Scraping Amazon can be tricky. I know the struggle. The site changes often, it has built-in protections and isn't exactly fond of being scraped. If you've ever tried going down this road, you've probably ran into roadblocks in the form of CAPTCHAs or empty responses. This tutorial will show you how to scrape Amazon shopping results step by step, bypassing anti-scraping measures with code examples.
We'll demonstrate how to extract product details like names, prices, and links, and how to save this data into a CSV file easily. We'll also learn how to deal with common issues using proxies and other advanced tools. By the end you'll have a working Python script and full understanding of how all this ties together.
Today we'll explore two approaches:
- Traditional scraping — also known as "yer olde scraping" (just joking). Identify and extract elements from the page using CSS selectors.
- AI-powered scraping — using ScrapingBee's AI. Simply describe what you need in plain English, and the tireless algorithm figures out the rest. No need to mess with selectors anymore.
I'd say that the AI method is a great modern solution, but both approaches are viable.
Why scrape Amazon in the first place?
That's a good question! Well, Amazon has a ton of potentially useful data. Prices, reviews, product descriptions... There's a lot you can do with this information! Scraping enables you to automate tasks, analyze trends, or build useful tools.
So, let's quickly cover typical needs:
- Developers — for example, if you're creating a price comparison app or a product tracking tool, you definitely need some fresh data.
- Researchers — you might be studying trends, customer preferences, or product popularity. In this case scraping helps gather large datasets.
- Small businesses or sellers — you'll probably want to keep an eye on your competitors by tracking their prices. Obviously, checking prices manually for hundreds or even thousands of products is not feasible but scraping can do the heavy lifting for you. Of course, you might also be interested in monitoring how your own products perform. For instance, you might want to understand what customers like or dislike about your products, how their reviews change over time, and so on.
- Data enthusiasts — finally, you might be learning data analysis or exploring scraping in general. In this case Amazon offers plenty of real-world data to practice on.
Prerequisites
Before we dive into the coding, let's make sure you have the necessary knowledge and tools. You don't need to be an expert, but basic Python skills like installing packages, writing simple scripts, and using the terminal are very much recommended.
So, here's what you'll need:
- Python installed — I recommend Python 3.9 or above. Run
python --versionorpython3 --versionin your terminal to make sure everything is in order. - A terminal or command-line tool — we'll run commands and scripts here (duh!).
- A code editor — use something you're comfortable with, like VS Code, PyCharm, or even a simple text editor.
Using Poetry for package management
Managing dependencies and virtual environments can become a headache, but Poetry makes it much simpler. It handles everything from installing packages to keeping your project organized therefore I tend to use it quite often these days.
After installing Poetry, create a new folder for your project and initialize it by running:
poetry init
This will walk you through setting up a pyproject.toml file where you'll define your dependencies and project settings.
Amazon's stance on scraping
Let's acknowledge a painful truth: Amazon doesn't like being scraped. They've set up all kinds of annoying protections against it which makes scraping a headache.
Here are some examples:
- Rate limiting — send too many requests too fast, and they'll slow you down or simply block you.
- CAPTCHAs — get ready to deal with CAPTCHAs to prove that you're a human. It becomes increasingly complex as obviously your script is definitely not a human!
- IP blocking — if your requests become suspicious, your IP address might be blocked for some time.
- Dynamic content — some parts of the page might be loaded using JavaScript. This poses a difficulty of its own.
- Changing structure — Amazon's developers are really fond of updating their HTML on a regular basis. If you're writing some CSS or XPath rules then be prepared to tweak it quite often as they might change the class names. It's even more annoying when some class names seem to be generated dynamically.
So yeah, it sounds like a huge pain. But, as you've probably guessed it, I'm bringing these issues up because I know how to overcome these. By the way, if you want more tips on how to scrape without getting blocked, check out my post Web Scraping Without Getting Blocked.
A simple solution to scrape Amazon without being blocked
Scraping Amazon can become problematic with all its anti-scraping defenses. Managing proxies or solving these challenges on your own does take time and effort. That's where a tool like ScrapingBee comes into play. It does the hard work for you: handles IP rotation, bypasses CAPTCHAs, and manages headers.
With ScrapingBee, you can focus on the data, not on the means of obtaining it reliably. Simply send a request to their API, and it handles everything in the background, returning data for you. It's straightforward and suitable for projects of any size.
Getting started with ScrapingBee
- Sign up for a free trial — head over to ScrapingBee and create a free account. You'll get 1000 credits to try it out—no credit card needed.
- Get your API token — once you've signed up, log in to your dashboard and copy your API token. This token is essential for authenticating your API requests.
- Install the ScrapingBee Python client — add the client to your project by running:
poetry add scrapingbee
or if not using poetry:
pip install scrapingbee
- Set up the client in your script — to start using the API, initialize the client in your Python script with the following code:
from scrapingbee import ScrapingBeeClient
client = ScrapingBeeClient(api_key='YOUR_API_KEY')
Replace 'YOUR_API_KEY' with the token you copied from your ScrapingBee dashboard, and you're ready to go.
Quickstart: Full parser code
If you're excited to jump straight into scraping, here's the complete parser code that we'll create step by step in this tutorial. It covers everything: setting up ScrapingBee, sending requests, and saving the scraped data to a CSV file.
Huge credit where credit's due, this awesome Amazon scraper was created by our legendary Support Engineer, Sahil Sunny, who is a master at helping people scrape anything and everything from across the internet, and we'll be walking you through it today. 🚀🌟
import csv
from scrapingbee import ScrapingBeeClient
client = ScrapingBeeClient(
api_key="YOUR_API_KEY"
)
def amazon_shopping_search(
search_query, page=1, sort_by="featured", zip_code=None, domain="com"
):
"""
Scrape Amazon search results using ScrapingBee.
Args:
search_query (str): The product search term.
page (int): Page number for pagination.
sort_by (str): Sorting option (e.g., 'featured', 'price_low_to_high').
zip_code (str, optional): Zip code for location-specific results.
domain (str): Amazon domain to scrape (default: 'com').
Returns:
dict: A dictionary containing search results and metadata.
