In previous articles, we talked about two different approaches to perform basic web scraping with Java. HtmlUnit for scraping basic sites and PhantomJS for scraping dynamic sites which make heavy use of JavaScript.
Both are tremendous tools and there's a reason why PhantomJS happened to be the leader in that market for a long time. Nonetheless, there occasionally were issues, either with performance or with support of web standards. Then, in 2017, there was a real game changer in this field, when both, Google and Mozilla, started to natively support a feature called headless mode in their respective browsers.

Welcome to Chrome scripting
Headless mode in Chrome has proven to be quite use- and powerful. It allows you to have the same kind of control and automation, you were used to with HtmlUnit and PhantomJS, but this time in the context of the very same browser engine you are using every day yourself, and which you are most likely using right now to read this article.
No more issues with only partially supported CSS features, possibly slightly incompatible JavaScript code, or performance bottlenecks with overly complex HTML pages. Your favourite browser engine is at your fingertips, only a couple of Java commands away.
All right, we have now marvelled long enough at the theory, time to get into coding.
Let's check it out
We will start with something simple and try to get a screenshot of Hacker News in our first example. Before we can jump right into coding and making our browser do our bidding, we first need to make sure we have the right environment and all the necessary tools.
As for the browser, the library we are going to use (spoiler, Selenium) actually supports a number of different browsers, though for our examples here we will focus on Chrome, but it should be easy to just switch the driver for a different browser engine.
So without further ado, here the list of packages you will need to run our code examples.
Prerequisites
- a recent JDK, version 8 or higher
- the latest version of Google Chrome
- a ChromeDriver binary matching your Chrome version
- the Selenium library
The setup
A screenshot, we said, right? But to make things a tad more interesting, it will be a screenshot with a twist. It will be an "authenticated" screenshot, so we will need to have a username and password and provide those to the sign-in dialogue.
For starters, we need to get an instance of a WebDriver object (as we are using Chrome, this will be ChromeDriver for the implementation), in order to be able to access the browser in the first place. We can achieve this relatively easily by specifying the path to our ChromeDriver binary in the webdriver.chrome.driver system property and instantiating a ChromeDriver class with a couple of options.
// Initialise ChromeDriver
String chromeDriverPath = "/Path/To/Chromedriver" ;
System.setProperty("webdriver.chrome.driver", chromeDriverPath);
ChromeOptions options = new ChromeOptions();
options.addArguments("--headless", "--window-size=1920,1200","--ignore-certificate-errors");
WebDriver driver = new ChromeDriver(options);
As for Chrome, ChromeDriver should automatically find its installation directory, but if you prefer a custom path, you can set it via ChromeOptions.setBinary.
options.setBinary("/Path/to/specific/version/of/Google Chrome");
💡 A full list of all ChromeDriver options can be found here.
The screenshot
Now, we are ready to get our screenshot. All we need to do is
- get the login page
- populate the username and password field with the correct values
- click the login button
- check if authentication worked
- get our well-deserved screenshot - PROFIT 💰
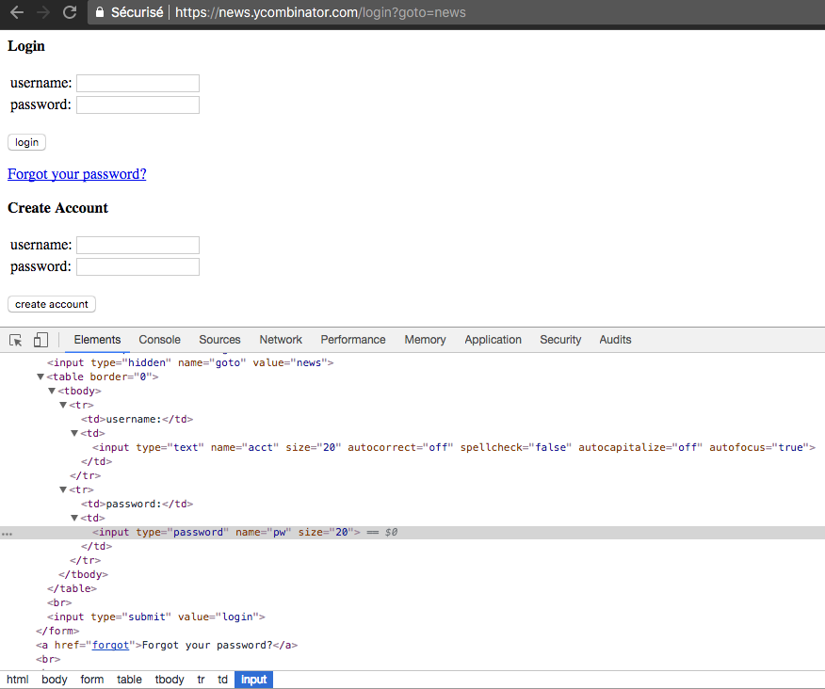
As we have already covered these steps in a previous article, we will simply provide the full code.
