With more than 199 million reviews of businesses worldwide, Yelp is one of the biggest websites for crowd-sourced reviews. In this article, you will learn how to scrape data from Yelp's search results and individual restaurant pages. You will be learning about the different Python libraries that can be used for web scraping and the techniques to use them effectively.
If you have never heard about Yelp before, it is an American company that crowd-sources reviews for local businesses. They started as a reviews company for restaurants and food businesses but have lately been branching out to cover additional industries as well. Yelp reviews are very important for food businesses as they directly affect their revenues. A restaurant owner told Harvard Business Review:
Yelp review translated to anywhere from a 5 percent to 9 percent effect on revenues
You might want to scrape information about local businesses on Yelp to figure out who your competitors are. You can evaluate how popular they are by scraping their ratings and reviews count. You can also use this data to shortlist neighborhoods that contain the most highly rated restaurants and which neighborhoods are underserved.
In this article you will learn to:
- Fetch Yelp.com search result page
- Extract restaurant information from the Yelp result page
- Extract restaurant information from the Yelp restaurant page
- Extract Yelp information without getting blocked
If you're an absolute beginner in Python, you can read our full Python web scraping tutorial, it'll teach you everything you need to know to start!
Fetching Yelp.com search result page
This is what a typical search result page looks like on Yelp. You can access this particular page by going to this URL.
Go ahead and create a new file called scraper.py inside a new folder called yelp_scraper. This file will contain all of the Python code for this project:
$ mkdir yelp_scraper
$ touch yelp_scraper/scraper.py
You will be using three libraries: re (regular expressions), Requests, BeautifulSoup.
- Requests will help you in downloading the webpage in Python
- BeautifulSoup will help you in extracting data from the HTML
- Regular expressions will assist you in using some advanced data extraction techniques in BeautifulSoup
re comes by default with Python but you will have to install Requests and BeautifulSoup. You can do so easily by running this PIP command in the terminal:
$ pip install beautifulsoup4 requests
A typical website is made up of HTML (HyperText Markup Language). This is what a server responds with when you open a URL in the browser. You can download the same HTML using requests. Open up the scraper.py file and type in the following code:
import requests
url = "https://www.yelp.com/search?find_desc=Restaurants&find_loc=Seattle%2C+WA%2C+United+States"
html = requests.get(url)
print(html.text)
Running this code should print a big chunk of text in your terminal window. This is HTML and you will be parsing the data from this HTML output in just a bit.
How to extract restaurant information from the Yelp result page
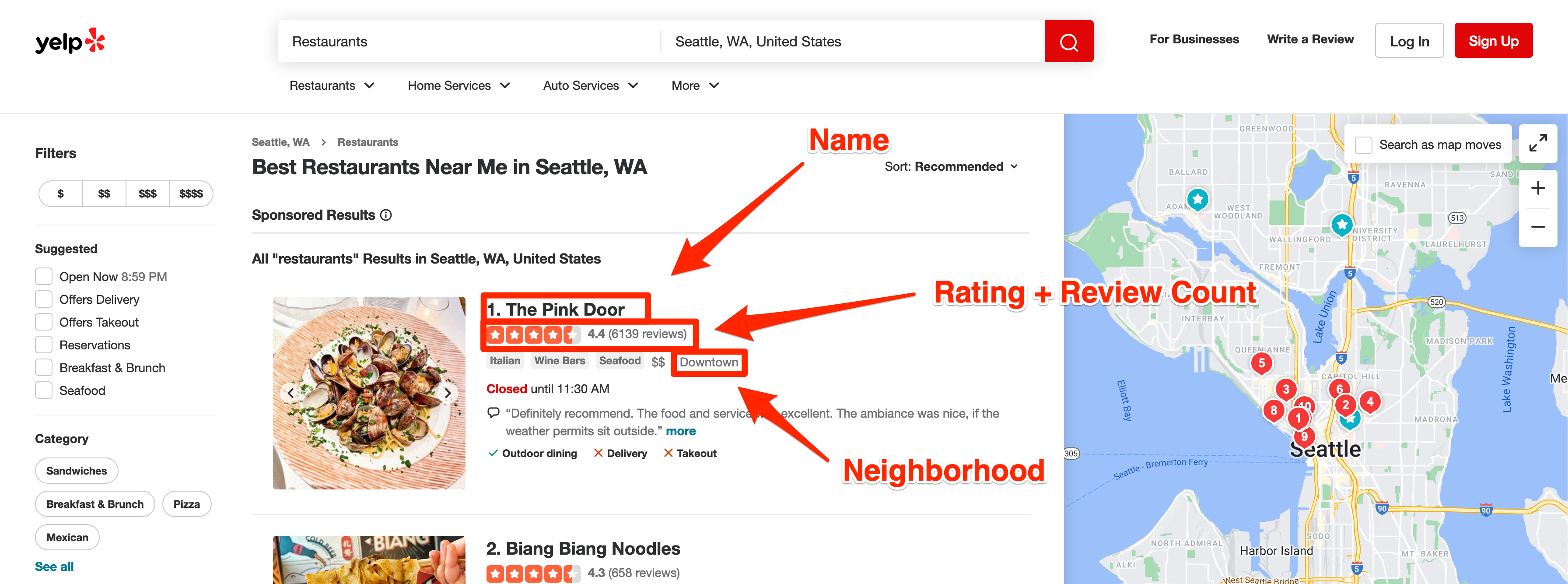
Before you continue, it is important to finalize what data you need to extract. This article will focus on extracting the following restaurant data from the search result page:
- Name
- Rating
- Review count
- Neighborhood
- Restaurant page URL
The image below shows the annotated result page highlighting where all of this information is visually located:
You will be using BeautifulSoup for HTML parsing and data extraction in most web scraping tasks. It is not the only library for this job but it has a very powerful and easy-to-use API that makes it the default choice for most programmers.
If you followed the installation instructions at the beginning, you should already have BeautifulSoup installed. Before you can use it though, you need to explore the HTML returned by Yelp and figure out which HTML tags contain the data you need to extract.
