Google search engine results pages (SERPs) can provide alot of important data for you and your business but you most likely wouldn't want to scrape it manually. After all, there might be multiple queries you're interested in, and the corresponding results should be monitored on a regular basis. This is where automated scraping comes into play: you write a script that processes the results for you or use a dedicated tool to do all the heavy lifting.
In this article you'll learn how to scrape Google search results with Python. We will discuss three main approaches:
- Using the Scrapingbee API to simplify the process and overcome anti-bot hurdles (hassle free)
- Using a graphical interface to construct a scraping request (that is, without any coding)
- Writing a custom script to do the job
We will see multiple code samples to help you get started as fast as possible.
Shall we get started?
You can find the source code for this tutorial on GitHub.

Why scrape search results?
The first question that might arise is "why in the world do I need to scrape anything?". That's a fair question, actually.
- You might be an SEO tool provider and need to track positions for billions of keywords.
- You might be a website owner and want to check your rankings for a list of keywords regularly.
- You might want to perform competitor analysis. The simplest thing to do is to understand how your website ranks versus that other guy's website: in other words, you'll want to assess your competitor's positions for various keywords.
- Also, it might be important to understand what customers are into these days. What are they searching for? What are the modern trends? For this kind of search-interest and topic trend analysis, you can use our Google Trends API to pull time-series demand data and combine it with your scraped SERP results.
- If you're a content creator, it will be important for you to analyze potential topics to cover. What your audience would like to read about?
- Perhaps, you might need to perform lead generation, monitor certain news, prices, or research and analyze a given field.
In fact, as you can see, there are many reasons to scrape the search results. But while we understand "why", the more important question is "how" which is closely tied to "what are the potential issues". Let's talk about that.
Challenges of scraping Google search results
Unfortunately, scraping Google search results is not as straightforward as one might think. Here are some typical issues you'll probably encounter:
Aren't you a robot, by chance?
I'm pretty sure I'm not a robot (mostly) but for some reason Google keeps asking me this question for years now. It seems he's never satisfied with my answer. If you've seen those nasty "I'm not a robot" checkboxes also known as "captcha" you know what I mean.
So-called "real humans" can pass these checks fairly easily but if we are talking about scraping scripts, things become much harder. Yes, you can think of a way to solve captchas but this is definitely not a trivial task. Moreover, if you fail the check multiple times your IP address might get blocked for a few hours which is even worse. Luckily, there's a way to overcome this problem as we'll see next.
Do you want some cookies?
If you open Google search home page via your browser's incognito mode, chances are you're going to see a "consent" page asking whether you are willing to accept some cookies (no milk though). Until you click one of the buttons it won't be possible to perform any searches. As you can guess, the same thing might happen when running your scraping script. Actually, we will discuss this problem later in this article.
Don't request so much from me!
Another problem happens when you request too much data from Google, and it becomes really angry with you. It might happen when your script sends too many requests too fast, and consequently the service blocks you for a period of time. The simplest solution is to wait, or to use multiple IP addresses, or to limit the number of requests, or... perhaps there's some other way? We're going to find out soon enough!
Lost in data
Even if you manage to actually get some reasonable response from Google, don't celebrate yet. Problem is, the returned HTML data contains lots and lots of stuff that you are not really interested in. There are all kinds of scripts, headers, footers, extra markup, and so on and so forth. Your job is to try and fetch the relevant information from all this gibberish but it might appear to be a relatively complex task on its own.
Problem is, Google tends to use not-so-meaningful tag IDs due to certain reasons, therefore you can't even create reliable rules to search the content on the page. I mean, yesterday the necessary tag ID was yhKl7D (whatever that means) but today it's klO98bn. Go figure.
Using an API vs doing it yourself
So, what options do we have at the end of the day? You can craft your very own solution to scrape Google, or you can take advantage of a third-party API to do all the heavy lifting.
