Imagine searching for the perfect vacation rental, only to be overwhelmed by options. Or perhaps you're a host curious about how your Airbnb listing compares to others in your area.
Airbnb is a popular online marketplace that connects people seeking unique accommodations with hosts offering their homes. But with so many listings, finding the ideal one can be a challenge.
This article will explore the easiest way to scrape Airbnb listings using Python, BeautifulSoup, and ScrapingBee.

TL;DR: Full AirBnb Listings Scraper
In this article, we explored how to scrape Airbnb listings using BeautifulSoup and ScrapingBee’s Python SDK.
If you're looking for a quick summary, here's the Airbnb scraper we built in this guide. Remember to replace 'YOUR_API_KEY' with your ScrapingBee API key which you can retrieve here. For more details on how to use the API and its features, refer to the official ScrapingBee Documentation.
from scrapingbee import ScrapingBeeClient
from bs4 import BeautifulSoup
import json
client = ScrapingBeeClient(api_key='YOUR_API_KEY')
print("starting ... ")
response = client.get("https://www.airbnb.com/s/california--United-States/homes?checkin=2024-05-20&checkout=2024-05-27",
params = {
'country_code': 'us',
'premium_proxy': 'True',
'wait_browser': 'load',
}
)
soup = BeautifulSoup(response.content, "lxml")
results = []
listings = soup.find_all("div", class_="lxq01kf")
for listing in listings:
# Extract the title of the listing
title = listing.find("div", class_="t1jojoys").get_text(strip=True) if listing.find("div", class_="t1jojoys") else 'N/A'
# Extracting the description
description_section = listing.find("div", class_="fb4nyux")
description = description_section.get_text(strip=True) if description_section else 'N/A'
beds = 'N/A'
date_range = 'N/A'
# Find all subtitle divs for the number of beds nd date range within the listing
beds_and_dates = listing.find_all("div", {"data-testid": "listing-card-subtitle"})
for subtitle in beds_and_dates:
text = subtitle.get_text(strip=True)
# Check if the subtitle text contains information about beds
if 'bed' in text.lower():
beds = text
# Check if the subtitle text looks like a date range
elif '-' in text or '-' in text:
date_range = text
# Extracting the total price
total_price = listing.find("span", class_="_14y1gc").get_text(strip=True) if listing.find("span", class_="_14y1gc") else 'N/A'
# Extracting the rating
rating = listing.find("span", class_="r1dxllyb").get_text(strip=True) if listing.find("span", class_="r1dxllyb") else 'N/A'
# Extracting the listing URL. The URL is relative, need to prepend the base Airbnb URL.
listing_url_section = listing.find("div", class_="c14whb16")
listing_url = (
"https://www.airbnb.com" + listing_url_section.find("a")["href"] if listing_url_section else ""
)
# Create a dictionary for the current listing
listing_data = {
"Title": title,
"Description": description,
"Beds": beds,
"Total Price": total_price,
"Rating": rating,
"Date Range": date_range,
"Listing URL": listing_url
}
# Append the listing dictionary to the results list
results.append(listing_data)
# write the results to a JSON file
with open('airbnb_results.json', 'w') as f:
json.dump(results, f, indent=4, ensure_ascii=False)
print("Results saved to airbnb_results.json")
Deciding What to Scrape
Before scraping Airbnb listings, it's essential to determine what data you want to extract. For this tutorial, you'll focus on the following attributes from the Airbnb listings page:
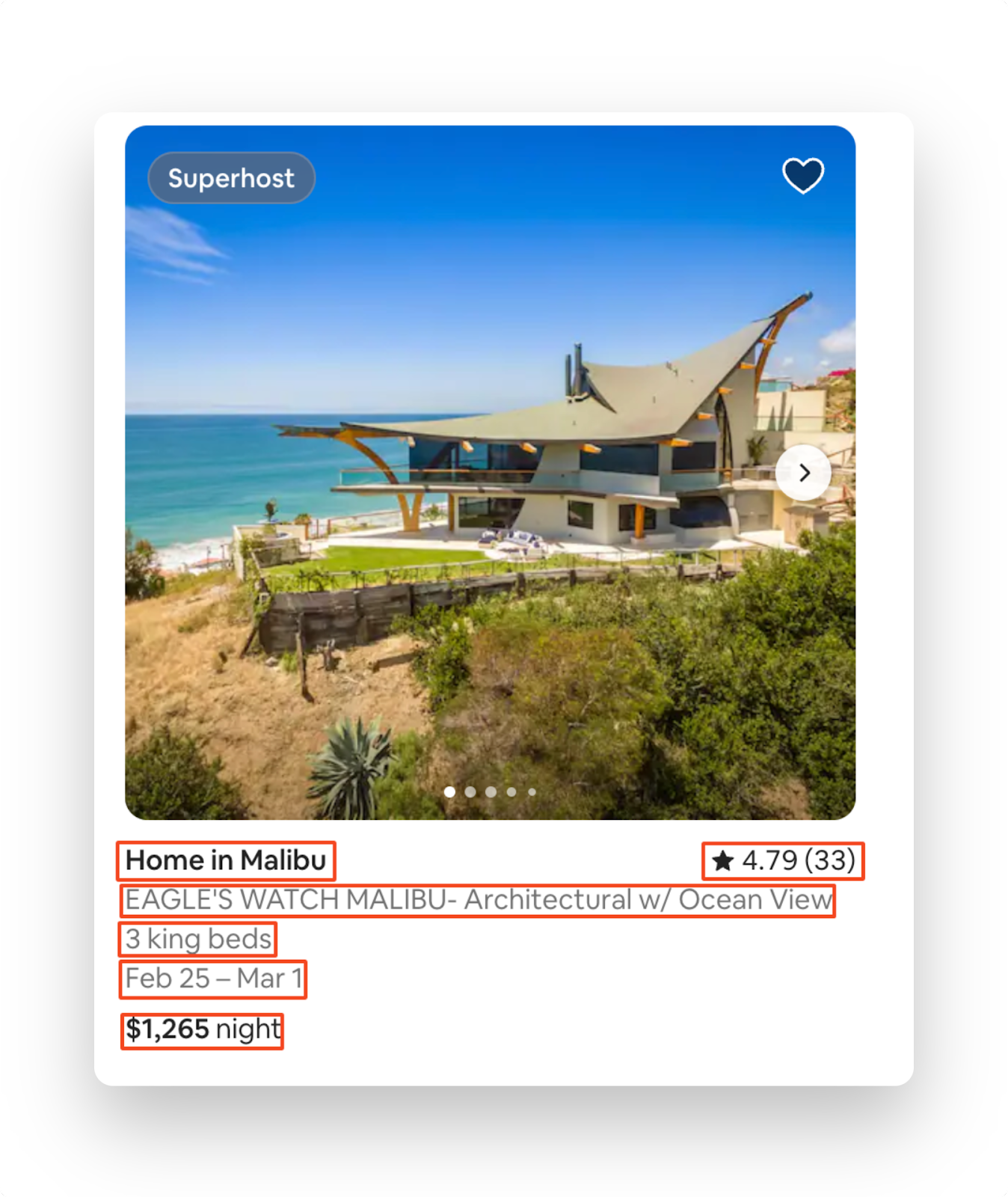
-
Title
-
Description
-
Beds
-
Rating
-
Price
-
Date Range
-
URL
To start scraping, you'll need to open the Airbnb search page for the location you're interested in. For this tutorial, we'll use California:
https://www.airbnb.com/s/california--United-States/homes
You can specify the check-in and check-out dates by appending the ‘checkin’ and ‘checkout’ parameters with your preferred dates in ‘YYYY-MM-DD’ format. For example, you could specify your query URL like this:
https://www.airbnb.com/s/california--United-States/homes?checkin=2024-05-20&checkout=2024-05-27
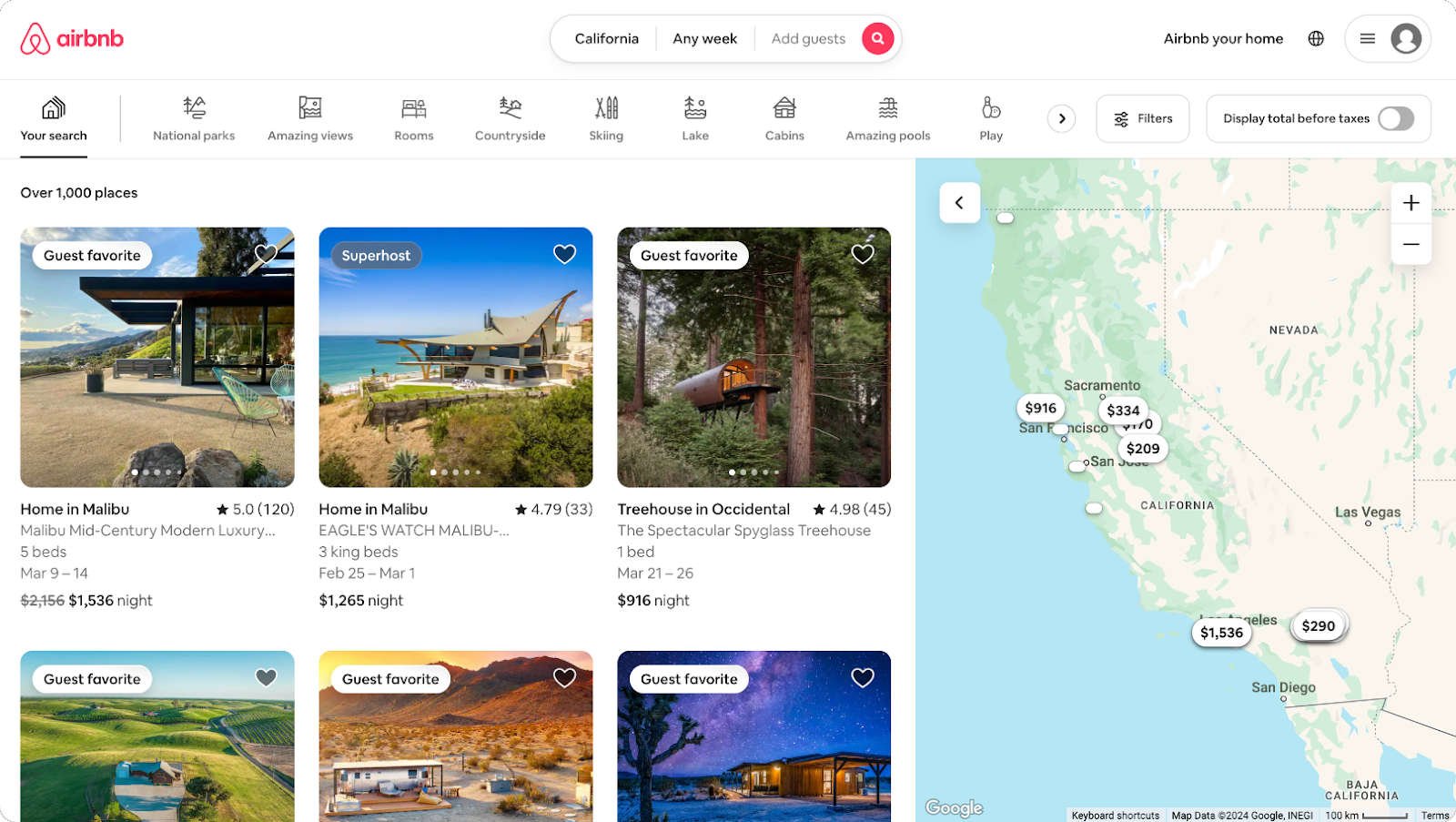
Inspect the page's source code to identify the HTML elements containing the data we want to scrape. By right-clicking on the page and selecting "Inspect," we can open the Developer Tools and inspect the source code.