As you will soon learn, you won't have to use BeautifulSoup to extract the search results data at all. You will mainly use it to extract data from the individual restaurant pages which we will cover in the second half of this tutorial.
If you observe, every new search query on Yelp refreshes only the results section. The rest of the page stays the same and is not refreshed. This typically suggests that the website is using some sort of an API to query for the results and then updates the page based on that. Luckily, this is true in Yelp's case too.
Open up Developer Tools in your browser of choice and navigate to the Network tab. Developer Tools come by default with most major web browsers and allow you to inspect the HTML of the webpage and also the network requests made by it. Try to search for a new location on Yelp while having the Network tab open and observe the new requests made by the webpage. Hopefully, you will quickly spot a request made to the /search/snippet endpoint:
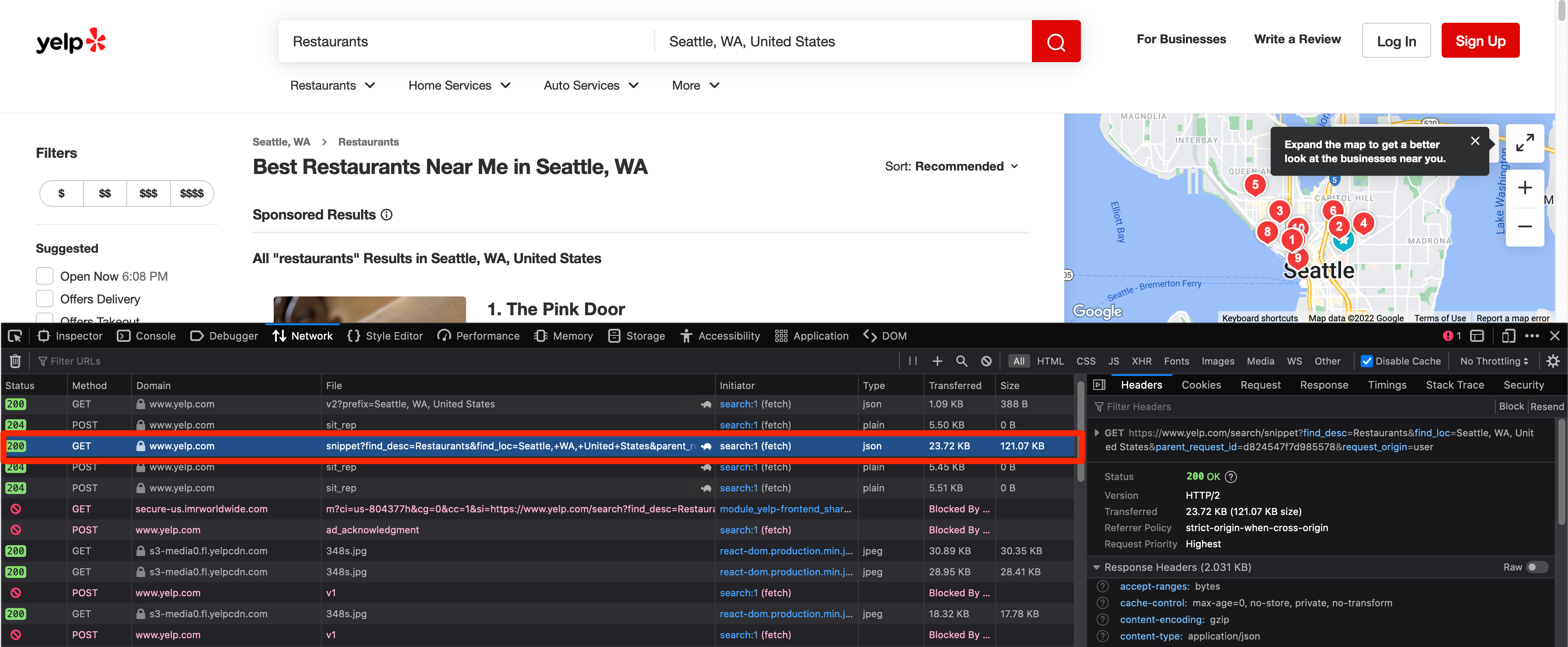
If you open this URL in a new tab, you will notice that it returns a JSON response and contains all the data used to populate the search result section:
Congratulations! You have hit a jackpot! It is almost always easier to extract data from a JSON API response as compared to an HTML response. If you take a closer look at the URL again, you will observe that it contains only a few dynamic parts:
https://www.yelp.com/search/snippet?find_desc=Restaurants&find_loc=Seattle%2C+WA%2C+United+States&parent_request_id=d824547f7d985578&request_origin=user
You can safely get rid of the parent_request_id and the URL should still function correctly. This means that you can plug in whichever city or area you want to search and the rest of the URL should stay and function the same.
Firefox allows you to easily search this JSON response. Type in the name of the first restaurant from the results page in the filter box to figure out which JSON keys contain the data you need:
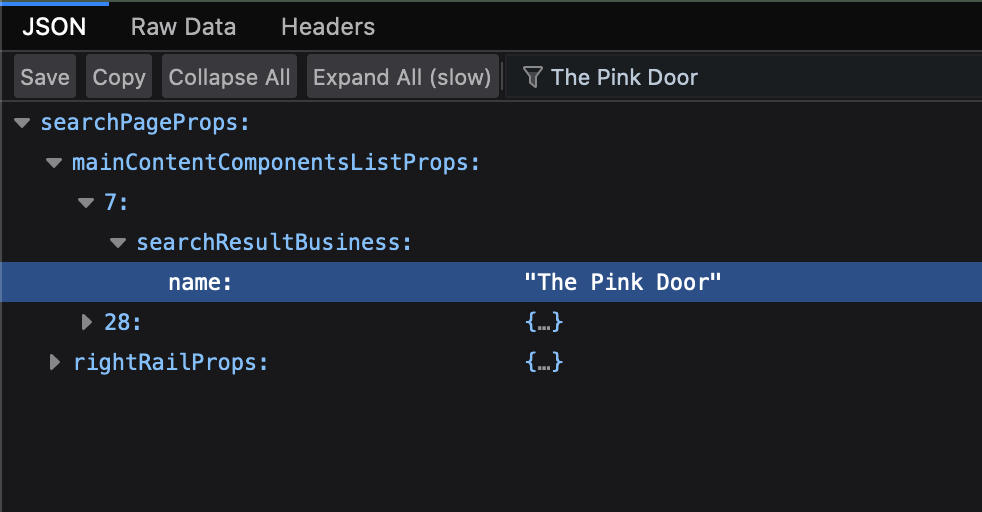
It appears that all the search results are stored as a list in searchPageProps -> mainContentComponentsListProps. There are some additional elements in this list as well that do not represent a search result. You can easily filter those out by considering only those list items that have the searchResultLayoutType key set to iaResult.
