curl – there's a rather high chance that you already used it today, directly or indirectly.
In today's article, we are going to take a closer look at what curl is, how it can help you with your scraping projects, and how you can use it in the context of Python scripts.

What is curl?
curl is an immensely popular and widely (one can't stress widely enough) used tool for doing anything that is remotely related to HTTP (and other network protocols). You can use it for a variety of use cases:
- Downloading data files: If it is accessible via HTTP, you can use it with curl. Download the latest JSON or CSV data for your application or the most recent binary patch.
- Uploading files via FTP: curl is not only limited to the web, but also supports a large number of other network protocols. Need to upload something via FTP? curl is your guy!
- REST and SOAP: Use curl to perform your requests against REST APIs.
- Web scraping: Last, but certainly not least, curl can be an ideal choice for your webscraping projects.
Being an open-source project, it has a very active community with lots of contributors who make sure it is secure and up-to-date. All of this made curl a ubiquitous tool, which you can find anywhere from small shell scripts, to large enterprise applications, to IoT devices, and even in cars.
ℹ️ If you are curious what the name stands for, then that's rather trivial: Client and URL
Originally published in 1996, coinciding with the advent of the first mainstream version of HTTP, it has become since then the defacto standard for handling HTTP requests in shell scripts and many programming languages alike. curl comes in the form of a command line application, as well as the C library libcurl, for which countless of bindings exist in different languages, among them Python.
Fair enough, but how do we use all that power of curl in the context of Python? Let's find out!
Comparing different ways to use curl in Python
When using curl with Python, we have two principal options:
- Using the CLI and invoking the curl binary as child process
- Using the native Python library PycURL (preferred option)
While the native library will be in most cases the best option, there still can be reasons why one may want to use the command line application instead. For example, your code could run in an environment where you cannot control, or install, third party dependencies or you may want to send just a quick and simple HTTP request without the usual boilerplate code of initialising objects and calling a plethora of methods.
Another option on Python is the very popular Requests library, for which there are also several online tools available which can convert a curl command to native Python code.
Converting a curl command line call to "Requests"
