Your browser uses it, as does your REST API. It connects you to your favorite restaurant whenever you order food online. It's built into your IoT gadget and allows you to unlock doors and adjust your living room temperature, when you are on the other side of the planet. And it's even used to occasionally tunnel other protocols - HTTP
But what exactly is HTTP? What does it do and how does it work? If you already read some of our other articles (e.g. Web Scraping with PHP), you'll have already come across some details, but today we really want to go in-depth into what HTTP is.
The origins of HTTP
HTTP is an acronym for Hypertext Transfer Protocol and has been, ever since the inception of the WWW and HTML in 1989, the web's one fundamental building block and has served as primary communication technology between web clients and web servers.
HTTP is extremely ubiquitous these days and has superseded to a very good extent most "rival" protocols (notable exception, of course, SMTP). Before the web, the Internet used a variety of different protocols for serving information (e.g. NNTP, FTP, Gopher, and others), but all that changed with the advent of the web and the introduction of HTTP.
Basic Concepts of HTTP
The simplest way to explain HTTP, is probably to say you have two parties, A and B, A either wants some information from B, or it has some information for B. A would be the client here, whereas B would be the server.
What A essentially does, is send a request to B and wait for a response. Aptly, this is called a request-response approach and is rather common throughout network protocols.
In the context of HTTP, the client will simply establish a connection to the server and use that connection to send an HTTP request. That request contains all information necessary for the server to serve an answer. That may be either the exact location of a resource the client asked for (i.e. the path) or maybe the client actually provided some additional payload (i.e. a request body) because it wanted to store a file on the server.
Once the server has received the request, it will handle it accordingly and provide the client with the appropriate response.
That's actually it - but, of course, the devil lies in the details, doesn't it?
💡 One important detail, only the client will ever establish a connection. The server will never connect directly to the client.
HTTP Methods
An HTTP method (some also call it HTTP verb) is essentially just an English verb in uppercase, telling the server what kind of basic action should be performed with that request. While one can (in theory at least), introduce their own methods/verbs, there is a set of pre-defined and standardized method names.
These method names are indicated in the initial request line, which we will cover in just a second, promised.
GET
The very first, and by far most commonly used, method is GET. GET is, as the name suggests, intended to essentially fetch information from the server. No uploading, no modifying, really just a straight get.
While implementations may not always adhere to it, GET is supposed to be idempotent, meaning the call itself should not change anything about the resource it is querying and you should always get the same response to the same GET request. Well, in theory at least 😄
POST
Another rather common method is POST. POST is typically used when one wants to submit chunks of data to the server (e.g. upload a file).
HEAD, PATCH, PUT, and more
There are quite a few other method types and each has its own use case (e.g. HEAD will return the same headers as a GET request, but tells the server to explicitly omit the actual resource data in the response).
A full list of currently standardized methods can be found at https://developer.mozilla.org/docs/Web/HTTP/Methods.
The Structure of an HTTP Exchange
Whenever you type www.google.com in your browser and press Enter, there are quite a few steps your browser will perform before it will be able to show you the Google search bar (and possibly Google's Doodle of the day).
For example, it will check whether it already has a valid cache entry for that page, it will match the domain against any blacklist entries, and - of course - it will use DNS to try and resolve the hostname to its actual IP address (computers love numbers, don't they?). But for the sake of this article, let's skip the other parts and focus on the HTTP part, shall we?
The HTTP request
Once the browser is ready to ask the server for the information, it will open a TCP (or UDP as of HTTP 3) connection and send something like the following over that connection.
GET / HTTP/1.1
Host: www.google.com
This request mirrors our previous example with Google and shows a request that asked for the root page (/) of the specified hostname (www.google.com). Of course, this is a very simplified example, but it does show the most basic request syntax for an HTTP 1.1 connection.
