a particular class
# use CSS selectors to select these divs
cards = soup.select("div.kc-horizontal-rank-card")
assert len(cards)==20
for card in cards:
# run loop over each div containing a chart entry
chart_position = int(card.select_one("div.kc-rank-card-rank").text.strip())
# construct a unique key to avoid duplicate entries into db
key = chart_name + "-" + date_str + "-" + str(chart_position)
exists = db["chart_entries"].find_one(key=key)
if exists:
print("SKIPPING:", key, "- ALREADY EXISTS")
continue
# scrape necessary fields using CSS selectors
author_el = card.select_one("div.kc-rank-card-author")
chart_entry = dict(
key=key,
chart_name=chart_name,
date=date_str,
chart_position=chart_position,
book_name=card.select_one("div.kc-rank-card-title").text.strip(),
author_name=author_el.get("title") if author_el else "N/A",
# use previously defined function to get weeks as int
weeks_on_chart=_parse_weeks(card.select_one("div.kc-wol,div.kc-wol-first").text),
link=card.select_one("a.kc-cover-link").get("href"),
cover_image=card.select_one("a.kc-cover-link img").get("src"),
)
# make sure no fields are blank
for dict_key in chart_entry:
assert chart_entry[dict_key]
# add the chart entry to db
db["chart_entries"].insert(chart_entry)
# repeat for subsequent sunday
date = date + timedelta(days=7)
The above code is written in such a way that if it crashes for some reason, it can be restarted right where it was interrupted. Or, if we want to refresh our analysis after a few weeks, we can get data for just the newer weeks. If the scraper starts from scratch, we would have duplicate entries in the database from multiple runs. Once this was done, I ensured there were exactly 29,680 chart entries in the database.
Scraping Book Metadata
While the chart pages had the title, cover image, and URL for each book, I had to scrape the book's product page to obtain additional data about the book such as publication date, number of pages, category, etc.
Though there were 29680 chart entries, I did not have to scrape that many product pages, as most books repeat on the chart. The simplest algorithm was to iterate over the chart entries and scrape a product page only if it hadn't been scraped before.
This approach yielded 3,497 unique books on the chart.
Since Amazon is more rigorous with blocking automated access to the product pages, I used ScrapingBee API to overcome this limitation. Let's look at the code below.
from contextlib import contextmanager
from datetime import datetime
import html
import signal
import time
import traceback
from bs4 import BeautifulSoup
import dataset
import requests
from scrapingbee import ScrapingBeeClient
# connect to SQLite DB
db = dataset.connect("sqlite:///data.db")
# initialize ScrapingBeeClient using the ScrapingBee Python Package
spb_client = ScrapingBeeClient(api_key="{{REDACTED}}")
# for parsing date strings
MONTHS = {
"january": 1, "february": 2, "march": 3, "april": 4,
"may": 5, "june": 6, "july": 7, "august": 8,
"september": 9, "october": 10, "november": 11, "december": 12,
}
def _parse_date(raw_date):
chunks = raw_date.lower().replace(",","").split(" ")
month = int(MONTHS[chunks[0]])
day = int(chunks[1])
year = int(chunks[2])
return datetime(year, month, day).isoformat().split("T")[0]
# for setting a timeout for requests
class TimeoutException(Exception): pass
@contextmanager
def _time_limit(seconds):
def signal_handler(sigint, frame):
raise TimeoutException
signal.signal(signal.SIGALRM, signal_handler)
signal.alarm(seconds)
try:
yield
finally:
signal.alarm(0)
def run():
counter = 0
for entry in db["chart_entries"]:
# each book has an unique id on Amazon, present in the URL
book_id = entry["link"].split("/")[2]
base_url = "https://amazon.com"
url = base_url + entry["link"]
# printing for monitoring
counter += 1
print(counter, entry["book_name"], url)
# check if book was already scraped
exists = db["books"].find_one(book_id=book_id)
if exists:
# skip if scraped
print("SKIPPING: ALREADY PROCESSED")
continue
# get the HTML in the page through ScrapingBee
# throws an Exception if request does not complete in 60s
with _time_limit(60):
r = spb_client.get(url, params={"timeout": "10000", "return_page_source": "true"})
# write HTML response to file, to inspect if required
with open("last.html", "w") as f:
f.write(str(r.content))
f.close()
# create dict to store scraped data
book_data = dict(
book_id=book_id,
name=entry["book_name"],
author=entry["author_name"],
url=url,
)