"""
# Map for sorting options
sort_by_map = {
"featured": "relevanceblender",
"price_low_to_high": "price-asc-rank",
"price_high_to_low": "price-desc-rank",
"avg_customer_review": "review-rank",
"newest_arrivals": "date-desc-rank",
"best_sellers": "exact-aware-popularity-rank",
}
# Extraction rules for the scraped data
extract_rules = {
"location": "#glow-ingress-block",
"products": {
"selector": ".puisg-col-inner .a-section.a-spacing-small.a-spacing-top-small, .s-product-image-container + div",
"type": "list",
"output": {
"name": "[data-cy=title-recipe]",
"current-price": ".a-price > .a-offscreen",
"listed-price": ".aok-inline-block > .a-price > .a-offscreen",
"rating": "[data-cy=reviews-ratings-slot]",
"reviews": ".rush-component > div > span > a > span, a.a-link-normal > span.a-size-base",
"options": ".s-variation-options-text > a > span > .a-offscreen",
"delivery": "[data-cy=delivery-recipe]",
"coupon": ".s-coupon-unclipped",
"link": "a.a-link-normal@href",
},
},
}
# JavaScript scenario for setting location if zip_code is provided
js_scenario = None
if zip_code:
js_scenario = {
"instructions": [
{
"evaluate": f"""
var xhttp = new XMLHttpRequest();
xhttp.open('POST', 'https://www.amazon.{domain}/gp/delivery/ajax/address-change.html');
xhttp.setRequestHeader('Content-Type', 'application/x-www-form-urlencoded;charset=UTF-8');
xhttp.onload = function() {{
if (xhttp.status >= 200 && xhttp.status < 300) {{
window.location.reload();
}}
}};
xhttp.send('locationType=LOCATION_INPUT&zipCode={zip_code}&storeContext=generic&deviceType=mobile&pageType=Gateway&actionSource=glow');
"""
},
{"wait": 4000},
]
}
# Replace spaces with '+' for URL encoding
encoded_query = search_query.replace(" ", "+")
# Send request to ScrapingBee
response = client.get(
f'https://www.amazon.{domain}/s?k={encoded_query}&page={page}&s={sort_by_map.get(sort_by, "relevanceblender")}',
params={
"wait_browser": "load",
"extract_rules": extract_rules,
"js_scenario": js_scenario,
"timeout": 20000,
},
headers={
"Referer": f"https://www.amazon.{domain}",
},
retries=5,
)
# Check for API key issues
if response.text.startswith('{"message":"Invalid api key:'):
return {
"error": "Invalid API key. Please check your API key and try again. Get your key here: https://app.scrapingbee.com/account/manage/api_key"
}
# Parse the response and return results
data = response.json()
location = data.get("location", "").replace("\u200c", "")
products = data.get("products", [])
# Additional status messages
info_message = (
"FAILED TO RETRIEVE PRODUCTS USING ZIP CODE"
if zip_code and str(zip_code) not in location
else "FAILED TO RETRIEVE PRODUCTS" if not products else "SUCCESS"
)
return {
"location": location,
"count": len(products),
"products": products,
"info": f"{response.status_code} {info_message}",
"page": page,
}
if __name__ == "__main__":
results = amazon_shopping_search(
search_query="school bags",
page=1,
zip_code=20500,
domain="com",
sort_by="avg_customer_review",
)
# Print summary of results
print("Location:")
print(results.get("location", "Unknown location"))
print("Total number of products:")
print(results.get("count", "n/a"))
# Extract products from the results
products = results.get("products", [])
# Check if products exist before proceeding
if products:
# Define the CSV file name
csv_file = "amazon_products.csv"
# Write the results to a CSV file
with open(csv_file, mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=products[0].keys())
writer.writeheader()
writer.writerows(products)
print(f"Results saved to {csv_file}")
else:
print("No products found. CSV file was not created.")
Feel free to copy this code and try it out, but don't worry if it feels overwhelming at first—we'll break it all down in the sections ahead to ensure everything is clear and easy to follow.
Starting with the scraping function
Now it's time to write the main function that will scrape search results from Amazon. This function is flexible—it can handle pagination, sorting, and even location-based results. It's designed to work across different Amazon country sites, making it versatile for various use cases.
def amazon_shopping_search(
search_query, page=1, sort_by="featured", zip_code=None, domain="com"
):
"""
Scrape Amazon search results using ScrapingBee.
Args:
search_query (str): The product search term.
page (int): Page number for pagination.
sort_by (str): Sorting option (e.g., 'featured', 'price_low_to_high').
zip_code (str, optional): Zip code for location-specific results.
domain (str): Amazon domain to scrape (default: 'com').
Returns:
dict: A dictionary containing search results and metadata.
"""
# Map for sorting options
sort_by_map = {
"featured": "relevanceblender",
"price_low_to_high": "price-asc-rank",
"price_high_to_low": "price-desc-rank",
"avg_customer_review": "review-rank",
"newest_arrivals": "date-desc-rank",
"best_sellers": "exact-aware-popularity-rank",
}
Breaking down the code
Function definition
The amazon_shopping_search function is the heart of the scraper. It's where we'll manage the logic for fetching and processing Amazon search results. The function takes the following inputs:
search_query— the product or keyword you want to look for.page— the page number of the search results, allowing you to paginate.sort_by— lets you choose sorting options such as price, customer reviews, or relevance.zip_code— Helps fetch location-specific results, like delivery options or pricing (optional).domain— specifies the Amazon domain (e.g.,.com,.co.jp) for regional scraping.
Sorting map
A key part of the function is the sort_by_map. This dictionary translates human-readable sorting options, like "price_low_to_high", into the actual query parameters Amazon uses in its URLs, such as "price-asc-rank". Here's why this is important:
- Amazon's sorting parameters are not intuitive and are hard to guess.
- The map keeps the code clean and makes it easy to switch sorting options.
- If Amazon changes how sorting works, you only need to update this map instead of modifying the entire function.
Data extraction rules from Amazon
Scraping Amazon effectively starts with writing accurate rules to extract the data you need. Amazon's layout is complex and often varies by product type or region, so crafting these rules can be one of the trickiest parts of the process.
Current location
Amazon shows the user's current location in the top menu:
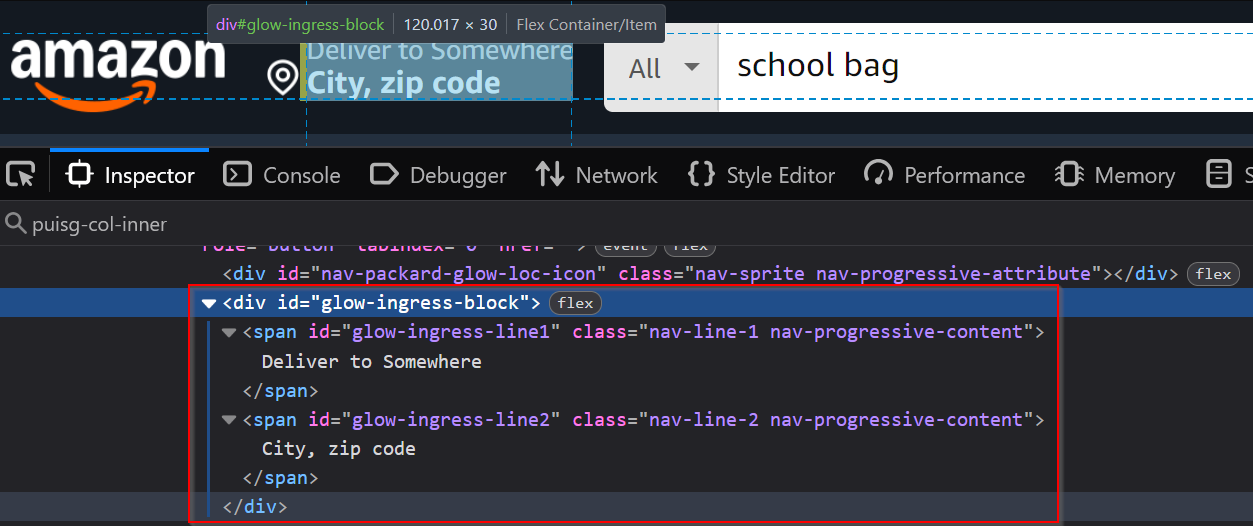
The location is stored within a tag with the ID #glow-ingress-block. This selector helps us grab the location information from the page.