The benefits of writing a custom solution are obvious. You are in full control, you 100% understand how this solution works (well, I hope), you can make any enhancements to it as needed, plus the maintenance is like zero bucks. What are the downsides? For one thing, crafting a proper solution is hard due to the issues listed above. To be honest, I'd rather re-read "War and Peace" (I never liked this novel in school, sorry mr. Tolstoy) then agree to write such a script. Also, Google might introduce some new obscure stuff that would make your script turn into potato until you understand what's wrong. Also, you'll probably still need to purchase some servers/proxies to overcome rate limitations and other related problems.
So, let's suppose for a second that you are not an adventuring type and don't want to solve all the problems by yourself. In this case I'm happy to present you another way: use our Google Search Results Scraper API that can alleviate 95% of the problems. You don't need to think about how to fetch the data anymore. Rather, you can concentrate on how to use and analyze this data — after all, I'm pretty sure that's your end goal. And if you also need to collect visual assets from SERPs, such as product photos or thumbnails, you can complement it with our Google Image Scraper API to automatically extract images from Google.
Yes, a third-party API comes with a cost but frankly speaking it's worth every penny becasue it will save you time and hassle. You don't need to think about those annoying captchas, rate limitations, IP bans, cookie consents, and even about HTML parsing. It goes like this: you send a single request and only the relevant data without any extra stuff is delivered straight to your room in a nicely formatted JSON rather than ugly HTML (but you can download the full HTML if you really want). Sounds too good to be true? Isn't it a dream? Welcome to the real world, mr. Anderson.
How to scrape Google search results with Scrapingbee
Without any further ado, I'm going to explain how to work with the ScrapingBee API to easily scrape Google search results of various types. I'm assuming that you're familiar with Python (no need to be a smooth pro), and you have Python 3 installed on your PC.
If you are not really a developer and have no idea what Python is, don't worry. Please skip to the "Scraping Google search results without coding" section and continue reading.
Quickstart
Okay, so let's get down to business!
To get started, grab your free ScrapingBee trial. No credit card is required, and you'll get 1000 credits (each request costs around 25 credits).
After logging in, you'll be navigated to the dashboard. Copy your API token as we'll need it to send the requests:
- Next, create your Python project. It can be a regular
.pyscript but I'm going to use a dependency management and packaging tool called Poetry to create a project skeleton:
poetry new google_scraper
- We'll need a library to send HTTP requests, so make sure to install Requests library by running
pip install requestsor by adding it to thepyproject.tomlfile (if you're using Poetry):
[tool.poetry.dependencies]
requests = "^2.31"
In the latter case don't forget to run poetry install.
- Create a new Python file. For example, I'll create a new
google_scraperdirectory in the project root and add ascraping_bee_classic.pyfile inside. Let's suppose that we would like to scrape results for the "pizza new-york" query. Here's the boilerplate code:
import requests
response = requests.get(
url="https://app.scrapingbee.com/api/v1/google", # ScrapingBee endpoint to query Google
params={
"api_key": "YOUR_API_KEY", # Your key from step 2
"search": "pizza new-york", # Your search term
},
)
print('Response HTTP Status Code: ', response.status_code)
print('Response HTTP Response Body: ', response.content)
So, here we're are using ScrapingBee Google endpoint to perform scraping. Make sure to provide your api_key from the second step, and adjust the search param as needed to the keyword you want to scrape SERPs for.
By default the API will return results in English but you can adjust the language param to override this behavior.
The response.content will contain all the data in JSON format. However, it's important to understand what exactly this data contains therefore let's briefly talk about that.
