Certain websites may hide all of their page content inside a shadow root, which makes scraping them quite challenging. This is because most scrapers cannot directly access HTML content embedded within a shadow root. Here is a guide on how you can extract such data via ScrapingBee.
We will use a quite popular site as an example: www.msn.com
If you inspect any article on this page, let’s use this one. You can see that all of its contents are inside a shadow root: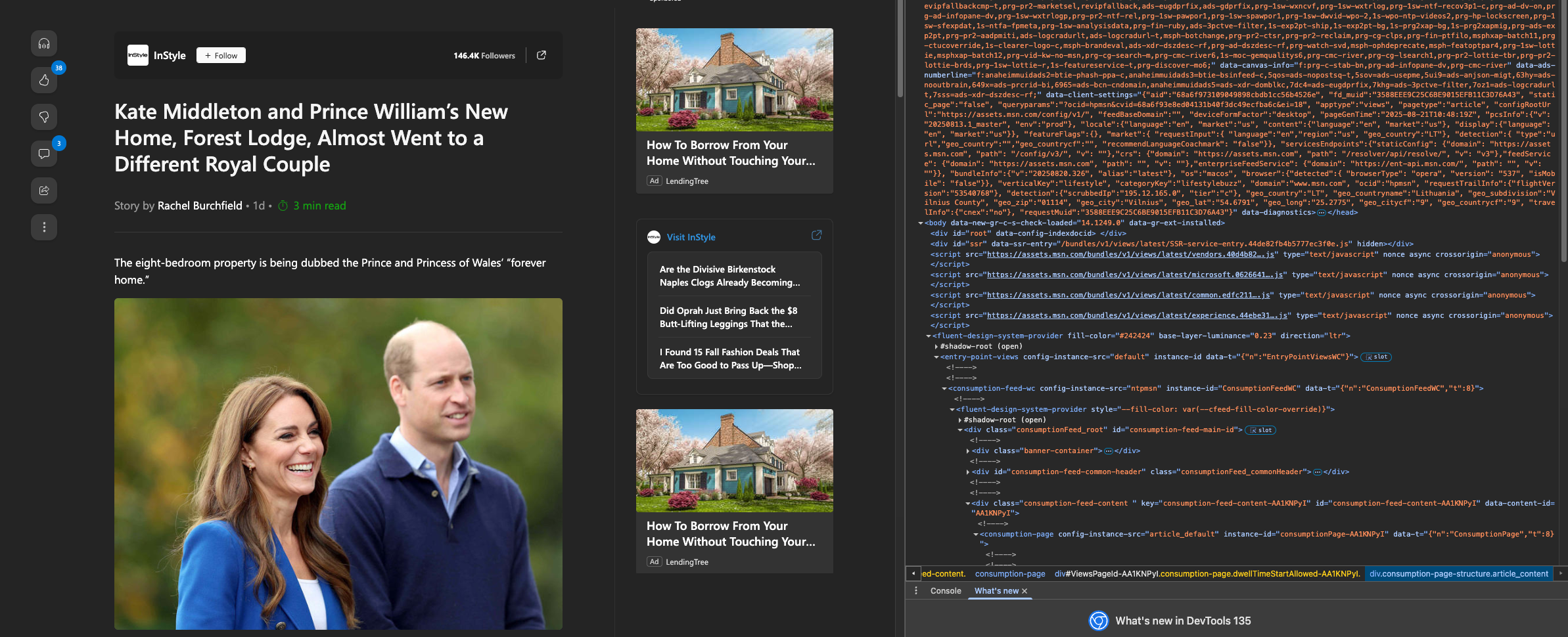