public class ChromeHeadlessTest {
private static String userName = "";
private static String password = "";
public static void main(String[] args) throws IOException {
String chromeDriverPath = "/your/chromedriver/path";
System.setProperty("webdriver.chrome.driver", chromeDriverPath);
ChromeOptions options = new ChromeOptions();
options.addArguments("--headless", "--window-size=1920,1200","--ignore-certificate-errors", "--silent");
WebDriver driver = new ChromeDriver(options);
// Get the login page
driver.get("https://news.ycombinator.com/login?goto=news");
// Search for username / password input and fill the inputs
driver.findElement(By.xpath("//input[@name='acct']")).sendKeys(userName);
driver.findElement(By.xpath("//input[@type='password']")).sendKeys(password);
// Locate the login button and click on it
driver.findElement(By.xpath("//input[@value='login']")).click();
if (driver.getCurrentUrl().equals("https://news.ycombinator.com/login")) {
System.out.println("Incorrect credentials");
driver.quit();
System.exit(1);
}
System.out.println("Successfully logged in");
// Take a screenshot of the current page
File screenshot = ((TakesScreenshot) driver).getScreenshotAs(OutputType.FILE);
FileUtils.copyFile(screenshot, new File("screenshot.png"));
// Logout
driver.findElement(By.id("logout")).click();
driver.quit();
}
}
Voilà, that should be it. Once you compile and run that code, you should have a file called screenshot.png in your working directory, with a gorgeous screenshot of the Hacker News homepage, including your username and a logout link.
What else?
Getting a live screenshot from your browser is great, but do you know what's even better? Interacting with the website.
There are plenty of different opinions on infinite scrolling. And while some love it and some do not, it is a common theme in today's web design and has always been a bit tricky to handle in web scraping, due to its dynamic content nature and the heavy involvement of JavaScript. And that's exactly an area where a full-fledged browser engine will come to shine, as it will allow you to handle the page in its completely natural way, without any workarounds. Let's have a look, shall we?
Infinite scrolling
There are lots of services out there using infinite scrolling, but as we really want to focus on the scrolling part this time, and not so much on handling authentication, we are following the tradition of any half-decent TV chef and use the scrolling example ScrapingBee already prepared at https://demo.scrapingbee.com/infinite_scroll.html.
Bottom line, that page really is the definition of infinite scrolling, as long as you scroll to the bottom of the page, it will append more content.
How do we handle this now?
For starters, we set up the same environment we used in our previous example. This includes setting the reference to ChromeDriver, initialising a WebDriver instance, and loading the page with WebDriver.load(). So far, so good, nothing much new.
The first new thing will be, that we will want to determine the initial height of the page, using our newly introduced getCurrentHeight() method.
private static long getCurrentHeight(JavascriptExecutor js)
{
Object obj = js.executeScript("return document.body.scrollHeight");
if (!(obj instanceof Long)) throw new RuntimeException("scrollHeight did not return a long");
return (long)obj;
}
Here, we essentially run the JavaScript snipped return document.body.scrollHeight in the context of the page, which provides us with the current height of the page. We save that information in prevHeight and use it later to check if the height of the page changed. Next, infinity! ♾
We now run an infinite loop (well, as with all such loops we need a rather solid exit clause), where we first fetch the last content element on our page with the XPath expression (//div[@class='box'])[last()] and get its content with WebElement.getText(). That will serve as our content ID.