Interpreting scraped data
So, the response.content will return JSON data and you can find the sample response in the official docs. Let's cover some important fields:
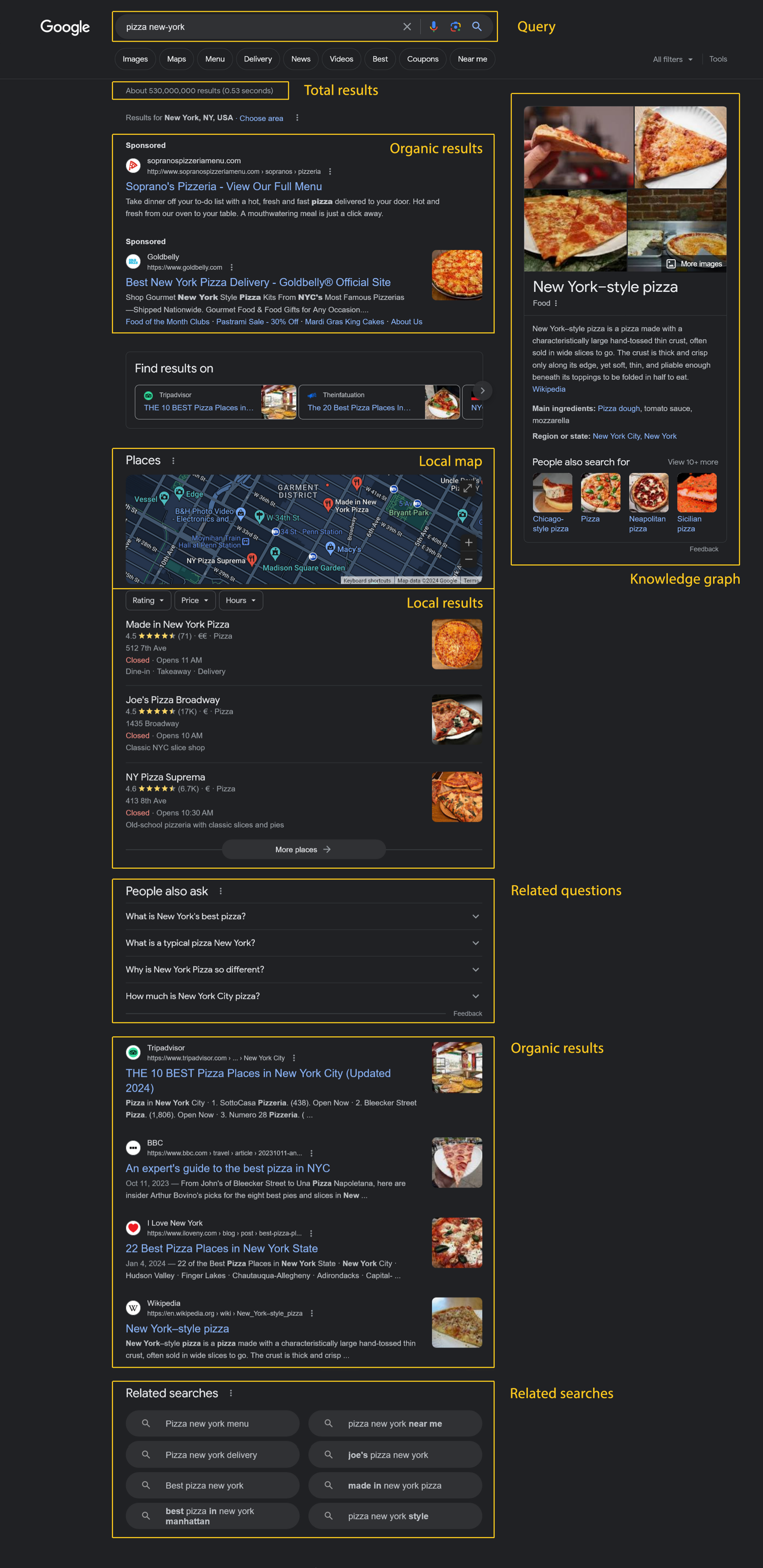
meta_data— your search query in the form ofhttps://www.google.com/search?q=..., number of results, number of organic results.organic_results— these are the actual "search results" as most people see them. For every result there's aurlfield as well asdescription,position,domain.local_results— results based on the chosen location. For example, in our case we'll see some top pizzerias in New York. Every item containstitle,review(rating of the place from 0 to 5, for example,4.5),review_count,position.top_ads— advertisement on the top. Containsdescription,title,url,domain.related_queries— some similar queries people were searching for. Containstitle,url,position.questions— the most popular questions with answers related to the current query. Containstextandanswer.knowledge_graph— general information related to the query usually composed from resources like Wikipedia. Containstitle,type,images,website,description.map_results— contains information about locations relevant to the current query. Containsposition,title,address,rating,price(for example$for cheap,$$$for expensive). We will see how to fetch map results later in this article.