soup = BeautifulSoup(r.content, features="html5lib")
if "/dogsofamazon" in str(r.content):
# this is 404 page
# mark as missing and move to next book
book_data["missing"] = True
print("BOOK PAGE MISSING, SKIPPING")
# add book as missing to DB
db["books"].insert(book_data)
continue
# scrape required fields
categories = list(map(
lambda s: s.text.strip(),
soup.select("#wayfinding-breadcrumbs_feature_div a.a-link-normal"),
))
book_data["categories"] = "|".join(categories)
details = {}
# most metadata is available as key value pairs
# the format is slightly different for regular and audible links
detail_soups = soup.select("#detailBullets_feature_div ul:first-child li .a-list-item")
if len(detail_soups)>0:
for item in detail_soups:
spans = item.select("span")
key = spans[0].text.replace("\u200F", "").replace("\u200E", "").replace("\n","")
key = html.unescape(key).split(":")[0].strip()
key = key.lower().replace(" ", "_").replace("-","_")
value = html.unescape(spans[1].text).strip()
if "_date" in key:
value = _parse_date(value)
book_data["details_" + key] = value
else:
detail_soups = soup.select("#audibleProductDetails tr, #prodDetails tr")
assert len(detail_soups)>0
for item in detail_soups:
key = item.select_one("th").text.lower()
key = key.strip().replace(" ","_").replace("-","_").replace(".","_")
value = item.select_one("td").text.strip()
if "_date" in key:
value = _parse_date(value)
book_data["details_" + key] = value
# add scraped data to DB
db["books"].insert(book_data)
# indicate a successful run over all entries without errors
return "FINISHED"
for i in range(400):
# allow for 400 restarts in case of known exceptions
# if run completes without exceptions, break the loop, exit the program
try:
if run()=="FINISHED":
break
# most exceptions are below are network or Amazon related
# they are fixed by simply retrying
except AssertionError:
print("ASSERTION ERROR, RESTARTING")
time.sleep(20)
continue
except TimeoutException:
print("TIMED OUT, RESTARTING")
time.sleep(60)
continue
except requests.exceptions.ChunkedEncodingError:
print("CHUNKED ENCONDING ERROR, RESTARTING")
time.sleep(2)
continue
except Exception:
# any Exception other than the above indicates a bug in the code
# bug is to be fixed and program is to be restarted
print(traceback.format_exc())
break
In the above code, there were a lot of possible network errors that could be fixed by simply restarting the program. I had written the code in such a way that I could leave the machine aside for a while without babysitting it and restarting it manually when something went wrong.
This involved restarting the program in case of network errors, or a particular request taking too long to complete.
Once the above code was finished, the data was ready for analysis and visualization.
Basic Setup for Analysis and Visualization
There were some common datasets and packages that I used for all the visualizations. I prepared them as shown in the code below.
from datetime import datetime, timedelta
import dataset
import matplotlib.animation as animation
import matplotlib.image as image
import matplotlib.pyplot as plt
from matplotlib.ticker import PercentFormatter
import numpy as np
import pandas as pd
# formatting settings for matplotlib
plt.rcParams["font.family"] = "Noto Sans"
plt.rcParams["font.size"] = 16
# common function for adding our logo to plots
logo = image.imread("logo.png")
def _add_logo(fig):
logo_ax = fig.add_axes([0.02, 0.82, 0.13, 0.13], anchor="NE", zorder=1)
logo_ax.imshow(logo)
logo_ax.axis("off")
# connect to db
db = dataset.connect("sqlite:///data.db")
# get data for the 4 charts from DB
mostread_fiction = list(db["chart_entries"].find(chart_name="mostread/fiction"))
mostsold_fiction = list(db["chart_entries"].find(chart_name="mostsold/fiction"))
mostread_nonfiction = list(db["chart_entries"].find(chart_name="mostread/nonfiction"))
mostsold_nonfiction = list(db["chart_entries"].find(chart_name="mostsold/nonfiction"))
# read all necessary book metadata into a dict
book_metadata = {}
date_keys = ["details_publication_date", "details_audible_com_release_date", "details_release_date"]
for book in db["books"]:
book_id = book["book_id"]
book_metadata[book_id] = book
for key in date_keys:
if book[key]:
book_metadata[book_id][key] = datetime(*list(map(int, book[key].split("-"))))
With one list for each of the 4 charts, it was possible to have one function for each visualization and run the lists through it one by one. This is called the DRY (Do not Repeat Yourself) principle.