The request here consists of three lines (please do note the empty line at the end)
- the request line
- one HTTP request header
- the header delimiter
The request line
The first line here is called request line. It consists of three parts
- the request method (
GETin our case) - the request target (typically the path,
/in our example) - and the HTTP version (1.1 in our example)
HTTP request headers
Following our request line, is a number of request headers. In our example above, we only have one header (Host), but typically you'll find ten to twenty such headers in an HTTP request. These headers provide the server with additional information on our request any may include
- details on the client software we are using -
User-Agent - a list of resource types we are accepting for our request -
Accept - credentials for user authentication -
Authorization
HTTP headers are used for a variety of use cases - for example, HTTP cookies - and you can find a semi-complete list at https://developer.mozilla.org/docs/Web/HTTP/Headers. All right, what's next?
Actually, an empty line 🤷🏻♂️
The header delimiter
That's right, after all our request headers, we take a quick break with an empty line. That line indicates the end of our headers and possibly our request altogether. That is, if we did not opt to include a body in our request, in which case the server can already handle our request. Otherwise, if we included a payload in the request body, that payload will start immediately after our empty line here.
The request body
The request body is an optional element of every request and actually only used with certain HTTP methods. For example, GET is never supposed to include a request body, whereas POST will typically always include a body.
Should the client choose to add a body, then it will immediately follow the empty delimiter line. It may be appended to our request either as-is or converted into one of the encoding formats available via Transfer-Encoding.
Request summary
To quickly recap on requests, they are the first part in an HTTP exchange and let the client specify exactly what it wants to request from the server, or send to it. This includes the address of the resource in question, information on the client itself, as well as possible data chunks it wants to send to the server, along with metadata.
Of course, when you send a request, it would be ideal if you also got a response, right? And that's exactly what we are going to check out next.
The HTTP response
Let's jump right in and show an example, which we might receive to our previous request to www.google.com.
HTTP/1.1 200 OK
Content-Type: text/html
Server: gws
Transfer-Encoding: chunked
[PAGE CONTENT FOLLOWS HERE]
As you notice, a response is structure-wise actually pretty similar to a request. The first line appears to be some sort of status, following are a couple of headers, then we our good old delimiter line, and finally, there seemingly is a body with the page content. That does look just like a request, doesn't it?
You are right, the structure of an HTTP response is not all that different, there are a few major differences, however.
First and foremost, while the majority of requests does not include body data, it's quite the opposite with responses. As they typically serve content, they usually do include body data. But let's check out the response elements in detail.
The status line
Just like the request line for requests, the status line is the very first line in the response and provides us with the overall status of the response, as presented by the server.
It consists of three parts
- the HTTP version (1.1 in our example)
- a three-digit status code (
200in our example) - a complementary text description to the status code (
OKhere)
Particularly, the status code is interesting, as it is the sole indicator if the request was successfully handled by the server or if there were any issues.
Status codes are managed in groups, indicated by the very first digit (Xyy). Codes starting with "2" (200 to 299) are generally success messages and indicate that the server accepted the request and provided a valid response.
In addition to "200" codes, HTTP has a few other number ranges reserved for additional information or error message.
- 100 - 199, for general information hints
- 300 - 399, for request redirections
- 400 - 499, for client-side errors, for example missing authentication or a badly formatted request
- 500 - 599, for server-side errors
While the status code really is one of the most important details in an HTTP response, the response headers will also provide crucial additional information.
HTTP response headers
Response headers follow the same principle as their request counterparts, with the obvious difference, that they are response related.
For example, response headers provide
- details on the used server software -
Server - the MIME type of the content we are receiving -
Content-Type
Next, again a quick break with the same delimiter line that we also encountered with the request. So just one single empty line and we are already off to the response body.
The response body
This, as well, is very similar in concept to the request body. It essentially contains the payload of the response, which
Just like the request body, its encoding format is also specified in the Transfer-Encoding header of the response.
Response summary
Let's recap on responses as well. They are the second part in an HTTP exchange and what the server sends to the client in - no pun intended - response to the client's original request.
Among other metadata, this usually includes the resource (e.g. an image or a web page) the client requested.
