Get Markdown or Plain Text content from any website you want to scrape. Mike Ritchie CEO @
SeekWell ScrapingBee simplified our day-to-day marketing and engineering operations a lot. We no longer have to worry about managing our own fleet of headless browsers, and we no longer have to spend days sourcing the right proxy provider The Problem Collecting training data for LLMs shouldn't feel like hacking. Building datasets for AI models and LLMs is a pain: You're blocked by anti-bot systems when scraping at scale HTML noise pollutes your training datasets Manual data cleaning and parsing wastes time and resources Unstructured data formats slow down model training Managing proxies and browsers distracts from your core work Whether you're training AI models, building LLMs, or collecting data for machine learning at scale, you shouldn't need a DevOps team just to get clean, structured training data. ScrapingBee simplifies the process with smart parameters designed for cleaner, faster, and more reliable data extraction. ScrapingBee's return_page_markdown and return_page_text parameters automatically convert web pages into structured, LLM-ready formats—eliminating HTML noise and streamlining your data pipeline for AI training and content processing. Developer Experience Top-rated support & Our team is here to guide you when you need the extra assistance. And we're constantly working on new features to make your life easier. Fantastic documentation Take a look at our AI documentation and get started in minutes! Code samples Whatever the programming language you enjoy, we have written code samples ready. Knowledge base Our extensive knowledge base covers the most frequent use cases with code samples. Exceptional support Fast, engineer-led support via live chat or email Cancel anytime, no questions asked! Need more credits and concurrency per month? Not sure what plan you need? Try ScrapingBee with 1000 free API calls. (No credit card required)The easiest way to make the web LLM-readable
