Beautiful Soup is super easy to use for parsing HTML and is hugely popular. However, if you're extracting a gigantic amount of data from tons of scraped pages it can slow to a crawl if not properly optimized.
In this tutorial, I'll show you 10 expert-level tips and tricks for transforming Beautiful Soup into a blazing-fast data-extracting beast and how to optimize your scraping process to be as fast as lightning.
Factors affecting the speed of Beautiful Soup
Beautiful Soup's performance can vary based on several factors. Here are some key factors that influence the speed of web scraping using Beautiful Soup.
- Parser Choice: The parser you choose (such as
lxml,html.parser, orhtml5lib) significantly impacts Beautiful Soup's speed and performance. - Document Complexity: Parsing large or complex HTML/XML documents can be resource-intensive, which ultimately results in slower execution times.
- CSS Selectors: Using complex or inefficient CSS selectors can slow down the parsing process.
- Connection Overhead: Repeatedly establishing new connections for each request can significantly reduce the speed. So, using sessions or persistent connections can help a lot.
- Concurrency: Using multi-threading or asynchronous processing allows you for concurrent fetching and parsing, which improve the overall speed.
Many other factors affect Beautiful Soup's performance, which we'll explore further in the following sections, along with strategies to make beautiful soup faster.
How to profile the different performance factors
Profiling is an important step in identifying performance bottlenecks in any software application. Python provides several tools for profiling, with cProfile being one of the most commonly used for identifying slow parts of the code. By analyzing the output of a profiler, developers can pinpoint areas that require optimization and implement alternative approaches to make beautiful soup faster.
cProfile is a built-in Python module that allows you to profile the execution time of various parts of a program.
Here's a quick example of how to profile a code:
import cProfile
from bs4 import BeautifulSoup
import requests
def fetch_data(url):
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
return soup.title.text
# Profiling the function to analyze performance
cProfile.run('fetch_data("https://news.ycombinator.com")')
The result is:
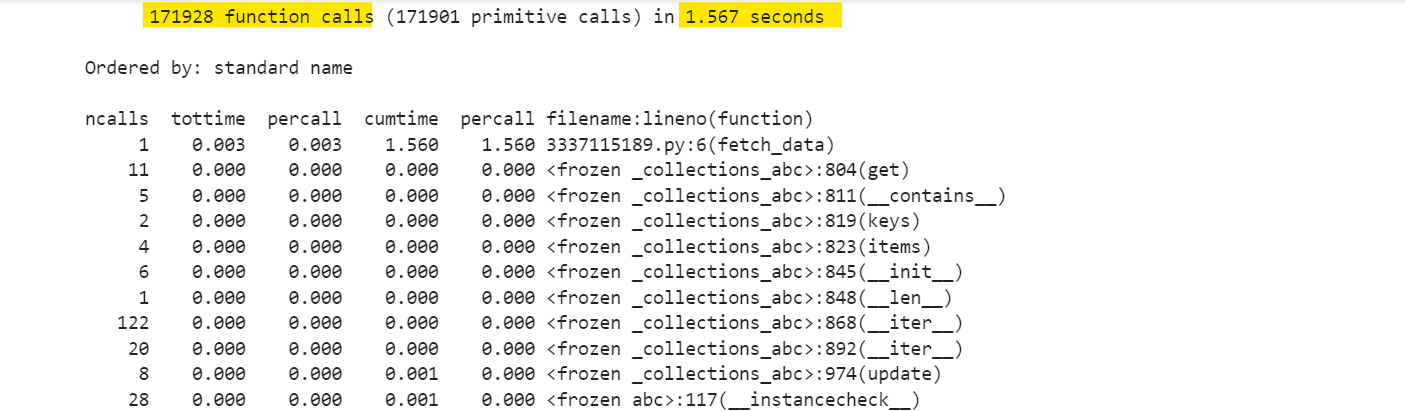
So, we’re using cProfile.run() for a quick overview of the performance.
If you want more detailed and sorted profiling results, you can add the following code to sort and format the output:
import cProfile
import pstats
from bs4 import BeautifulSoup
import requests
def fetch_data(url):
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
return soup.title.text
# Profiling the function to analyze performance
cProfile.run('fetch_data("https://news.ycombinator.com")', "my_profile")
p = pstats.Stats("my_profile")
p.sort_stats("cumulative").print_stats() # Sort by cumulative time
The result is:
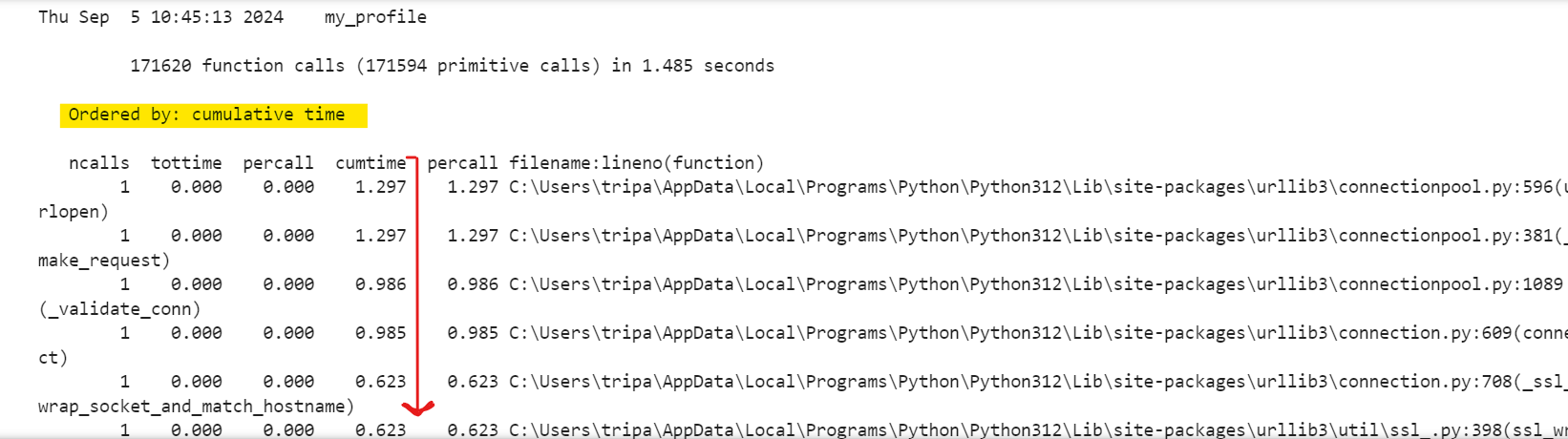
Here, we’re pstats.Stats with sorting options like cumulative to get more detailed and sorted output.