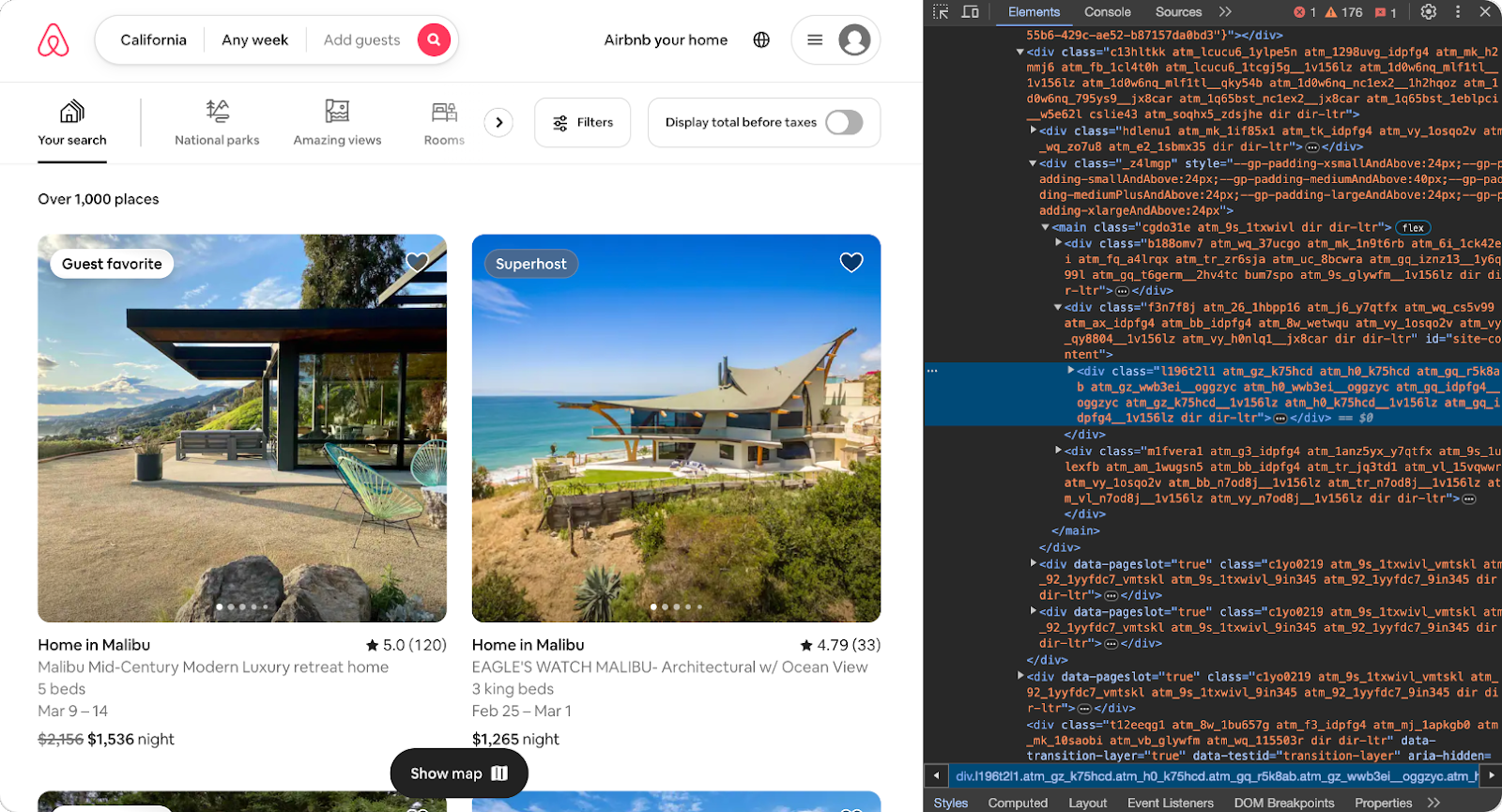
Upon inspecting the DOM, we find that the listings are contained within div elements with a common class structure. For example, the class “lxq01kf” seems to be a common element that wraps the listing details.
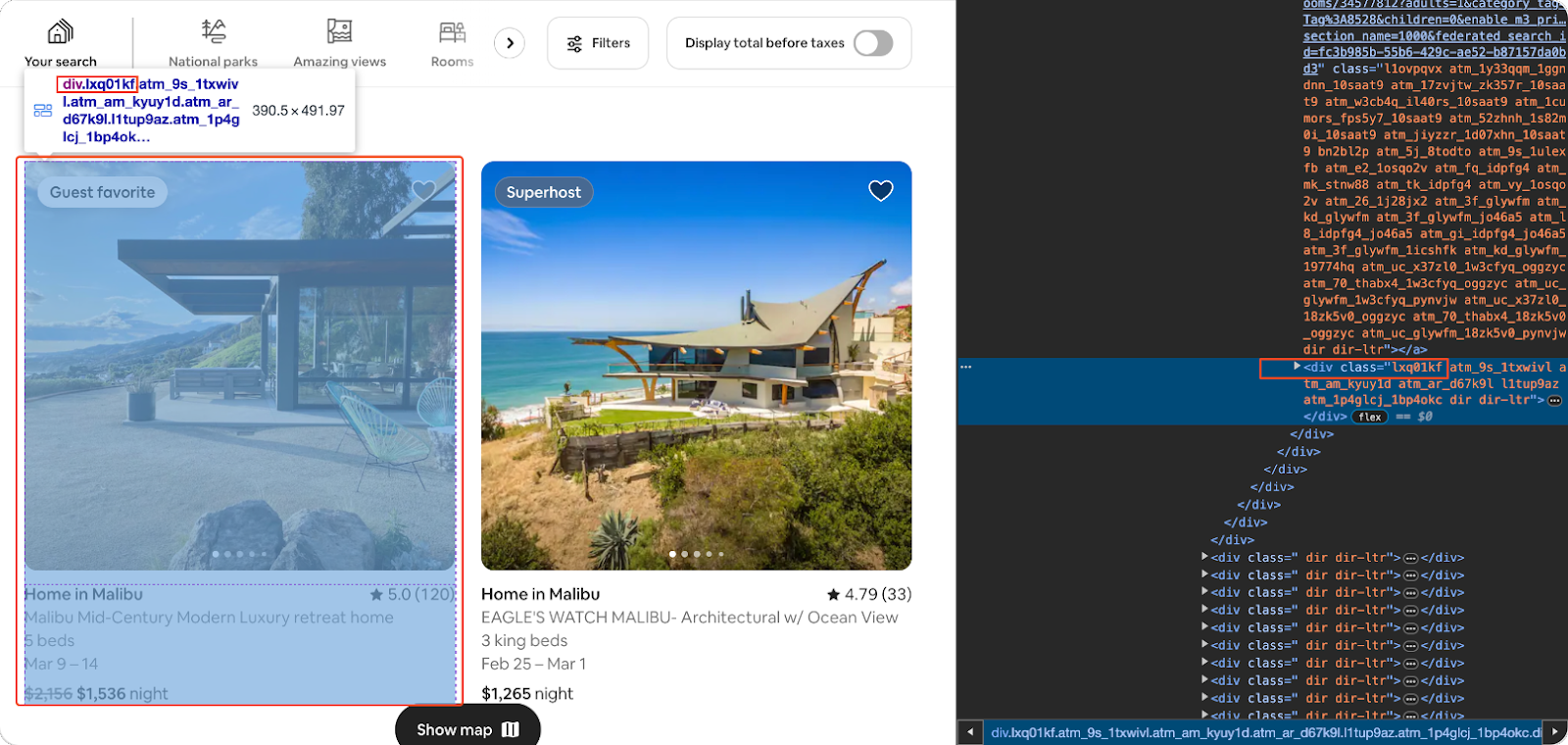
By inspecting the page and identifying the HTML elements that hold the data you want, you can create a targeted web scraping script that extracts these attributes for each listing on the page.