Product general information
The key details for each product—such as the name, price, and rating—are grouped together in a container:
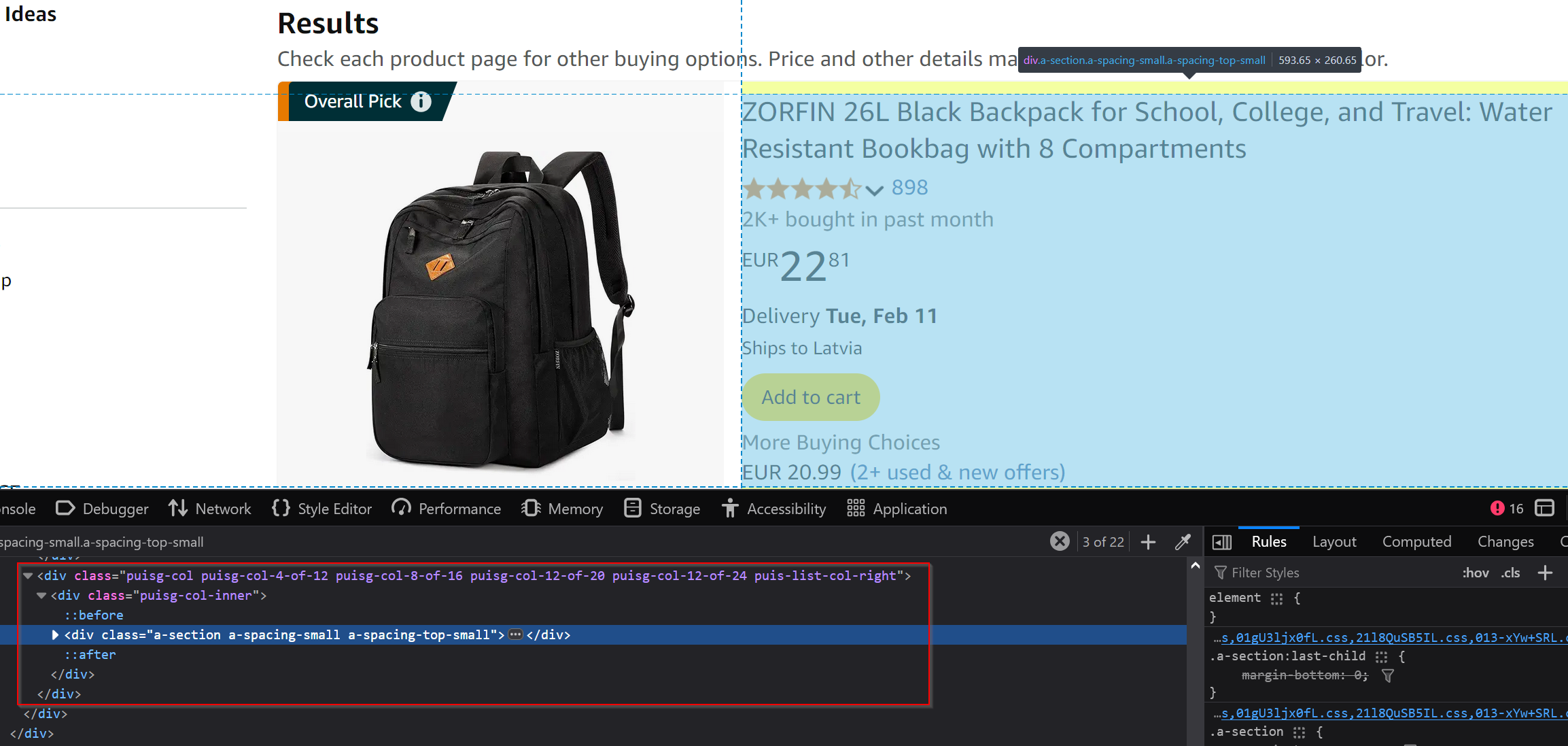
The main selector for this section is: .puisg-col-inner .a-section.a-spacing-small.a-spacing-top-small.
Sometimes, you might also need to use this alternative selector: .s-product-image-container + div.
Product title
To extract the product title, drill down into the general product section:
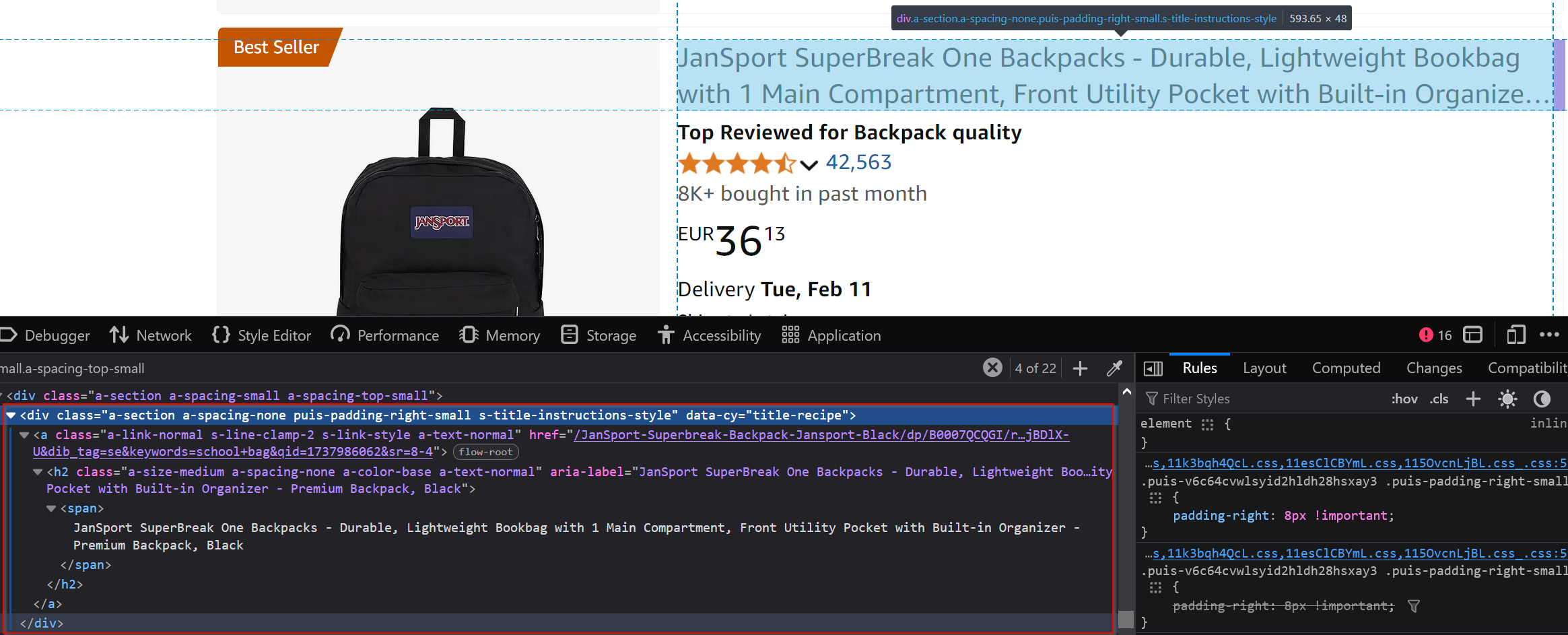
The title is located in the [data-cy=title-recipe] tag, and you can extract the text directly from it.
Product link
The product image typically acts as a clickable link to the product page.
You can grab this link using the a.a-link-normal@href selector.