Longest Charting Table
To make the longest charting table, I iterated over all the chart entries, while keeping count of how many times each book occurs. I then used Pandas to identify the top 20 most occurring books.
def table_longest_charting(entries, filename):
books_dict = {}
for entry in entries:
book_name = entry["book_name"]
if book_name not in books_dict:
# start counter if it does not exist
books_dict[book_name] = {"weeks": 0}
# increment the counter
books_dict[book_name]["weeks"] += 1
index = [] # book names
weeks = [] # number of weeks spent on charts
for book_name in books_dict:
index.append(book_name)
weeks.append(books_dict[book_name]["weeks"])
df = pd.DataFrame({"Weeks": weeks}, index=index)
df = df.sort_values(by="Weeks", ascending=False)
# identify the value for 20th position
# filter out everything below it
# this makes sure all books tied at 20th position are included
cutoff_value = df["Weeks"].iloc[19]
df = df[df["Weeks"] >= cutoff_value]
df.to_markdown(filename, index=True)
# run above function on all 4 datasets
table_longest_charting(mostread_fiction, "longest-charting-most-read-fiction.md")
table_longest_charting(mostsold_fiction, "longest-charting-most-sold-fiction.md")
table_longest_charting(mostread_nonfiction, "longest-charting-most-read-nonfiction.md")
table_longest_charting(mostsold_nonfiction, "longest-charting-most-sold-nonfiction.md")
Stint Analysis
Stint analysis involved tracking the books as they enter, stay on and leave the chart over successive weeks. This section had two tables to be output: longest stints and most number of stints. The code for this is below.
def stints(entries, chart_name):
file_suffix = chart_name.lower().replace(" ", "-")
# to keep track of books by week
weekwise_books = {}
for entry in entries:
if entry["date"] not in weekwise_books:
weekwise_books[entry["date"]] = set()
book_name = entry["book_name"]
weekwise_books[entry["date"]].add(book_name)
# the dates to iterate over
dates = sorted(weekwise_books.keys())
# to keep track of books that entered and left
stints = []
# to keep track of books that are currently staying on the charts
open_stints = {}
last_date = "2024-05-05"
for date in dates:
week_book_names = weekwise_books[date]
# for books on the chart in this week
for book_name in week_book_names:
# check if this book entered the charts this week
# if yes, initialize stint
if book_name not in open_stints:
open_stints[book_name] = {
"book_name": book_name,
"start_date": date,
"weeks": 0,
}
# increment weeks in stint
open_stints[book_name]["weeks"] += 1
# for books that were staying on the charts
open_stint_book_names = list(open_stints.keys())
for book_name in open_stint_book_names:
# check if a book exited this week
if book_name not in week_book_names or date==last_date:
# record the stint weeks
stints.append(open_stints[book_name])
# end the stint
del open_stints[book_name]
# make a dataframe with the stints
data = {"Book Name": [], "Start Date": [], "Weeks": []}
index = []
for obj in stints:
data["Book Name"].append(obj["book_name"])
data["Start Date"].append(obj["start_date"])
data["Weeks"].append(obj["weeks"])
index.append(obj["book_name"])
df = pd.DataFrame(data, index)
df = df.sort_values(by="Weeks", ascending=False)
# write the longest stints
cutoff_value = df["Weeks"].iloc[19]
top_df = df[df["Weeks"] >= cutoff_value]
top_df.to_markdown("longest-stints-" + file_suffix + ".md", index=False)
# make a dataframe with number of stints per book
stint_count_dict = {x: index.count(x) for x in set(index)}
counts_index = list(stint_count_dict.keys())
counts_data = {"Book Name": [], "Stints": []}
for book_name in counts_index:
counts_data["Book Name"].append(book_name)
counts_data["Stints"].append(stint_count_dict[book_name])
stint_count_df = pd.DataFrame(counts_data, counts_index)
stint_count_df = stint_count_df.sort_values(by="Stints", ascending=False)
# write books with most number of stints
cutoff_value = stint_count_df["Stints"].iloc[19]
top_df = stint_count_df[stint_count_df["Stints"] >= cutoff_value]
top_df.to_markdown("most-stints-"+file_suffix+".md", index=False)
# run above function on the 4 datasets
stints(mostread_fiction, "Most Read Fiction")
stints(mostread_nonfiction, "Most Read Non Fiction")
stints(mostsold_fiction, "Most Sold Fiction")
stints(mostsold_nonfiction, "Most Sold Non Fiction")
The above code produces 8 tables in total, 2 for each dataset.