Note: Remember that the class names and structure of the Airbnb website may change over time, so it's important to regularly update your scraping script to ensure it continues functioning correctly.
How to Get the Data? ScrapingBee to the Rescue!
Airbnb, while a publicly available website, does not offer its listings in a straightforward format like a CSV file or an API. However, with the help of ScrapingBee, we can easily extract this data.
ScrapingBee is a service that provides tools for data extraction. It handles headless browsers, JavaScript rendering, and rotates proxies for you, ensuring you can scrape most websites without getting blocked.
ScrapingBee's API is designed to render web pages as if they were viewed in a real browser using the latest Chrome version. This means that even if the website relies on JavaScript frameworks to load content, ScrapingBee can capture the fully rendered page, allowing for complete data retrieval. It also provides geolocation capabilities, so you can appear as if you're browsing from a specific region.
How to scrape AirBNB Listings with ScrapingBee
Without further ado, we will quickly integrate the ScrapingBee API into our project to make it easier for us to extract data from AirBNB listings.
Prerequisites
To follow this guide, you'll need to preferably have Python 3.12.0 installed on your computer. Start by creating a separate directory for this project:
$ mkdir airbnb_scraper
$ cd airbnb_scraper
$ touch main.py
This will create a new directory called airbnb_scraper, navigate into it, and create a new Python file named main.py.
Now, let's install the necessary libraries. For this project, you'll need BeautifulSoup and lxml. You can install these libraries using pip. Run the following command in your terminal:
$ pip install beautifulsoup4 lxml
Setting Up ScrapingBee
To get started with ScrapingBee, you'll need to install the ScrapingBee Python SDK. You can do this using pip:
$ pip install scrapingbee
After installing the SDK, sign up for an account. Once you sign up, you'll receive an API key and 1000 free scraping credits!
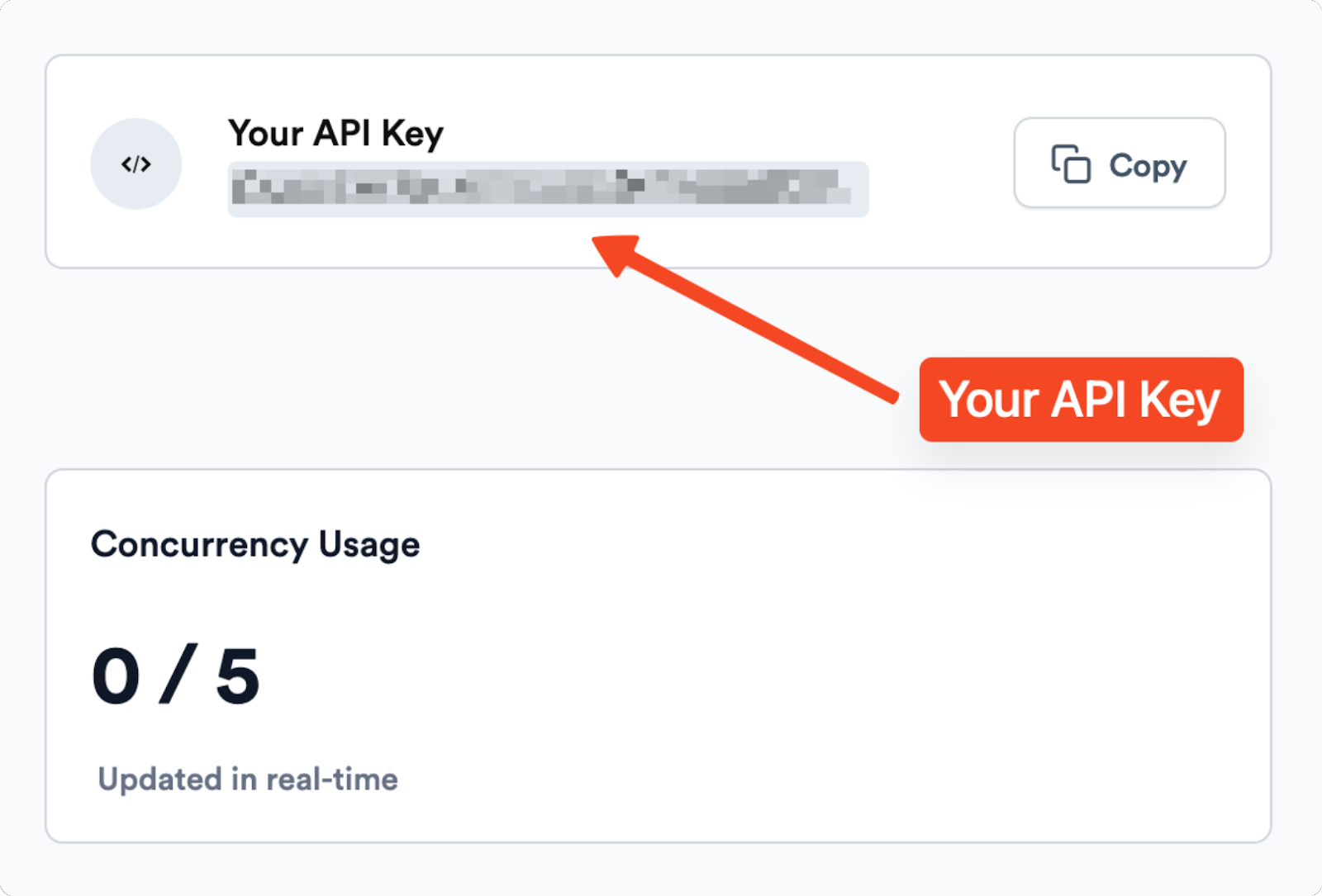
After signing up, navigate to your ScrapingBee dashboard to find your API key.