Let's give this a shot with a real-world example on the Nasdaq page for Apple shares: https://www.nasdaq.com/market-activity/stocks/aapl
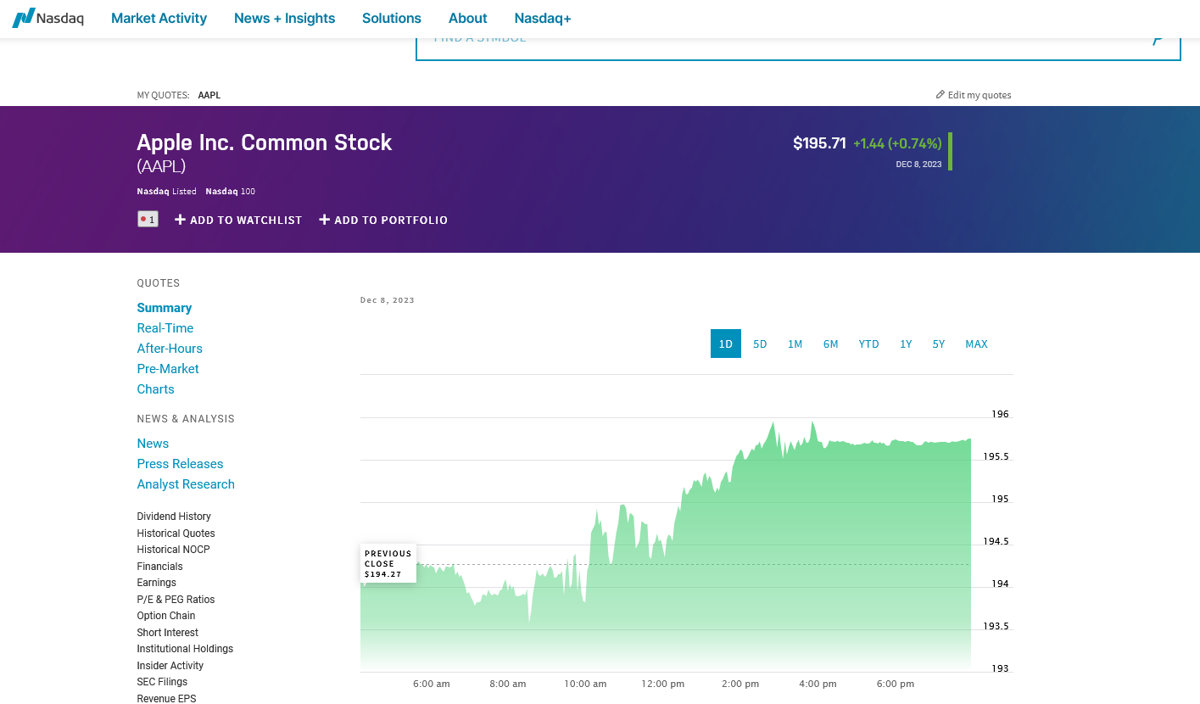
That's a nice chart and shareholders probably appreciate its overall tendency, but how do we get the actual data? Let's find the API URL!
👉 ScrapingBee curl-to-Python converter
At ScrapingBee, we really embrace the low and no-code approach and want to offer the easiest path for your scraping projects. To support you in this endeavour, we have our own, custom converter tool to turn a curl command into working Python code with a few clicks.
Did you know, ScrapingBee also offers a free trial for the platform? Sign up and get 1,000 API requests completely on the house.
Determining the API URL
For starters, we need to get an understanding how the site works, what resources it loads, and where it obtains the data from.
To achieve this, we seek out the help of the developer tools of our browser and here the "Network" tab in particular.
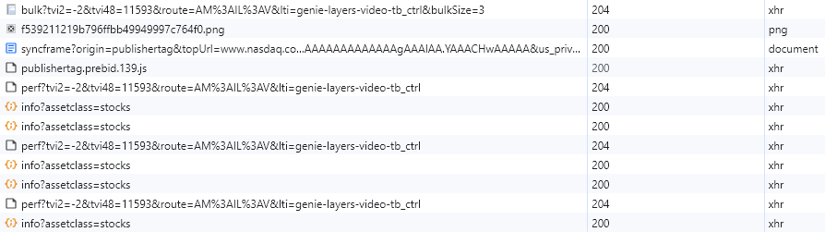
- Open up a new tab.
- Press F12 to open the developer tools and select the "Network" tab.
- Load https://www.nasdaq.com/market-activity/stocks/aapl.
- Observe the requests the browser is performing and the resources the site is using.
There'll be a whole bunch of scripts, images, and stylesheets the site will be loading, but if you wait a couple of seconds, you'll notice that there is one particular JSON URL, which the site is fetching every five seconds:
https://api.nasdaq.com/api/quote/AAPL/info?assetclass=stocks
That's the API URL we are interested in.
Obtaining the curl command from the browser
Now that we know which URL we need to request, how do we get the curl command which will enable us to receive the data from it?
Fairly straightforward actually! Both, Firefox and Chrome, support curl commands by default and allow you to copy them with two clicks.
- Right-click the request the list to open the entry's context menu.
- Select
Copy Valueon Firefox andCopyon Chrome to open the sub-menu. - Select
Copy as cURL- you can choose either for Windows or for Unix, which relates mostly to different quotation marks
Voilà, you have the full curl command in your clipboard, similar to the following string.
curl "https://api.nasdaq.com/api/quote/AAPL/info?assetclass=stocks" --compressed -H "User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:120.0) Gecko/20100101 Firefox/120.0" -H "Accept: application/json, text/plain, */*" -H "Accept-Language: en-GB" -H "Accept-Encoding: gzip, deflate, br" -H "Referer: https://www.nasdaq.com/" -H "Origin: https://www.nasdaq.com" -H "Connection: keep-alive" -H "Sec-Fetch-Dest: empty" -H "Sec-Fetch-Mode: cors" -H "Sec-Fetch-Site: same-site" -H "Pragma: no-cache" -H "Cache-Control: no-cache"
If we ran this command now, we'd get something like the following output in our shell.