By using tools like cProfile to identify bottlenecks and employing strategies such as choosing the right parser, optimizing CSS selectors, leveraging concurrency, and implementing caching, developers can significantly improve the efficiency of their web scraping projects.
Tip 1: Effective use of parsers in beautiful soup
One of the main factors that impact the performance of Beautiful Soup is the choice of parser. A common mistake many developers make is selecting any parser without considering its effect on speed and efficiency. Beautiful Soup supports multiple parsers, including html.parser, lxml, and html5lib, each with its unique features and performance characteristics.
Choosing the right parser can significantly make beautiful soup faster. But how do you select the best parser for your specific needs? Let's look at the several options to help you make the correct decision.
html5lib
html5lib is a parser that's great for handling messy HTML because it parses documents the same way a web browser would. It's especially useful when dealing with poorly structured HTML or pages that use newer HTML5 elements. However, this flexibility comes at the cost of slower performance compared to other parsers.
Here's the code:
import cProfile
import requests
from bs4 import BeautifulSoup
# Function to parse HTML content using html5lib parser
def parse_html(url):
response = requests.get(url)
soup = BeautifulSoup(response.content, "html5lib")
# Profile the parse_html function using cProfile
cProfile.run('parse_html("https://news.ycombinator.com/")')
The result is:
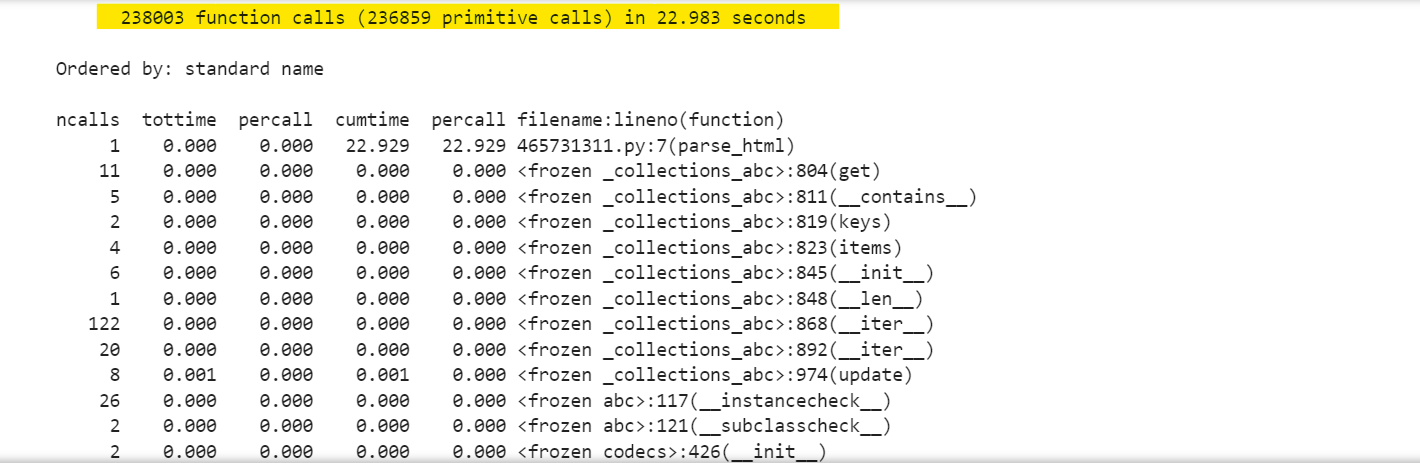
The results for the html5lib parser show that it made 318,133 function calls in 1.030 seconds.
html.parser
html.parser is the default parser that comes with Python's standard library, and it offers better performance than html5lib. It's a good choice for smaller projects or when dealing with HTML that is relatively well-structured.
Here's the code:
import cProfile
import requests
from bs4 import BeautifulSoup
# Function to parse HTML content using html.parser parser
def parse_html(url):
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
# Profile the parse_html function using cProfile
cProfile.run('parse_html("https://news.ycombinator.com/")')
The result is:
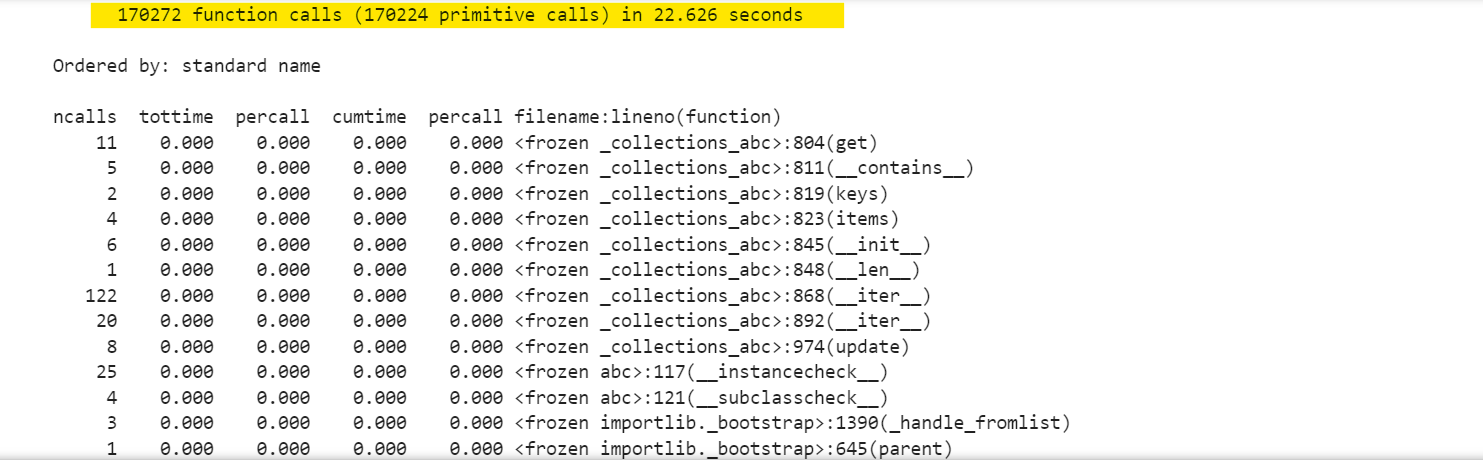
The results for html.parser shows that it made 170272 function calls in 22.626 seconds. This is significantly faster than html5lib.
lxml
The lxml parser is the fastest option among the parsers supported by Beautiful Soup. It's built on the C libraries libxml2 and libxslt, which offer great performance and support for advanced features like XPath and XSLT.
