In this tutorial, we will see how you can log in to any website, using three different methods:
- A JavaScript scenario.
- A POST request.
- Cookies
As an example, we’re going to log into this demo website and take a screenshot of the account page. So make sure to create an account there before you start!
1. Login using a js_scenario:
This is the easiest solution among the three, as it mimics the behavior of a normal user. We first visit the login page, input our login credentials, and click on the login button.
The code below will do that for our example website, and will take a screenshot of the account page:
from scrapingbee import ScrapingBeeClient
MAIN_URL = "http://automationpractice.com/index.php?controller=authentication"
client = ScrapingBeeClient(api_key='YOUR-API-KEY')
response = client.get(
MAIN_URL,
params= {
"js_scenario": {"instructions":[
{"fill": ["#email", "your-registration-email@website.com"]}, # Enter registration email
{"fill": ["#passwd", "your-password"]}, # Enter password
{"click": "#SubmitLogin"}, # Click on login
{"wait": 1000} # Wait for a second
]},
"screenshot_full_page": True # Take a screenshot
}
)
if response.ok:
with open("./screenshot.png", "wb") as f:
f.write(response.content)
else:
print(response.content)
And the result is a successful login as you can see:
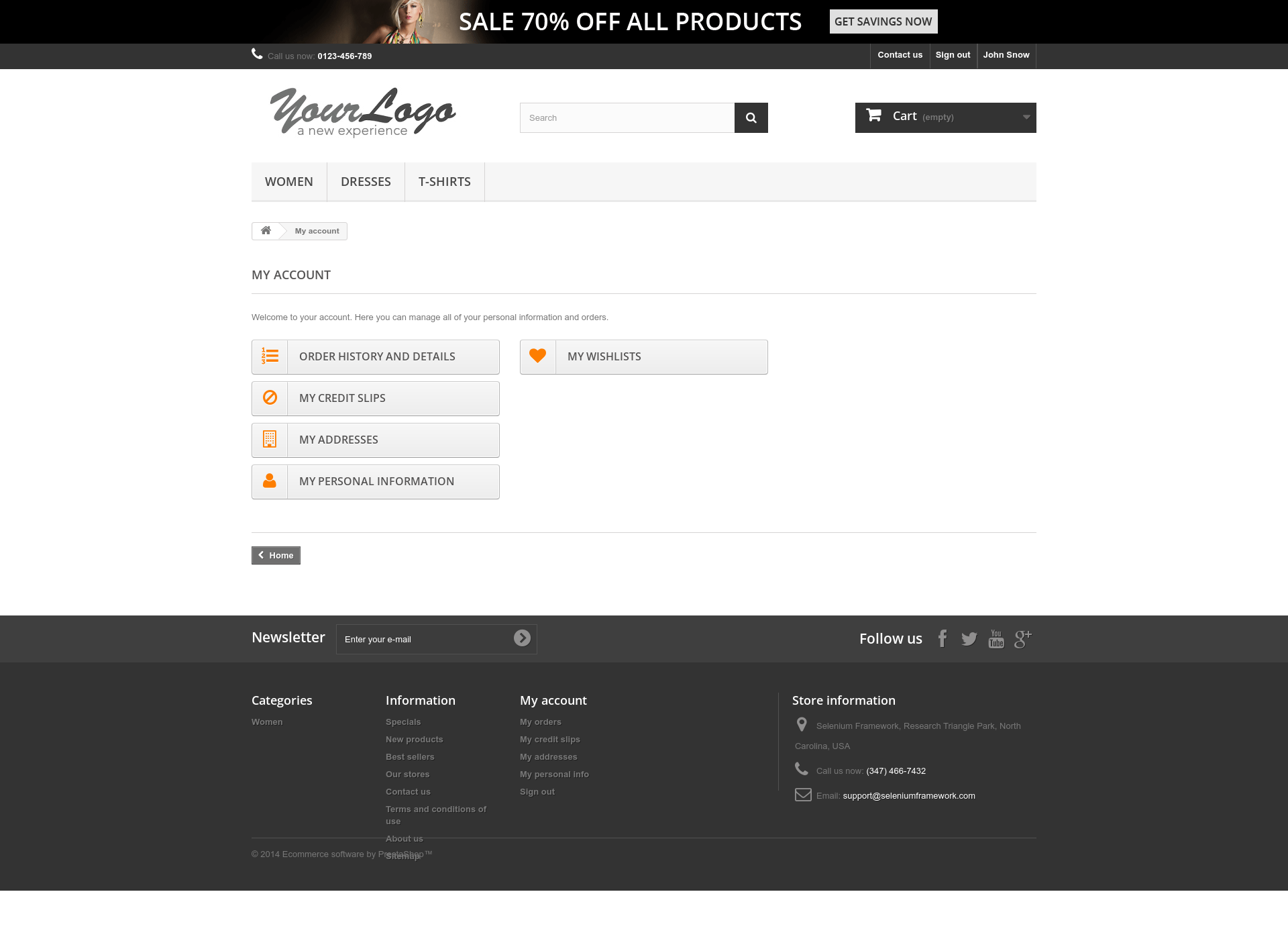
2. Login using a POST requests:
With this method, we will send a direct POST request to the form action URL.