{
"data": {
"symbol": "AAPL",
"companyName": "Apple Inc. Common Stock",
"stockType": "Common Stock",
"exchange": "NASDAQ-GS",
"isNasdaqListed": true,
"isNasdaq100": true,
"isHeld": false,
"primaryData": {
"lastSalePrice": "$193.18",
"netChange": "-2.53",
"percentageChange": "-1.29%",
"deltaIndicator": "down",
"lastTradeTimestamp": "Dec 11, 2023",
"isRealTime": false,
"bidPrice": "N/A",
"askPrice": "N/A",
"bidSize": "N/A",
"askSize": "N/A",
"volume": "60,943,699"
},
"secondaryData": null,
"marketStatus": "Closed",
"assetClass": "STOCKS",
"keyStats": {
"fiftyTwoWeekHighLow": {
"label": "52 Week Range:",
"value": "124.17 - 198.23"
},
"dayrange": {
"label": "High/Low:",
"value": "191.42 - 193.49"
}
},
"notifications": []
},
"message": null,
"status": {
"rCode": 200,
"bCodeMessage": null,
"developerMessage": null
}
}
Good old JSON and we can already see what kind of data structure we receive with the company name, its exchange, and so on.
But for your example here, we are interested in converting our curl call to Python code using the Requests library. So let's do that next.
Converting the curl call to Python code
Once we have the curl command, the conversion is a piece of cake 🍰
- Visit https://www.scrapingbee.com/curl-converter/python/
- Paste our previous curl command into the textbox
- Click the
Copy to clipboardbutton - Profit 💰 – you should now have the following Python code in your clipboard, ready to be pasted into your favourite Python editor
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:120.0) Gecko/20100101 Firefox/120.0',
'Accept': 'application/json, text/plain, */*',
'Accept-Language': 'en-GB',
# 'Accept-Encoding': 'gzip, deflate, br',
'Referer': 'https://www.nasdaq.com/',
'Origin': 'https://www.nasdaq.com',
'Connection': 'keep-alive',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-site',
'Pragma': 'no-cache',
'Cache-Control': 'no-cache',
}
params = {
'assetclass': 'stocks',
}
response = requests.get('https://api.nasdaq.com/api/quote/AAPL/info', params=params, headers=headers)
Let's run it, shall we?
Running the converted Requests sample
Before saving your new .py file, just add these two lines, so that we get some pretty output.
data = response.json()
print(data.get('data').get('companyName'))
If we now run the script, Python should send the same request as curl did earlier and save the response in the - aptly named - variable response. With our additional two lines, we parse the response as JSON (-> response.json()) and access .data.companyName from our JSON object.
Apple Inc. Common Stock
Call the curl binary as child process
In these cases, you can simply call the curl binary as if you were directly on the shell and pass all required and desired parameters. The following example sends a basic GET request to example.com, pipes the standard output stream (where curl returns the content) back to Python, and accesses the output using the stdout member of the process object we received from the run command. As curl will print status information to the standard error stream, we configured that with DEVNULL to be suppressed.
import subprocess
command = 'curl http://example.com'
process = subprocess.run(command, stdout=subprocess.PIPE, stderr=subprocess.DEVNULL)
# process.stdout has the HTTP response at this point
print(process.stdout)
Pretty straightforward and works with all command line parameters the curl binary accepts, but it may become a bit fiddly if your request is more complex or involves uploads. For these cases, it is best to switch to something more native to Python - welcome PycURL!