Here's the code:
import cProfile
import requests
from bs4 import BeautifulSoup
# Function to parse HTML content using lxml parser
def parse_html(url):
response = requests.get(url)
soup = BeautifulSoup(response.content, "lxml")
# Profile the parse_html function using cProfile
cProfile.run('parse_html("https://news.ycombinator.com/")')
The result is:
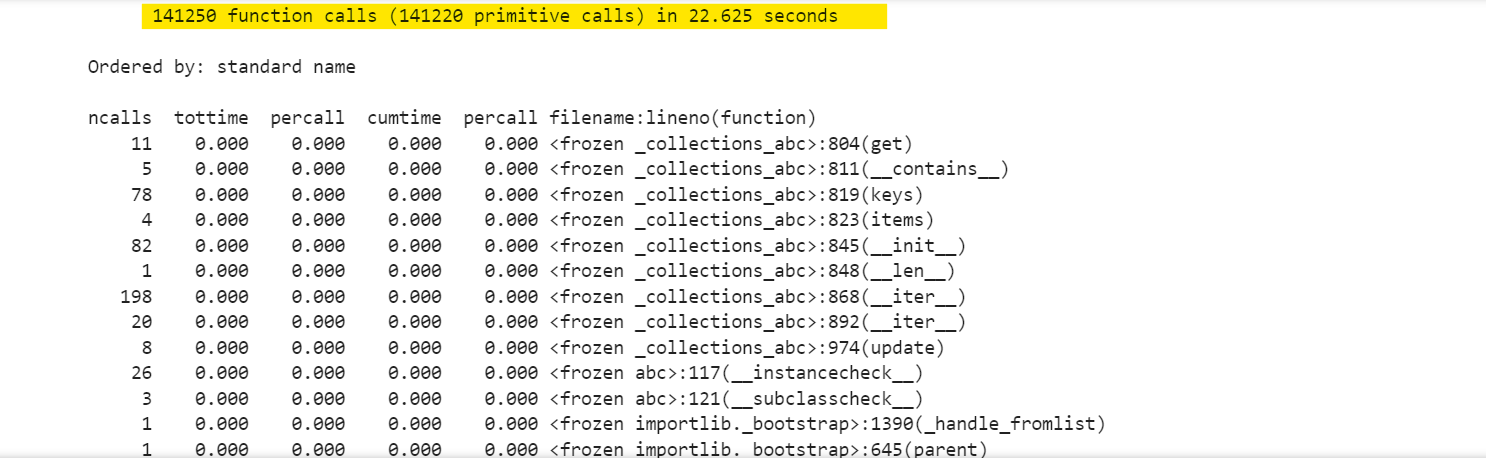
The lxml parser shows great performance, making 141250 function calls in just 22.625 seconds. This was the fastest result among the parsers tested.
Performance analysis
We measured the time each parser took to process the same HTML document.
- html5lib: This parser is the slowest, as it takes the most time to process the document. This is due to its comprehensive approach to handling malformed HTML.
- html.parser: It is faster than
html5lib, but it still falls short oflxmlin terms of speed. It provides a good balance between speed and robustness for moderately well-formed HTML. - lxml: The lxml parser is the fastest and most efficient for parsing well-formed HTML and XML documents.
Tip 2: Reducing network load with sessions
Another common mistake developers make is establishing a new connection for each request, which can significantly slow down the process. To avoid this, you can use sessions to maintain persistent connections, reducing connection overhead. The Python requests library provides a Session object that can be reused for multiple requests to the same server.
For example, using a session can be as simple as:
import requests
from bs4 import BeautifulSoup
import cProfile
def fetch_data():
# Create a session
session = requests.Session()
# Use the session to make requests
response = session.get("https://news.ycombinator.com/")
soup = BeautifulSoup(response.content, "lxml")
# Close the session
session.close()
# Profile the fetch_data function
cProfile.run("fetch_data()")
The result is:
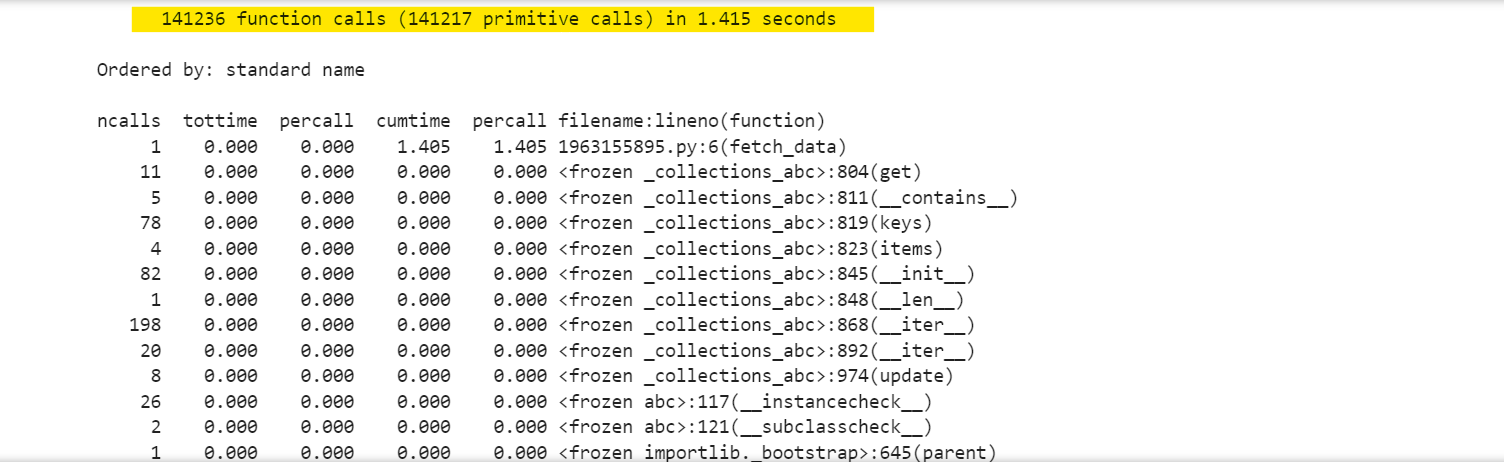
Maintaining a session helps you avoid the time-consuming process of setting up a new connection for each request. This is especially useful when scraping multiple pages from the same domain, as it allows faster and more efficient data extraction.