Type in the following code in the scraper.py file that will search for restaurants in the Seattle, WA area and list their names:
import requests
search_url = "https://www.yelp.com/search/snippet?find_desc=Restaurants&find_loc=Seattle%2C+WA%2C+United+States&request_origin=user"
search_response = requests.get(search_url)
search_results = search_response.json()['searchPageProps']['mainContentComponentsListProps']
for result in search_results:
if result['searchResultLayoutType'] == "iaResult":
print(result['searchResultBusiness']['name'])
You can again use Firefox to filter out the JSON for neighborhoods, review count, ratings, and business page URL to figure out which keys contain that information. You should end up with the following keys:
- Neighborhoods (list):
result['searchResultBusiness']['neighborhoods'] - Review Count:
result['searchResultBusiness']['reviewCount'] - Rating:
result['searchResultBusiness']['rating'] - Business URL:
result['searchResultBusiness']['businessUrl']
The final scraper.py file should resemble this:
import requests
search_url = "https://www.yelp.com/search/snippet?find_desc=Restaurants&find_loc=Seattle%2C+WA%2C+United+States&request_origin=user"
search_response = requests.get(search_url)
search_results = search_response.json()['searchPageProps']['mainContentComponentsListProps']
for result in search_results:
if result['searchResultLayoutType'] == "iaResult":
print(result['searchResultBusiness']['name'])
print(result['searchResultBusiness']['neighborhoods'])
print(result['searchResultBusiness']['reviewCount'])
print(result['searchResultBusiness']['rating'])
print("https://www.yelp.com" + result['searchResultBusiness']['businessUrl'])
print("--------")
Running this file should result in an output similar to this:
The Pink Door
['Downtown']
6139
4.4
https://www.yelp.com/biz/the-pink-door-seattle-4?osq=Restaurants
--------
Biang Biang Noodles
['First Hill']
658
4.3
https://www.yelp.com/biz/biang-biang-noodles-seattle-2?osq=Restaurants
--------
Tilikum Place Cafe
['Belltown']
2167
4.3
https://www.yelp.com/biz/tilikum-place-cafe-seattle-3?osq=Restaurants
--------
Nue
['Capitol Hill']
1269
4.2
https://www.yelp.com/biz/nue-seattle?osq=Restaurants