Use curl with PycURL on Python
As mentioned in the introduction, curl provides its feature set also in the form of a C library, for which varieties of native bindings exist across the different language platforms. For Python, that would be PycURL.
Assuming you have the necessary prerequisites installed (i.e. libcurl), the installation is rather easy with Python's package manager pip.
pip install pycurl
Once successfully installed, you can import PycURL in your scripts with import pycurl.
At this point you should have full access to all of its functionality and can instantiate a PycURL object using the following call:
curl = pycurl.Curl()
This will create a PycURL object and save its reference in the curl variable, which you subsequently use to interact with PycURL and perform your HTTP requests.
Let's put that theory into practice with a few samples!
⚠️ All the following Python samples assume that you are using Python 3.12 or higher. Please verify your version with
python --versionand update if necessary.
Performing a GET request with PycURL
import pycurl
from io import BytesIO
# Creating a buffer as the cURL is not allocating a buffer for the network response
buffer = BytesIO()
# Initialising the curl object
curl = pycurl.Curl()
# Setting the request URL, the user agent, and the buffer for the response
curl.setopt(pycurl.URL, 'https://www.scrapingbee.com/')
curl.setopt(pycurl.USERAGENT, "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:120.0) Gecko/20100101 Firefox/120.0")
curl.setopt(pycurl.WRITEDATA, buffer)
# Performing the actual request
curl.perform()
# Accessing the response code
print('Status: %d' % curl.getinfo(pycurl.RESPONSE_CODE))
# Accessing the first twenty characters of the HTTP response
print(buffer.getvalue()[0:20])
# Ending the session and freeing the resources
curl.close()
Beautiful, when we save this to a .py file and run it, we should get an output similar to that (assuming we have a working Internet connection, of course).
Status: 200
b'<!DOCTYPE html>\n<htm'
But what exactly are we doing here?
- We declare our imports.
- We initialise a buffer using
BytesIO, where PycURL will later save the response. - As mentioned in the theory part, we use
pycurl.Curl()to initialise a PycURL object. - We then call
setopt()a few times to configure our PycURL object with the correct data (i.e., the URL, the user agent, and the buffer). - Using the
perform()method, we send our request off to the configured URL.
Once perform() returns, PycURL has received the response and already prepared everything for us. We just need to access whichever data we need for our job.
Here, we got the status code of the HTTP response
curl.getinfo(pycurl.RESPONSE_CODE)
and also read the first twenty characters from the response buffer
buffer.getvalue()[0:20]
To get the whole response, we could also call buffer.getvalue().decode('iso-8859-1') but that output, of course, would be slightly too much for the page here 😳.
Now that we covered GET, let's see how it works with a POST request.
Performing a POST request with PycURL
In the following example, we send a POST request to httpbin.org, which will echo back what we sent, along with additional request details. Let's jump right in!
import pycurl
from io import BytesIO
from urllib.parse import urlencode
# Creating a buffer as the cURL is not allocating a buffer for the network response
buffer = BytesIO()
# Initialising the curl object
curl = pycurl.Curl()
# Setting the request URL
curl.setopt(pycurl.URL, 'https://httpbin.org/post')
curl.setopt(pycurl.WRITEDATA, buffer)
# Setting the form data for the request
post_data = {'field': 'value'}
# Encoding the string to be used as a query
postfields = urlencode(post_data)
# Setting the cURL for POST operation
curl.setopt(pycurl.POSTFIELDS, postfields)
# Performing the request
curl.perform()
# Ending the session and freeing the resources
curl.close()
# Accessing the HTTP response
print(buffer.getvalue().decode('iso-8859-1'))
Once more, let's take a look at the exact steps we performed here:
- Just like in our GET example, we declared our library imports.
- We also initialised a buffer and a PycURL object again.
- Again, we set the request parameters using
setopt. - With
post_datawe have the first change to our previous example. Here we set the data that we are going to send in the request body to our URL. - In the next steps, we encode our POST data with
urlencode, save that topostfields, and usesetoptagain to attach that data to our request.