Tip 3: Using multi-threading and asynchronous processing
Multi-threading and asynchronous processing are techniques that can significantly improve the performance of web scraping tasks by enabling concurrent execution of tasks.
Using multi-threading
The ThreadPoolExecutor from the concurrent.futures module is a popular tool for implementing multi-threading in Python. It enables you to create a pool of threads and manage their execution efficiently.
Here’s how to use ThreadPoolExecutor with Beautiful Soup:
from concurrent.futures import ThreadPoolExecutor, as_completed
import requests
from bs4 import BeautifulSoup
import cProfile
def fetch_url(url):
"""
Fetches the content of a URL and parses it using BeautifulSoup.
"""
response = requests.get(url)
print(f"Processed URL: {url}")
return BeautifulSoup(response.content, "lxml")
# List of URLs to be processed.
urls = [
"https://news.ycombinator.com/",
"https://news.ycombinator.com/?p=2",
"https://news.ycombinator.com/?p=3",
]
def main():
"""
Main function to fetch and process multiple URLs concurrently.
Uses ThreadPoolExecutor to manage concurrent requests.
"""
with ThreadPoolExecutor(max_workers=5) as executor:
# Dictionary to track futures and corresponding URLs.
futures = {executor.submit(fetch_url, url): url for url in urls}
for future in as_completed(futures):
url = futures[future]
try:
# Attempt to get the result of the future.
soup = future.result()
except Exception as e:
print(f"Error processing {url}: {e}")
if __name__ == "__main__":
# Profile the main function to analyze performance.
cProfile.run("main()")
This approach results in 1,357,674 function calls completed in 23.274 seconds.
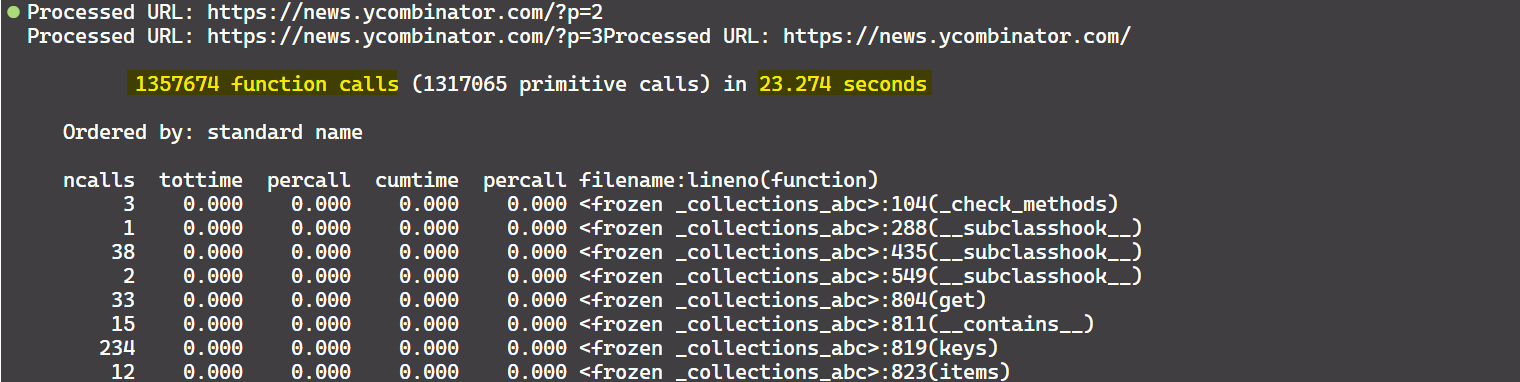
The code creates a pool of five threads, with each thread responsible for fetching and parsing a URL. The as_completed function is then used to iterate over the completed futures, allowing you to process results as soon as it is ready.
Using asynchronous processing
For asynchronous processing, the combination of the asyncio library with aiohttp provides a powerful solution for managing web requests. aiohttp is an asynchronous HTTP client that integrates smoothly with asyncio, allowing you to perform web scraping without blocking other operations.
💡You can also check out a detailed guide on how to use asyncio for web scraping with Python.
Here’s an example of how you can use these libraries to implement asynchronous web scraping:
import asyncio
import aiohttp
from bs4 import BeautifulSoup
import cProfile
urls = [
"https://news.ycombinator.com/",
"https://news.ycombinator.com/?p=2",
"https://news.ycombinator.com/?p=3",
]
async def fetch_url(session, url):
"""
Asynchronously fetches the content of a URL using aiohttp and parses it using BeautifulSoup.
"""
async with session.get(url) as response:
content = await response.text()
print(f"Processed URL: {url}")
return BeautifulSoup(content, "lxml")
async def main():
"""
Main function to create an aiohttp session and fetch all URLs concurrently.
"""
async with aiohttp.ClientSession() as session:
tasks = [fetch_url(session, url) for url in urls]
await asyncio.gather(*tasks)
if __name__ == "__main__":
cProfile.run("asyncio.run(main())")
This asynchronous approach results in 126,515 function calls completed in 22.383 seconds.
In this example, aiohttp.ClientSession is used to manage HTTP connections, and asyncio.gather is used to run multiple asynchronous tasks concurrently. This approach allows you to handle a large number of requests efficiently, as the event loop manages the execution of tasks without blocking.