--------
Toulouse Petit Kitchen & Lounge
['Lower Queen Anne']
4663
4.0
https://www.yelp.com/biz/toulouse-petit-kitchen-and-lounge-seattle?osq=Restaurants
--------
Biscuit Bitch
['Downtown']
4401
4.1
https://www.yelp.com/biz/biscuit-bitch-seattle?osq=Restaurants
--------
Kedai Makan
['Capitol Hill']
1094
4.3
https://www.yelp.com/biz/kedai-makan-seattle-4?osq=Restaurants
--------
Elliott’s Oyster House
['Waterfront']
3984
3.9
https://www.yelp.com/biz/elliotts-oyster-house-seattle-2?osq=Restaurants
--------
Katsu-ya Seattle
['South Lake Union']
183
4.5
https://www.yelp.com/biz/katsu-ya-seattle-seattle?osq=Restaurants
--------
Ishoni Yakiniku
['Capitol Hill']
147
4.4
https://www.yelp.com/biz/ishoni-yakiniku-seattle?osq=Restaurants
--------
Sweet! Now you know how to extract all the information you need from the search results page. You can use the same method to extract restaurant images, price ranges, business tags, and whatever else you need.
How to extract restaurant information from the Yelp restaurant page
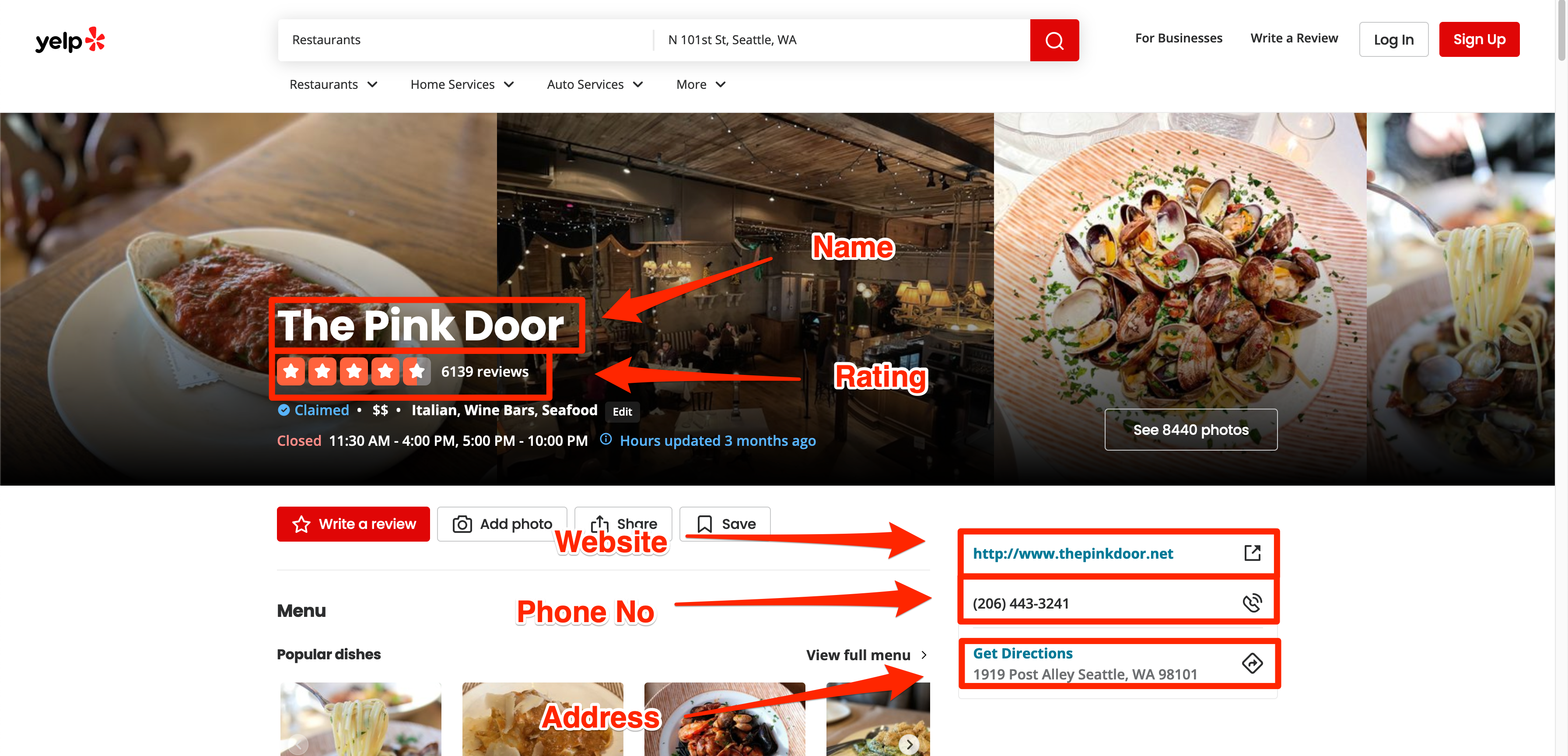
Let's move on and figure out how you can extract some additional information from the dedicated restaurant pages on Yelp. This section will cover the extraction of:
- Name
- Rating
- Website
- Phone No
- Address
The image below shows where all of this information is visually located on a restaurant page. You can access this exact page at this URL.
Unlike the search results, this page does not rely on a JSON API. The data comes embedded in the HTML response and you will have to use BeautfulSoup to extract it.
The workflow that most people use for this step is to open the developer tools and figure out which tag contains the required information. I will be showcasing the same workflow. Right-click on the restaurant name and click on inspect.
As you can see, the restaurant name is stored in an h1 tag. Upon further investigation, it seems like this is the first (and only) h1 tag on the page.
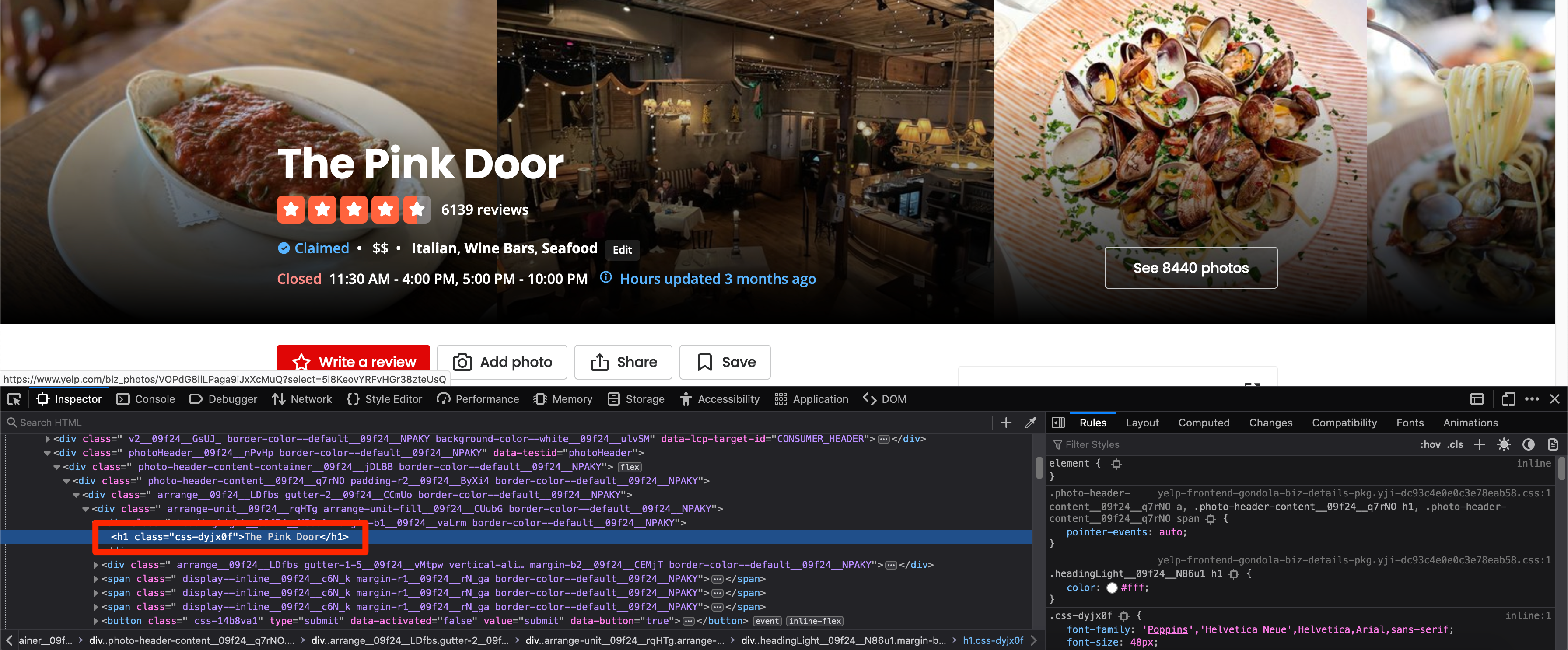
Normally you should try to search for unique class names or IDs that you can use to target a particular HTML tag and extract the data but Yelp randomizes the class names so you can not rely on them here.