First we need to see what fields are being sent when we login. We can do that easily via Chrome developers tools:
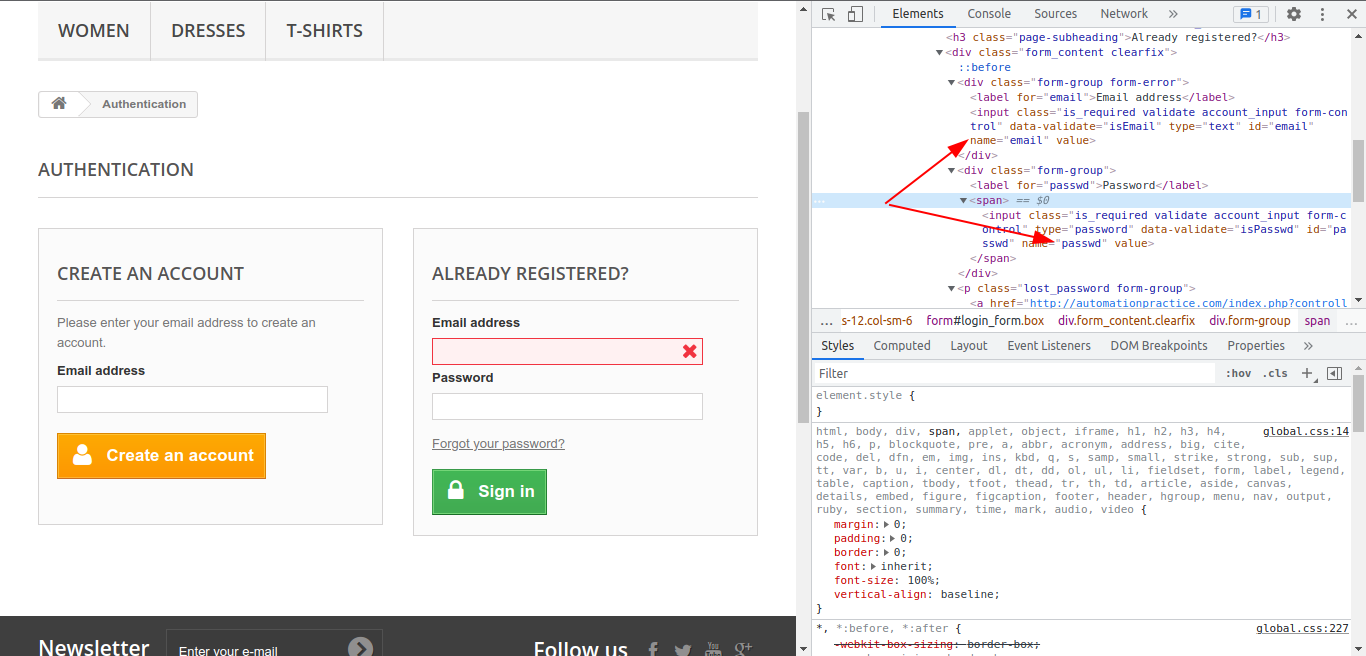
As you can see, the fields we need to fill are: email and passwd.
The code below will make a POST request to our website, sending our data with it.
from scrapingbee import ScrapingBeeClient
MAIN_URL = "http://automationpractice.com/index.php?controller=authentication"
client = ScrapingBeeClient(api_key='YOUR-API-KEY')
response = client.post( # Using a POST request instead of GET
MAIN_URL,
data= { # Data to send with our POST request
"email": "your-registration-email@website.com", # Login email
"passwd": "your-password" # Login password
}
)
if response.ok:
with open("./account.html", "wb") as f:
f.write(response.content)
else:
print(response.content)
3. Using cookies to login:
Log into our demo website, and open Chrome developers tools, go to Application → Cookies, and you will notice that a cookie with the name PrestaShop-a30a9934ef476d11b6cc3c983616e364 with a large hashed value is saved and being used on that domain. That cookie stores all of the information about the user, logging information, user status, etc…
Now that we have that cookie, we can copy its content and send it directly with a request to My Account area without having to send any credentials.