With pycurl.POSTFIELDS set, PycURL automatically set POST as request method and once we send our request with perform(), we can access our response data just like before using buffer.
When we run this code, we should get some output similar to this:
{
"args": {},
"data": "",
"files": {},
"form": {
"field": "value"
},
"headers": {
"Accept": "*/*",
"Content-Length": "11",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "PycURL/7.44.1 libcurl/7.81.0 GnuTLS/3.7.3 zlib/1.2.11 brotli/1.0.9 zstd/1.4.8 libidn2/2.3.2 libpsl/0.21.0 (+libidn2/2.3.2) libssh/0.9.6/openssl/zlib nghttp2/1.43.0 librtmp/2.3 OpenLDAP/2.5.13",
},
"json": null,
"url": "https://httpbin.org/post"
}
In this JSON document, the headers object contains all the request headers we sent with our request (notice the default user agent, as we didn't send any this time), whereas the form object contains the POST data we sent with our request (remember post_data).
Downloading a file with curl and PycURL
For our next example, we are going to show how to download a (binary) file from any given URL. Without much further ado, here the code:
import sys
from urllib.parse import urlparse
import os
import pycurl
from io import BytesIO
# Parsing passed URL
url = urlparse(sys.argv[1])
# Determining the file name
file = os.path.basename(url.path)
# Creating a buffer as the cURL is not allocating a buffer for the network response
buffer = BytesIO()
# Initialising the curl object
curl = pycurl.Curl()
# Setting the request URL and the buffer for the response
curl.setopt(pycurl.URL, sys.argv[1])
curl.setopt(pycurl.WRITEDATA, buffer)
# Performing the actual request
curl.perform()
# Ending the session and freeing the resources
curl.close()
# Writing the buffer to the file
with open(file, "wb") as f:
f.write(buffer.getbuffer())
At this point, you are probably relatively familiar with the PycURL details, so let's focus on the new stuff here.
- Our script assumes it gets passed as first command line parameter the URL to download (
sys.argv[1]). - It uses
urlparseto get a parsed representation of that URL and the actual filename withbasename. - It then performs the PycURL network magic to get the content of the URL, which it eventually writes to the filesystem with
openandwrite.
Let's save the code as downloader.py and run it with the following command
python3 downloader.py https://www.python.org/static/img/python-logo.png
We should now have the Python logo from https://www.python.org/static/img/python-logo.png in our local directory under python-logo.png.
💡 Love the power of cURL? Check out our ultimate guide on How to download files at enterprise level scale with cURL.
Handling user authentication and cookies with PycURL
Next, we'd like to check out how we can handle user authentication and cookies with PycURL. As we really love Hacker News at ScrapingBee, we often use it as example for such tasks and this time shouldn't be any different, as it is once again a perfect occasion.
import pycurl
from io import BytesIO
from urllib.parse import urlencode
# Setting our Hacker News credentials
hn_username = ''
hn_password = ''
postdata = urlencode({ 'goto': 'news', 'acct': hn_username, 'pw': hn_password })
# Creating a buffer as the cURL is not allocating a buffer for the network response
buffer = BytesIO()
# Initialising the curl object
curl = pycurl.Curl()
# Setting the request URL
curl.setopt(pycurl.URL, 'https://news.ycombinator.com/login')
curl.setopt(pycurl.USERAGENT, 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:120.0) Gecko/20100101 Firefox/120.0')
curl.setopt(pycurl.WRITEDATA, buffer)
curl.setopt(pycurl.COOKIEJAR, 'hn_cookies.txt')
curl.setopt(pycurl.POSTFIELDS, postdata)
# Performing the request
curl.perform()
statuscode = curl.getinfo(pycurl.RESPONSE_CODE)
if statuscode == 302:
# The login worked
else:
print('Invalid credentials')
# Ending the session and freeing the resources
curl.close()
The example above is actually quite similar to what we learned in our earlier POST demo. We set our POST data (this time our logon credentials), we allocate a buffer, we initialise a PycURL object, and we send off the request with perform(). However, you may have already spotted the one big difference - the cookie jar 🍪.