Replace the contents of the scraper.py file with the code listed below. It opens up the restaurant page using requests and extracts the restaurant name using BeautifulSoup:
from bs4 import BeautifulSoup
import requests
html = requests.get("https://www.yelp.com/biz/the-pink-door-seattle-4?osq=Restaurants")
soup = BeautifulSoup(html.text)
name = soup.find('h1').text
print(name)
Running the above code should print the name of the restaurant in the terminal:
The Pink Door
Next, inspect the rating stars using developer tools and try to search for something that you can use to extract the rating information. The rating information is stored in the aria-label attribute of a div. This is what the HTML looks like:
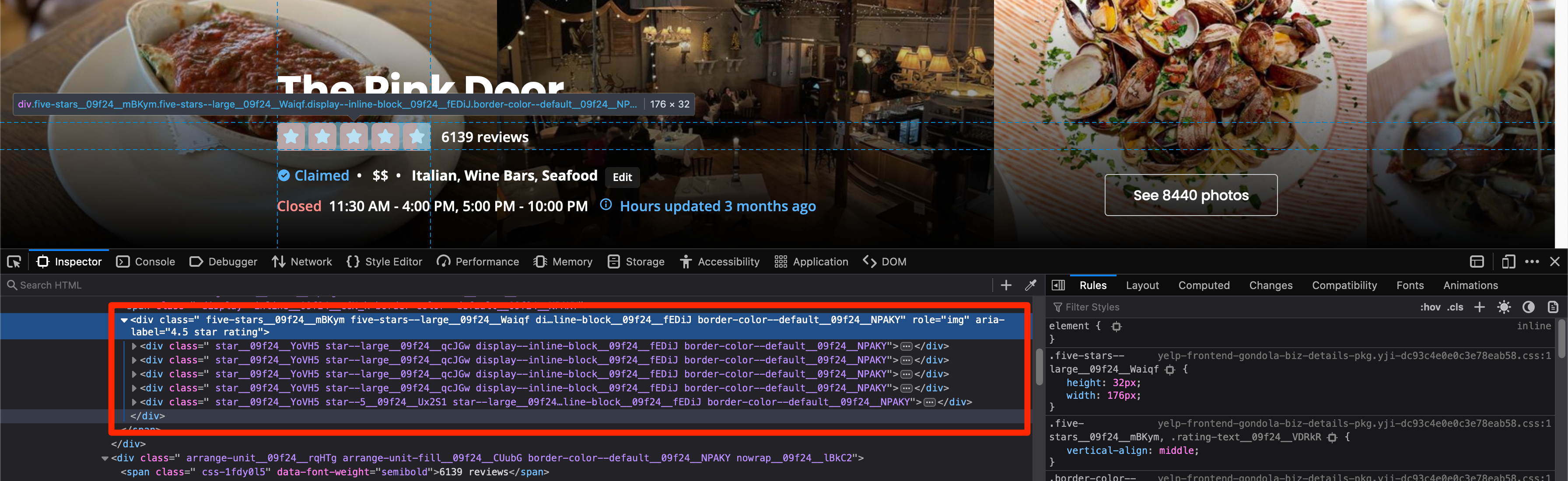
Thankfully, BeautifulSoup allows you to target elements based on arbitrary attributes. It even allows you to target tags based on partial attribute patterns. This means that you can ask BeautifulSoup to target a div in the HTML whose aria-label value contains the partial string star rating. This requires the use of a regular expression pattern.
Add the following code to the scraper.py file to extract the aria-label from this div:
import re
# ...
rating_tag = soup.find('div', attrs={'aria-label': re.compile('star rating')})
rating = rating_tag['aria-label']
print(rating)