WebElement lastElement = driver.findElement(By.xpath("(//div[@class='box'])[last()]"));
int id = Integer.parseInt(lastElement.getText());
Once we have our content ID, we can scroll to the bottom and hope that our site will load additional content (which in our case it always will). To do that, we - again - run a small JavaScript snippet, using window.scrollTo(), and wait a couple of milliseconds. We will now check if we have met our exit condition yet, and if not, continue the loop.
js.executeScript("window.scrollTo(0, document.body.scrollHeight);");
Thread.sleep(500);
long height = getCurrentHeight(js);
if (id > 100 || height == prevHeight || height > 30000) break;
prevHeight = height;
Our exit condition, right! Even though infinite scrolling really is loved by many, we really want to avoid literally entering an infinite loop. To do that, we assume that we will be happy once we've got at least 100 elements or the page is at least 30,000 pixel tall. Of course, once the height stays the same, there's not much more to load for us either.
Once we have exited our loop, we only need to collect all the content and we're all set.
List<WebElement> boxes = driver.findElements(By.xpath("//div[@class='box']"));
for (WebElement box : boxes) System.out.println(box.getText());
And now for the grand finale, the full code.
public class InfiniteScrolling
{
public static void main(String[] args) throws IOException, Exception {
String chromeDriverPath = "/your/chromedriver/path";
System.setProperty("webdriver.chrome.driver", chromeDriverPath);
ChromeOptions options = new ChromeOptions();
options.addArguments("--headless", "--window-size=1920,1200","--ignore-certificate-errors", "--silent");
WebDriver driver = new ChromeDriver(options);
JavascriptExecutor js = (JavascriptExecutor)driver;
// Load our page
driver.get("https://demo.scrapingbee.com/infinite_scroll.html");
// Determine the initial height of the page
long prevHeight = getCurrentHeight(js);
while (true)
{
// Get the last div element of class box
WebElement lastElement = driver.findElement(By.xpath("(//div[@class='box'])[last()]"));
// Consider the element's text content the ID
int id = Integer.parseInt(lastElement.getText());
// Scroll to the bottom and wait for 500 milliseconds
js.executeScript("window.scrollTo(0, document.body.scrollHeight);");
Thread.sleep(500);
// Get the current height of the page
long height = getCurrentHeight(js);
// Stop if we reached at least 100 elements, the bottom of the page, or a height of 30,000 pixels
if (id > 100 || height == prevHeight || height > 30000) break;
prevHeight = height;
}
// Get all div elements of class "box" and print their IDs
List<WebElement> boxes = driver.findElements(By.xpath("//div[@class='box']"));
for (WebElement box : boxes) System.out.println(box.getText());
driver.quit();
}
private static long getCurrentHeight(JavascriptExecutor js)
{
Object obj = js.executeScript("return document.body.scrollHeight");
if (!(obj instanceof Long)) throw new RuntimeException("scrollHeight did not return a long");
return (long)obj;
}
}
Disable images
While images are lovely to look at and can truly improve overall user experience, they often are somewhat superfluous for the purpose of web scraping. Especially in the context of a proper browser engine, they will be always downloaded, however, and can impact performance and network traffic, especially on a larger scale.
A relatively easy fix is to instruct the browser not to download images and only focus on the actual HTML content, along with JavaScript and CSS. And that's exactly what we are now going to do.
Let's take a very image-rich site as an example, Pinterest, and take our original screenshot code and adapt it, to only load the home page of pinterest.com and take a screenshot.
String chromeDriverPath = "/your/chromedriver/path";
System.setProperty("webdriver.chrome.driver", chromeDriverPath);
ChromeOptions options = new ChromeOptions();
options.addArguments("--headless", "--window-size=1920,1200","--ignore-certificate-errors", "--silent");
WebDriver driver = new ChromeDriver(options);
// Load our page
driver.get("https://www.pinterest.com/");
// Take a screenshot of the current page
File screenshot = ((TakesScreenshot) driver).getScreenshotAs(OutputType.FILE);
FileUtils.copyFile(screenshot, new File("screenshot.png"));
driver.quit();
Once we compile and run that code, we will get a file called screenshot.png with a similar output as the following.