![]() based on 100+ reviews.
based on 100+ reviews.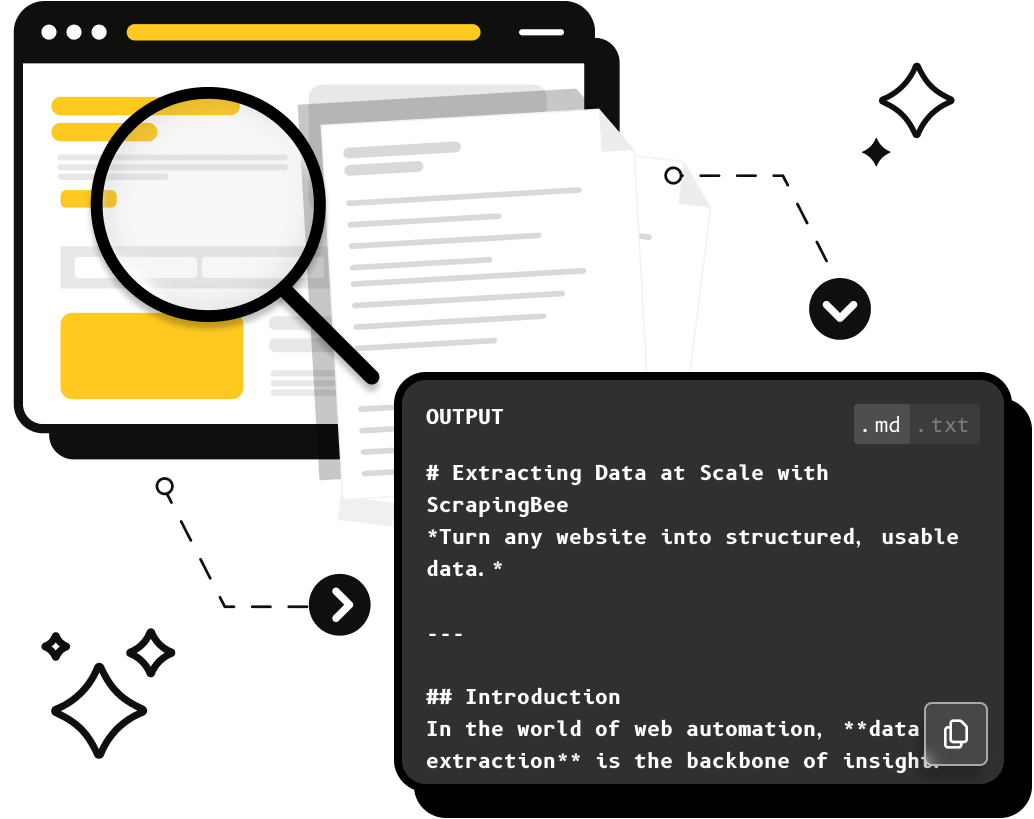


The ScrapingBee Advantage
Extract Clean Markdown or Plain Text from Any Website
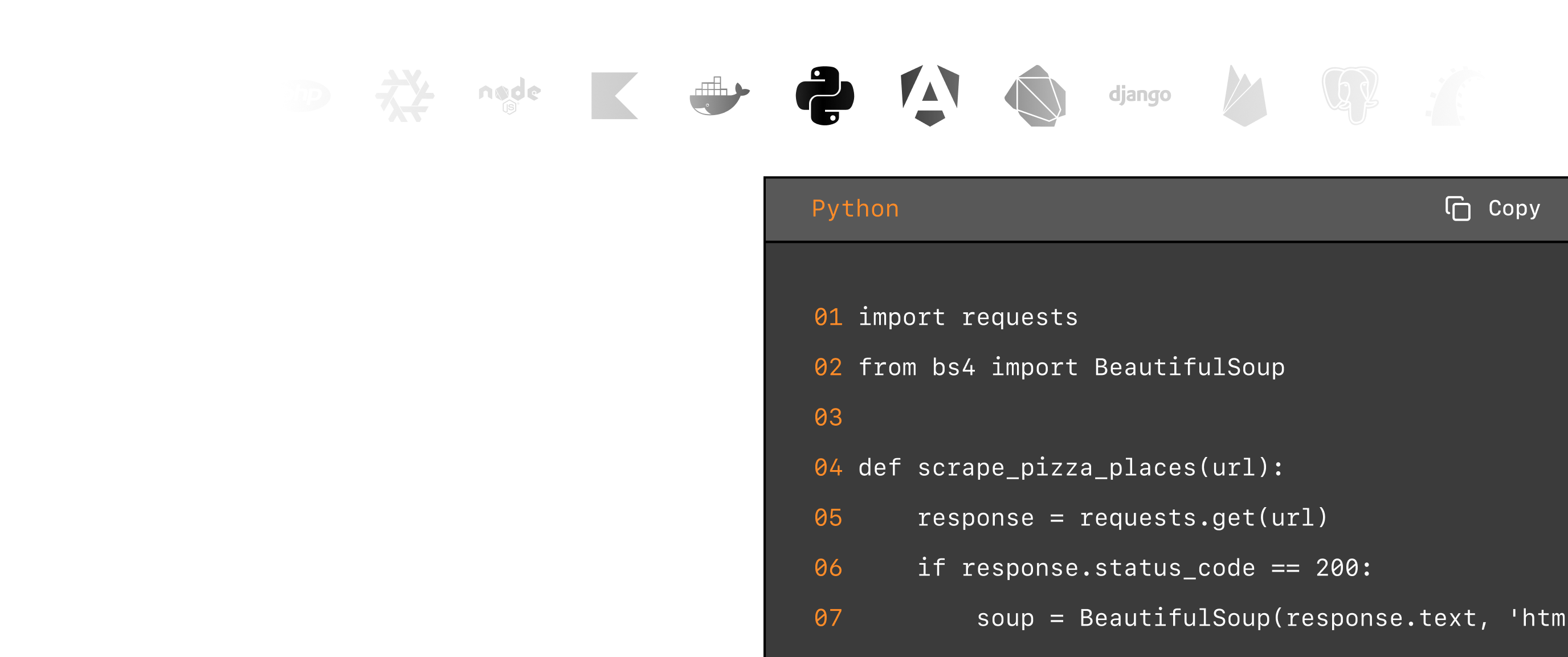
# Install the Python ScrapingBee library:
# pip install scrapingbee
from scrapingbee import ScrapingBeeClient
client = ScrapingBeeClient(api_key='YOUR-API-KEY')
response = client.get('YOUR-URL',
params = {
'return_page_markdown': 'True',
}
)
print('Response HTTP Status Code: ', response.status_code)
print('Response HTTP Response Body: ', response.content)
const axios = require('axios');
axios.get('https://app.scrapingbee.com/api/v1/', {
params: {
"api_key": "YOUR-API-KEY",
"url": "YOUR-URL",
"return_page_markdown": "True"
}
}).then(function (response) {
console.log(response);
});
<?php
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'https://app.scrapingbee.com/api/v1/?api_key=YOUR-API-KEY&url=YOUR-URL&return_page_markdown=True');
curl_setopt($ch, CURLOPT_CUSTOMREQUEST, 'GET');
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$response = curl_exec($ch);
if (!$response) {
die('Error: "' . curl_error($ch) . '" - Code: ' . curl_errno($ch));
}
echo 'HTTP Status Code: ' . curl_getinfo($ch, CURLINFO_HTTP_CODE) . PHP_EOL;
echo 'Response Body: ' . $response . PHP_EOL;
curl_close($ch);
?>
# Install the Python ScrapingBee library:
# pip install scrapingbee
from scrapingbee import ScrapingBeeClient
client = ScrapingBeeClient(api_key='YOUR-API-KEY')
response = client.get('YOUR-URL',
params = {
'return_page_text': 'True',
}
)
print('Response HTTP Status Code: ', response.status_code)
print('Response HTTP Response Body: ', response.content)
const axios = require('axios');
axios.get('https://app.scrapingbee.com/api/v1/', {
params: {
"api_key": "YOUR-API-KEY",
"url": "YOUR-URL",
"return_page_text": "True"
}