Here's an image showing where the mentioned results can be found on the actual Google search page:
Displaying scraped results
Okay, now let's try to display the fetched results in a more user-friendly way. To achieve that, first import the json module because — guess what — we'll need to parse JSON content:
import json
Let's display some organic search results:
# imports...
# ScrapingBee request...
data = json.loads(response.content)
print("=== Organic search results ===")
for result in data["organic_results"]:
print("\n\n")
print(f"{result['position']}. {result['title']}")
print(result["url"])
print(result["description"])
By default you'll get up to 100 results but it's possible to request less by adjusting the nb_results parameter:
response = requests.get(
url="https://app.scrapingbee.com/api/v1/google",
params={
"api_key": "API_KEY",
"search": "pizza new-york",
"nb_results": "20", # <===
},
)
You can also provide the page param to work with pagination.
Next, display local search results:
print("\n\n=== Local search results ===")
for result in data["local_results"]:
print(f"{result['position']}. {result['title']}")
print(f"Rating: {result["review"]} (based on {result['review_count']} reviews)")
print("\n\n")
Let's now list the related queries:
print("\n\n=== Related queries ===")
for result in data["related_queries"]:
print(f"{result['position']}. {result['title']}")
print("\n")
And finally some relevant questions:
print("\n\n=== Relevant questions ===")
for result in data["questions"]:
print(f"Question:\n{result['text']}")
print(f"\n{result['answer']}")
print("\n\n")
Great job!
Monitoring and comparing website positions
Of course that's not all as you can now use the returned data to perform custom analysis. For example, let's suppose we have a list of domains that we would like to monitor search results positions for. Specifically, I'd like my script to say "this domain previously had position X but its current position is Y".
Let's also suppose we have historical data stored in a regular CSV file therefore create a new file google_scraper/data.csv:
tripadvisor.com,bbc.com,foodnetwork.com
4,13,10
Here we are storing previous positions for three domains. Make sure to add a newline at the end of the file because we will append to it later.
Now let's create a new Python script at google_scraper/scraping_bee_comparison.py:
import requests
import json
import os
import csv
response = requests.get(
url="https://app.scrapingbee.com/api/v1/google",
params={
"api_key": "YOUR_API_KEY",
"search": "pizza new-york",
},
)
data = json.loads(response.content)
Next, let's produce a list of the monitored domains as well as a dictionary to store their current positions:
# ...
domains = ["tripadvisor.com", "bbc.com", "foodnetwork.com"]
domain_positions = dict([(domain, 0) for domain in domains])
The default position for every domain is 0 which means that we haven't really determined it yet.
Iterate over the results and find the desired domain:
# ...
for result in data["organic_results"]:
# Strip out the www. part:
current_domain = result["domain"].replace("www.", "")
# If this is the required domain and we haven't seen it yet:
if current_domain in domains and domain_positions[current_domain] == 0:
domain_positions[current_domain] = result["position"]
Please note that the domain field in the returned response might contain the www. part so we just strip it out.
Also note that the same domain might be included into the search results multiple times, and currently we are interested only in its highest position. The results are sorted by their positions, thus, if the domain_positions[current_domain] already contains some non-zero value, we skip this domain.
Great, now we have information about the current domain positions. The next step is to open our CSV file:
# ...
# Current root:
root = os.path.dirname(os.path.abspath(__file__))
print("\n=====")
print(f"Let's compare positions for the requested domains!")
# Open CSV for reading:
with open(os.path.join(root, "data.csv"), newline="") as csvfile:
reader = csv.DictReader(csvfile)
I'd like to work with the CSV data as with regular dictionary, so use the DictReader here.