Product price
The product price is nested within several layers:
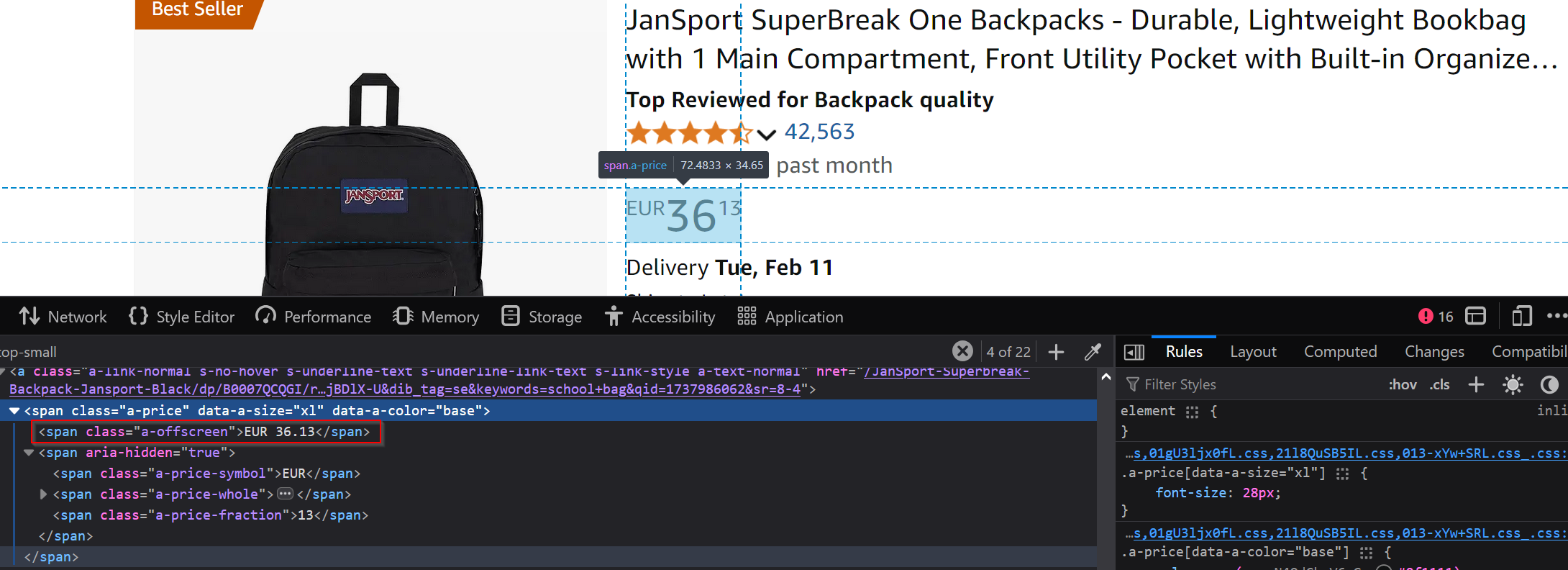
Use the selector .a-price > .a-offscreen to extract the current price. If there's also a listed price, it can be found using .aok-inline-block > .a-price > .a-offscreen.
Product rating
The product rating is displayed in a specific section:
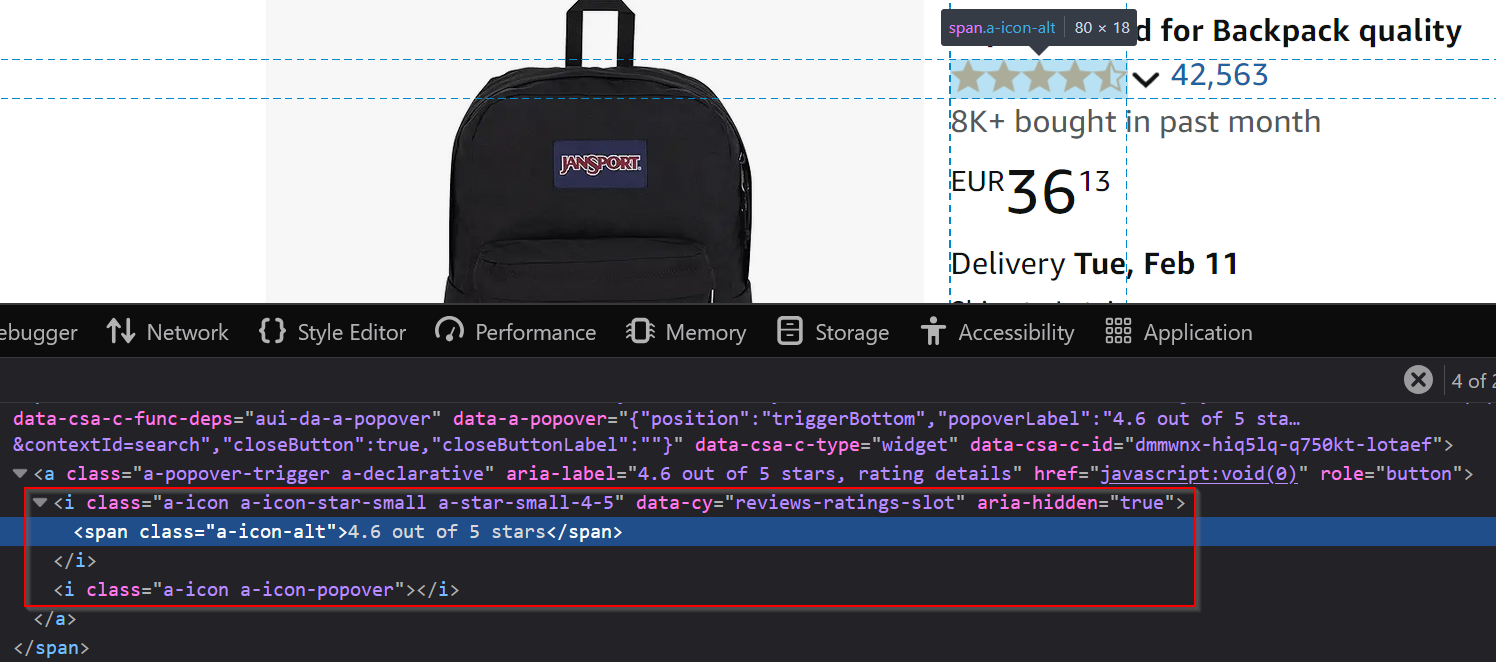
You can extract the rating using [data-cy=reviews-ratings-slot].
Product review count
The number of reviews written for a product is also displayed nearby:
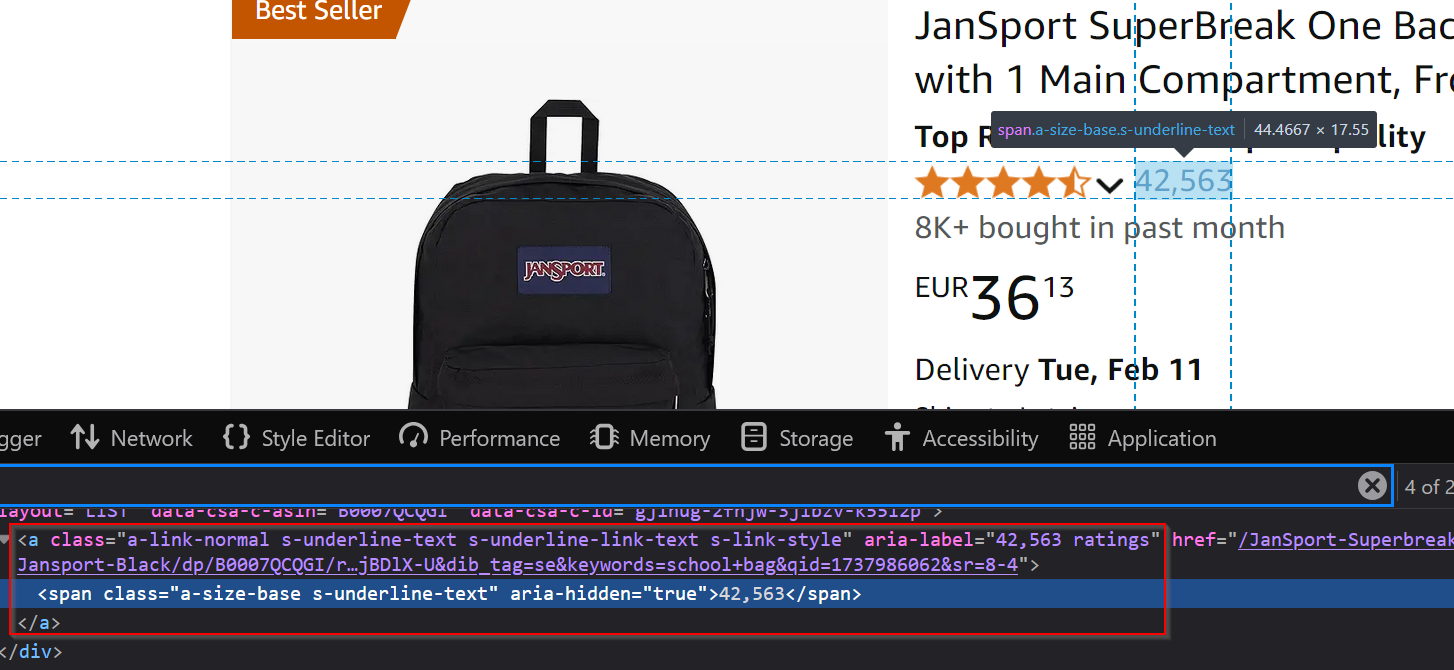
Use the selector a.a-link-normal > span.a-size-base. Alternatively, .rush-component > div > span > a > span works in some cases.