Debut Pattern Analysis
The debut pattern analysis involved a filtered list of chart entries, where a book shows up on the chart for the first time. Based on this, I performed analyses such as the position of debut and time to debut.
def debut_trends(entries):
# common for both plots
# to keep track over iterations
debuted_book_names = set()
debut_positions = []
times_to_debut = []
for entry in entries:
book_name = entry["book_name"]
book_id = entry["link"].split("/")[2]
if book_name not in debuted_book_names:
book = book_metadata[book_id]
if book["details_publication_date"]:
chart_date = datetime(*list(map(int, entry["date"].split("-"))))
diff = chart_date - book["details_publication_date"]
times_to_debut.append(int(diff.days/7))
debuted_book_names.add(book_name)
debut_positions.append(entry["chart_position"])
return debut_positions, times_to_debut
def plot_debut_position(debut_positions, chart_name):
file_suffix = chart_name.lower().replace(" ", "-")
# bin the positions
positions = list(range(1,21))
positionwise_debut_percentages = list(map(
lambda val: debut_positions.count(val)/len(debut_positions),
positions,
))
# plot bar chart
fig = plt.figure(figsize=(16, 9))
bar_plot = plt.bar(
positions, positionwise_debut_percentages,
color="#ffc91f",
)
plt.xlabel("Debut Position on Chart")
plt.ylabel("No. of Books")
plt.gca().yaxis.set_major_formatter(PercentFormatter(1))
plt.xticks(positions)
plt.bar_label(bar_plot, fmt=lambda x: f'{round(x*100, 1)}%')
plt.title(
"Amazon Book Charts\nDebut Position Distribution - " + chart_name,
)
_add_logo(fig)
plt.savefig("debut-position-distribution-" + file_suffix + ".png")
plt.clf()
def plot_times_to_debut(times_to_debut_a, times_to_debut_b, chart_name, legend):
file_suffix = chart_name.lower().replace(" ", "-").replace(".", "")
# Compute histogram values first
histogram_a, _bins = np.histogram(times_to_debut_a, bins=range(0, max(times_to_debut_a), 1))
cumulative_histogram_a = np.cumsum(histogram_a)
normalized_cumulative_histogram_a = cumulative_histogram_a/cumulative_histogram_a[-1]
histogram_b, _bins = np.histogram(times_to_debut_b, bins=range(0, max(times_to_debut_b), 1))
cumulative_histogram_b = np.cumsum(histogram_b)
normalized_cumulative_histogram_b = cumulative_histogram_b/cumulative_histogram_b[-1]
# plot computed histogram as line chart
# avoided plt.hist due to limited formatting options
fig = plt.figure(figsize=(16, 9))
plt.plot(normalized_cumulative_histogram_a[:500], color = "#ffc91f", linewidth=2)
plt.plot(normalized_cumulative_histogram_b[:500], color = "#1fffcb", linewidth=2)
plt.ylim(0,1)
plt.xlabel("Weeks After Publication")
plt.ylabel("% of Books Debuted")
plt.gca().yaxis.set_major_formatter(PercentFormatter(1))
plt.title("Amazon Book Charts\nCumulative Time To Debut - " + chart_name)
plt.legend(legend)
_add_logo(fig)
plt.savefig(f"time-to-debut-{file_suffix}.png")
plt.clf()
# Most Read Debut Trends
debut_positions_1, times_to_debut_1 = debut_trends(mostread_fiction)
debut_positions_2, times_to_debut_2 = debut_trends(mostread_nonfiction)
plot_debut_position(debut_positions_1, "Most Read Fiction")
plot_debut_position(debut_positions_2, "Most Read Non Fiction")
plot_times_to_debut(
times_to_debut_1,
times_to_debut_2,
"Most Read Fiction vs. Non Fiction",
["Fiction", "Non Fiction"],
)
# Most Sold Debut Trends
debut_positions_3, times_to_debut_3 = debut_trends(mostsold_fiction)
debut_positions_4, times_to_debut_4 = debut_trends(mostsold_nonfiction)
plot_debut_position(debut_positions_3, "Most Sold Fiction")
plot_debut_position(debut_positions_4, "Most Sold Non Fiction")
plot_times_to_debut(
times_to_debut_3,
times_to_debut_4,
"Most Sold Fiction vs. Non Fiction",
["Fiction", "Non Fiction"]
)
The above code produced 6 visuals in total.