Once you have signed up and received your API key, you can integrate ScrapingBee into your project.
Step-by-Step Guide
Step 1: Import the Required Libraries
Import the necessary libraries at the beginning of your Python script:
from scrapingbee import ScrapingBeeClient
from bs4 import BeautifulSoup
import json
Step 2: Initialize the ScrapingBee Client
Initialize the ScrapingBee client, which will be used to send requests to Airbnb.
client = ScrapingBeeClient(api_key='YOUR_API_KEY')
This creates an instance of the ScrapingBeeClient using your provided API key, Replace 'YOUR_API_KEY' with your actual ScrapingBee API key which you can get here.
Step 3: Make a Request to Airbnb
Next, request to Airbnb's search page for California listings using the ScrapingBee client. We specify some parameters to ensure the page is fully loaded before we scrape it.
response = client.get("https://www.airbnb.com/s/california--United-States/homes?checkin=2024-05-20&checkout=2024-05-27",
params = {
'country_code': 'us',
'premium_proxy': 'True',
'wait_browser': 'load',
}
)
The get method sends an HTTP GET request to the specified URL with the provided parameters. The “premium_proxy” and “wait_browser” parameters are used to ensure that the page is fully loaded before attempting to scrape it. For more details on these parameters, refer to the official ScrapingBee Documentation.
Step 4: Parse the HTML with BeautifulSoup
Next, parse the HTML content of the response using BeautifulSoup. This library will help us navigate and search the HTML structure easily.
soup = BeautifulSoup(response.content, "lxml")
BeautifulSoup is initialized with the content of the response and the parser library 'lxml'. This creates a “soup” object that we can use to find elements and extract data from the HTML.
Step 5: Extract Listing Information
BeautifulSoup is used to find the listings and extract the desired information. We will look for elements with specific classes and extract text or other attributes.
listings = soup.find_all("div", class_="lxq01kf")
for listing in listings:
# Extract the title, description, beds, date range, total price, rating, and URL
Use the find_all method to get a list of all div elements with the class “lxq01kf”, which contains the listings. Then, for each listing, extract various information such as the title, description, number of beds, date range, total price, rating, and the URL.
Extracting the Listing Title
First, extract the title of each listing. Find the 'div' element with the class ‘t1jojoys’ and get its text content.
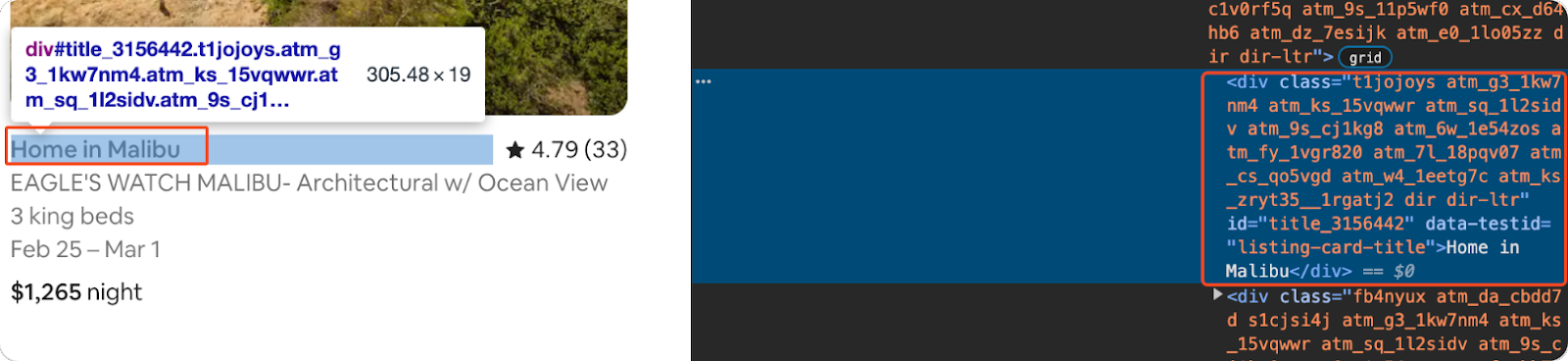
title = listing.find("div", class_="t1jojoys").get_text(strip=True) if listing.find("div", class_="t1jojoys") else 'N/A'
Extract the Description
Next, extract the description of the listing. Find the 'div' element with the class 'fb4nyux' and get its text content.