This works because the star rating part of the aria-label will remain the same for all restaurants and only the decimal number before it will change.
You can use a similar approach for extracting the review count. The HTML for the review count looks like this:
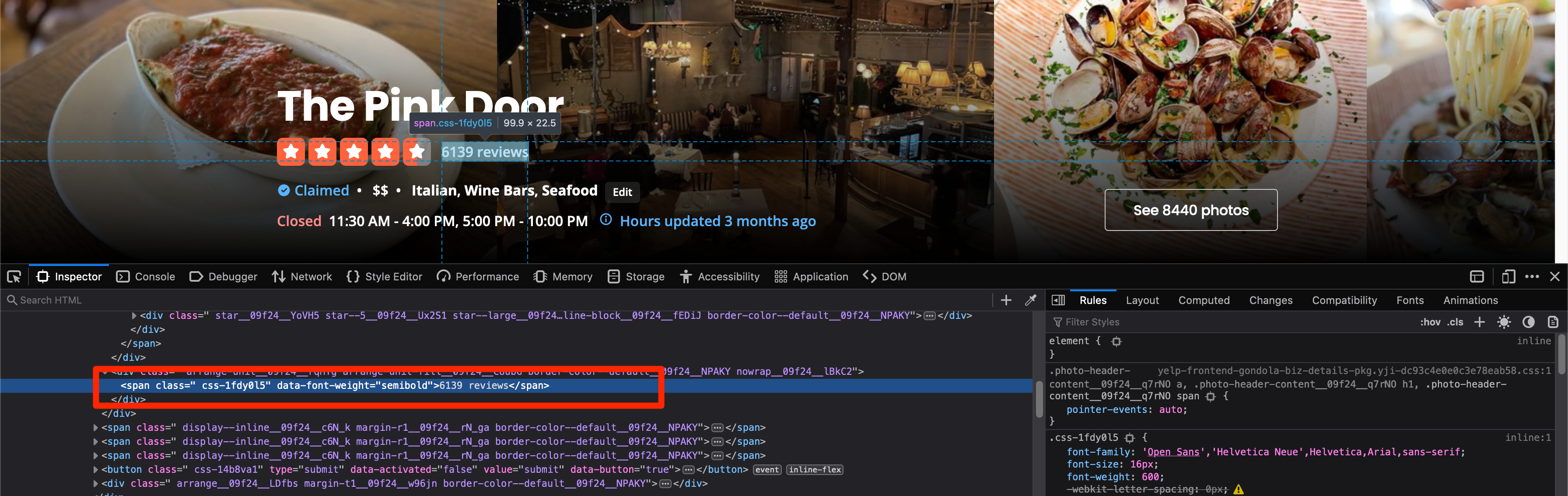
You can target this span based on the text within the span tags. Append the following code to the scraper.py file to do this:
review_count = soup.find('span', text=re.compile('reviews')).text
print(review_count)
You can use a slightly different approach for extracting the business website. Look at the HTML for the section that contains the website URL:
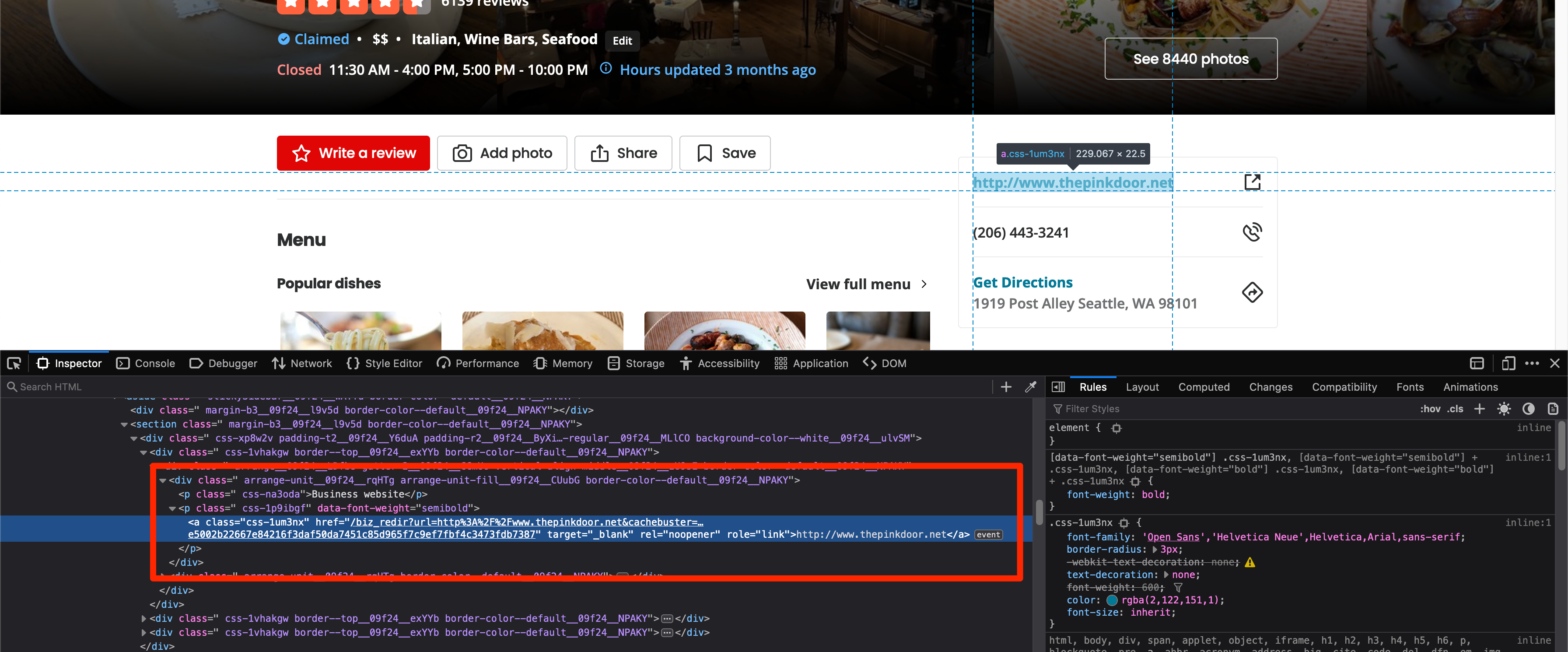
You can target the p tag that contains the Business website string and then extract the text from the sibling p tag. This approach works as there is only one p tag on the page with this exact string and BeautifulSoup allows you to easily access sibling tags using the .next_sibling attribute.
The following code should help you accomplish this:
website_sibling = soup.find('p', text="Business website")
if website_sibling:
website = website_sibling.next_sibling.text
print(website)
There is an if condition because not all businesses have a website listed on their business pages and in that case, the soup.find call will return None and the code will break in the absence of an if condition.