}).then(function (response) {
console.log(response);
});
<?php
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'https://app.scrapingbee.com/api/v1/?api_key=YOUR-API-KEY&url=YOUR-URL&return_page_text=True');
curl_setopt($ch, CURLOPT_CUSTOMREQUEST, 'GET');
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$response = curl_exec($ch);
if (!$response) {
die('Error: "' . curl_error($ch) . '" - Code: ' . curl_errno($ch));
}
echo 'HTTP Status Code: ' . curl_getinfo($ch, CURLINFO_HTTP_CODE) . PHP_EOL;
echo 'Response Body: ' . $response . PHP_EOL;
curl_close($ch);
?>
# Extracting Data at Scale with ScrapingBee
*Turn any website into structured, usable data.*
---
## Introduction
In the world of web automation, **data extraction** is the backbone of insight.
ScrapingBee simplifies the process — handling **JavaScript rendering**, **proxies**, and **CAPTCHAs**, so you can focus on **collecting clean, structured data**.
Whether you're gathering product prices, blog articles, or real estate listings, ScrapingBee lets you scrape and extract data efficiently with just a few lines of code.
---
## Why Data Extraction Matters
Businesses rely on extracted data to drive smarter decisions:
- 🛒 **E-commerce Monitoring** — Track product prices and availability.
- 📰 **News & Content Aggregation** — Collect headlines or summaries.
- 📊 **Market Research** — Analyze competitors and industry trends.
- 💬 **Social Listening** — Gather reviews or comments across platforms.
- 🏘 **Real Estate Listings** — Keep listings up-to-date automatically.
---
## How ScrapingBee Helps
ScrapingBee provides **a fast, reliable, and scalable API** that abstracts the complexities of web scraping.
### Key Extraction Capabilities
- **Automatic HTML Rendering** — Perfect for sites built with React, Vue, or Angular.
- **Smart Parsing Options** — Extract structured data like JSON or XPath.
- **Built-in Proxy Rotation** — Avoid IP bans and captchas automatically.