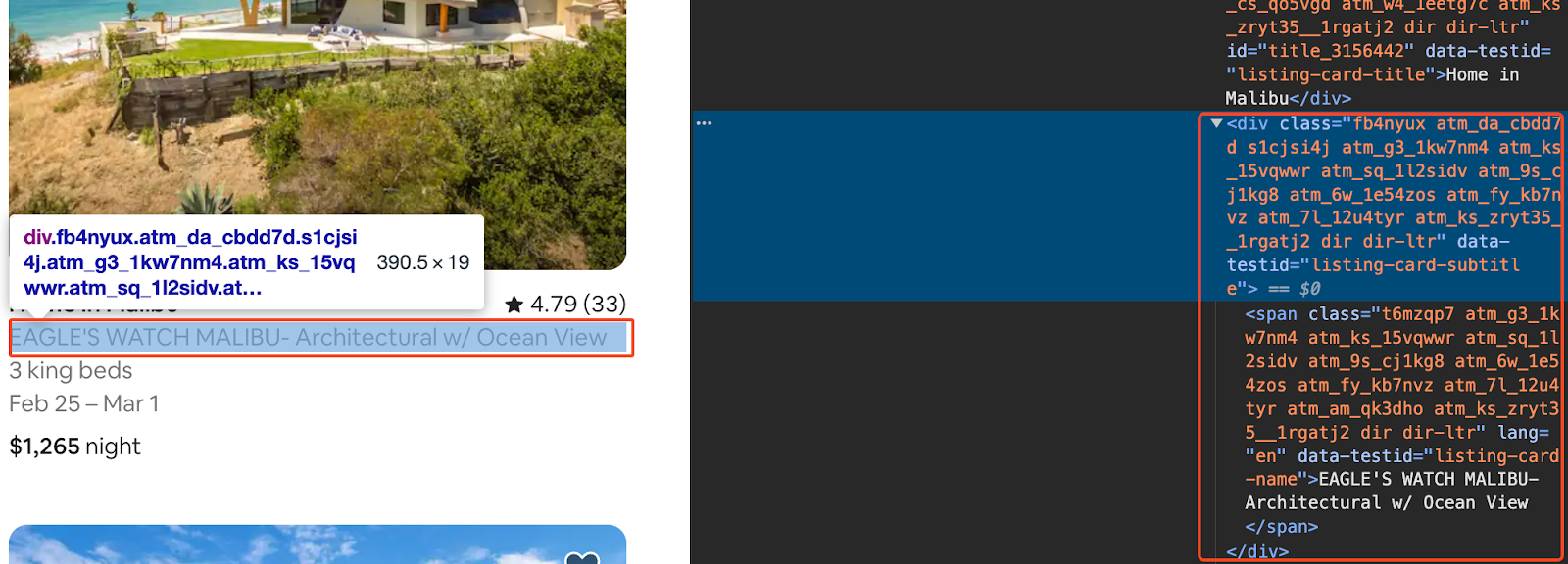
description_section = listing.find("div", class_="fb4nyux")
description = description_section.get_text(strip=True) if description_section else 'N/A'
Extract the Number of Beds and Date Range
To extract the number of beds and date range, look for 'div' elements with a 'data-testid' attribute of 'listing-card-subtitle'. Check the text of each element to determine if it contains information about the number of beds or a date range.
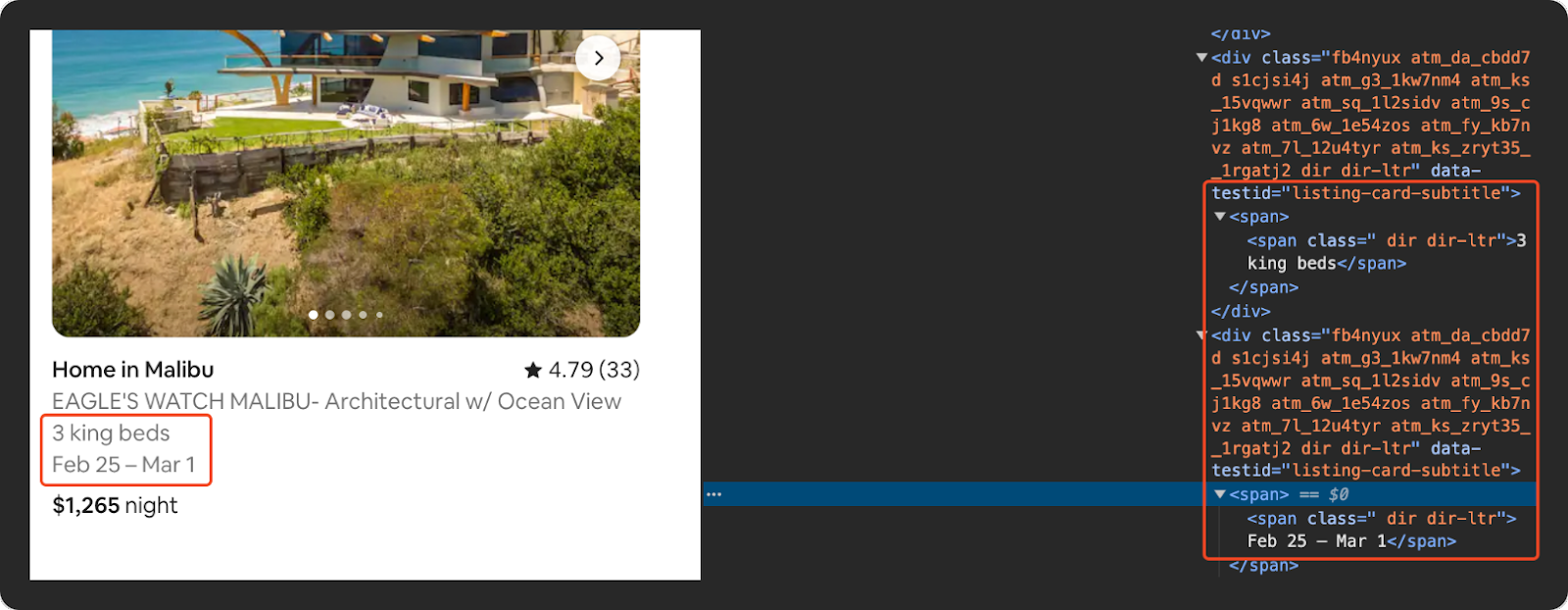
beds = 'N/A'
date_range = 'N/A'
beds_and_dates = listing.find_all("div", {"data-testid": "listing-card-subtitle"})
for subtitle in beds_and_dates:
text = subtitle.get_text(strip=True)
if 'bed' in text.lower():
beds = text
elif '-' in text or '-' in text:
date_range = text
This code iterates over all 'div' elements with the 'data-testid' attribute set to 'listing-card-subtitle'. It checks if the text contains the word 'bed' (indicating the number of beds) or a date range (indicated by a dash).
Extract the Total Price
We extract the total price by finding the 'span' element with the class '_14y1gc' and getting its text content, stripping any whitespace.
