In this tutorial, we are going to take a look at Puppeteer, a JavaScript library developed by Google. Puppeteer provides a native automation interface for Chrome and Firefox, allowing you to launch a headless browser instance and take full control of websites, including taking screenshots, submitting forms, extracting data, and more. Let's dive right in with a real-world example. 🤿
💡 If you are curious about the basics of web scraping in JavaScript, you may be also interested in Web Scraping with JavaScript and Node.js.
Getting Started
For starters, make sure you are running Node.js 22 or higher with a working npm installation. With that at hand, we now create a sample directory and install the required puppeteer package:
mkdir first-puppeteer-demo
cd first-puppeteer-demo
npm install puppeteer
npm pkg set type="module"
ℹ️ The puppeteer package comes with its own dedicated Chrome setup. If prefer to use an existing browser instance, you can also install puppeteer-core instead (you'd pass
executablePathto itslaunch()method in that case).
With Puppeteer successfully installed, we can now write our first demo script.
First steps: taking a screenshot
For starters, let's do something simple and simply take a screenshot of the current page. Using the following script, we do just that with the homepage of the subreddit /r/MovieMistakes.
Save the following code as index.js in the directory we just created, and run it with node index.js.
import puppeteer from 'puppeteer';
// Launch browser and open a new tab
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
// Navigate to a website
await page.goto('https://www.reddit.com/r/MovieMistakes/');
// Take screenshot
await page.screenshot({ path: 'moviemistakes.png' });
// Close browser
await browser.close();
A Chrome window should briefly flash, completing the set of instruction steps, and once the browser has closed and the script finished, there should be a new file moviemistakes.png in the directory:
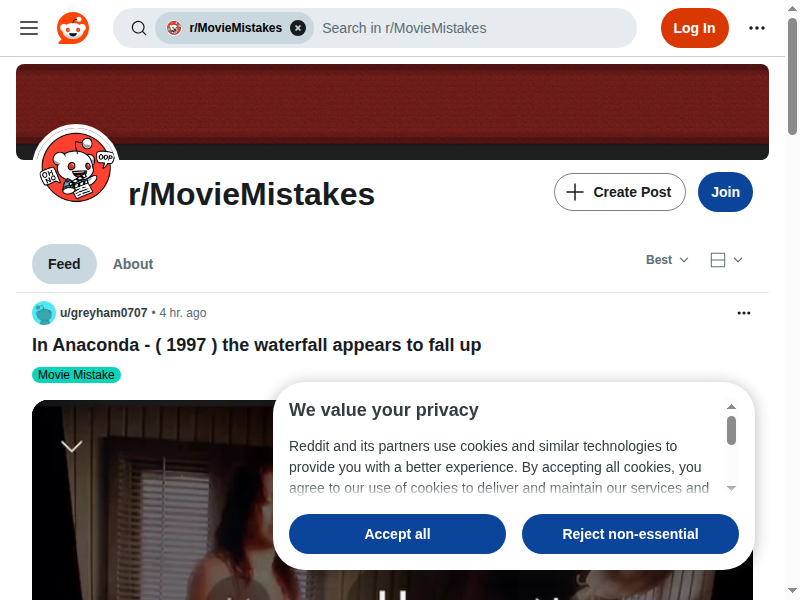
So what exactly does our code do here?
- Importing the library - with support for the
importstatement now being mainstream, we opted for that route instead of the more traditionalrequire()call - Launching the browser - with
puppeteer.launch(), we start the browser instance. Here, we also setheadlesstofalse, so that the browser instance is actually visible, which helps with debugging - Opening new tab - the call to
newPage()opens a new browser tab and returns a handle to it, which we save topage - Loading a page - our
pagehandle comes with agoto()method, which we use to load the desired page - Obtaining the screenshot - the
pagehandle also has ascreenshot()method, which allows us to save a screenshot of the current page - Cleaning up - last, but not least, we are good citizens and close our browser instance with
browser.close()
That was pretty smooth and straightforward, but let's take it from goto() a step further and actually scrape the site!
Scraping Reddit
The goal of our scraper is to extract the titles and links of the Reddit posts for a particular search term. For that, we want to load the Movie Mistakes subreddit, use the search bar at the top to perform the search, scrape the links which the search yielded, and eventually return the data as JSON-formatted output.
Let's see how we can do that! 💪
Performing the search
Keeping everything from our previous screenshot example, up to the goto() call, we first want to locate the search box at the top of the page:
We'll use a CSS selector for that, and as it is a regular text box, we can use the Page.type() method to enter the text we'd like to use for our eventual query. Here, we need to pass the relevant selector and the input in question.