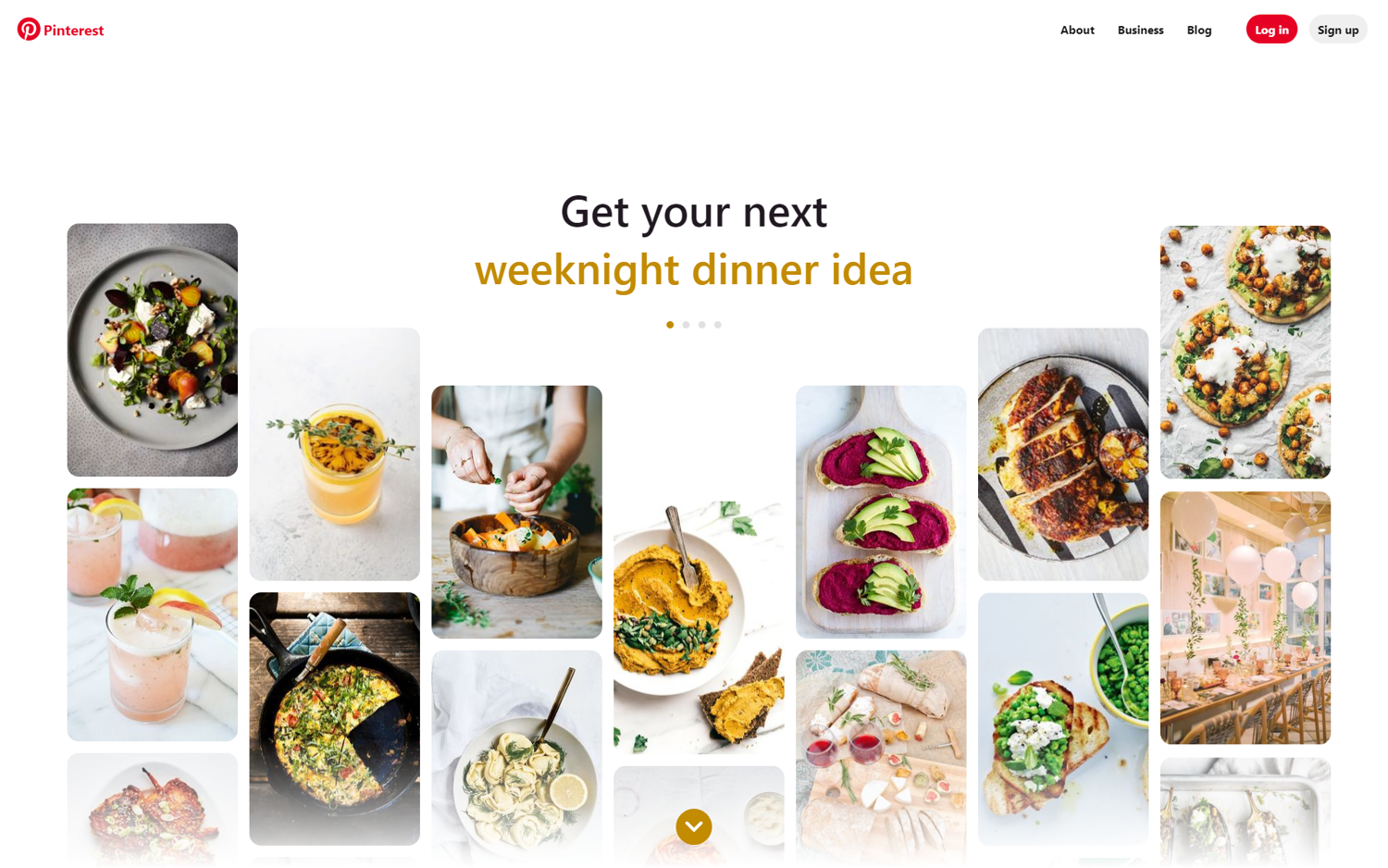
Sans images s'il vous plait
Now, if we wanted to run the same request but have the browser ignore the images, all we would need to do, is add the blink-settings=imagesEnabled parameter to the ChromeOptions list and set it to false.
options.addArguments("--headless", "--window-size=1920,1200","--ignore-certificate-errors", "--silent", "--blink-settings=imagesEnabled=false");
If we run this code now, we will get the same screenshot, but without images.