Extra product options
Some products come with extra options, like size or color variations:
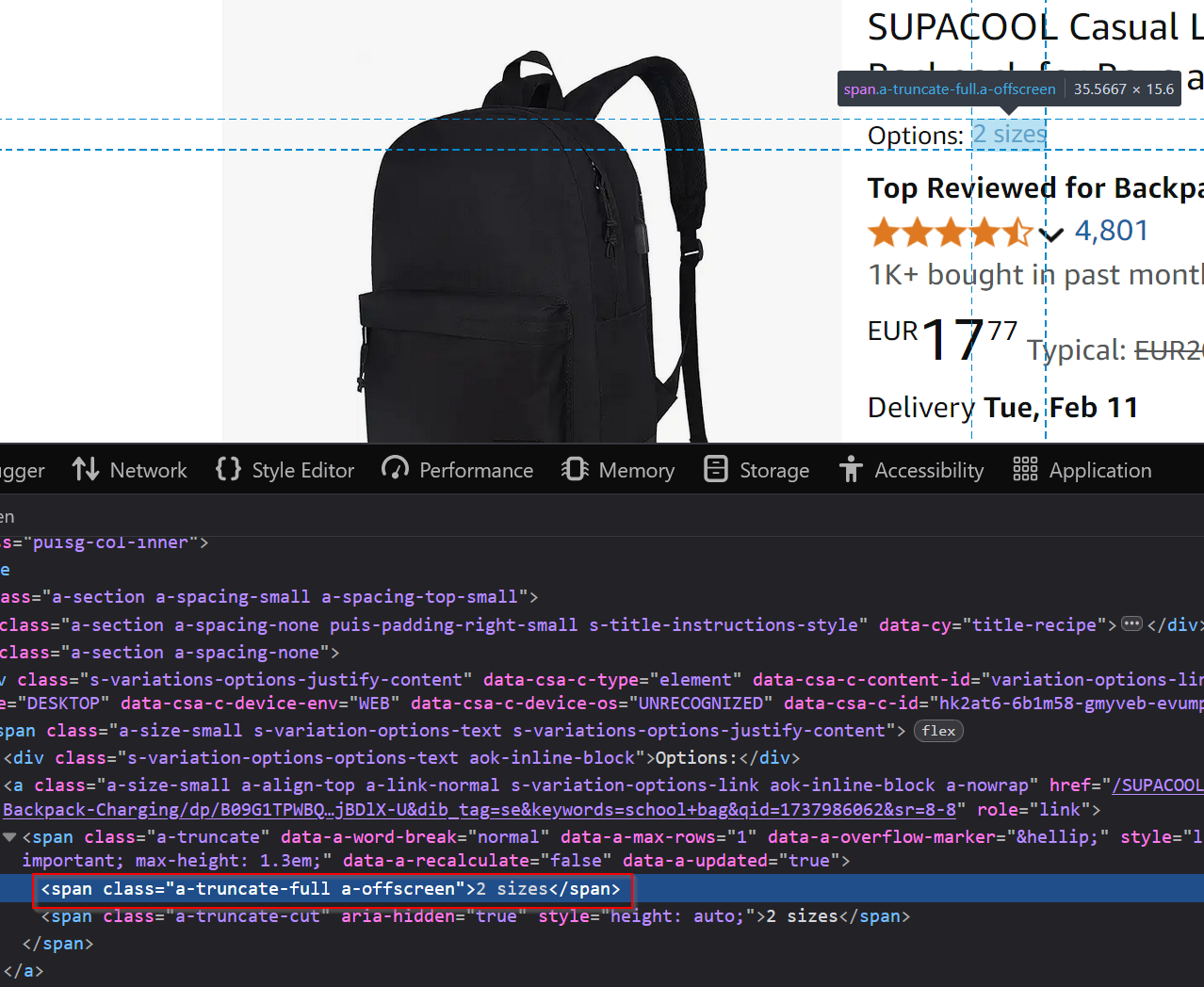
These details can be accessed using the selector .s-variation-options-text > a > span > .a-offscreen.
Delivery information
Amazon provides delivery details for most products:
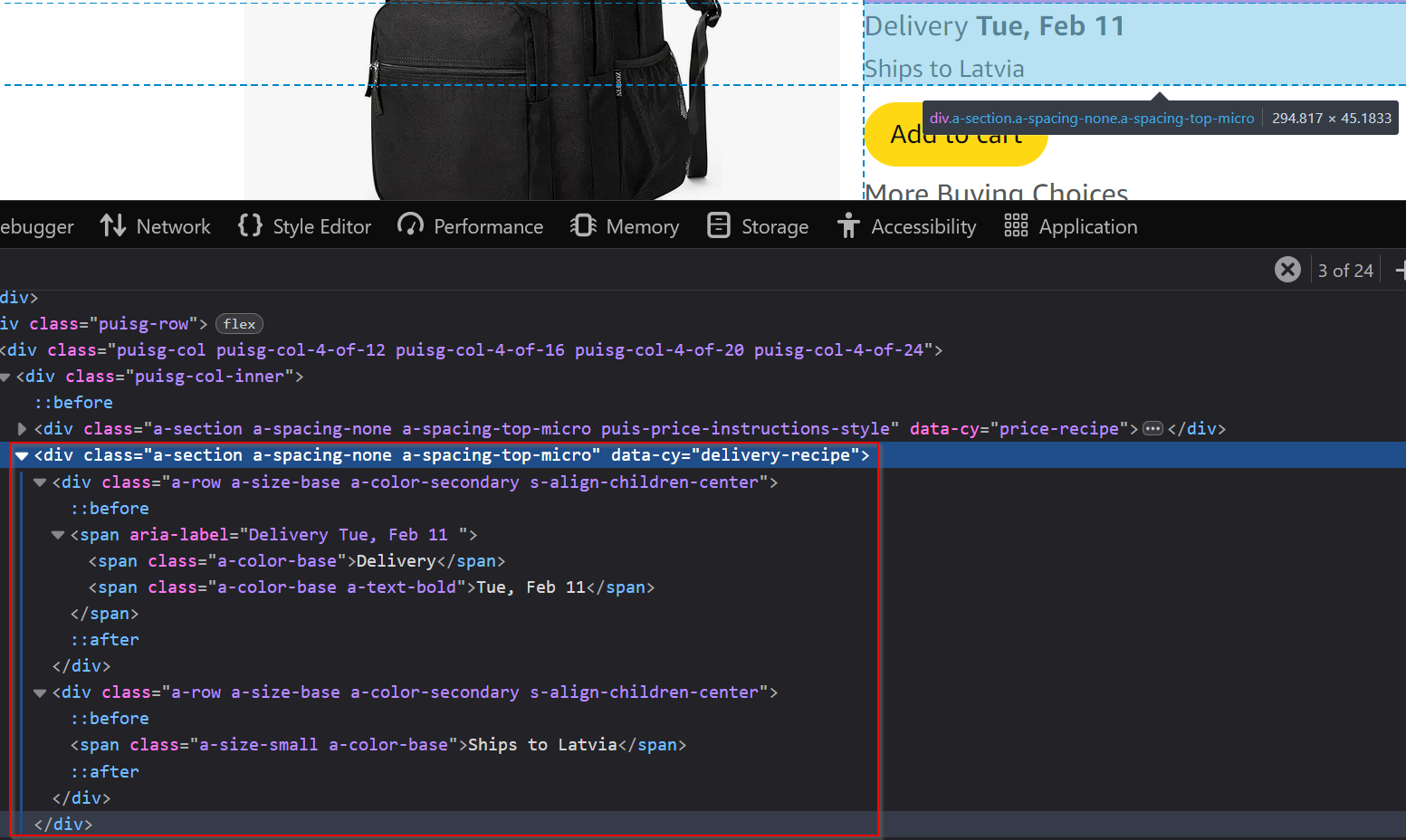
You can retrieve this information using [data-cy=delivery-recipe].