While most HTTP libraries provide direct access to HTTP headers and cookies, curl (and by extension PycURL) follows a rather Unixoid approach and uses files. Here, we used the pycurl.COOKIEJAR option to pass the path to a text file where curl will store the cookies it received with the request. This means, once our request completed we have a new file hn_cookies.txt in the local directory which contains our user session information. We can use this very same file for all our subsequent (and to be authenticated) requests, by simply passing the (read-only counterpart) pycurl.COOKIEFILE option to our PycURL object.
curl.setopt(pycurl.COOKIEFILE, 'hn_cookies.txt')
With this line, we'll use the file where we stored our session cookie in the previous step and and send that information along with any following, new requests. By doing so, these requests will be authenticated with our original user session and we can perform all the possible actions in this context.
Following HTTP redirects
One important part of HTTP are request redirects. This is, when the web server tells us to find a certain resource at a new location. Such redirects are indicated with a 300 response code and can be found in the HTTP status line.
While we could certainly handle this ourselves, it would make our code more complex as we'd need to perform the following steps for each request
- Check the response code for a 300
- Fetch the URL from the
Locationheader - Send a new request with the updated URL address
Nothing impossible, but a bit cumbersome. Thankfully, curl got us covered here and provides an option to automatically follow redirects. That's exactly what the following code does.
import pycurl
# Initialising the curl object
curl = pycurl.Curl()
# Setting the request URL, the user agent, and the buffer for the response
curl.setopt(pycurl.URL, 'https://httpbin.org/redirect-to?url=http%3A%2F%2Fexample.com')
curl.setopt(pycurl.FOLLOWLOCATION, True)
# Performing the actual request
curl.perform()
# Accessing the response code
print('Status: %d' % curl.getinfo(pycurl.RESPONSE_CODE))
# Ending the session and freeing the resources
curl.close()
In this sample, we send a GET request to https://httpbin.org/redirect-to and receive a redirect to example.com in the response.
The crucial line in question here is curl.setopt(pycurl.FOLLOWLOCATION, True). This option tells curl to handle redirects automatically and fetch their content transparently, without us having to check and issue sub-requests. If we run the example, curl will first send a request to httpbin.org, receive the redirect, and send a second HTTP request to example.com. There, we get a response with a 200 code and the HTML document, which curl will eventually return to us.
<!doctype html>
<html>
<head>
<title>Example Domain</title>
[MORE HTML HERE]
Status: 200
If we had omitted pycurl.FOLLOWLOCATION (or set it to False), curl would have only sent the first request to httpbin.org and provided us instead with that redirect response.
Status: 302
While there will be use cases where you specifically want to handle a redirect yourself, in most cases you should enable pycurl.FOLLOWLOCATION and save yourself the trouble of re-implementing that logic.
Extracting content from the DOM with Beautiful Soup
So far all our examples covered the basic nature of HTTP requests (different request methods, saving the HTTP response stream, handling HTTP cookies, and so on), but the very idea of web scraping is to extract structured data from an HTML document served by a web server. That's what our next example is about, using Beautiful Soup to parse an HTML document and extract elements from its DOM tree.