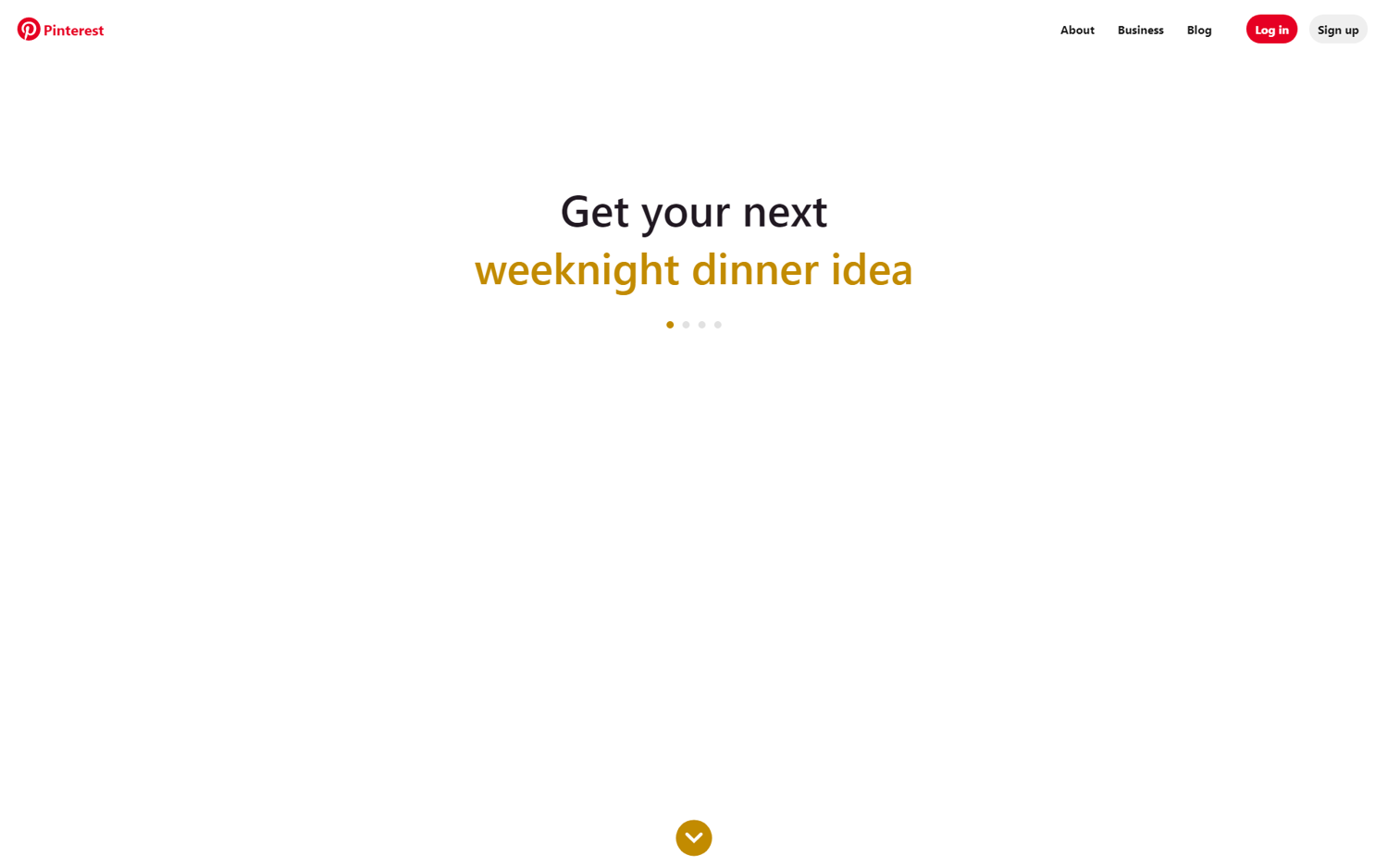
Even though, we specifically took a screenshot here, this will be obviously less useful if your project depends on accurate screenshots, but it can save you quite a fair share of traffic costs if you are primarily after text data.
Conclusion
As you can see Chrome headless is really easy to use and it is hardly any different from PhantomJS, since we are using Selenium to run it.
💡 Check out our new no-code web scraping API, if your project requires data extraction, but you are tired of blocked requests, overcomplicated JavaScript rendering, CAPTCHAs, and similar obstacles. The first 1,000 API calls are on us.
As usual, the code is available in this Github repository.

Kevin worked in the web scraping industry for 10 years before co-founding ScrapingBee. He is also the author of the Java Web Scraping Handbook.