Combining multi-threading and asynchronous processing
Multi-threading and asynchronous processing are effective individually as we can see, however, combining them can lead to even better performance gains. For example, you can use asynchronous processing to handle network requests and multi-threading to parse HTML content simultaneously, optimizing both fetching and processing times.
Here’s a code of this combined approach:
import aiohttp
import asyncio
from bs4 import BeautifulSoup
from concurrent.futures import ThreadPoolExecutor
import cProfile
# List of URLs to fetch data from
urls = [
"https://news.ycombinator.com/",
"https://news.ycombinator.com/?p=2",
"https://news.ycombinator.com/?p=3",
]
async def fetch(session, url):
"""
Asynchronously fetches the content from a given URL using the provided session.
"""
async with session.get(url) as response:
content = await response.text()
print(f"Fetched URL: {url}")
return content
def parse(html):
soup = BeautifulSoup(html, "lxml")
async def main():
"""
Main function to fetch URLs concurrently and parse their HTML content.
"""
async with aiohttp.ClientSession() as session:
# Create a list of tasks for fetching URLs
tasks = [fetch(session, url) for url in urls]
# Gather all responses concurrently
htmls = await asyncio.gather(*tasks)
# Use ThreadPoolExecutor to parse HTML content in parallel
with ThreadPoolExecutor(max_workers=5) as executor:
executor.map(parse, htmls)
if __name__ == "__main__":
# Profile the asynchronous main function to analyze performance
cProfile.run("asyncio.run(main())")
This combined approach yields 125,608 function calls completed in just 1.642 seconds.
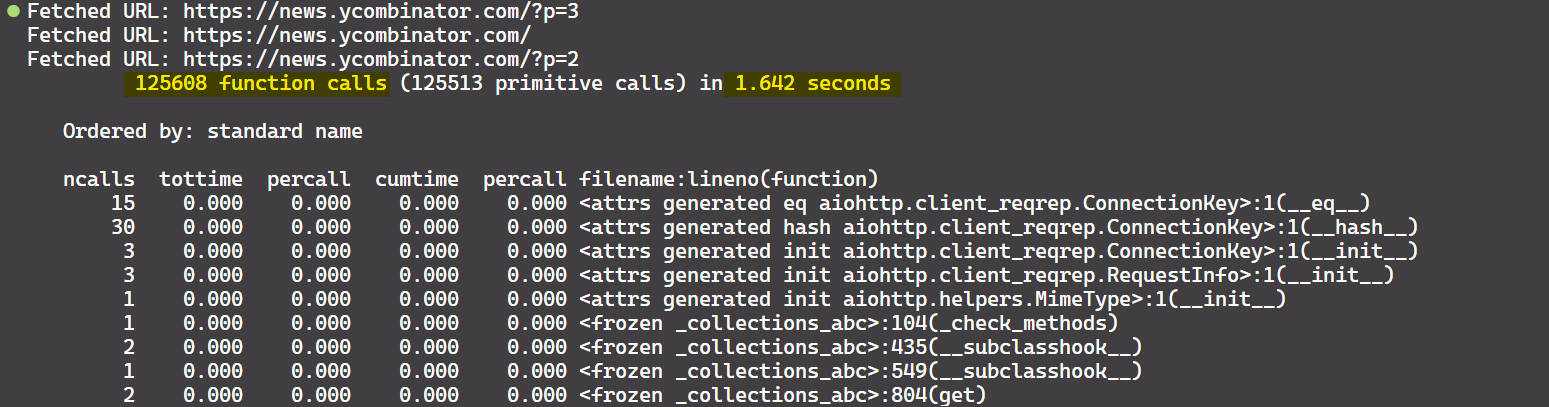
In this hybrid approach, aiohttp and asyncio are used to fetch web pages asynchronously, while ThreadPoolExecutor handles the HTML parsing concurrently. By combining these methods, you can use the strengths of both asynchronous processing and multi-threading to achieve maximum performance in your web scraping tasks.
Observation? The combined approach delivered the best performance, with an execution time of just 1.642 seconds, compared to 23.274 seconds for multi-threading alone and 22.383 seconds for pure asynchronous processing.
Tip 4: Caching techniques to speed up scraping
Caching is an excellent method to improve the performance of your web scraping activities. By temporarily storing data, caching decreases the frequency of repeated requests to the server. Therefore, when you make the same request again, it retrieves the data from the local cache rather than fetching it from the server, ultimately reducing the load on external resources.
One of the easiest ways to add caching to your web scraping is by using the requests-cache, a persistent cache for Python requests.
First, install the requests-cache library using pip:
pip install requests-cache
You can then use requests_cache.CachedSession to make your requests. This session behaves like a standard requests.Session, but includes caching functionality.
Here's a simple code:
import requests_cache # Import the library for caching HTTP requests
from bs4 import BeautifulSoup
import cProfile
def fetch_data():
# Create a cached session that stores responses for 24 hours (86400 seconds)
session = requests_cache.CachedSession("temp_cache", expire_after=86400)
response = session.get("https://news.ycombinator.com/")
# Check if the response is from the cache
if response.from_cache:
print("Data is coming from cache")
else:
print("Data is coming from server")
soup = BeautifulSoup(response.content, "lxml")
print(soup.title.text)
# Profile the function call
cProfile.run("fetch_data()")
When you run the script for the first time, data is fetched from the server, as shown below:
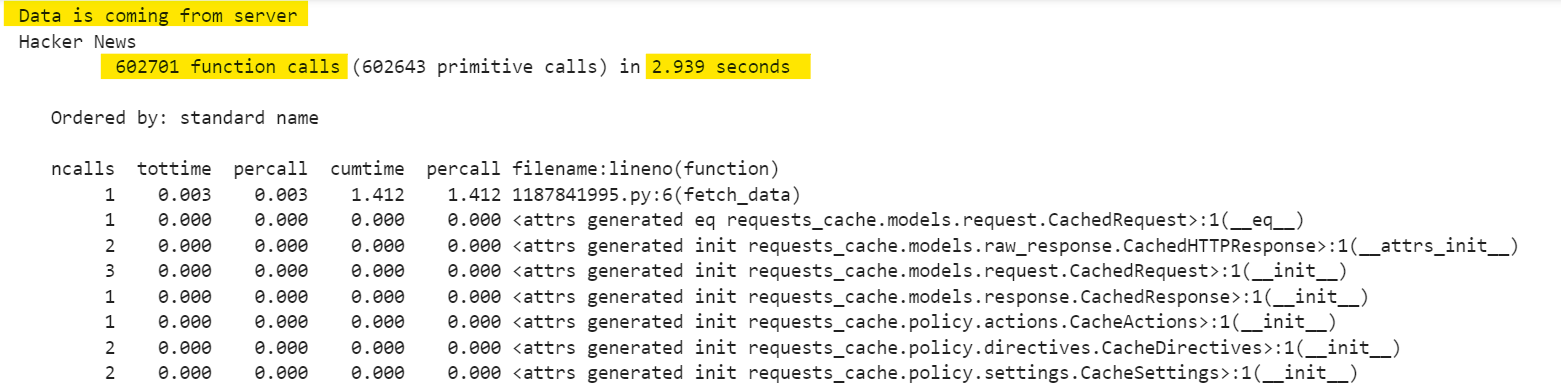
In this initial request, the operation involves approximately 602,701 function calls and takes about 2.939 seconds.