- **Header & Cookie Control** — Emulate any browser environment easily.
---
## Example: Extracting Product Data
### 1️⃣ Make the Request
curl "https://api.scrapingbee.com/v1/?api_key=YOUR_API_KEY&url=https://example.com/products&extract_rules=rules.json"
Extracting Data at Scale with ScrapingBee
Turn any website into structured, usable data.
Introduction
In the world of web automation, data extraction is the backbone of insight.
ScrapingBee simplifies the process — handling JavaScript rendering, proxies, and CAPTCHAs, so you can focus on collecting clean, structured data.
Whether you're gathering product prices, blog articles, or real estate listings, ScrapingBee lets you scrape and extract data efficiently with just a few lines of code.
Why Data Extraction Matters
Businesses rely on extracted data to drive smarter decisions:
E-commerce Monitoring — Track product prices and availability.
News & Content Aggregation — Collect headlines or summaries.
Market Research — Analyze competitors and industry trends.
Social Listening — Gather reviews or comments across platforms.
Real Estate Listings — Keep listings up-to-date automatically.
How ScrapingBee Helps
ScrapingBee provides a fast, reliable, and scalable API that abstracts the complexities of web scraping.
Key Extraction Capabilities
Automatic HTML Rendering — Perfect for sites built with React, Vue, or Angular.
Smart Parsing Options — Extract structured data like JSON or XPath.
Built-in Proxy Rotation — Avoid IP bans and captchas automatically.
Header & Cookie Control — Emulate any browser environment easily.
Example: Extracting Product Data
1️⃣ Make the Request
curl "https://api.scrapingbee.com/v1/?api_key=YOUR_API_KEY&url=https://example.com/products&extract_rules=rules.json"
documentation
Frequently Asked Questions
Simple, transparent pricing.
High-volume data collection at scale
Industry-leading success rates
Clean, parsed structured data
Fully automated workflows
Our Solution

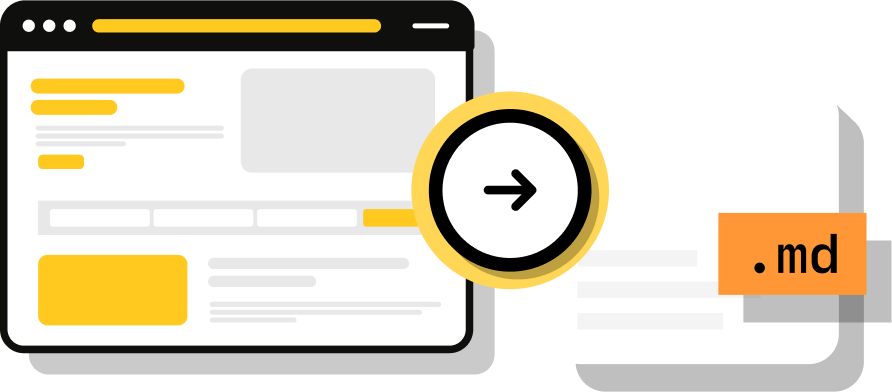
INPUT PARAMETERS
OUTPUT
.mdAI web scraping requests cost an additional five credits on top of the regular API cost.
Register your ScrapingBee account at https://dashboard.scrapingbee.com/account/register to get your 1,000 free API calls and check out the documentation of the AI Web Scraping API
Yes, our AI web scraping functionality is a complementary feature to our existing highly scalable scraping platform that's able to process millions of requests a day.
You can contact us either via the contact form on our website or our live chat where you can talk to one of our customer support agents who are scraping experts in their own right. We can help you to scale your scraping project with ease.
Yes, our AI web scraping support is built on top of our existing platform and can make full use of its broad JavaScript rendering support.
API Credits
Concurrent requests
JavaScript rendering
Rotating & Premium Proxies
Geotargeting
Screenshots, Extraction Rules, Google Search API
Priority Email Support
Dedicated Account Manager
Team Management
All prices are exclusive of VAT.