Coupon information
Occasionally, products offer discounts through coupons:
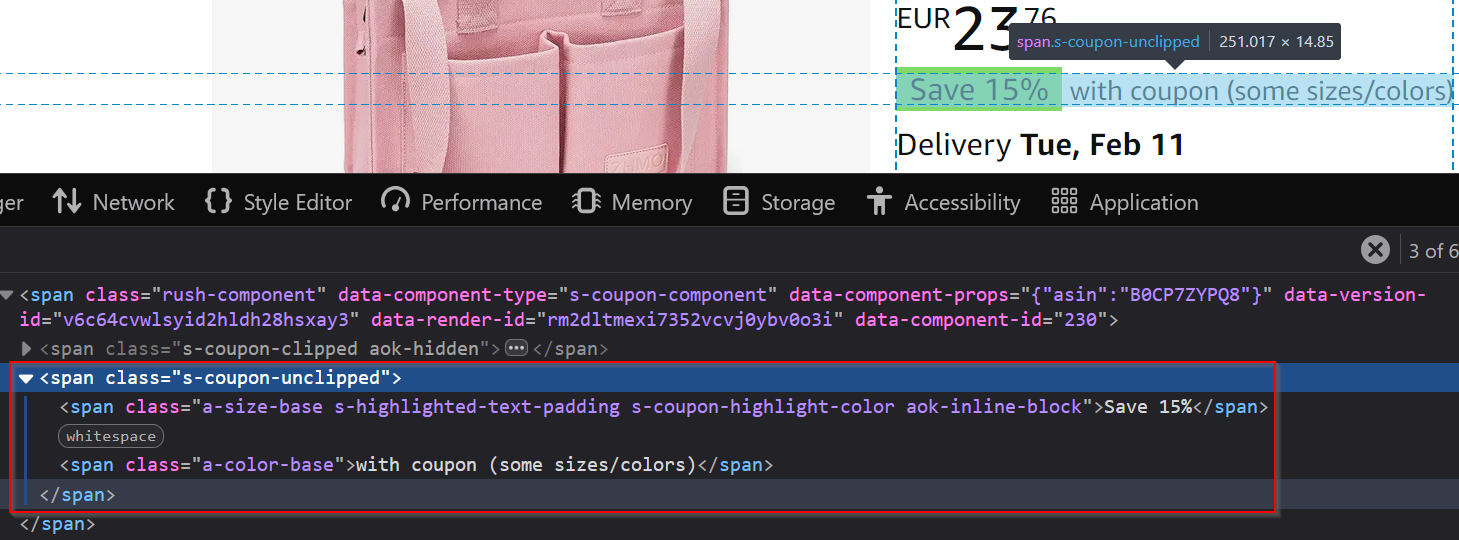
Extract coupon details using the selector .s-coupon-unclipped.
Constructing the extraction rules
Let's consolidate all these rules into a single structure for our scraper. This set of extraction rules will guide our script to pull the data we need from Amazon pages.
def amazon_shopping_search(
search_query, page=1, sort_by="featured", zip_code=None, domain="com"
):
# ... map for sorting options and other code ...
# Extraction rules for the scraped data
extract_rules = {
"location": "#glow-ingress-block",
"products": {
"selector": ".puisg-col-inner .a-section.a-spacing-small.a-spacing-top-small, .s-product-image-container + div",
"type": "list",
"output": {
"name": "[data-cy=title-recipe]",
"current-price": ".a-price > .a-offscreen",
"listed-price": ".aok-inline-block > .a-price > .a-offscreen",
"rating": "[data-cy=reviews-ratings-slot]",
"reviews": ".rush-component > div > span > a > span, a.a-link-normal > span.a-size-base",
"options": ".s-variation-options-text > a > span > .a-offscreen",
"delivery": "[data-cy=delivery-recipe]",
"coupon": ".s-coupon-unclipped",
"link": "a.a-link-normal@href",
},
},
}
With these rules, we've laid the groundwork for extracting essential product details from Amazon search results. Next, we'll focus on sending requests and processing the response.
Switching zip code using a JavaScript scenario
Amazon customizes product availability, prices, and delivery options based on your location. If you want to scrape region-specific data, you'll need to simulate browsing from a specific area. ScrapingBee makes this possible by letting us use a JavaScript scenario to change the zip code dynamically.
def amazon_shopping_search(
search_query, page=1, sort_by="featured", zip_code=None, domain="com"
):
# ... other code ...
# JavaScript scenario for setting location if zip_code is provided
js_scenario = None
if zip_code:
js_scenario = {
"instructions": [
{
"evaluate": f"""
var xhttp = new XMLHttpRequest();
xhttp.open('POST', 'https://www.amazon.{domain}/gp/delivery/ajax/address-change.html');
xhttp.setRequestHeader('Content-Type', 'application/x-www-form-urlencoded;charset=UTF-8');
xhttp.onload = function() {{
if (xhttp.status >= 200 && xhttp.status < 300) {{
window.location.reload();
}}
}};
xhttp.send('locationType=LOCATION_INPUT&zipCode={zip_code}&storeContext=generic&deviceType=mobile&pageType=Gateway&actionSource=glow');
"""
},
{"wait": 4000},
]
}
This approach mimics how a user would change their location on Amazon, ensuring the zip code is applied correctly and the results are customized for the desired region.
Breaking down the code
Amazon doesn't always let you change the location through simple URL parameters. Instead, it relies on JavaScript interactions to update your region. By using ScrapingBee's JavaScript scenario feature, we can replicate these actions programmatically.
Setting up the scenario
We start by initializing the js_scenario variable to None. This ensures that a JavaScript scenario is only created if a zip code is provided. If no zip code is needed, the scraping proceeds without this extra step.