Now, when you run the same script again, the data is retrieved from the cache:
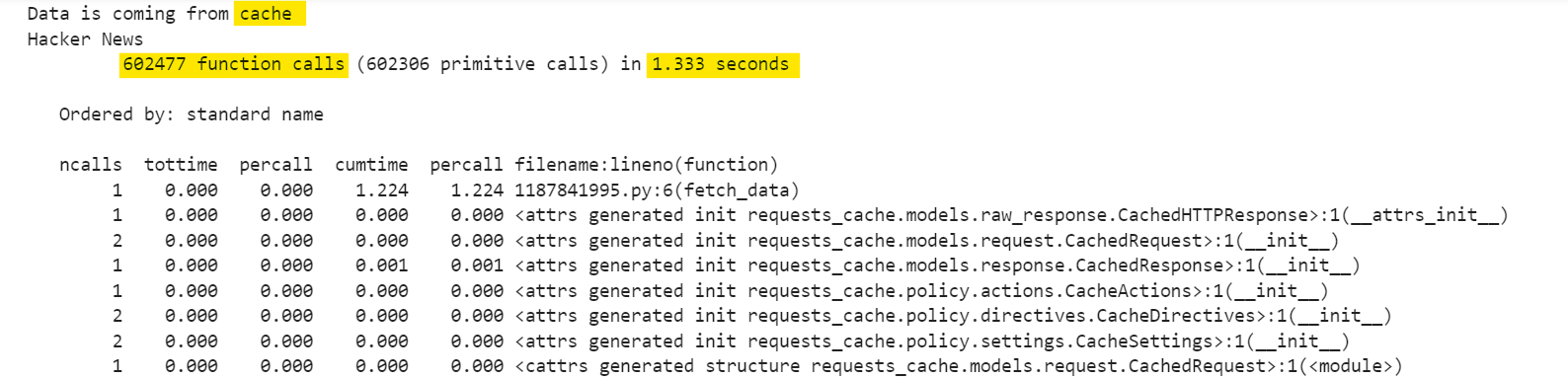
Here, the cached response makes about 602,477 function calls and completes in 1.333 seconds. This shows an improvement in speed and efficiency due to caching.
Customizing cache
requests-cache allows you to customize cache behaviour according to your needs. For example, you can choose different backends (e.g., SQLite, Redis), set expiration times, and specify which HTTP methods to cache.
Here’s the code
import requests_cache
import cProfile
def fetch_data():
session = requests_cache.CachedSession(
"temp_cache",
backend="sqlite", # use SQLite as the caching backend
expire_after=3600, # cache expires after 1 hour
allowable_methods=["GET", "POST"], # cache both GET and POST requests
)
response = session.get("https://news.ycombinator.com/")
# ...
cProfile.run("fetch_data()")
You might also want to cache only specific types of responses, such as successful ones. This can be achieved using the cache_filter parameter, which allows you to define a custom filtering function:
import requests_cache
import cProfile
def is_successful(response):
"""Cache only responses with status code 200."""
return response.status_code == 200
def fetch_data():
# Create a cached session with a filter to cache only successful responses
session = requests_cache.CachedSession(
"temp_cache", expire_after=86400, cache_filter=is_successful
)
response = session.get("https://news.ycombinator.com/")
# ...
cProfile.run("fetch_data()")
Tip 5: Using SoupStrainer for partial parsing
When working with large documents, sometimes you might prefer to parse just a portion rather than the entire content. Beautiful Soup makes this easier with SoupStrainer, which lets you filter out the unnecessary parts and focus only on what matters.
Here’s the code:
import cProfile
import requests
from bs4 import BeautifulSoup, SoupStrainer
# Function to parse HTML content using lxml parser
def parse_html(url):
response = requests.get(url)
only_a_tags = SoupStrainer("a")
soup = BeautifulSoup(response.content, "lxml", parse_only=only_a_tags)
for link in soup:
print(link.get("href"))
# Profile the parse_html function using cProfile
cProfile.run('parse_html("https://news.ycombinator.com/")')
The result is:
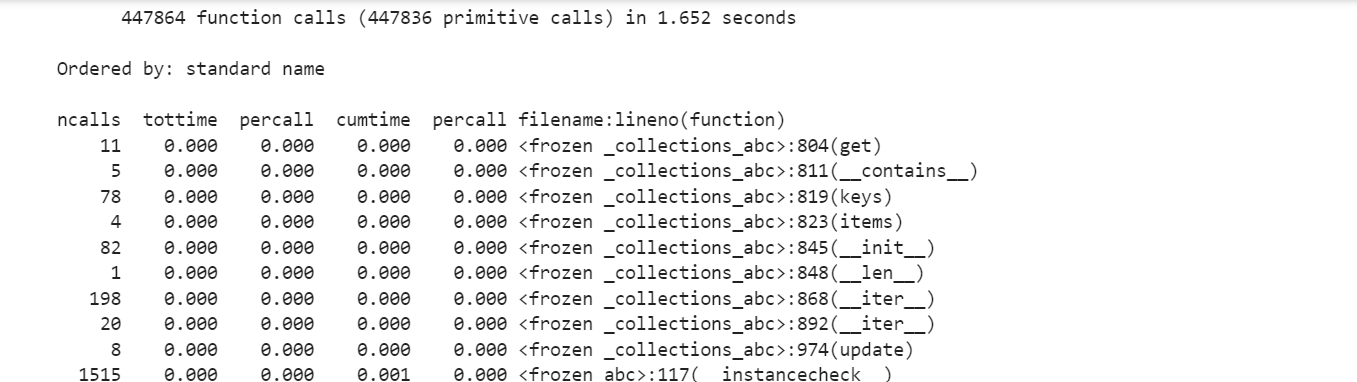
So, by parsing only the parts of the document you need, you can significantly reduce the time and resources required for parsing.