Read the CSV file and display the corresponding information:
# ...
with open(os.path.join(root, "data.csv"), newline="") as csvfile:
reader = csv.DictReader(csvfile)
# For every monitored domain
for domain in domains:
# Rewind to the beginning of the file
csvfile.seek(0)
print("\n---")
# Do we have any info on the current domain position?
if domain_positions[domain] == 0:
print(f"Unfortunately I was not able to find {domain} in the results...")
else:
print(f"{domain} has position {domain_positions[domain]}")
print("Here are the historical records for this domain:")
# Get info for the current domain from CSV:
for row in reader:
print(row[domain])
Please note that we read the CSV file multiple times for each domain therefore it's important to say csvfile.seek(0) to rewind it to the beginning.
Finally, I'd like to update our historical data with new values:
# Open the file in "append" mode:
with open(os.path.join(root, "data.csv"), "a", newline="") as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=domains)
# Add a new row at the end of the file:
writer.writerow(domain_positions)
Make sure to provide the a mode when opening the file because we want to append data, not overwrite those.
We use the DictWriter to work with the CSV file as with a dictionary. Then simply say writerow and pass our dictionary. It should work properly because the dictionary's keys have the same values as the headers in the CSV file (in other words, we use the same domains).
This is it, brilliant! As you can see, the overall process is very straightforward and you don't need to worry how the results are being fetched — instead, you focus on how to use these results.
Displaying map results
You might also want to display results from the Google map so let's see how to achieve that. Create a new Python script google_scraper/scraping_bee_map.py:
import requests
import json
response = requests.get(
url="https://app.scrapingbee.com/api/v1/google",
params={
"api_key": "API_KEY",
"search": "pizza new-york",
"search_type": "maps", # make sure to adjust the type!
},
)
data = json.loads(response.content)
Please note that in this case we set the search_type to maps (another supported type is news).
Now simply iterate over the fetched results:
# ...
print("\nHere are the map results:")
for result in data["maps_results"]:
print(f"{result['position']}. {result['title']}")
print(f"Address: {result['address']}")
print(f"Opening hours: {result['opening_hours']}")
print(f"Link: {result['link']}")
print(f"Price: {result['price']}")
print(f"Rating: {result['rating']}, based on {result['reviews']} reviews")
print("\n\n")
This is it!
Scraping Google search results with our API builder
If you are not a developer but would like to scrape some data, ScrapingBee is here to help you!
If you haven't already done so, register for free and then proceed to the Google API Request Builder:

Adjust the following options:
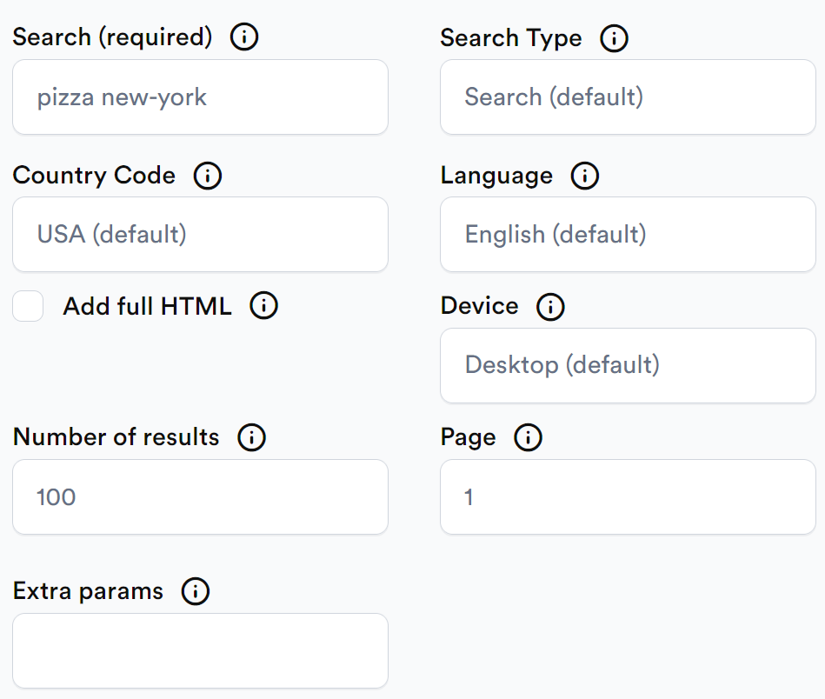
- Search — the actual search query.