Animated Bar Charts
I made animated bar charts to visualize the tables as weeks passed by, with bars indicating how long each book had been on the charts. For this, I used the animation capabilities of Matplotlib. The code is below.
# used one of 6 colors for each book
# color of a book is fixed through the timelapse
# helps to keep track of a book as it moves
def animated_bar_chart(entries, chart_name):
file_suffix = chart_name.lower().replace(" ", "-")
# dates to iterate over
dates = list(set([x["date"] for x in entries]))
dates.sort()
fig = plt.figure(figsize=(12, 9))
colorset = ["#ffcb1f", "#53ff1f", "#1fffcb", "#1f53ff", "#cb1fff", "#ff1f53"]
charted_books = {}
# returns a plot for a given date
def animate(i):
print(i+1, end="\r"*4)
# clear previous plot
plt.clf()
# get entries for given date
date = dates[i]
date_obj = datetime(*map(int, date.split("-")))
date_entries = list(filter(lambda entry: entry["date"]==date, entries))
date_entries.sort(key=lambda entry: entry["chart_position"])
# get book names and number of weeks on chart
for entry in date_entries:
# if its a new entrant, start counter and allot a color
if entry["book_name"] not in charted_books:
color = colorset[len(charted_books)%len(colorset)]
charted_books[entry["book_name"]] = {"color": color, "weeks": 0}
# increment counter for new entrants & previously charted books
charted_books[entry["book_name"]]["weeks"] += 1
# construct a data frame to get top 20
names = []
weeks_on_chart = []
colors = []
for book_name in charted_books:
names.append(book_name)
weeks_on_chart.append(charted_books[book_name]["weeks"])
colors.append(charted_books[book_name]["color"])
df = pd.DataFrame({"Name": names, "Weeks": weeks_on_chart, "Color": colors})
df = df.sort_values(by=["Weeks", "Name"], ascending=False).head(20)
# draw the bar plot for this frame
bar_plot = plt.barh(
df["Name"][::-1],
df["Weeks"][::-1],
color=df["Color"][::-1],
height=0.3,
)
# customize the plot
ax = plt.gca()
ax.get_xaxis().set_visible(False)
ax.spines["top"].set_visible(False)
ax.spines["right"].set_visible(False)
ax.spines["bottom"].set_visible(False)
ax.spines["left"].set_visible(False)
plt.tick_params(left=False)
plt.bar_label(bar_plot, padding=10)
date_str = date_obj.strftime("%-d %b %Y")
plt.title(
"\n".join([
f"Number of Weeks on Amazon's {chart_name} Chart",
"Date: " + date_str
]),
x=1.05, y=1.02, ha="right",
)
plt.subplots_adjust(left=0.6, top=0.87)
_add_logo(fig)
# generate plot for all dates and put it together
ani = animation.FuncAnimation(fig, animate, frames=len(dates))
# save as GIF
ani.save(f"animated-{file_suffix}.gif", writer=animation.PillowWriter(fps=3))
animated_bar_chart(mostread_fiction, "Most Read Fiction")
animated_bar_chart(mostread_nonfiction, "Most Read Non Fiction")
animated_bar_chart(mostsold_fiction, "Most Sold Fiction")
animated_bar_chart(mostsold_nonfiction, "Most Sold Non Fiction")
Conclusion
We looked at some interesting tables and visuals from the Amazon book charts over a period of 7 years. Under each of the two categories of fiction and non-fiction, we saw 2 charts for most-sold and most-read books.
We saw the longest charting books, looked at how books debut, stay on, and exit the charts, and also at animated bar charts to visually summarize everything.
Some of these patterns changed between the two categories, for example, the distribution of books in the longest charting table. However, in all the charts, we saw mostly newer books debuting. This suggests Amazon has been a great platform for debuting books in recent times.
Apart from the newer books effect, we could also see that TV and film have a huge impact on charts. The Harry Potter series, which dominates the most-read fiction charts has also done very well as a movie series.
A Game of Thrones and Dune featuring in the most stints (most-read) suggest that fans pick up these books every time a new TV show season or a new movie is released in the franchise.
To look into the older books that have stood the test of time and made it into these charts, we looked at the tables for most stints on the charts.
The book topping the Most Stints table for Most Read Non-Fiction, The Power of Now, was published way back in 2004 and has been revisited by Amazon readers multiple times since then.
Think and Grow Rich, which was first published more than 80 years ago, appears only in this table.