Instructions for the scenario
The JavaScript scenario contains a list of instructions that ScrapingBee will execute in the browser. These instructions consist of actions ("evaluate") and delays ("wait"):
1. evaluate
This action performs several tasks:
Creating an XMLHttpRequest
Sends a POST request to Amazon'saddress-change.htmlendpoint to update the location.Headers
Sets theContent-Typetoapplication/x-www-form-urlencodedto ensure the data is formatted properly.Request Body
Contains key parameters, including:zipCode
The desired zip code to simulate the user's location.- Other Parameters
Additional parameters such aslocationType,storeContext, anddeviceTypeto emulate a mobile browsing session.
Reloading the Page
Once the location change is successful, the page reloads to reflect the updated region.
2. wait
- Delay
Introduces a 4-second pause. This delay allows the browser to reload and apply the new location settings before continuing.
Sending the request
With the extraction rules and optional JavaScript scenario ready, the next step is to send a request to ScrapingBee's API. This part of the process constructs the URL, prepares the query, and submits the request, ensuring everything is set up to extract data effectively.
def amazon_shopping_search(
search_query, page=1, sort_by="featured", zip_code=None, domain="com"
):
# ... other code ...
# Replace spaces with '+' for URL encoding
encoded_query = search_query.replace(" ", "+")
# Send request to ScrapingBee
response = client.get(
f'https://www.amazon.{domain}/s?k={encoded_query}&page={page}&s={sort_by_map.get(sort_by, "relevanceblender")}',
params={
"wait_browser": "load",
"extract_rules": extract_rules,
"js_scenario": js_scenario,
"timeout": 20000,
},
headers={
"Referer": f"https://www.amazon.{domain}",
},
retries=5,
)
URL encoding the search query
Amazon's URLs require search queries to be encoded properly. Spaces must be replaced with +, as Amazon doesn't handle raw spaces in queries. For example, if the search query is "school bags", it's transformed into "school+bags" using this line:
encoded_query = search_query.replace(" ", "+")
This ensures that the query is in the correct format for Amazon's URL structure.
Constructing the URL
The base URL for Amazon search results is:
https://www.amazon.{domain}/s
The query parameters include:
k— the encoded search query.page— the current page of search results, increment this number to scrape different pages in the pagination.s— the sorting option, fetched fromsort_by_map. If no sort option is specified, it defaults to"relevanceblender".
An example of the final URL might look like this: https://www.amazon.com/s?k=school+bags&page=1&s=review-rank.
Parameters for ScrapingBee
The params dictionary fine-tunes how ScrapingBee processes the request:
wait_browser— ensures the API waits for the browser to fully load the page before extracting data.extract_rules— specifies the rules for pulling data from the page (like product name, price, etc).js_scenario— executes the JavaScript scenario to set the zip code if provided (optional).timeout— sets a 20-second timeout to avoid hanging requests.
Headers and retries
The headers dictionary includes a Referer header, which makes the request appear as if it's coming from a real user browsing Amazon. For example, it points to https://www.amazon.{domain}.
Additionally, the retries parameter is set to 5, ensuring the request is retried up to five times in case of temporary failures, such as network issues or API rate limits.
Processing the response
Once we've sent the request to ScrapingBee, the next step is to parse the response and extract the relevant data. This part of the function also includes error handling to ensure the process runs smoothly.
def amazon_shopping_search(
search_query, page=1, sort_by="featured", zip_code=None, domain="com"
):
# ... other code ...
# Check for API key issues
if response.text.startswith('{"message":"Invalid api key:'):
return {
"error": "Invalid API key. Please check your API key and try again. Get your key here: https://app.scrapingbee.com/account/manage/api_key"
}
# Parse the response and return results
data = response.json()
location = data.get("location", "").replace("\u200c", "")
products = data.get("products", [])
# Additional status messages
info_message = (
"FAILED TO RETRIEVE PRODUCTS USING ZIP CODE"
if zip_code and str(zip_code) not in location
else "FAILED TO RETRIEVE PRODUCTS" if not products else "SUCCESS"
)
return {
"location": location,
"count": len(products),
"products": products,
"info": f"{response.status_code} {info_message}",
"page": page,
}
Breaking down the code
This section of the function is responsible for validating the response, parsing the data, and returning a clean, structured result.
API key validation The first thing the function does is check if the API key is valid. If the response contains an error message indicating an invalid key, the function immediately returns an error with instructions to fix it. This ensures any configuration issues are caught early.
Parsing the response The response is converted from JSON into Python-friendly objects. Key data points are extracted:
location— the detected location, cleaned to remove stray characters (like\u200c).products— a list of products retrieved from the page.
Generating a status message The function creates a helpful
info_messageto indicate the result of the request:- If a zip code was provided but isn't reflected in the location, it shows:
"FAILED TO RETRIEVE PRODUCTS USING ZIP CODE". - If no products are found:
"FAILED TO RETRIEVE PRODUCTS". - If everything works as expected:
"SUCCESS".
- If a zip code was provided but isn't reflected in the location, it shows:
Returning the results The final output is a structured dictionary containing:
location— where the data was scraped from.count— the total number of products retrieved.products— a list of product details (like names, prices, and links).info— a combined message with the HTTP status code and the status message.page— the page number of the search results.
Running the scraper and saving results into the CSV file
The final step is to run our scraper, process the results, and save the data into a CSV file for easy access. Let's break down the code to understand how everything comes together.
import csv
# your scraping function here ...
if __name__ == "__main__":
results = amazon_shopping_search(
search_query="school bags",
page=1,
zip_code=20500,
domain="com",
sort_by="avg_customer_review",
)
# Print summary of results
print("Location:")
print(results.get("location", "Unknown location"))
print("Total number of products:")
print(results.get("count", "n/a"))
# Extract products from the results
products = results.get("products", [])
# Check if products exist before proceeding
if products:
# Define the CSV file name
csv_file = "amazon_products.csv"
# Write the results to a CSV file
with open(csv_file, mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=products[0].keys())
writer.writeheader()
writer.writerows(products)
print(f"Results saved to {csv_file}")
else:
print("No products found. CSV file was not created.")
Breaking down the code
This part of the script handles execution, displays a summary of results, and writes the scraped data into a structured CSV file.
Calling the scraping function The script starts by invoking the
amazon_shopping_searchfunction with specific parameters:search_query— what we're looking for (e.g., "school bags").page— the page of results to scrape.zip_code— for location-specific results (optional).domain— the Amazon domain to scrape (e.g.,.com,.co.jp).sort_by— determines how results are sorted (e.g., "avg_customer_review").
Printing a summary Once the results are retrieved, the script prints:
location— the detected user location (or"Unknown location"if unavailable).count— the total number of products scraped (or"n/a"if none were found).
This gives you a quick overview of the data without needing to open the CSV file.
Checking for products Before saving, the script ensures there's data to write. If the
productslist is empty:- It skips the file creation step.
- Prints a message:
"No products found. CSV file was not created."
This prevents creating empty or incomplete files.
Saving to a CSV file If products are available:
- The script specifies the output filename (
amazon_products.csv). - It opens the file in write mode and uses
csv.DictWriterto handle the data. - The column headers are dynamically set based on the product keys (like
name,price, etc.). - Each product is written as a row in the file.
- The script specifies the output filename (
Completion message After saving the file, the script prints a success message:
"Results saved to amazon_products.csv".
If no products were found, it lets you know the file wasn't created.
AI-powered scraping with ScrapingBee
Using traditional scraping methods like CSS or XPath selectors can feel like a hassle. Web pages change their layouts often, and keeping your extraction rules up to date can quickly turn into a frustrating job. That's where ScrapingBee's AI-powered scraping comes to the rescue. With this feature, you can describe what you want in plain language and use simple JSON rules — no need for manual selectors.
Why use AI-powered scraping?
AI scraping takes the headache out of the process by letting you focus on your data, not the nitty-gritty of web layouts. Here's what it brings to the table:
- Extract structured data easily — even when pages are messy or inconsistently structured.