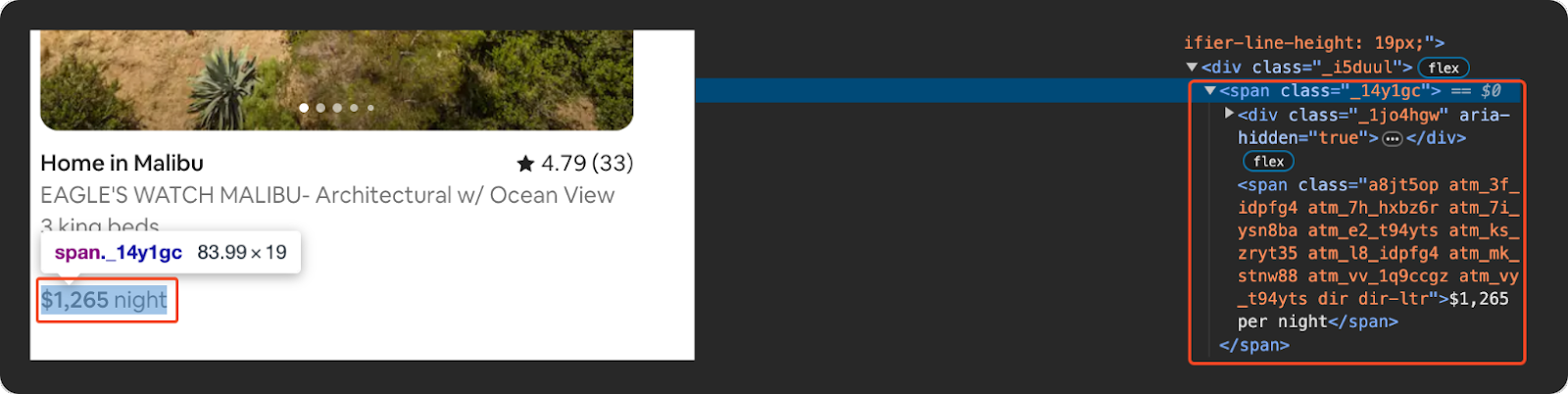
total_price = listing.find("span", class_="_14y1gc").get_text(strip=True) if listing.find("span", class_="_14y1gc") else 'N/A'
Extract the Rating
The rating is extracted by finding the 'span' element with the class 'r1dxllyb' and getting its text content, stripping any whitespace.
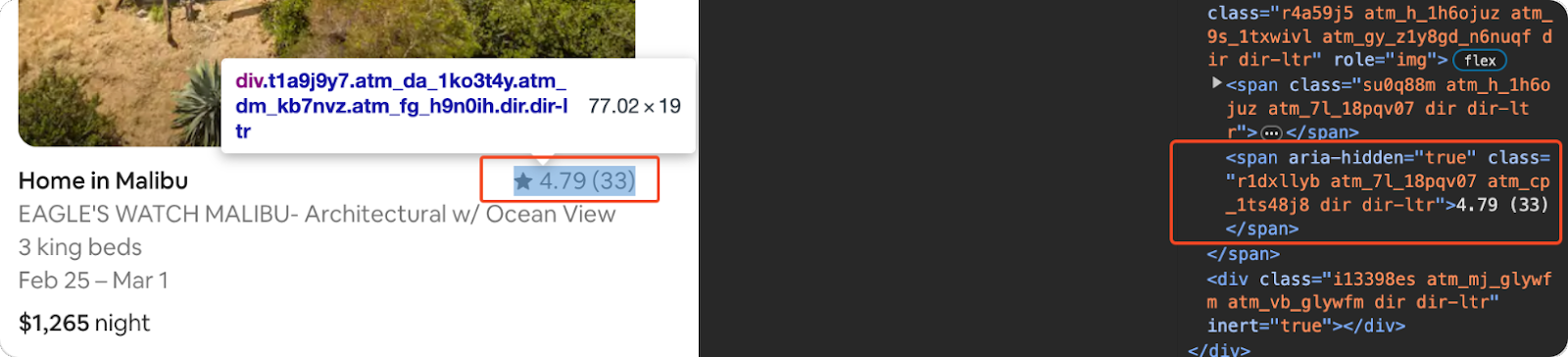
rating = listing.find("span", class_="r1dxllyb").get_text(strip=True) if listing.find("span", class_="r1dxllyb") else 'N/A'
Extract the Listing URL
Lastly, we extract the URL of the listing. We find the 'div' with the class 'c14whb16', get the 'a' tag within it, and retrieve the 'href' attribute.
listing_url_section = listing.find("div", class_="c14whb16")
listing_url = (
"https://www.airbnb.com" + listing_url_section.find("a")["href"] if listing_url_section else ""
)
Step 6: Save the Results
Finally, save the extracted data to a JSON file. This allows us to store the data for later use or analysis.
with open('airbnb_results.json', 'w') as jsonfile:
json.dump(results, jsonfile, indent=4, ensure_ascii=False)
Create a file named ‘airbnb_results.json’ in write mode and use ‘json.dump’ to write the results list to the file. The indent parameter is set to ‘4’ to format the JSON in a readable way, and ‘ensure_ascii’ is set to ‘False’ to properly handle non-ASCII characters.
Full Code
Here is the full code for the scraper we built in this tutorial. Remember to replace 'YOUR_API_KEY' with your ScrapingBee API key.
from scrapingbee import ScrapingBeeClient
from bs4 import BeautifulSoup
import json
client = ScrapingBeeClient(api_key='YOUR_API_KEY')
print("starting ... ")
response = client.get("https://www.airbnb.com/s/california--United-States/homes?checkin=2024-05-20&checkout=2024-05-27",
params = {
'country_code': 'us',
'premium_proxy': 'True',
'wait_browser': 'load',
}
)
soup = BeautifulSoup(response.content, "lxml")
results = []
listings = soup.find_all("div", class_="lxq01kf")
for listing in listings:
# Extract the title of the listing
title = listing.find("div", class_="t1jojoys").get_text(strip=True) if listing.find("div", class_="t1jojoys") else 'N/A'
# Extracting the description
description_section = listing.find("div", class_="fb4nyux")
description = description_section.get_text(strip=True) if description_section else 'N/A'
beds = 'N/A'
date_range = 'N/A'
# Find all subtitle divs for the number of beds nd date range within the listing
beds_and_dates = listing.find_all("div", {"data-testid": "listing-card-subtitle"})
for subtitle in beds_and_dates:
text = subtitle.get_text(strip=True)
# Check if the subtitle text contains information about beds
if 'bed' in text.lower():
beds = text
# Check if the subtitle text looks like a date range
elif '-' in text or '-' in text:
date_range = text
# Extracting the total price
total_price = listing.find("span", class_="_14y1gc").get_text(strip=True) if listing.find("span", class_="_14y1gc") else 'N/A'
# Extracting the rating
rating = listing.find("span", class_="r1dxllyb").get_text(strip=True) if listing.find("span", class_="r1dxllyb") else 'N/A'