Tip 6: Optimizing CSS selectors
When using Beautiful Soup to extract specific elements from HTML, the efficiency of your CSS selectors plays a crucial role in performance. By narrowing the scope of your selectors, you can significantly reduce parsing time. Instead of using broad selectors that traverse a large portion of the DOM tree, focus on targeting elements directly.
# Using efficient CSS selectors
soup.select("div.classname > p")
💡 You can also refer to a detailed guide on using CSS selectors for web scraping.
Tip 7: Using proxy servers for load balancing
Proxy servers act as intermediaries between your scraper and the target website. They distribute requests across multiple IP addresses, which helps reduce the risk of being blocked and balances the load of requests. This is particularly useful for scraping websites with rate limits or IP-based restrictions.
💡 You can also check out the detailed guide on getting started with BeautifulSoup.
To use proxies with Beautiful Soup, you can configure the requests library to route requests through a proxy server.
Here’s the code:
import requests
from bs4 import BeautifulSoup
# Define the proxy server
proxies = {
"http": "http://your_proxy_ip:port",
"https": "http://your_proxy_ip:port",
}
# Make a request through the proxy server
response = requests.get("https://news.ycombinator.com/", proxies=proxies)
soup = BeautifulSoup(response.content, "lxml")
In the code, requests are routed through the proxy server specified in the proxies dictionary. This helps in balancing the request load and improving the performance of Beautiful Soup.
Tip 8: Managing rate limits with sessions and proxies
When web scraping, it's important to respect the rate limits set by the target server to avoid getting blocked. You can effectively manage the frequency of your requests by using sessions and proxies. Additionally, introducing a delay between requests can also help.
import requests
import time
# Initialize a session for HTTP requests
web_session = requests.Session()
# Proxy settings
proxy_settings = {
'http': 'http://your_proxy_ip:port',
'https': 'http://your_proxy_ip:port',
}
# Apply proxy settings to the session
web_session.proxies.update(proxy_settings)
def retrieve_web_data(target_url):
# Make a request using the predefined session
result = web_session.get(target_url)
if result.status_code == 200:
print("Successfully retrieved data.")
else:
print("Data retrieval failed.")
return result
# Target URL
target_url = 'https://news.ycombinator.com/'
# Execute data retrieval with pauses between requests
for _ in range(5):
retrieve_web_data(target_url)
time.sleep(2) # Wait for 1 second between requests
In the code, using requests.Session can speed up web scraping by reusing connections. Setting up proxies to rotate IP addresses helps distribute the load and avoid rate limits. Additionally, using time.sleep() introduces pauses between requests, which helps you stay within server limits and reduces the risk of getting blocked.
Tip 9: Error handling and retry logic with proxies
When scraping the web, using proxies is great, but you also have to manage connection errors and timeouts. Therefore, it's important to use error handling and retry logic to ensure effective web scraping. For example, if a request fails, attempting a retry with a different proxy can significantly improve the likelihood of success.
Here’s the code of how to implement retry logic with proxies.
import requests
from requests.exceptions import RequestException, ProxyError, Timeout
import random
from bs4 import BeautifulSoup
proxies_list = [
"http://your_proxy_ip:port",
"http://your_proxy_ip:port",
"http://your_proxy_ip:port",
]
def fetch_with_retry(url, retries=3):
session = requests.Session()
for attempt in range(1, retries + 1):
try:
proxy = {"http": random.choice(proxies_list)}
response = session.get(url, proxies=proxy, timeout=10)
if response.status_code == 200:
print(f"Attempt {attempt} succeeded.")
return BeautifulSoup(response.text, "lxml")
print(
f"Attempt {attempt} failed with status code: {
response.status_code}"
)
except (RequestException, ProxyError, Timeout) as e:
print(f"Attempt {attempt} failed with error: {e}")
continue
return None
if __name__ == "__main__":
url = "https://news.ycombinator.com"
result = fetch_with_retry(url)
if result:
print("Fetch successful!")
else:
print("Failed to fetch the URL after several retries.")
This code tries to fetch data from a URL using different proxy servers. It retries the request up to three times if it fails, picking a new proxy for each attempt. If successful, it parses the HTML content with BeautifulSoup. If not, it continues trying with different proxies until it either succeeds or exhausts all attempts.
Tip 10: Efficient data extraction with XPath
Although Beautiful Soup is great for parsing HTML and navigating the document tree, XPath expressions can provide greater precision and flexibility when it comes to complex data extraction. The lxml library is particularly powerful because it combines the ease of HTML parsing with the advanced querying capabilities of XPath and XSLT.
Before you can start using lxml, you'll need to install it:
pip install lxml
Here's a quick example of how you can use lxml with XPath:
import requests
from lxml import html
import cProfile
def fetch_data():
url = 'https://news.ycombinator.com/'
response = requests.get(url)
if response.status_code == 200:
# Parse the HTML content into a tree structure
tree = html.fromstring(response.content)
# Use XPath to extract data
titles = tree.xpath(
'//tr[@class="athing"]//span[@class="titleline"]/a/text()')
else:
print("Failed to fetch the page. Status code:", response.status_code)
cProfile.run('fetch_data()')
The result shows that we successfully extracted all the news titles from the URL in just 1.2 seconds which is quick and efficient.