- Save time — skip the effort of writing and debugging complex selectors.
- Stay robust — minimize breakages when website layouts change.
With ScrapingBee's AI feature, scraping becomes faster, smarter, and much more beginner-friendly.
Quickstart
If you're ready to jump straight in, here's the final version of the AI-powered scraping code that we'll explain step by step in this tutorial
Get your API key and 1,000 free credits by signing up for a free account.
import csv
import json
from scrapingbee import ScrapingBeeClient
def scrape_amazon_products(
search_query, domain="com", output_file="amazon_products_ai.csv"
):
"""
Scrapes Amazon search results for specified products using ScrapingBee's AI features.
Args:
search_query (str): The search term to look for on Amazon.
domain (str): The Amazon domain to scrape (default: 'com').
output_file (str): The CSV file to save results to.
Returns:
dict: The extracted data or error message.
"""
# Initialize the ScrapingBee client with your API key
client = ScrapingBeeClient(
api_key="YOUR_API_TOKEN"
)
ai_params = {
"ai_query": "Return a list of products with their names, prices, and links to the product pages",
"ai_extract_rules": json.dumps(
{
"product_name": {
"type": "list",
"description": "The full name of the product as displayed on the page",
},
"product_price": {
"type": "list",
"description": "The price of the product in USD",
},
"link_to_product_page": {
"type": "list",
"description": "The URL linking to the product page",
},
}
),
}
# Define the parameters for AI-based scraping
response = client.get(
f'https://www.amazon.{domain}/s?k={search_query.replace(" ", "+")}',
params=ai_params,
)
# Check the response status
if response.status_code == 200:
# Parse the JSON response
results = response.json()
# Combine the data into rows for CSV
products = zip(
results.get("product_name", []),
results.get("product_price", []),
results.get("link_to_product_page", []),
)
# Save the results to a CSV file
with open(output_file, mode="w", newline="", encoding="utf-8") as file:
writer = csv.writer(file)
# Write the headers
writer.writerow(["Product Name", "Product Price", "Product Link"])
# Write each product as a row
for name, price, link in products:
writer.writerow([name, price, f"https://www.amazon.{domain}{link}"])
print(f"Results saved to {output_file}")
return results
else:
print(f"Failed to scrape Amazon. HTTP Status Code: {response.status_code}")
print("Response:", response.content)
return {"error": "Failed to scrape Amazon."}
# Example usage
if __name__ == "__main__":
results = scrape_amazon_products(
search_query="school backpacks",
domain="com",
output_file="amazon_school_backpacks.csv",
)
We'll guide you through each part of the script to make sure you understand how it all works. Let's get started!
Getting started with the AI scraping
Here's the starting point for our AI-powered Amazon scraping script:
import csv
import json
from scrapingbee import ScrapingBeeClient
def scrape_amazon_products(
search_query, domain="com", output_file="amazon_products_ai.csv"
):
"""
Scrapes Amazon search results for specified products using ScrapingBee's AI features.
Args:
search_query (str): The search term to look for on Amazon.
domain (str): The Amazon domain to scrape (default: 'com').
output_file (str): The CSV file to save results to.
Returns:
dict: The extracted data or error message.
"""
# Initialize the ScrapingBee client with your API key
client = ScrapingBeeClient(
api_key="YOUR_API_KEY"
)
Understanding the AI parameters
To use ScrapingBee's AI effectively, you need to define parameters that specify what data to extract and how to structure it. These parameters let you customize the scraper for your needs while keeping the setup simple.
def scrape_amazon_products(
search_query, domain="com", output_file="amazon_products_ai.csv"
):
# ... other code ...
ai_params = {
"ai_query": "Return a list of products with their names, prices, and links to the product pages",
"ai_extract_rules": json.dumps(
{
"product_name": {
"type": "list",
"description": "The full name of the product as displayed on the page",
},
"product_price": {
"type": "list",
"description": "The price of the product in USD",
},
"link_to_product_page": {
"type": "list",
"description": "The URL linking to the product page",
},
}
),
}
Let's break them down:
ai_query
The ai_query parameter uses plain language to describe the content you want to scrape. For example, if you need a list of products with names, prices, and links, you can simply state that in your query. This removes the need for complex selectors or technical rules.
ai_extract_rules
The ai_extract_rules parameter defines how the data should be organized. It uses a JSON schema to specify:
- Field names — the keys you want in the output (e.g.,
product_name,product_price). - Data types — the expected format for each field, like
list,number, orstring. - Descriptions — plain language explanations of what each field represents, helping the AI understand the context.
For example:
product_name— a list of product titles exactly as they appear on the page.product_price— a list of prices for each product in USD.link_to_product_page— URLs pointing to the product pages.
These parameters guide the AI, ensuring the extracted data is accurate and well-structured.
Putting it all together: Sending the request and saving the results
Here's how the full script works, from sending the request to saving the results to a CSV file:
def scrape_amazon_products(
search_query, domain="com", output_file="amazon_products_ai.csv"
):
# other code ...
response = client.get(
f'https://www.amazon.{domain}/s?k={search_query.replace(" ", "+")}',
params=ai_params,
)
# Check the response status
if response.status_code == 200:
# Parse the JSON response
results = response.json()
# Combine the data into rows for CSV
products = zip(
results.get("product_name", []),
results.get("product_price", []),
results.get("link_to_product_page", []),
)
# Save the results to a CSV file
with open(output_file, mode="w", newline="", encoding="utf-8") as file:
writer = csv.writer(file)
# Write the headers
writer.writerow(["Product Name", "Product Price", "Product Link"])
# Write each product as a row
for name, price, link in products:
writer.writerow([name, price, f"https://www.amazon.{domain}{link}"])
print(f"Results saved to {output_file}")
return results
else:
print(f"Failed to scrape Amazon. HTTP Status Code: {response.status_code}")
print("Response:", response.content)
return {"error": "Failed to scrape Amazon."}
# Example usage
if __name__ == "__main__":
results = scrape_amazon_products(
search_query="school backpacks",
domain="com",
output_file="amazon_school_backpacks.csv",
)
Breaking it down
Sending the request
The client.get function sends the request to ScrapingBee. It constructs the Amazon URL with the search query and domain, then includes the ai_params to guide the AI in extracting the specified fields.
Checking the response status
The script checks if the API call was successful. If the status code is anything other than 200, it prints an error message for debugging and skips further processing.
Parsing the response
If the request succeeds:
- The response is parsed as JSON.
- Fields like
product_name,product_price, andlink_to_product_pageare extracted. - The data is aligned into rows using the
zipfunction, which pairs the product details together for each item.
Saving to a CSV file
The data is saved to a CSV file:
- File setup — the script opens the file in write mode using UTF-8 encoding.
- Writing headers — write column names (
Product Name,Product Price,Product Link) to the first row. - Writing rows — add each product as a row and convert links to full URLs.
Conclusion
And this is it! So today we talked about scraping Amazon shopping results. Together we learned how to fetch product details and save them to a CSV file. We wrote Python scripts to achieve this task with the "classic" approach using CSS selectors and also by utilizing ScrapingBee's AI. By customizing the code you can further adapt the scraper to suit your needs.
I hope you found this tutorial helpful. As always, I thank you for staying with me and happy scraping!

Ilya is an IT tutor and author, web developer, and ex-Microsoft/Cisco specialist. His primary programming languages are Ruby, JavaScript, Python, and Elixir. He enjoys coding, teaching people and learning new things. In his free time he writes educational posts, participates in OpenSource projects, tweets, goes in for sports and plays music.