HTTP Versions
You may have noticed, that we have used HTTP 1.1 so far in our examples. How come, when there are already much newer versions out there?

Truth be told, HTTP 1.1, being a text-based protocol, is a lot more suited for demonstrating the protocol's fundamental concepts than its more modern, binary counterparts.
Speaking of version, let's go a bit back in time and take a history lesson on HTTP.
A brief history of HTTP
0.9 - HTTP started off with version 0.9 in 1991. It only supported the GET method at that point and was really intended only to «get» data (i.e. an HTML document) from a server.
1.0 - Five years later, in '96, HTTP 1.0 was announced and it was a major upgrade and introduced eleven other HTTP methods (e.g. POST and PUT). You can find a memo from back then at https://www.w3.org/Protocols/HTTP/HTTP2.html.
1.1 - Just a year later, in '97, HTTP 1.1 was already announced and it was a game changer. That version introduced features which became the very cornerstones of the modern web (e.g. virtual hosting) and it should stay with us for the next 18 years, until 2015 and HTTP 2.
2.0 - Eighteen years after 1.1, we got HTTP 2.0 and by switching to a binary protocol (as opposed to HTTP's traditional textual approach) and introducing network frames, it allowed for vastly improved request concurrency and pipelining. While still supporting unencrypted connections, all mainstream implementations de-facto require encryption.
3.0 - Fast forward seven years, to 2022, and we got HTTP 3.0. On a semantics level, it is actually pretty similar to 2.0. However, by substituting TCP with UDP, it further improved network performance, albeit re-implementing some TCP logic. This version also abandoned unencrypted connections altogether and imposed protocol-level encryption by default.
While 0.9 and 1.0 marked the beginnings of HTTP's wild journey, neither version is widely used any more. Interestingly, HTTP 1.1 still enjoys broad support, even if HTTP 2.0 and, most recently, 3.0 are certainly becoming more and more mainstream. That is partially because of lots of legacy code, but also due to HTTP 1.1 being partially easier to handle because of its less complex request structure (no binary protocol, only text). Let's give this a quick run.
Running Your Own HTTP Request
There are plenty of command line tools, which you can use to run a quick HTTP request. Popular ones are curl and Postman, and PowerShell, for example, even has a built-in command, Invoke-WebRequest.
Alternatively, you can also go bare-knuckles. Telnet and Netcat will allow you to do so, right from your shell.
Type the following the command in your shell, to open a connection to example.com on port 80 (the default port for HTTP).
telnet example.com 80
You should be connected after just a moment, at which point we simply type (or paste) our HTTP request as text (remember, HTTP 1.x is purely text-based).
GET / HTTP/1.1
Host: example.com
Let's please not forget our request delimiter and we should be all set. More or less instantly, we should get the following response from example.com
HTTP/1.1 200 OK
Cache-Control: max-age=604800
Content-Type: text/html; charset=UTF-8
Server: ECS (dcb/7F80)
Vary: Accept-Encoding
Content-Length: 1256
<!doctype html>
<html>
<head>
<title>Example Domain</title>
[ lots more of HTML]
That really is it 🥳
Want the same, just on an encrypted connection? Simply use OpenSSL instead of Telnet.
openssl s_client -connect example.com:443 -servername example.com
Encryption you said? I think, that's our cue.
Secure HTTP With SSL and TLS = HTTPS
Do you have this inkling when you are on a website which is on HTTP and where your browser yells at you in big, red letters I-N-S-E-C-U-R-E?
You probably do. Well, these days, HTTPS really is pretty common and while not everything is perfect, it still is far less plaintext than it used to be only five or ten years ago.
ℹ️ Did you know, HTTP was actually one of the first protocols to adopt SSL back in '94 with Netscape?
Still, HTTP per se is always plaintext, there is no built-in encryption per se. Any encryption comes from additional SSL/TLS layers, through which the HTTP request is tunneled. While covering TLS in detail would be a bit outside of the scope of this article, let's still have a quick look.