If you haven't installed Beautiful Soup yet, you can do this using pip:
pip install beautifulsoup4
Once installed, we are ready to start our newest webscraping adventure and what could be better than to check out Hacker News again. The following sample scrapes https://news.ycombinator.com/newest for the latest articles, extracts their respective anchor tags, and prints their titles.
import pycurl
from io import BytesIO
from bs4 import BeautifulSoup
# Creating a buffer as the cURL is not allocating a buffer for the network response
buffer = BytesIO()
# Initialising the curl object
curl = pycurl.Curl()
# Setting the request URL, the user agent, and the buffer for the response
curl.setopt(pycurl.URL, 'https://news.ycombinator.com/newest')
curl.setopt(pycurl.WRITEDATA, buffer)
# Performing the actual request
curl.perform()
# Ending the session and freeing the resources
curl.close()
# Initialising Beautiful Soup with the buffer content
soup = BeautifulSoup(buffer.getvalue(), 'html.parser')
# Selecting all title spans matching the provided CSS selector
title_spans = soup.select("span.titleline > a")
# Iterating over the title spans and printing their text
for title in title_spans:
print(title.getText())
At this point, you'll be pretty familiar with the curl part of the GET request, so let's skip that and head straight for the part where we are calling Beautiful Soup.
For starters, we initialise a new BeautifulSoup instance and pass it the response, which our earlier curl call saved in buffer.
soup = BeautifulSoup(buffer.getvalue(), 'html.parser')
Splendid, we now have in soup a parsed document object with all the DOM functions at our fingertips. Let's put this to a test by calling select()
title_spans = soup.select("span.titleline > a")
Here, we pass the CSS selector span.titleline > a to the select() function and receive in return a list of all matching DOM elements. The selector essentially tells Beautiful Soup to search for <a> tags which are immediate children of a <span> tag with the HTML class titleline. If you like to learn more about the intrinsics of CSS selectors, check out our article Using CSS Selectors for Web Scraping.
With all the matching elements now in title_spans, we only need to use a for loop to iterate over them and print their text content.
for title in title_spans:
print(title.getText())
💡 Should you be interested in more details about Beautiful Soup, please also take a look at our article on how to use Beautiful Soup with the Requests library.
Comparison table of curl and Requests parameters
The following table provides a quick overview of the different curl command line parameters and their counterparts in the Requests library.
| Feature | curl CLI argument | Requests feature |
|---|---|---|
| Set request method | --request | Either by specifying it as first parameter to the request() method or by using a dedicated request type method (e.g. get() or post()) |
| Set request URL | --url | Passed as second parameter to request() or first parameter to a request type method |
| Add header | --header | Passed as headers parameter |
| Add cookie | --cookie | Passed as cookies parameter |
| Add basic auth | --user | Passed as auth parameter |
| Set timeout | --connect-timeout | Passed as timeout parameter |
| Set client certificate | --cert | Passed as cert parameter |
| Follow HTTP redirects | --location | Passed as allow_redirects parameter |
For detailed information, please consult the documentation of curl and the documentation of Requests.
Using curl to scrape with ScrapingBee
ScrapingBee, being a REST-based no-code scraping platform, is another ideal use case for curl, especially if you want to scrape from a command line or shell scripts.
Both ScrapingBee request builders, the HTML API Request Builder and the Google API Request Builder, support - among popular language libraries - also curl template strings and you can assemble the perfect curl command with just a few clicks from the UI.