- Country code — the country code from which you would like the request to come from. Defaults to USA.
- Number of results — the number of search results to return. Defaults to 100.
- Search type — defaults to "classic", which is basically what you are doing when entering a search term on Google without any additional configuration. Other supported values are "maps" and "news". If you specifically need job listings from Google’s job search interface, you can also use our Google Jobs Scraper API.
- Language — the language to display results in. Defaults to English.
- Device — defaults to "desktop" but can also be "mobile".
- Page — default to 1, can be any non-negative value.
Once you are ready, click Try it:
Wait for a few moments, and the scraping results will be provided for you:
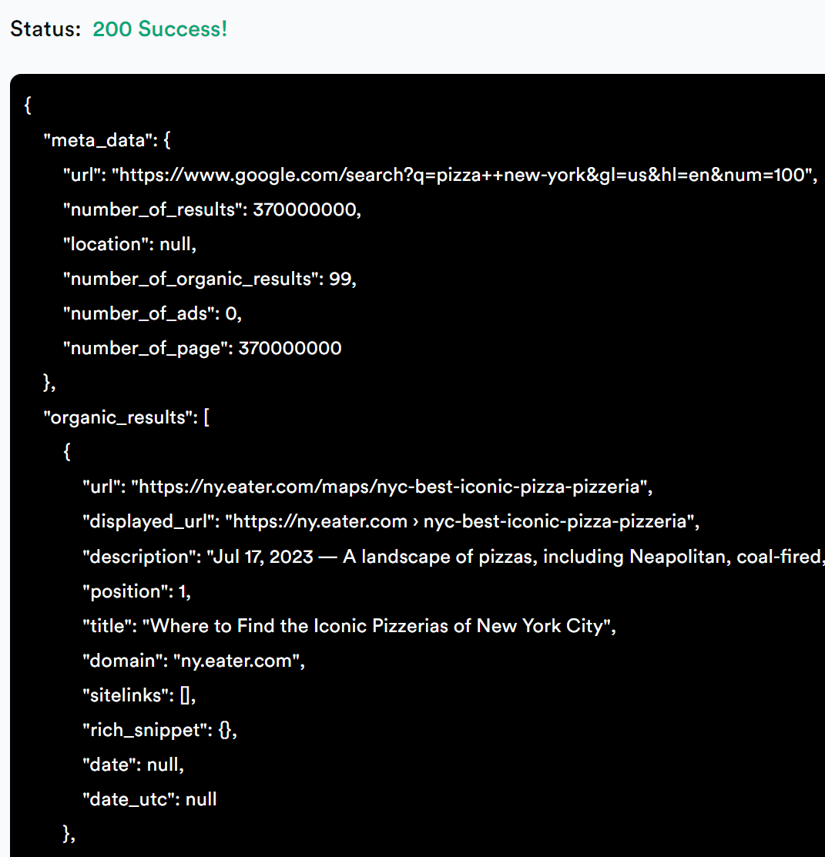
That's it, you can now use these results for your own purposes!
How to scrape Google search results DIY with just Python
Now let's discuss the process of scraping Google search results without any third-party services, only by using our faithful Python.
Preparations
To achieve that, you'll need to install a library called BeautifulSoup. No, I'm not pulling your leg, this is a real library enabling us to easily parse HTML content. Install it:
pip install beautifulsoup4
Or, if you're using Poetry, add it to the pyproject.toml file:
beautifulsoup4 = "^4.12"
Then don't forget to run poetry install. BeautifulSoup and Poetry — what could be better than that?