# Extracting the listing URL. The URL is relative, need to prepend the base Airbnb URL.
listing_url_section = listing.find("div", class_="c14whb16")
listing_url = (
"https://www.airbnb.com" + listing_url_section.find("a")["href"] if listing_url_section else ""
)
# Create a dictionary for the current listing
listing_data = {
"Title": title,
"Description": description,
"Beds": beds,
"Total Price": total_price,
"Rating": rating,
"Date Range": date_range,
"Listing URL": listing_url
}
# Append the listing dictionary to the results list
results.append(listing_data)
# write the results to a JSON file
with open('airbnb_results.json', 'w') as f:
json.dump(results, f, indent=4, ensure_ascii=False)
print("Results saved to airbnb_results.json")
Results
After running the web scraper, you will have a JSON file named “airbnb_results.json” that contains all the scraped data from the Airbnb listings.
{
"Title": "Home in Lake Arrowhead",
"Description": "Peaceful Modern A-Frame Cabin with a view",
"Beds": "3 beds",
"Total Price": "€ 514night€ 514 per night",
"Rating": "5.0 (56)",
"Date Range": "Mar 28 - Apr 2",
"Listing URL": "https://www.airbnb.com/rooms/762632213174916471?adults=1&category_tag=Tag%3A5348&children=0&enable_m3_private_room=true&infants=0&pets=0&photo_id=1530126067&check_in=2024-03-28&check_out=2024-04-02&source_impression_id=p3_1708063012_hrMsUUZbyRkUiARb&previous_page_section_name=1000&federated_search_id=25f6ee18-7919-4854-ac80-6a8d839d16a6"
},
{
"Title": "Home in Malibu",
"Description": "Malibu Mid-Century Modern Luxury retreat home",
"Beds": "5 beds",
"Total Price": "€ 2,325€ 1,748night€ 1,748 per night, originally € 2,325",
"Rating": "5.0 (120)",
"Date Range": "Mar 9 - 14",
"Listing URL": "https://www.airbnb.com/rooms/34577812?adults=1&category_tag=Tag%3A8528&children=0&enable_m3_private_room=true&infants=0&pets=0&photo_id=938111314&check_in=2024-03-09&check_out=2024-03-14&source_impression_id=p3_1708063012_xazOKnLr6NWOJSPu&previous_page_section_name=1000&federated_search_id=25f6ee18-7919-4854-ac80-6a8d839d16a6"
},
{
"Title": "Farm stay in La Grange",
"Description": "Farm Stay at the Bell-Zwart Lodge",
"Beds": "5 beds",
"Total Price": "€ 243night€ 243 per night",
"Rating": "4.95 (60)",
"Date Range": "May 19 - 24",
"Listing URL": "https://www.airbnb.com/rooms/544062603243081437?adults=1&category_tag=Tag%3A4104&children=0&enable_m3_private_room=true&infants=0&pets=0&photo_id=1383507376&check_in=2024-05-19&check_out=2024-05-24&source_impression_id=p3_1708063012_s0ol%2BdxRrqO1erqq&previous_page_section_name=1000&federated_search_id=25f6ee18-7919-4854-ac80-6a8d839d16a6"
},
{
"Title": "Farm stay in Martinez",
"Description": "Bellacollina Farms ~ Beautiful Briones Retreat",
"Beds": "4 beds",
"Total Price": "€ 390night€ 390 per night",
"Rating": "4.92 (112)",
"Date Range": "Feb 23 - 28",
"Listing URL": "https://www.airbnb.com/rooms/48848443?adults=1&category_tag=Tag%3A8175&children=0&enable_m3_private_room=true&infants=0&pets=0&photo_id=1151899222&check_in=2024-02-23&check_out=2024-02-28&source_impression_id=p3_1708063012_amcohU3J5J71T8tm&previous_page_section_name=1000&federated_search_id=25f6ee18-7919-4854-ac80-6a8d839d16a6"
},
{
"Title": "Camper/RV in Joshua Tree",
"Description": "Wonderlust Airstream",
"Beds": "2 beds",
"Total Price": "€ 349€ 317night€ 317 per night, originally € 349",
"Rating": "4.97 (337)",
"Date Range": "Mar 16 - 21",
"Listing URL": "https://www.airbnb.com/rooms/44403770?adults=1&category_tag=Tag%3A8099&children=0&enable_m3_private_room=true&infants=0&pets=0&photo_id=1082320026&check_in=2024-03-16&check_out=2024-03-21&source_impression_id=p3_1708063012_qT1erkLzgNN%2Bd%2F4m&previous_page_section_name=1000&federated_search_id=25f6ee18-7919-4854-ac80-6a8d839d16a6"
},
... More Listing Data ...
Wrapping Up
In this article, we've covered the basics of scraping Airbnb listings using Python, BeautifulSoup, and ScrapingBee. We've walked you through the steps to set up your Python environment, make requests to Airbnb, extract the desired information, and save the results to a JSON file.
Remember, the code provided is an example, and you'll need to adapt it to your specific needs. Happy scraping!
Want to try ScrapingBee API?
If you are interested in scraping data and building products around it, then give ScrapingBee a try.
Sign up now to get 1000 free scraping credits! There's no need to provide credit card information or any commitment upfront, making it easy to test out the service.
So, why wait? Sign up for ScrapingBee today and supercharge your web scraping output!⚡️
Frequently Asked Questions (FAQs)
Can I scrape Airbnb without using ScrapingBee?
Yes, you can use other proxy services or even your own IP to scrape Airbnb, but using a service like ScrapingBee can help you avoid getting blocked.
Will Airbnb block my IP if I scrape their site?
There's a possibility of being blocked if your scraping activities are detected as excessive or malicious. Using ScrapingBee helps mitigate this risk by offering premium proxy options.
What if the website structure changes?
If the website structure changes, your scraping code may break. Always check for updates to the website and adjust your code accordingly.