As mentioned, HTTP itself is always plaintext, however it can use different transport protocols, and that's where encryption comes in. By default, HTTP will use TCP (at least until version 2), in which case data will be sent in plaintext. However, one can switch over to TLS (which typically will use TCP itself), in which case HTTP will immediately make use of the cryptographic nature of the TLS tunnel, and HTTP exchanges will be subsequently securely encrypted on HTTPS.
Serving More Than One Service (Virtual Hosting)
Before HTTP 1.1, it was tricky to run more than one website (not so much services, it was mostly proper sites back then) off of one web server instance.
This was because you could only send a request to the server, but not specify for which instance or hostname it was. So if you ran two sites (i.e. example.com and example.net) on the same IP address, the client could not tell the server which site it meant to request. However, this changed with 1.1 and the Host header.
That header is a crucial part of virtual hosting and allows the client to indicate, which site it actually wants to access, regardless of how many domains or sites the server may be hosting.
💡 Please note, TLS has a similar feature with SNI and its even more secure successor ECH.
Analyzing HTTP Requests with your Browser
Did you know that your browser has a built-in HTTP analyzer and logger?
Just press F12 to open the browser's developer tools and select the Network tab. There, you'll get a full overview of all HTTP requests made by this tab.
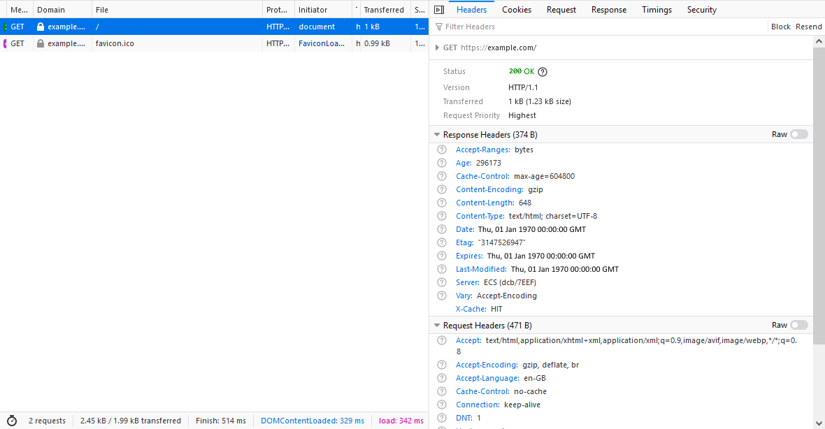
You can examine each request individually, check which request headers were included in the request, and get a summary on the response, including the response headers, a preview of the payload, as well as network timings.
While the other parts of developer tools will assist you with debugging HTML, JavaScript, or CSS specific issues, the Network tab is an indispensable tool for anything HTTP related.
ℹ️ If Firefox is your choice of browser, you can even compile and send custom HTTP requests straight from the Network tab. Just right-click an entry and pick
Resend.
Let's Summarize
In this article we have taken a look at what HTTP is and what it does. We have checked out its protocol in details and learned about requests and responses and their headers, as well as HTTP methods.
One important thing we could not cover was request throttling. This is something you may particularly experience in the context of web crawling and it does very much deserve an entire article on its own.
And, surprise 😆, we actually do have that addressed in our other article on what to do to avoid getting your scraper throttled or blocked. Please check it out.
The following HTTP related articles may also be of interest for you in this context.
- The best Python HTTP clients
- How to send a POST with Python Requests?
- The Best Ruby HTTP clients
- HTTP headers with axios
Last but not least, if you are in for professional web crawling, please feel free to check out our scraping and data extraction SaaS solution. Being designed from the ground up for HTTP crawling and scraping, ScrapingBee - naturally - fully supports HTTP - cookies, redirects, authentication, TLS, you name it.
If you have any other questions on HTTP or how to approach your scraping project best, please do not hesitate a second to contact us. We're happy to help.
Happy curl-ing, happy postman-ing, and - most importantly - happy scraping!
Before you go, check out these related reads:

Alexander is a software engineer and technical writer with a passion for everything network related.