The final code will look like this:
from scrapingbee import ScrapingBeeClient
MAIN_URL = "http://automationpractice.com/index.php?controller=my-account"
client = ScrapingBeeClient(api_key='YOUR-API-KEY')
response = client.get(
MAIN_URL,
cookies = {"PrestaShop-a30a9934ef476d11b6cc3c983616e364": "Cookie-Text-Here"},
params= {
"screenshot_full_page": True,
}
)
if response.ok:
with open("./screenshot.png", "wb") as f:
f.write(response.content)
else:
print(response.content)
And as you can see below, we managed to access that page without having to manually log in!
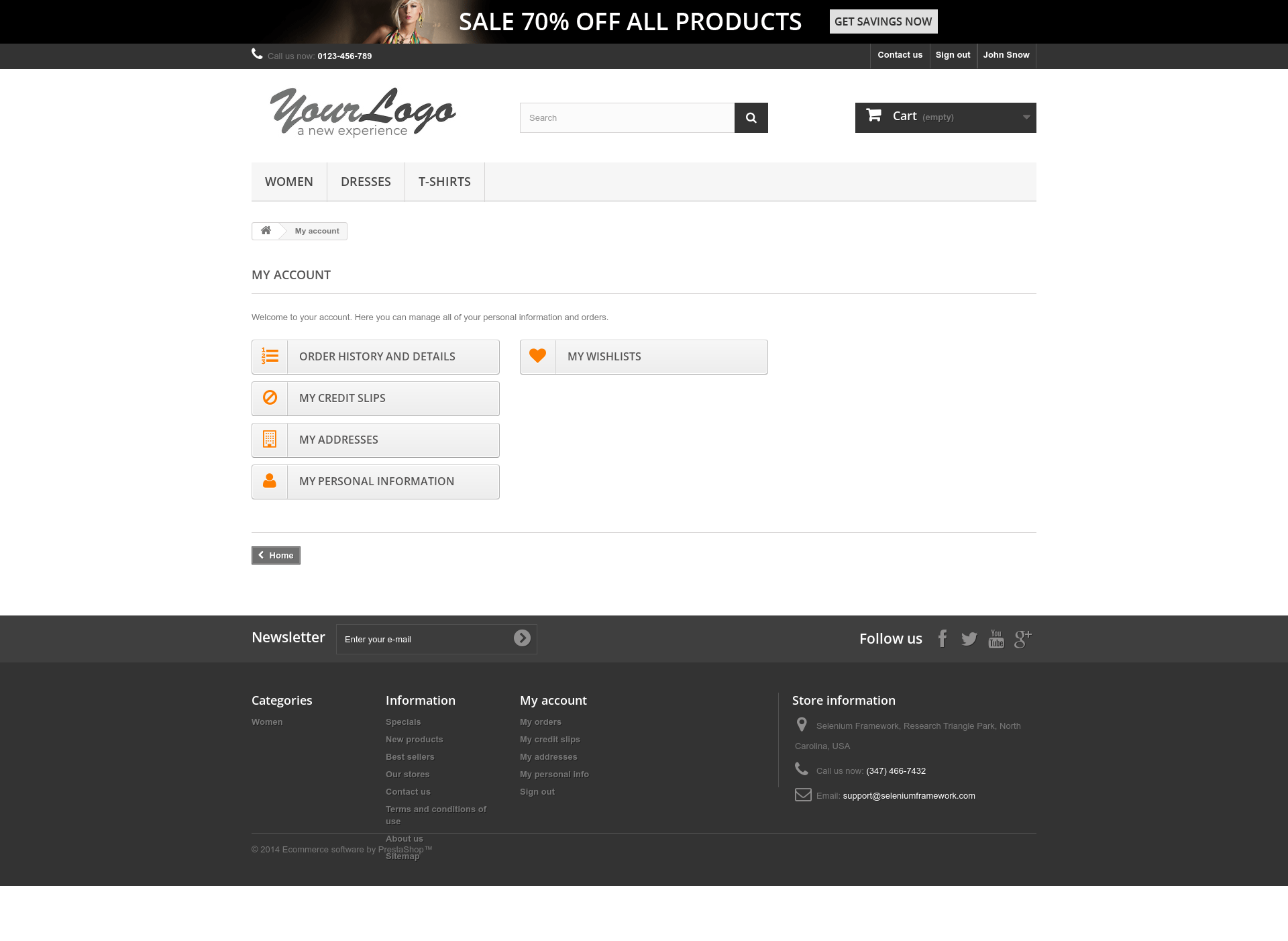 Go back to tutorials
Go back to tutorials