Now let's create a new file google_scraper/scrape_diy.py:
import requests
from bs4 import BeautifulSoup
Sending request
Let's suppose that we would like to scrape information about... well, web scraping, for instance. I mean, why not?
text = "web scraping"
url = "https://google.com/search?q=" + text
Now you could try sending the request to Google right away but most likely you won't get the response you're expecting. The lack of outcome is indeed an outcome by itself but still.
The problem is that Google will most likely present a cookie consent screen to you asking to accept or reject cookies. But unfortunately we can't really accept anything in this case because our script literally has no hands to move the mouse pointer and click buttons, duh.
Actually, this is a problem on its own but there's one solution: craft a cookie when making a request so that Google "thinks" you've already seen the consent screen and accepted everything. That's right: send a cookie that says you've accepted cookies.
cookies = {"CONSENT": "YES+cb.20220419-08-p0.cs+FX+111"}
Unfortunately, this is not a 100% reliable method and in your case the value might need to be slightly adjusted.
Also let's prepare a fake user agent (feel free to modify it):
headers = {
"User-Agent": "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:109.0) Gecko/20100101 Firefox/118.0"
}
Send the request:
response = requests.get(url, headers=headers, cookies=cookies)
Parsing HTML
The response will contain a body with the regular HTML. This is where our BeautifulSoup steps in as we'll use it to traverse the HTML content:
soup = BeautifulSoup(response.content, "html.parser")
Now let's detect all h3 on the page that are nested within the #search tag:
heading_object = soup.select("#search h3")
It appears that Google displays all the search results within the div#search tag, and every result's header is h3. BeautifulSoup enables us to construct queries similar to regular CSS, therefore #search h3 reads as "all h3 within the tag #search".
Nice! Now you can simply iterate over the found headers. Unfortunately, in some cases the header does not really belong to the search result thus let's check if the header's parent contains an href (in other words, its parent is a link):
for i, result in enumerate(heading_object):
if "href" in result.parent.attrs:
print(i + 1)
print(result.string)
result.string will return the actual text within the header.
You can also display the parent's href in the following way:
print(info.parent.attrs["href"])
Great job!
Using ScrapingBee to send requests
Actually, that's where ScrapingBee can also assist you because we provide a dedicated Python client to send HTTP requests. This client enables you to use proxies, make screenshots of the HTML pages, adjust cookies, headers, and more.
To get started, install the client by running pip install scrapingbee (or add it into your pyproject.toml), and import it inside your Python script:
from scrapingbee import ScrapingBeeClient
client = ScrapingBeeClient(
api_key="YOUR_API_KEY"
)
Now simply send the request:
response = client.get(
"https://www.google.com/search?q=Best+Laptops+in+Europe&tbm=shop",
params={
# Special setting for Google:
"custom_google": "true",
# Enable proxy:
# 'premium_proxy': 'true',
# 'country_code': 'gb',
"block_resources": "false",
"wait": "1500", # Waiting for the content to load (1.5 seconds)
"screenshot": True,
# Specify that we need the full height
"screenshot_full_page": True,
"forward_headers": True, # forward headers
},
cookies=cookies,
headers=headers,
)
After the script is executed, an image containing a page screenshot will be created in your current directory.
Of course, you can also parse the response body as before:
soup = BeautifulSoup(response.content, "html.parser")
Quite simple, eh?
💡Interested in analysing PPC competitors to see what they're ranking for and how their ad copy changes? Check out our guide on how to build a Google Ads Competitor Monitoring System
Conclusion
In this article we have discussed how to scrape Google search results with Python. We have seen how to use ScrapingBee for the task and how to write a custom solution. Please find the source code for this article on GitHub.
Thank you for your attention, and happy scraping!
Before you go, check out these related reads:

Ilya is an IT tutor and author, web developer, and ex-Microsoft/Cisco specialist. His primary programming languages are Ruby, JavaScript, Python, and Elixir. He enjoys coding, teaching people and learning new things. In his free time he writes educational posts, participates in OpenSource projects, tweets, goes in for sports and plays music.