The same approach will work for the phone number as well. This is what the HTML looks like:
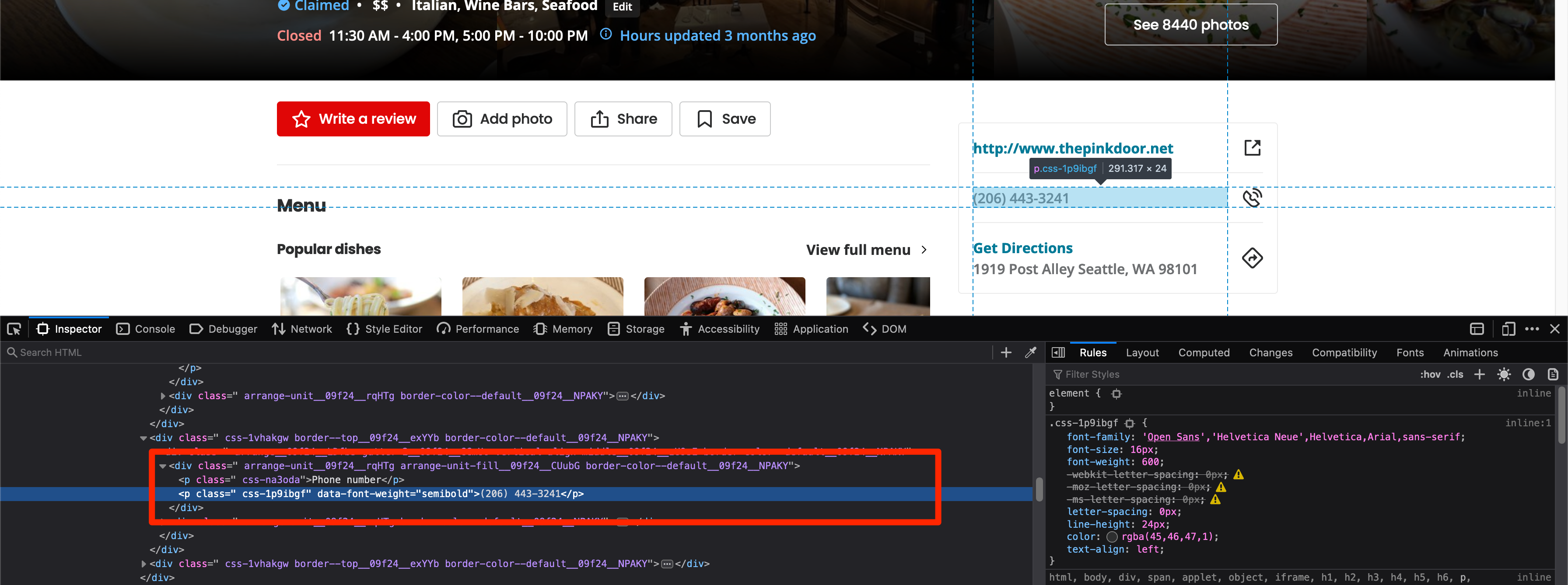
And this is what the extraction code looks like:
phone_no_sibling = soup.find('p', text="Phone number")
if phone_no_sibling:
phone_no = phone_no_sibling.next_sibling.text
print(phone_no)
There is only one small modification for the address extraction. You will have to use the .parent attribute as well. This is what the HTML looks like:
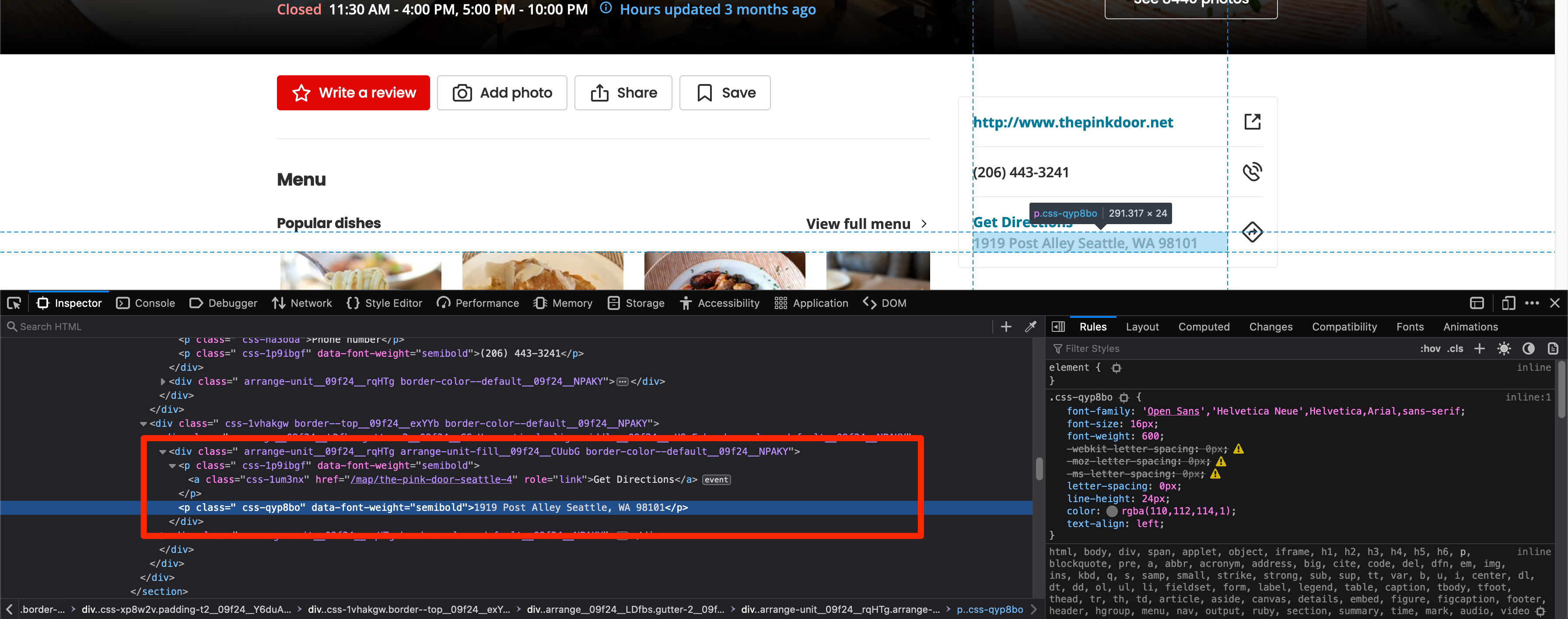
You can target the a tag with the Get Directions text and then select the sibling of the parent. The relevant code for doing that is listed below:
address_sibling = soup.find('a', text="Get Directions")
if address_sibling:
address = address_sibling.parent.next_sibling.text
print(address)
Now you have all the code for extracting the name, review count, rating, website, phone number, and address of a restaurant from its dedicated restaurant page on Yelp. The complete code should resemble this:
import re
from bs4 import BeautifulSoup
import requests
html = requests.get("https://www.yelp.com/biz/the-pink-door-seattle-4")
soup = BeautifulSoup(html.text)
name = soup.find('h1').text
print(name)
website_sibling = soup.find('p', text="Business website")
if website_sibling:
website = website_sibling.next_sibling.text
print(website)
phone_no_sibling = soup.find('p', text="Phone number")
if phone_no_sibling:
phone_no = phone_no_sibling.next_sibling.text
print(phone_no)
address_sibling = soup.find('a', text="Get Directions")
if address_sibling:
address = address_sibling.parent.next_sibling.text
print(address)
rating_tag = soup.find('div', attrs={'aria-label': re.compile('star rating')})
rating = rating_tag['aria-label']
print(rating)
review_count = soup.find('span', text=re.compile('reviews')).text
print(review_count)
A successful run of the code should print this in the terminal:
The Pink Door
http://www.thepinkdoor.net
(206) 443-3241
1919 Post Alley Seattle, WA 98101
4.5 star rating
6140 reviews
Avoid getting blocked with ScrapingBee
There are a few caveats I didn't discuss in the previous section. The biggest one is that if you run your scraper every so often, Yelp might block it. Most companies have protections in place to figure out when a request is made by a script and no simply setting an appropriate User-Agent string is not going to help you bypass that. You will have to use rotating proxies and automated captcha-solving services. This can be too much to handle on your own and luckily there is a service to help with that: ScrapingBee.
