Kotlin is a modern, cross-platform programming language. It's open source and developed by JetBrains, the team behind IDEs IntelliJ, WebStorm, and PyCharm. Kotlin is JVM-compatible and fully interoperable with Java. It has many features, including null safety, extension functions, higher-order functions, and coroutines.
Released in 2011, the language has quickly risen to prominence and is currently used by over 5 million developers across mobile, desktop, and backend. In 2017, Google made Kotlin a first-class language for developing Android apps.
In this guide, you'll learn how to perform web scraping using this powerful and versatile programming language. The article covers the tools and techniques for performing web scraping on static websites as well as on more dynamic websites such as single-page applications (SPAs).

💡 Interested in web scraping with Java? Check out our guide to the best Java web scraping libraries
Prerequisites
To follow along with this tutorial, you'll need the following:
- A recent version of the Java Development Kit (JDK) installed
- A suitable IDE
- Gradle installed (you can also use Maven, but examples in this tutorial use Gradle)
Scraping Static Pages
In this section, you'll learn how to scrape static sites using the Kotlin library skrape{it}. skrape{it} is one of many libraries that allow you to download and parse websites in Kotlin.
To start, create a new Kotlin project. You can do this via your IDE or by running the following commands in Gradle:
mkdir WebScrapingDemo
cd WebScrapingDemo
gradle init --type kotlin-application
After creating the project, you can add the skrape{it} library as a dependency by adding the following to your app/build.gradle.kts file:
dependencies {
implementation("it.skrape:skrapeit:1.2.2")
In this example, you'll be scraping a Wikipedia page that contains a list of all countries in the world. If you scroll down a bit, you'll see a table with a list of sovereign states; that's the part you'll extract. It should look like the following image:
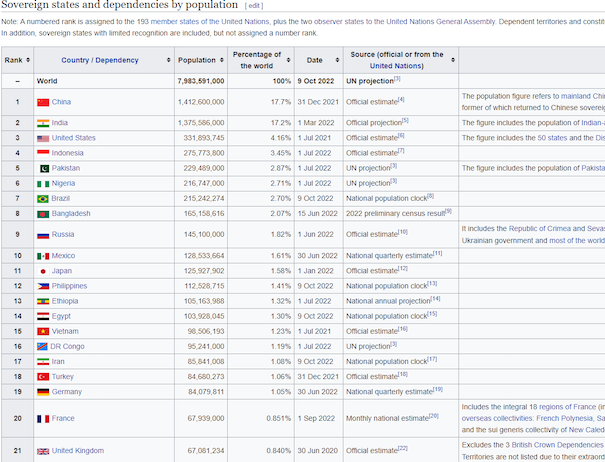
To start, create a data class to hold the countries you'll scrape. You can create a separate file or just add it to your App.kt file. This class is for when you want to persist the scraped data by saving it to a CSV file or a database, for example. Use the following code to create the data class:
// Child class
data class Country(var name: String="", val population: String="")
// Main class
data class ScrapingResult(val countries: MutableList<Country> = mutableListOf(), var count:Int = 0)
After that, create a main function in your App.kt file. This is the entry point of your app. In it, add the following code:
// Start by loading imports
import it.skrape.core.htmlDocument
import it.skrape.fetcher.HttpFetcher
import it.skrape.fetcher.extractIt
import it.skrape.fetcher.skrape
import it.skrape.selects.html5.*
fun main(){
// Set your website URL
val website_url = "https://en.wikipedia.org/wiki/List_of_countries_and_dependencies_by_population"
val countries = skrape(HttpFetcher) {
request {
// Tell skrape{it} which URL to fetch data from
url = website_url
}
extractIt<ScrapingResult> { results ->
htmlDocument{
// Main function where you'll parse web data
}
}
}
}
The function defined above tells skrape{it} to scrape your URL and return the results to the countries variable. It also tells skrape{it} to use the HttpFetcher, which is the default fetcher for making HTTP requests. It also defines the extractIt function where you'll perform web scraping. In this function, you'll have access to the DOM result and can manipulate it to get the data you need. The function has a ScrapingResult return type that is passed as your results object and is assigned to the countries variable. You can use the ScrapingResult object if you wish to persist the returned data.
Finding Data by CSS Selectors
The first thing you should do is select the table. To do this, you need to know what selectors to use. In Chrome, you can press Ctrl + Shift + C (Windows) or Command + Option + C (macOS) to open the Inspector view, or right-click the page and select Inspect from the context menu. You can then click the select icon and hover over the page to see the different elements on the page:
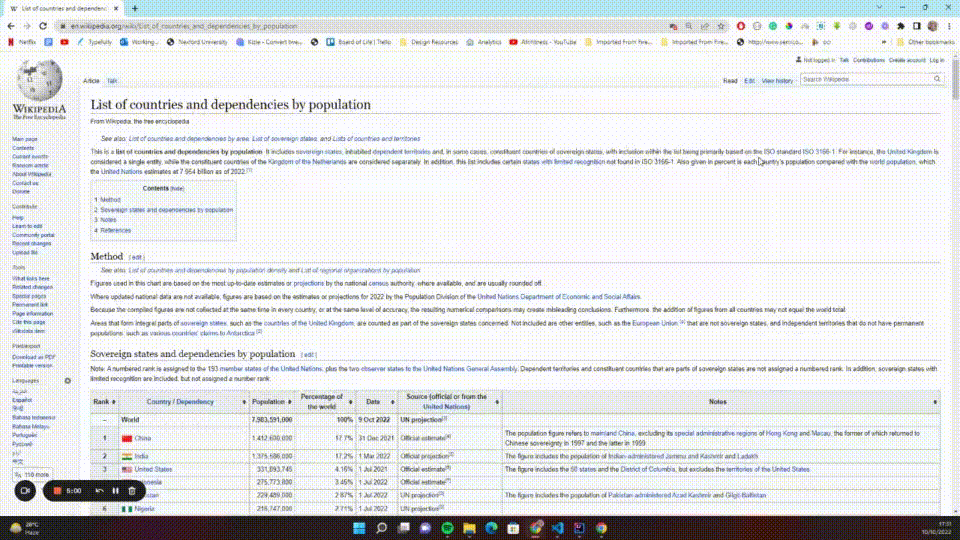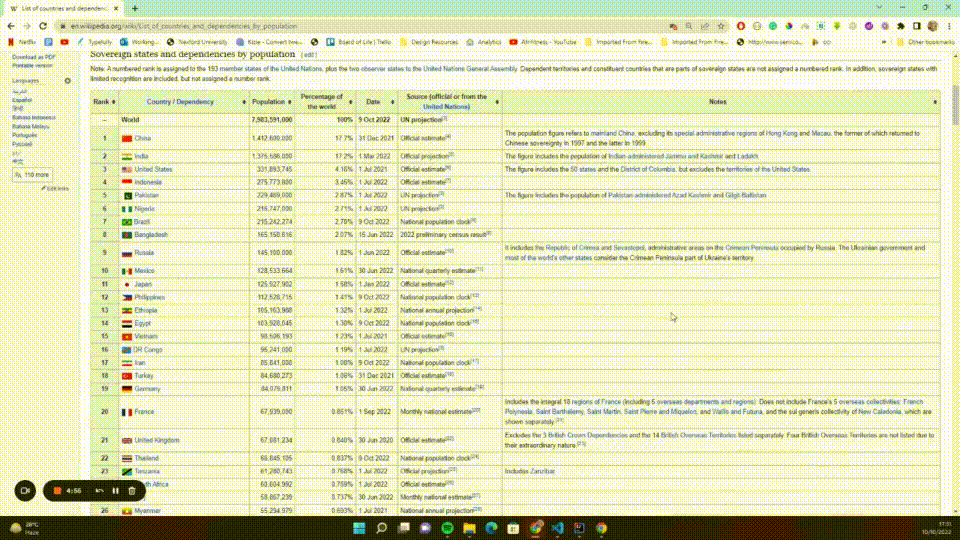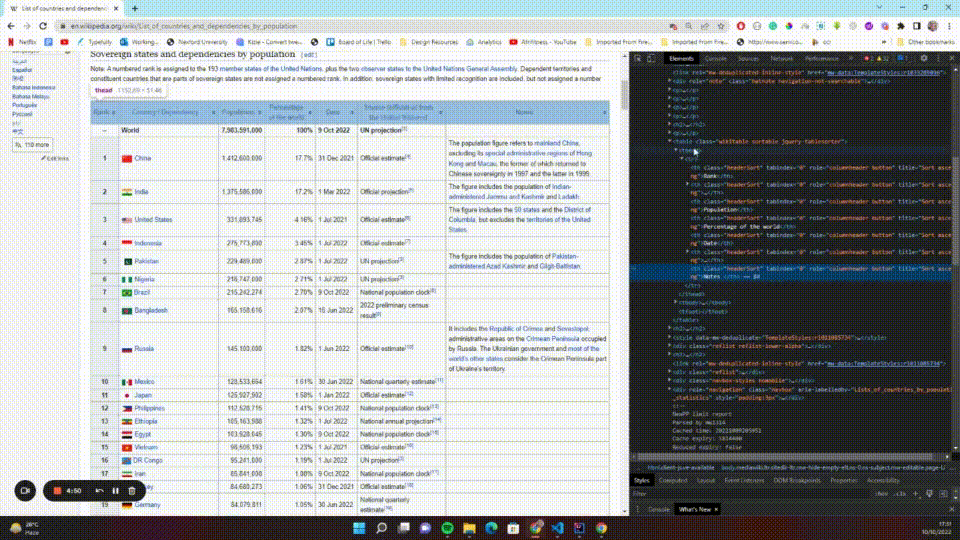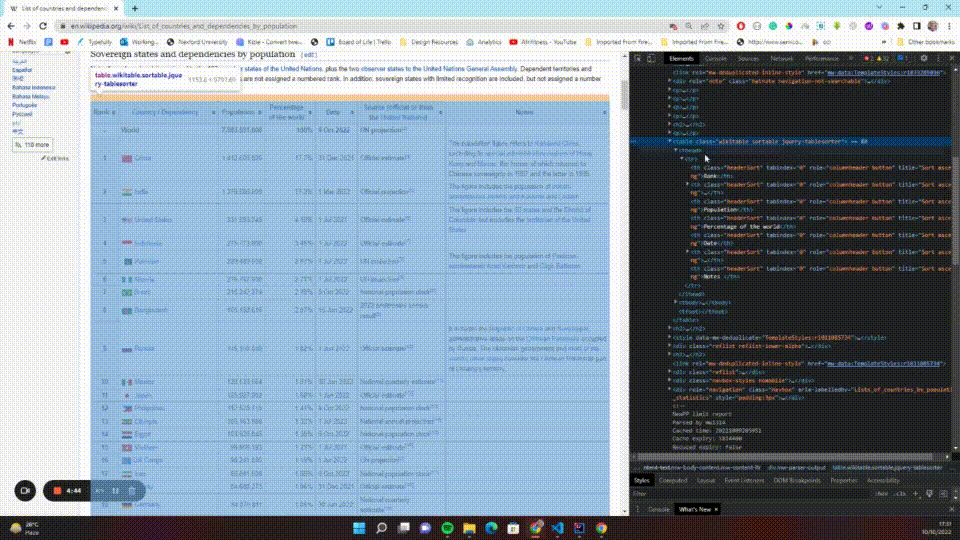
You'll notice that the table has a wikitable class. Using that information, you can select the table, then find each and every table row (<tr>) belonging to that table and return them as a list. You can add the following code to your extractIt, htmlDocument scope:
val countryRows = table(".wikitable") {
tr{
findAll{this}
}
}
This bit of code tells skrape{it} to locate a table with the wikitable class, find all the table rows within that table, and assign them to the countryRows variable. You can print the last item in your countryRows object to see what it looks like using println(countryRows.last()). The result will look something like this:
<tr>
<th>– </th>
<td scope="row" style="text-align:left"><span class="flagicon"><img alt="" src="//upload.wikimedia.org/wikipedia/commons/thumb/8/88/Flag_of_the_Pitcairn_Islands.svg/23px-Flag_of_the_Pitcairn_Islands.svg.png" decoding="async" width="23" height="12" class="thumbborder" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/8/88/Flag_of_the_Pitcairn_Islands.svg/35px-Flag_of_the_Pitcairn_Islands.svg.png 1.5x, //upload.wikimedia.org/wikipedia/commons/thumb/8/88/Flag_of_the_Pitcairn_Islands.svg/46px-Flag_of_the_Pitcairn_Islands.svg.png 2x" data-file-width="1200" data-file-height="600"></span> <a href="/wiki/Demographics_of_the_Pitcairn_Islands" class="mw-redirect" title="Demographics of the Pitcairn Islands">Pitcairn Islands</a> (United Kingdom)</td>
<td style="text-align:right">40</td>
<td style="text-align:right;font-size:inherit"><span data-sort-value="6,993,501,019,574,835,000♠" style="display:none"></span>0% </td>
<td><span data-sort-value="000000002021-01-01-0000" style="white-space:nowrap">1 Jan 2021</span></td>
<td style="text-align:left">Official estimate<sup id="cite_ref-201" class="reference"><a href="#cite_note-201">[200]</a></sup></td>
<td> <p><br> </p> </td>
</tr>
This information makes it easy to extract names and populations from the table rows.
Scraping Nested Data
To extract the required information, you can add the following code:
countryRows
.drop(2) // Remove the first two elements; these are just the table header and subheader
.map{
// Define variables to hold name and population
var name: String =""
var population: String=""
it.a{
findFirst(){ // Find the first <a> tag
name = text // Extract its text (this is the name of the country)
println("Name - $text ")
}
}
it.td{
findSecond(){ // Find the second <td> tag
population = text // Extract its text (this is the population of the country)
println("Population - $text \n")
}
}
results.countries.add(Country(name,population)) // Create a country and add it to the results object
results.count = results.countries.size // Get the number of countries and add it to the results object
}
When you run the code, it will print out each country and its population. You can also use the countries object to save your data to a database, CMS, Excel file, or CSV file. Below is the truncated output of running the code:
Population - World
Name China
Population - 1,412,600,000
Name India
Population - 1,375,586,000
Name United States
Population - 331,893,745
Limits of This Approach
While libraries like skrape{it} make it super simple to scrape static websites, some websites require a bit more work. For example, most websites use JavaScript extensively, which means the JavaScript continues to manipulate the DOM after the initial load. The website might call a REST API to get data and then populate the data into the DOM. This is especially common with SPAs, and scraping is hard when the data you get from the HTTP request differs from what is visible in the browser.
Scraping Dynamic Pages
There are a couple of solutions for scraping dynamic pages. The skrape{it} library used earlier provides a BrowserFetcher, which tries to replicate how the browser loads data and executes JavaScript before presenting you with the result. However, the best way to scrape dynamic data is to use a headless browser. This method runs your browser in the background and allows you to manipulate the results. Another advantage of using a headless browser is that you can perform actions—like clicking buttons or hovering over links—exactly like you would in the browser.
This section demonstrates how you can scrape a dynamic page using Selenium, a popular browser automation library. To add it to your project, you can include the following in the dependencies section of your Gradle file:
implementation("org.seleniumhq.selenium:selenium-java:4.5.0")
Next, this section replicates this Groovy tutorial for scraping Twitter but uses Kotlin as its programming language instead of Groovy. In this example, you'll search Twitter for the top Web3 tweets and save them to a list.
First, download ChromeDriver, a tool that allows Selenium to run a headless version of Chrome. This tool will enable you to navigate to web pages, enter input, click buttons, and execute JavaScript code. After downloading it, you can add it to your project. For this tutorial, it's been added under app/src/main/resources/.
Create a new file called DynamicScraping.kt. In it, create a main function with the following code to set the location of your web driver:
// Define your driver's location; you can substitute the one given if yours is different
val driverLocation = "app/src/main/resources/chromedriver.exe"
System.setProperty("webdriver.chrome.driver", driverLocation);
Now that you've set the driver's location, you can start scraping. To query all tweets on Web3, you need to visit https://twitter.com/search?q=web3, which tells Twitter to query Web3 tweets with q=web3:
val driver = ChromeDriver()
driver.get("https://twitter.com/search?q=web3") // Load the query
If you navigate to the URL, you'll notice that the page sometimes takes time to load the actual tweets. You can tell Selenium to delay giving you the results using the following code:
WebDriverWait(driver, Duration.ofSeconds(10)).until(
ExpectedConditions.presenceOfElementLocated(
By.cssSelector(
"main section"
)
)
)
This code tells Selenium to wait until the main section is loaded.
After it's loaded, your page will contain tweets. Proceed to scrape the results:
val links: MutableList<String> = mutableListOf() // Create a list to hold tweets
while( links.size< 10){ // Repeat loop until you have at least 10 tweets
val l = driver.findElements(By.xpath("//div[@data-testid=\"cellInnerDiv\"]//time/..")) // Find the tweets container
for (e in l) {
if (e.getAttribute("href")!=null){ // Look for the link attribute
links.add(e.getAttribute("href")) // If present, add it to the links list
}
}
driver.findElement(By.cssSelector("body")).sendKeys(Keys.PAGE_DOWN) // Find the body tag and press the down key to simulate scrolling
sleep(1500) // Sleep to allow the client to load new tweets
}
The above code snippet first gets the container for the tweets using XPath, an advanced syntax for navigating and querying the DOM. It then loops through all the elements to find one with an href element. When it finds one, it extracts the link from it. After iterating through all the elements, it presses the page down key to simulate scrolling and repeats until you have at least ten links.
Finally, you can call run the following code:
driver.quit(); // Closes the Selenium session
println(links); // Prints out all the links
The sample output is below:
[https://twitter.com/businessline/status/1582778630140481537, https://twitter.com/CoinDesk/status/1582498204167196672, https://twitter.com/HomaGames/status/1582467505548730368, https://twitter.com/Web_3space/status/1582092755194740736, https://twitter.com/businessline/status/1582778630140481537, https://twitter.com/Web_3space/status/1582092755194740736]
If you got lost anywhere along this tutorial, you can view and download the complete code on GitHub.
Conclusion
Kotlin is a powerful programming language with multiple use cases. In this tutorial, you learned how to use it to scrape data from the web. You learned the basics of web scraping and how to utilize Kotlin libraries such as skrape{it} and Selenium to get valuable data from pages that do not provide an API.
You learned about some challenges associated with web scraping, such as scraping dynamic content. In the real world, there are many other issues when scraping data. If you prefer not to have to deal with rate limits, proxies, user agents, and browser fingerprints, please check out our no-code web scraping API. Did you know that the first 1,000 calls are on us?