ℹ️ With Reddit making heavy use of custom web component elements, we need to use Puppeteer's
>>>operator to get access to the shadow DOM.
await page.type('reddit-search-large >>> input[name="q"]', 'comedy');
With the text entered, we now need to submit our query by hitting the "virtual" Enter button.
await page.keyboard.press('Enter');
Done and done! Chrome should now submit the search query and we should have the search result after a few seconds.
Loading all links
Because the search page is generated on the client side, it may take a few seconds for the postings to show up, so we use Page.waitForSelector() for that purpose.
await page.waitForSelector('#main-content > div > search-telemetry-tracker', { timeout: 10000 });
Once the element appears, we could scrape the site, however Reddit employs infinite scrolling, so we need to take this into account as well. Taking a page from our article Infinite Scroll with Puppeteer, we add the following three helper functions and should be almost ready to scrape the content.
function delay(ms)
{
return new Promise((resolve) => setTimeout(resolve, ms));
}
function extractItems()
{
const extractedElements = document.querySelectorAll('#main-content > div > search-telemetry-tracker a[data-testid="post-title-text"]');
const items = [];
for (let element of extractedElements) items.push({ title: element.innerText, url: element.href });
return items;
}
async function scrapeItems(page)
{
let items = [];
try
{
let previousHeight;
while (items.length < 100)
{
items = await page.evaluate(extractItems);
previousHeight = await page.evaluate('document.body.scrollHeight');
await page.evaluate('window.scrollTo(0, document.body.scrollHeight)');
await page.waitForFunction(`document.body.scrollHeight > ${previousHeight}`);
await delay(800);
}
}
catch(e)
{
}
return items;
}
Scraping the content and clean-up
At this point, all we need to do is call the scrapeItems() function with our page object, wait for it to return the items it found, close the browser session, and print everything to standard output.
const items = await scrapeItems(page);
await browser.close();
console.log(items);
Let everything come together
Now that all the necessary pieces are in place, we can assemble the full code and save it to our index.js:
import puppeteer from 'puppeteer';
function delay(ms)
{
return new Promise((resolve) => setTimeout(resolve, ms));
}
function extractItems()
{
const extractedElements = document.querySelectorAll('#main-content > div > search-telemetry-tracker a[data-testid="post-title-text"]');
const items = [];
for (let element of extractedElements) items.push({ title: element.innerText, url: element.href });
return items;
}
async function scrapeItems(page)
{
let items = [];
try
{
let previousHeight;
while (items.length < 100)
{
items = await page.evaluate(extractItems);
previousHeight = await page.evaluate('document.body.scrollHeight');
await page.evaluate('window.scrollTo(0, document.body.scrollHeight)');
await page.waitForFunction(`document.body.scrollHeight > ${previousHeight}`);
await delay(800);
}
}
catch(e)
{
console.log(e)
}
return items;
}
// Launch the browser and open a new blank page
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
// Navigate the page to a URL.
await page.goto('https://www.reddit.com/r/MovieMistakes/');
// Type into search box using input name.
await page.type('reddit-search-large >>> input[name="q"]', 'comedy');
// Submit the search
await page.keyboard.press('Enter');
await page.waitForSelector('#main-content > div > search-telemetry-tracker', { timeout: 10000 });
const items = await scrapeItems(page);
console.log(items.length)
Now, we simply run the script with the following command
node index.js
Once the script finishes, we should have some output like the following:
[
{
title: 'Quicksand on Netflix',
url: 'https://www.reddit.com/r/MovieMistakes/comments/e2mew7/quicksand_on_netflix/'
},
{
title: 'Robert Downey Jr. Clipping Through a CGI Dragon in Dolittle (2020)',
url: 'https://www.reddit.com/r/MovieMistakes/comments/nqd55i/robert_downey_jr_clipping_through_a_cgi_dragon_in/'
},
.... more data here
Summary
Puppeteer is a powerful tool that gives you full control over a browser instance directly from your JavaScript code. With just a few lines, you can launch a complete Chrome environment and interact with any website as if you were browsing it manually. This enables a far more realistic scraping experience compared to traditional HTTP libraries, particularly for single-page applications and other JavaScript-heavy sites.
While Puppeteer is sufficient for many common scraping tasks, challenges such as rate limits, request throttling, IP blocks, and other anti-scraping measures can still block you from successfully scraping your target site. That's where services like our scraping API come in — providing a reliable and easy way to seamlessly access and scrape websites with minimum friction and maximum success.
💡 Free trial
If you want to give ScrapingBee a try, sign up and receive 1,000 free ScrapingBee API calls.
As always, happy scraping!
Before you go, check out these related reads:

Alexander is a software engineer and technical writer with a passion for everything network related.