To extract this content with the ScrapingBee API, you would need to use this code in an evaluate command:
document.body.innerHTML = document.querySelector('article > cp-article').shadowRoot.innerHTML
And the response would look like this: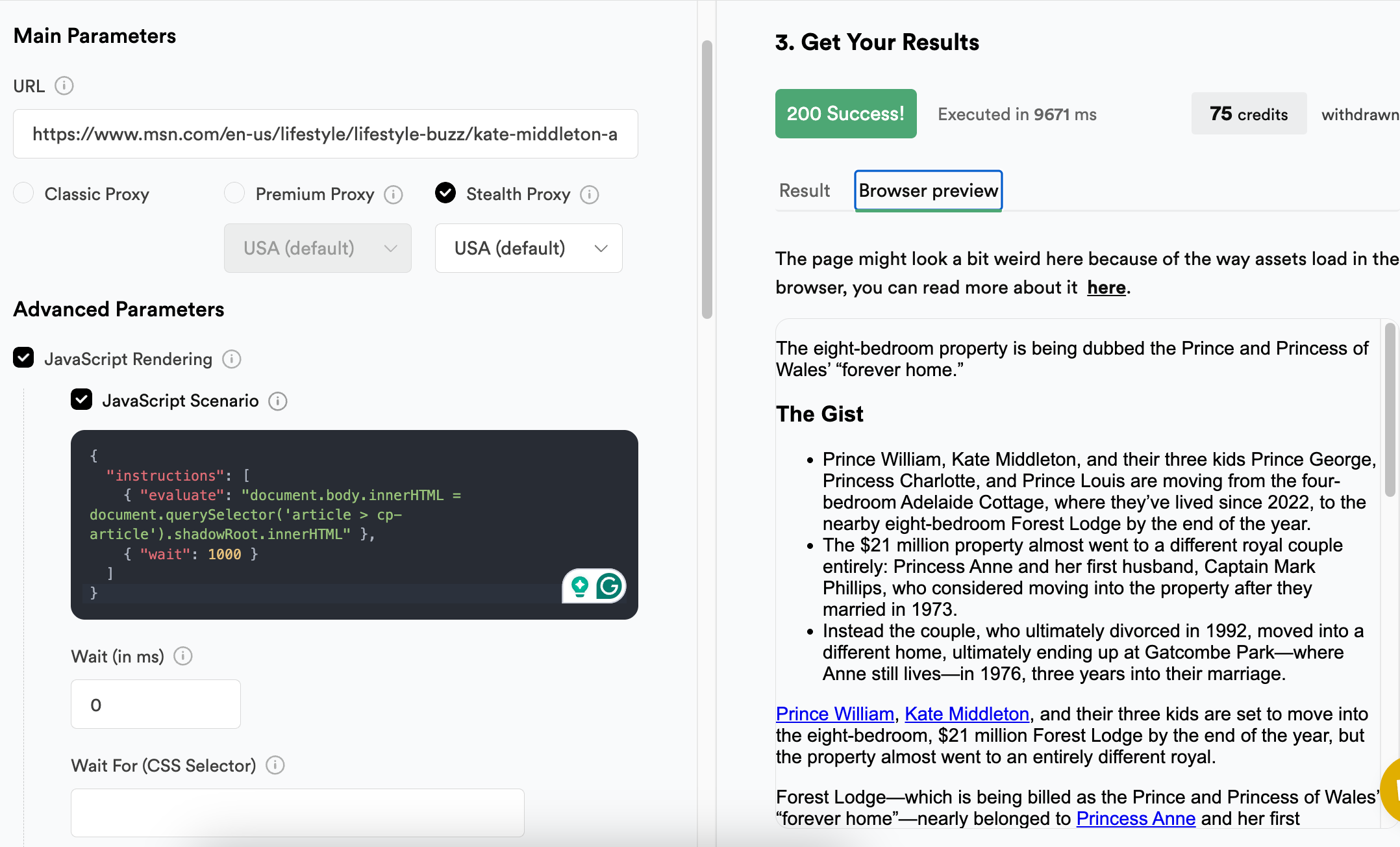
The article content is extracted from the shadow DOM and injected into the document body, making it directly accessible through our API. Once exposed, it can be parsed, processed, or utilized as needed.