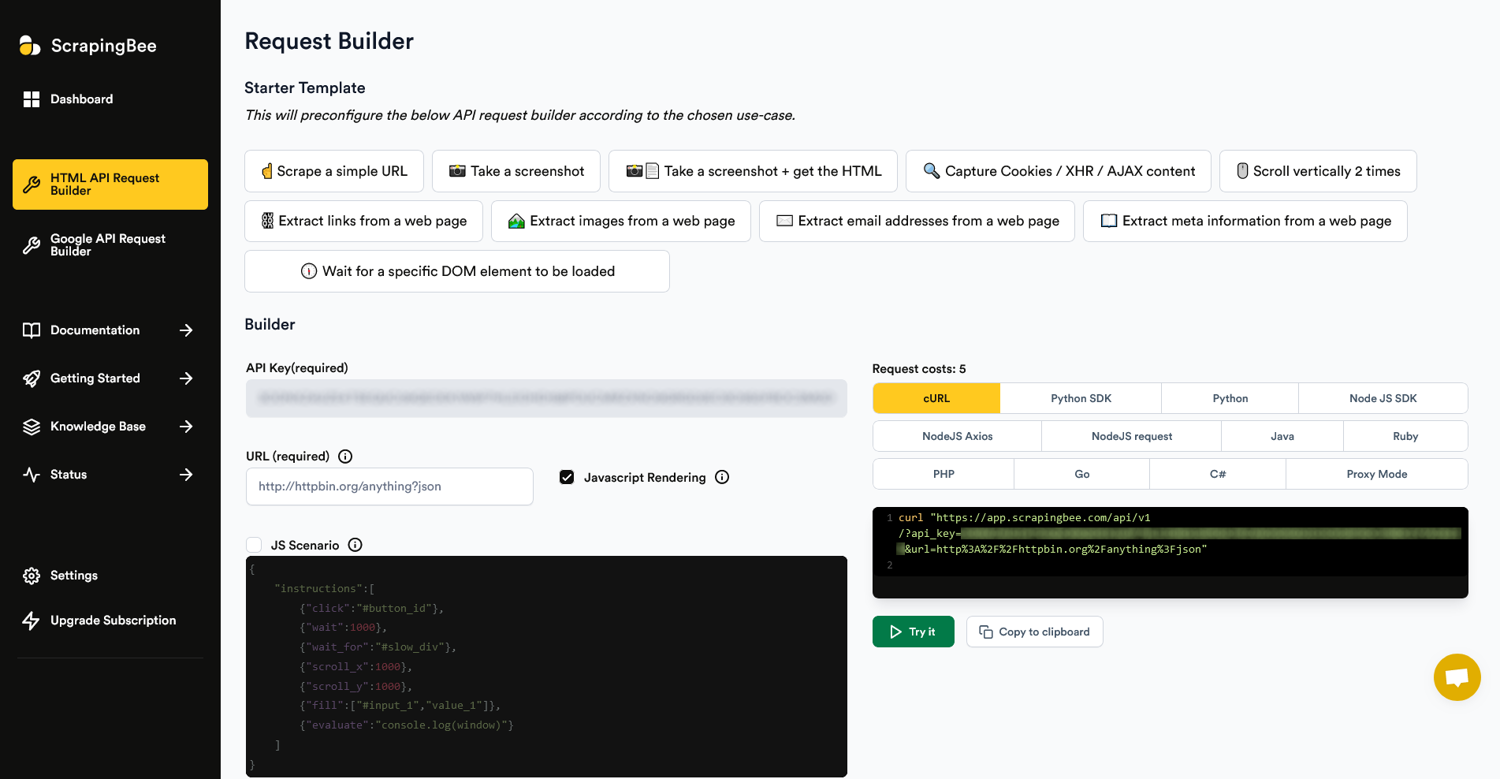
Once you have selected all the desired options, you can copy the ready command string to your clipboard or try a test run using the Try it button.
Summary
We hope we did not promise too much in the introduction and managed to successfully show the versatility of curl, be that as command line tool or as library for Python or many other languages. One can really call curl the Swiss Army knife of HTTP.
However, with curl focusing on HTTP and all its features, and not so much on scraping per se, one may still run into the usual obstacles and hurdles in the context of web scraping – rate limits, user agent limitations, IP address restrictions, geo-fencing, and so on. That's exactly where specialised scraping platforms come in, as they provide all the necessary tools to handle these issues.
So if you love curl, but still don't want to have to bother with rotating proxies or making sure all the site's necessary JavaScript code is executed, take a look at how ScrapingBee and its vast support for scraping screenshots, JavaScript, and REST APIs can help you with your latest web-scraping project. As mentioned earlier, every new account comes with the first 1,000 requests for free.
Happy curling 🥌 and happy scraping!

Alexander is a software engineer and technical writer with a passion for everything network related.