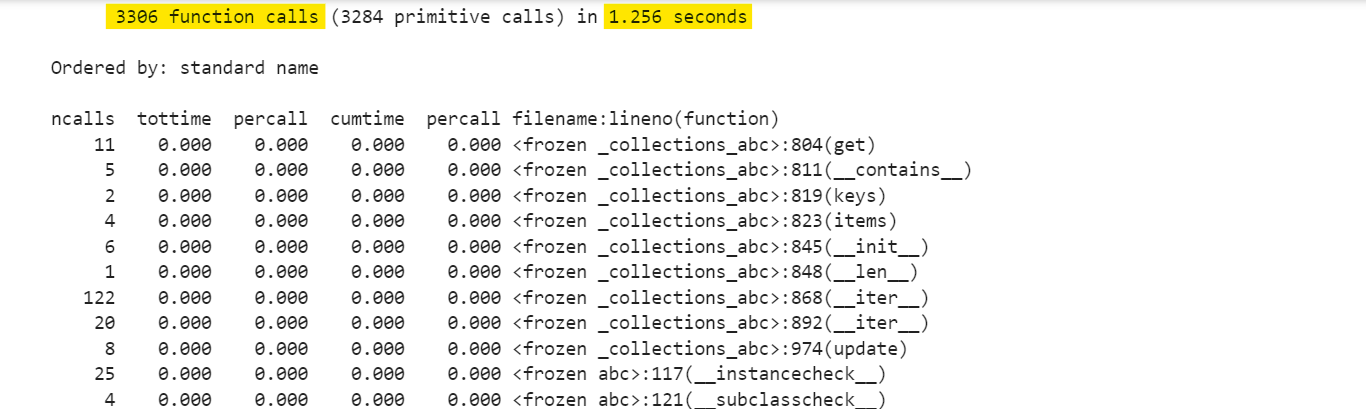
XPath expressions can be more efficient and concise than traditional CSS selectors, especially when dealing with complex document structures. This method can significantly speed up the data extraction process.
Tips for efficient HTML parsing
Here are some tips on how to parse HTML more efficiently.
1. Navigating the DOM tree: Understanding the Document Object Model (DOM) is crucial for efficient HTML parsing. The DOM represents the structure of an HTML document as a tree of objects.
2. Traversing the DOM:
- Use
.parentto access the parent of the tag and.childrento iterate over a children of the tag. This hierarchical navigation is useful for extracting nested data. - Use
.next_siblingand.previous_siblingto move horizontally across the DOM tree. This is useful for extracting data from elements that are on the same level.
3. Searching the DOM Tree:
Efficient searching within the DOM tree is vital for extracting specific data points. BeautifulSoup offers several methods to facilitate this:
- Use methods such as
find()andfind_all()to locate elements by tag name or attributes. - The
select()method allows for more complex queries using CSS selectors.
4. Handling large documents:
For large HTML documents, performance can be a concern. So, you can follow these quick tips:
- Consider using the
lxmlParser, which is faster and more efficient for parsing large documents, as discussed earlier in detail. - Install cchardet as this library speeds up encoding detection, which can be a bottleneck when parsing large files.
- You can also use
SoupStrainerto limit parsing to only the necessary parts of the document, as discussed earlier in detail.
5. Modifying the parse tree: BeautifulSoup allows you the modification of the parse tree, like the addition, deletion, or alteration of HTML elements. This is particularly useful for cleaning up scraped data or preparing it for further analysis.
6. Error handling and logging: It's important to implement error handling in your code. BeautifulSoup can encounter a lot of issues with malformed HTML or missing tags, which leads to exceptions. Therefore, using try-except blocks and logging errors can help in debugging and improving the stability of your scraper.
7. Integrating with other tools: For JavaScript-heavy sites, integrating BeautifulSoup with tools like Selenium, Playwright, or Puppeteer can be very effective. BeautifulSoup can handle static HTML well, but these tools can interact with the browser to scrape dynamic content that JavaScript generates.
Use a Scraping API instead
Data extraction is not easy nowadays, as it involves many challenges due to the anti-bot measures put in place. Bypassing anti-bot mechanisms can be challenging and take up a lot of time and resources. That’s where web scraping APIs like ScrapingBee come in!
ScrapingBee simplifies the scraping process by handling the hard parts like rotating proxies and rendering JavaScript, so you don’t have to worry about getting blocked. You can focus on extracting valuable data without the need to invest time and resources in optimizing BeautifulSoup for performance.
To start, sign up for a free ScrapingBee trial no credit card is needed, and you'll receive 1000 credits to begin. Each request costs approximately 25 credits.
Next, install the ScrapingBee Python client :
pip install scrapingbee
You can use the below Python code to begin web scraping:
from scrapingbee import ScrapingBeeClient
client = ScrapingBeeClient(api_key="YOUR_API_KEY")
response = client.get(
"https://www.g2.com/products/anaconda/reviews",
params={
"stealth_proxy": True, # Use stealth proxies for tougher sites
"block_resources": True, # Block images and CSS to speed up loading
"wait": "1500", # Milliseconds to wait before capturing data
# "device": "desktop", # Set the device type
# "country_code": "gb", # Specify the country code
# Optional screenshot settings:
# "screenshot": True,
# "screenshot_full_page": True,
},
)
print("Response HTTP Status Code: ", response.status_code)
print("Response HTTP Response Body: ", response.text)
The status code 200 indicates that the G2 anti-bot has been bypassed.

Using a web scraping API like ScrapingBee saves you from dealing with various anti-scraping measures, making your data collection efficient and less prone to blocks.
Wrapping up
In this tutorial we've shown you 10 expert tips and tricks for speeding up your scraping with Beautiful Soup, some of these concepts can be applied to different scraping libraries as well. Scaling your scraping operation can be a mammoth technical challenge to get right in a cost-effective and efficient way, but with these pointers, you should be on the way to becoming a scraping master. If you want to skip all of the technical challenges of scraping, we've done the hard work for you with our web scraping API which will allow you to easily scrape any page with one API call, give it a spin with 1,000 free credits, just sign up and start scraping.
Before you go, check out these related reads:


