C# is rather popular as backend programming language and you might find yourself in need of it for scraping a web page (or multiple pages). In this article, we will cover how to scrape a website using C#. Specifically, we'll walk you through the steps on how to send the HTTP request, how to parse the received HTML document with C#, and how to access and extract the information we are after.
As we mentioned in other articles, this will work beautifully as long as we scrape server-rendered/server-composed HTML. The moment we are dealing with single-page applications, or anything else that heavily relies on JavaScript, things become a lot more complicated. This is what we will discuss in the second part of this article, where we will have an in-depth look at PuppeteerSharp, Selenium WebDriver for C#, and Headless Chrome.
Note: This article assumes that the reader is familiar with C# and ASP.NET, as well as HTTP request libraries. The PuppeteerSharp and Selenium WebDriver .NET libraries are available to make integration of Headless Chrome easier for developers. Also, this project is using .NET Core 3.1 framework and the HTML Agility Pack for parsing raw HTML.

Part I: Static Pages
Setup
If you’re using C# as a language, you probably already use Visual Studio. This article uses a simple .NET Core Web Application project using MVC (Model View Controller). After you created a new project, use the NuGet package manager to add the necessary libraries used throughout this tutorial.
In NuGet, click the “Browse” tab and then type “HTML Agility Pack” to fetch the package.
Install the package, and then you’re ready to go. This package makes it easy to parse the downloaded HTML and find tags and information that you want to save.
Finally, before you get started with coding the scraper, you need the following libraries added to the codebase:
using HtmlAgilityPack;
using System.Net.Http;
using System.Net.Http.Headers;
using System.Threading.Tasks;
using System.Net;
using System.Text;
using System.IO;
Making an HTTP Request to a Web Page in C#
Imagine you have a project where you need to scrape Wikipedia for information on famous software engineers. It wouldn't be Wikipedia, if it didn't have such an article, right? 😉
That article has a list of programmers with links to their respective own Wikipedia pages. You can scrape the list and save the information to a CSV file (which e.g. you can easily process with Excel) for later use.
This is just one simple example of what you can do with web scraping, but the general concept is to find a site that has the information you need, use C# to scrape the content, and store it for later use. In more complex projects, you can crawl pages using the links found on a top category page.
Still, let's focus on that particular Wikipedia page for our following examples.
Using .NET's HttpClient to Retrieve HTML
.NET already comes with an HTTP client (aptly named HttpClient) in its System.Net.Http namespace, so no need for any external third party libraries or dependencies. Plus, it supports asynchronous calls out of the box.
Using GetStringAsync(), it's relatively straightforward to get the content of any URL in an asynchronous, non-blocking fashion, as we can observe in the following example.
private static async Task<string> CallUrl(string fullUrl)
{
HttpClient client = new HttpClient();
var response = await client.GetStringAsync(fullUrl);
return response;
}
We simply instantiate a new HttpClient object, call GetStringAsync(), "await" its completion, and return the completed task to our caller. We now just add that method to our controller class and we are good to go to call CallUrl() from our Index() method. Let's actually do that.
public IActionResult Index()
{
string url = "https://en.wikipedia.org/wiki/List_of_programmers";
var response = CallUrl(url).Result;
return View();
}
Here, we define our Wikipedia URL in url, it to CallUrl(), and are storing its response in our response variable.
All right, the code to make the HTTP request is done. We still haven’t parsed it yet, but now is a good time to run the code to ensure that the Wikipedia HTML is returned instead of any errors.
For that, we'll first set a breakpoint in the Index() method at return View();. This will ensure that you can use the Visual Studio debugger UI to view the results.
You can test the above code by clicking the “Run” button in the Visual Studio menu:
Visual Studio will stop at the breakpoint and now you can view the current state of the application.
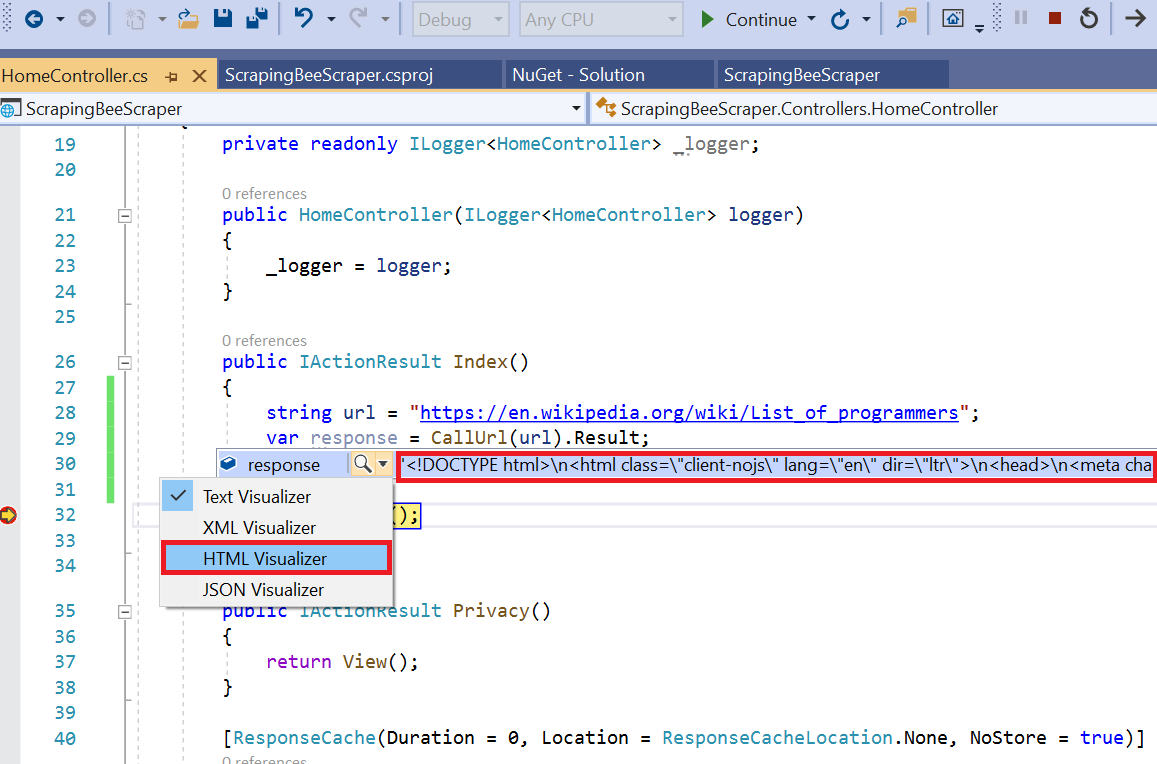
If you pick "HTML Visualizer" from the context menu, you'd be getting a preview of the HTML page, but already by hovering over the variable, we can see that we got a proper HTML page returned by the server, so we should be good to go.
Parsing the HTML
With the HTML retrieved, it's time to parse it. HTML Agility Pack is a popular parser suite and can be easily combined with LINQ as well, for example.
Before you parse the HTML, you need to know a little bit about the structure of the page so that you know which elements to extract exactly. This is where your browser's developer tools will shine once again, as they allow you to analyse the DOM tree in detail.
With our Wikipedia page, we'll notice we've got plenty of link in our Table of Contents, we won't need those. There are also quite a few other links (e.g. the edit links), which we do not necessarily need for our data set. On a closer look, we notice that all the links, we are interested in, are part of a <li> parent.
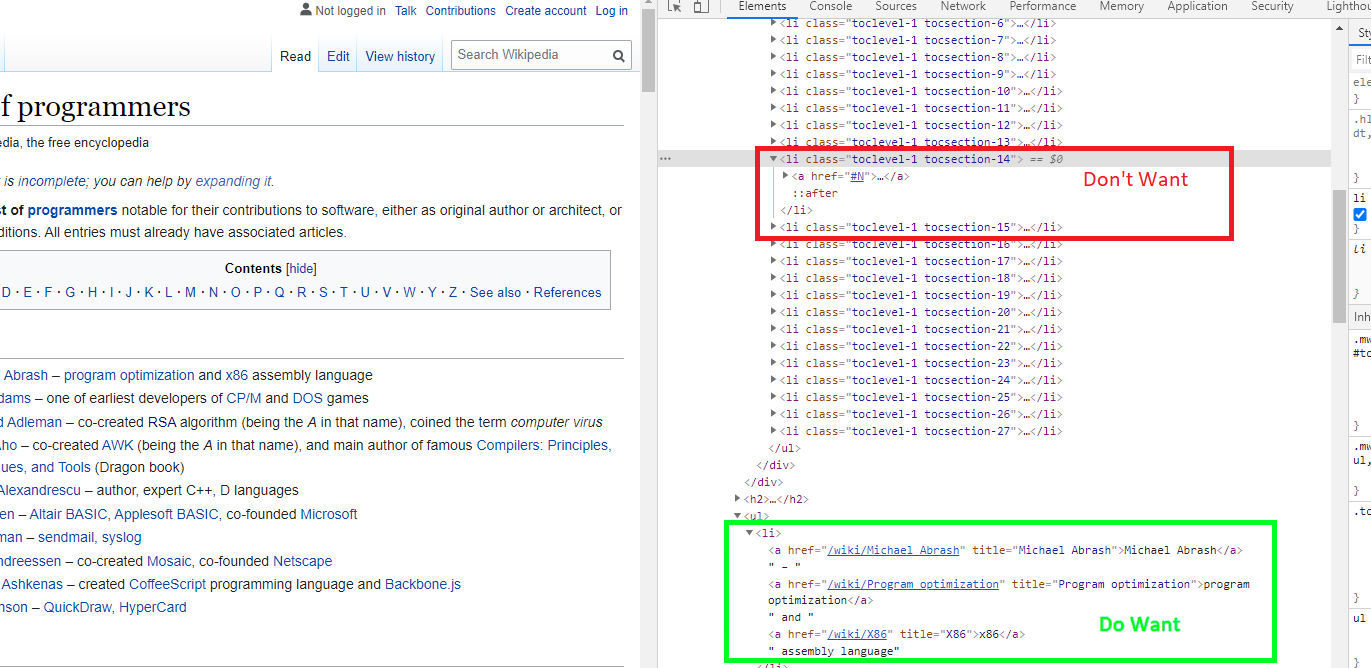
Based on the DOM tree, we have now established that <li>s are not only used for our actual link elements, but also for the page's content table. As we are not really after the content table, we need to make sure we filter out those <li>s and, fortunately, they come with their own distinct HTML classes, so we can simply exclude in our code all <li> elements having tocsection classes.
Time to code! We'll start off by adding another method to our controller class, ParseHtml().
private List<string> ParseHtml(string html)
{
HtmlDocument htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(html);
var programmerLinks = htmlDoc.DocumentNode.Descendants("li")
.Where(node => !node.GetAttributeValue("class", "").Contains("tocsection"))
.ToList();
List<string> wikiLink = new List<string>();
foreach (var link in programmerLinks)
{
if (link.FirstChild.Attributes.Count > 0) wikiLink.Add("https://en.wikipedia.org/" + link.FirstChild.Attributes[0].Value) ;
}
return wikiLink;
}
Here, we first create an instance of HtmlDocument and load the HTML document we earlier received from CallUrl(). We now have a proper DOM representation of our document and can proceed with scraping that document.
- We get all
<li>children withDescendants() - We use LINQ (
Where()) to filter out elements which use mentioned HTML classes - We iterate (
foreach) over our links and save their (relative) URLs as absolute URLs in ourwikiLinkstring list - We return the string list to our caller
XPath
One thing to note, we wouldn't have needed to perform the element selection manually. We did so solely for the sake of the example.
In real-world code, it will be much more convenient to apply an XPath expression. With that, our whole selection logic would fit into a one-liner.
var programmerLinks = htmlDoc.DocumentNode.SelectNodes("//li[not(contains(@class, 'tocsection'))]")
This follows the same logic as our manual selection and will select all (//) <li>s which do not contain said class (not(contains())).
💡 If you like to find out more about XPath, please check out our lovely tutorial on How to Use XPath for Web Scraping.
Exporting Scraped Data to a File
So far, we have fetched the HTML document from Wikipedia, parsed it into a DOM tree, and managed to extract all the desired links and we now have a generic list of links from the page.
Now, we want to export the links to a CSV file. We'll add another method named WriteToCsv() to write data from the generic list to a file. The following code is the full method that writes the extracted links to a file named “links.csv” and stores it on the local disk.
private void WriteToCsv(List<string> links)
{
StringBuilder sb = new StringBuilder();
foreach (var link in links)
{
sb.AppendLine(link);
}
System.IO.File.WriteAllText("links.csv", sb.ToString());
}
The above code is all it takes to write data to a file on local storage using native .NET framework libraries.
That's all, folks. Promised!
But to recap, let's also post the HomeController code in its full glory:
using System;
using System.Collections.Generic;
using System.Diagnostics;
using System.Linq;
using Microsoft.AspNetCore.Mvc;
using Microsoft.Extensions.Logging;
using HtmlAgilityPack;
using System.Net.Http;
using System.Net.Http.Headers;
using System.Threading.Tasks;
using System.Net;
using System.Text;
using System.IO;
namespace ScrapingBeeScraper.Controllers
{
public class HomeController : Controller
{
private readonly ILogger<HomeController> _logger;
public HomeController(ILogger<HomeController> logger)
{
_logger = logger;
}
public IActionResult Index()
{
string url = "https://en.wikipedia.org/wiki/List_of_programmers";
string response = CallUrl(url).Result;
var linkList = ParseHtml(response);
WriteToCsv(linkList);
return View();
}
[ResponseCache(Duration = 0, Location = ResponseCacheLocation.None, NoStore = true)]
public IActionResult Error()
{
return View(new ErrorViewModel { RequestId = Activity.Current?.Id ?? HttpContext.TraceIdentifier });
}
private static async Task<string> CallUrl(string fullUrl)
{
HttpClient client = new HttpClient();
ServicePointManager.SecurityProtocol = SecurityProtocolType.Tls13;
client.DefaultRequestHeaders.Accept.Clear();
var response = client.GetStringAsync(fullUrl);
return await response;
}
private List<string> ParseHtml(string html)
{
HtmlDocument htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(html);
var programmerLinks = htmlDoc.DocumentNode.Descendants("li")
.Where(node => !node.GetAttributeValue("class", "").Contains("tocsection"))
.ToList();
List<string> wikiLink = new List<string>();
foreach (var link in programmerLinks)
{
if (link.FirstChild.Attributes.Count > 0)
wikiLink.Add("https://en.wikipedia.org/" + link.FirstChild.Attributes[0].Value) ;
}
return wikiLink;
}
private void WriteToCsv(List<string> links)
{
StringBuilder sb = new StringBuilder();
foreach (var link in links)
{
sb.AppendLine(link);
}
System.IO.File.WriteAllText("links.csv", sb.ToString());
}
}
}
Part II: Scraping Dynamic JavaScript Pages
In Part I, the whole scraping was quite straightforward, because we received the full HTML document already from the server and we only had to parse it and pick the data we wanted.
JavaScript has shifted that landscape, however, and sites which primarily rely on JavaScript - in particular, of course, sites made with Angular, React, or Vue.js - can't be scraped in the way we discussed earlier. If you were to use the same approach, you wouldn't get much HTML back, but mostly just JavaScript code. You need to actually execute that JavaScript code to get to the data you want.
Dynamic JavaScript isn’t the only issue. Some sites detect if JavaScript is enabled or evaluate the user agent sent by the browser. The user agent header is part of the HTTP request and tells the web server the type of browser being used to access pages (e.g. Chrome, Firefox, etc). If you use web scraper code, it typically sends some default user agent and many web servers will return different content based on the user agent. Some web servers will use JavaScript to detect when a request is not from a human user.
💡 Check out our great article on Web Scraping without getting blocked for more details on that subject.
You can overcome this issue by using libraries that leverage Headless Chrome to render the page and then parse the results. Following, we'll be talking about two libraries freely available from NuGet that can be used in conjunction with Headless Chrome to parse results. PuppeteerSharp is the first solution we use that makes asynchronous calls to a web page. The other solution is Selenium WebDriver, which is a common platform for automated testing of web applications, but can also serve perfectly fine for scraping task.
Using PuppeteerSharp with Headless Chrome
Similar to our previous example, we start again with our controller's Index() method, but need fewer "additional" methods this time, as Puppeteer already covers quite a few of the areas we handled ourselves earlier.
public async Task<IActionResult> Index()
{
string fullUrl = "https://en.wikipedia.org/wiki/List_of_programmers";
List<string> programmerLinks = new List<string>();
var options = new LaunchOptions()
{
Headless = true,
ExecutablePath = "C:\\Program Files (x86)\\Google\\Chrome\\Application\\chrome.exe"
};
var browser = await Puppeteer.LaunchAsync(options, null, Product.Chrome);
var page = await browser.NewPageAsync();
await page.GoToAsync(fullUrl);
var links = @"Array.from(document.querySelectorAll('li:not([class^=""toc""]) a')).map(a => a.href);";
var urls = await page.EvaluateExpressionAsync<string[]>(links);
foreach (string url in urls)
{
programmerLinks.Add(url);
}
WriteToCsv(programmerLinks);
return View();
}
Please do not forget to install and import Puppeteer with NuGet and
using PuppeteerSharp;
Instead of sending the HTTP request, parsing the HTML, and extracting the data ourselves, we really only relied on Puppeteer and Chrome here. The first basic steps were:
- Defining a couple of options with the new
LaunchOptionsclass (among them, the path to our browser instance ‼️) - Launching a new browser instance with
Puppeteer.LaunchAsync()and got a fresh page object withNewPageAsync() - Loading https://en.wikipedia.org/wiki/List_of_programmers with
GoToAsync()
So far, so good, now the real magic.
Instead of handling the whole element selection ourselves, we now simply passed the following JavaScript snippet to EvaluateExpressionAsync(), which kindly did all the heavy lifting for us.
Array.from(document.querySelectorAll('li:not([class^="toc"]) a:first-child')).map(a => a.href);
If you are familiar with JavaScript, you will notice that we ran querySelectorAll(), with the CSS selector li:not([class^="toc"]) a to get the same set of elements from our first example, and eventually used map() to switch the element values to their respective link attributes (href).
Now we only had to collect our links and write them to the CSV file with WriteToCsv().
Done, thanks Puppeteer!
Using Selenium with Headless Chrome
If Puppeteer is not an option, you could also check out Selenium WebDriver. Selenium is a very popular platform for automated testing of web applications and works quite similar to Puppeteer. In addition to Puppeteer, it also allows you to perform typical user actions (e.g. mouse clicks) natively.
For our example, we first need to get over the usual NuGet rituals and install Selenium.WebDriver, as well as well as Selenium.WebDriver.ChromeDriver. The latter is the required browser helper for Chrome, of course there are also helpers for Firefox.
Now, just two more using statements and we can rock'n'roll.
using OpenQA.Selenium;
using OpenQA.Selenium.Chrome;
Now, you can add the code that will open a page and extract all links from the results. The following code demonstrates how to extract links and add them to a generic list.
public async Task<IActionResult> Index()
{
string fullUrl = "https://en.wikipedia.org/wiki/List_of_programmers";
List<string> programmerLinks = new List<string>();
var options = new ChromeOptions()
{
BinaryLocation = "C:\\Program Files (x86)\\Google\\Chrome\\Application\\chrome.exe"
};
options.AddArguments(new List<string>() { "headless", "disable-gpu" });
var browser = new ChromeDriver(options);
browser.Navigate().GoToUrl(fullUrl);
var links = browser.FindElementsByXPath("//li[not(contains(@class, 'tocsection'))]/a[1]");
foreach (var url in links)
{
programmerLinks.Add(url.GetAttribute("href"));
}
WriteToCsv(programmerLinks);
return View();
}
Quite similar to our Puppeteer example, isn't it?
Here we set our browser options with ChromeOptions, instantiated a ChromeDriver object, loaded the page with GoToUrl, and eventually extracted the elements and saved everything, once more, to our CSV file.
As attentive reader you certainly have noticed the technology switch we leisurely introduced. Instead of a CSS selector we used an XPath expression, but don't fret, Selenium supports CSS selectors just as fine.
var links = browser.FindElementsByCssSelector(@"li:not([class^=""toc""]) a:first-child");
Please, also notice that Selenium is not asynchronous, so if you have a large pool of links and actions to take on a page, it will freeze your program until the scraping completes. This is the one of the main differences between Puppeteer and Selenium.
In this tutorial, we haven't covered a bit subject in web scraping: Proxies! Check out our HttpClient proxy tutorial if you want to learn more.
Conclusion
C#, and .NET in general, have all the necessary tools and libraries for you to implement your own data scraper, and especially with tools like Puppeteer and Selenium it is easy to quickly implement a crawler project and get the data you want.
One aspect we only briefly addressed is the different techniques to avoid getting blocked or rate limited by the server. Typically, that is the real obstacle in web scraping and not any technical limitations.
Check out our no-code web scraping API, if you prefer to focus on your data rather than user agents, rate limits, proxies, and JavaScript challenges. Did you know, the first 1,000 API requests are on us?

Jennifer Marsh is a software developer and technology writer for a number of publications across several industries including cybersecurity, programming, DevOps, and IT operations.