You can use ScrapingBee to extract information from whichever page you want and ScrapingBee will make sure that it uses rotating proxies and solves captchas all on its own. This will let you focus on the business logic (data extraction) and let ScrapingBee deal with all the grunt work.
Let's look at a quick example of how you can use ScrapingBee. First, go to the terminal and install the ScrapingBee Python SDK:
$ pip install scrapingbee
Next, go to the ScrapingBee website and sign up for an account:
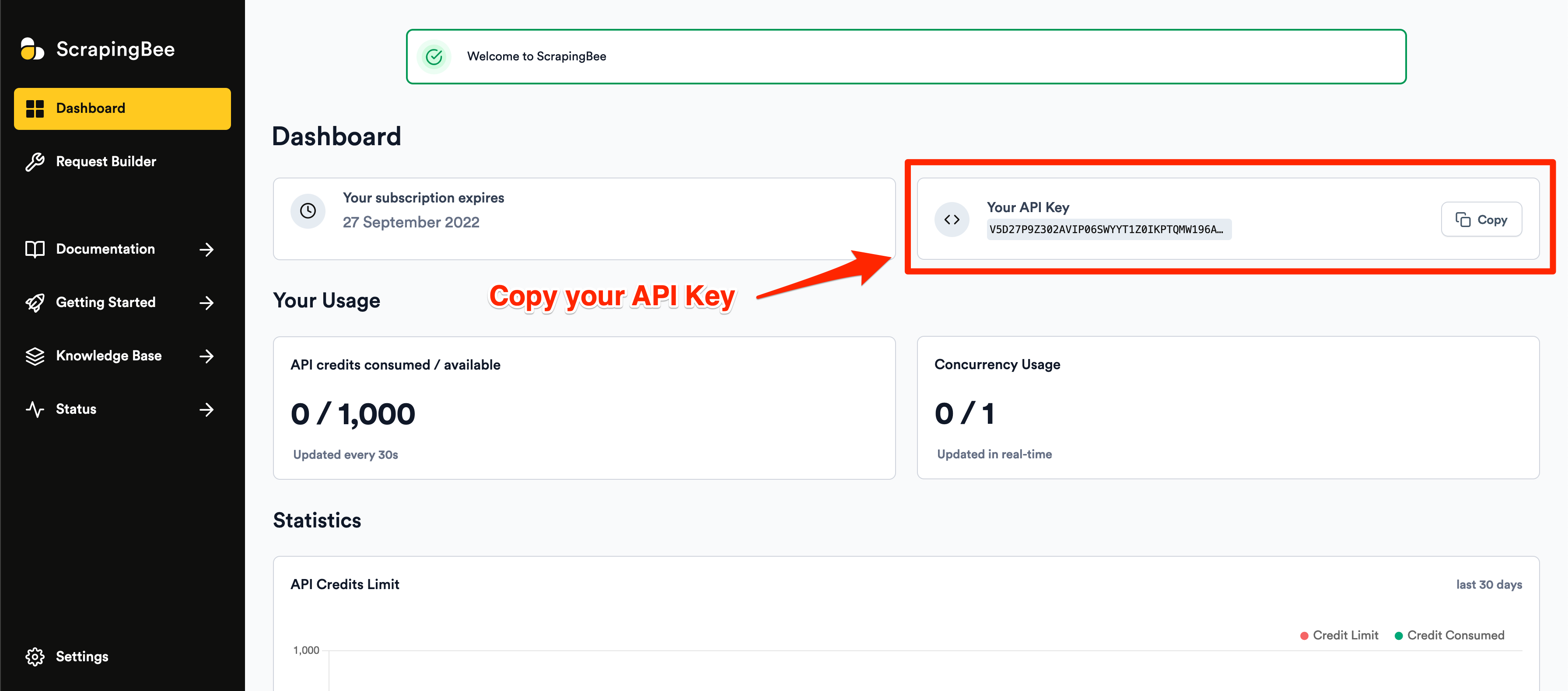
After successful signup, you will be greeted with the default dashboard. Copy your API key from this page and start writing some code in a new Python file:
Basic usage of ScrapingBee looks something like this:
import re
from scrapingbee import ScrapingBeeClient
client = ScrapingBeeClient(api_key='YOUR_API_KEY')
url = "https://www.yelp.com/biz/the-pink-door-seattle-4?osq=Restaurants"
response = client.get(url)
if response.ok:
# Do something with the response
Note: Don't forget to replace YOUR_API_KEY with your API key from ScrapingBee.
The code above asks ScrapingBee to send a request to Yelp and return the response. You are free to parse the response however you want. To make things easier, ScrapingBee API is somewhat similar to Requests API and most importantly, ScrapingBee will make sure that you are charged only for a successful response which makes it a really good deal.
Conclusion
I just scratched the surface of what is possible with Python and showed you just a few simple approaches to how you can leverage all the different Python packages to extract data from Yelp. If your project grows in size and you want to extract a lot more data and want to automate even more stuff, you should look into Scrapy. It is a full-fledged Python web scraping framework that features pause/resume, data filtration, proxy rotation, multiple output formats, remote operation, and a whole load of other features.
You can wire up ScrapingBee with Scrapy to utilize the power of both and make sure your scraping is not affected by websites that continuously throw a captcha or try to rate-limit your scraper.
I hope you learned something new today. If you have any questions please do not hesitate to reach out. We would love to take care of all of your web scraping needs and assist you in whatever way possible!

Yasoob is a renowned author, blogger and a tech speaker. He has authored the Intermediate Python and Practical Python Projects books ad writes regularly. He is currently working on Azure at Microsoft.