The web is becoming an incredible data source. There are more and more data available online, from user-generated content on social media and forums, E-commerce websites, real-estate websites or media outlets... Many businesses are built on this web data, or highly depend on it.
Manually extracting data from a website and copy/pasting it to a spreadsheet is an error-prone and time consuming process. If you need to scrape millions of pages, it's not possible to do it manually, so you should automate it.
In this article we will see how to get data from a website with many different solutions. The best way to pull data from the web depends on the following:
- Are you technical?
- Do you have in-house developers?
- What type of websites do you need to extract data from?
- What is your budget?
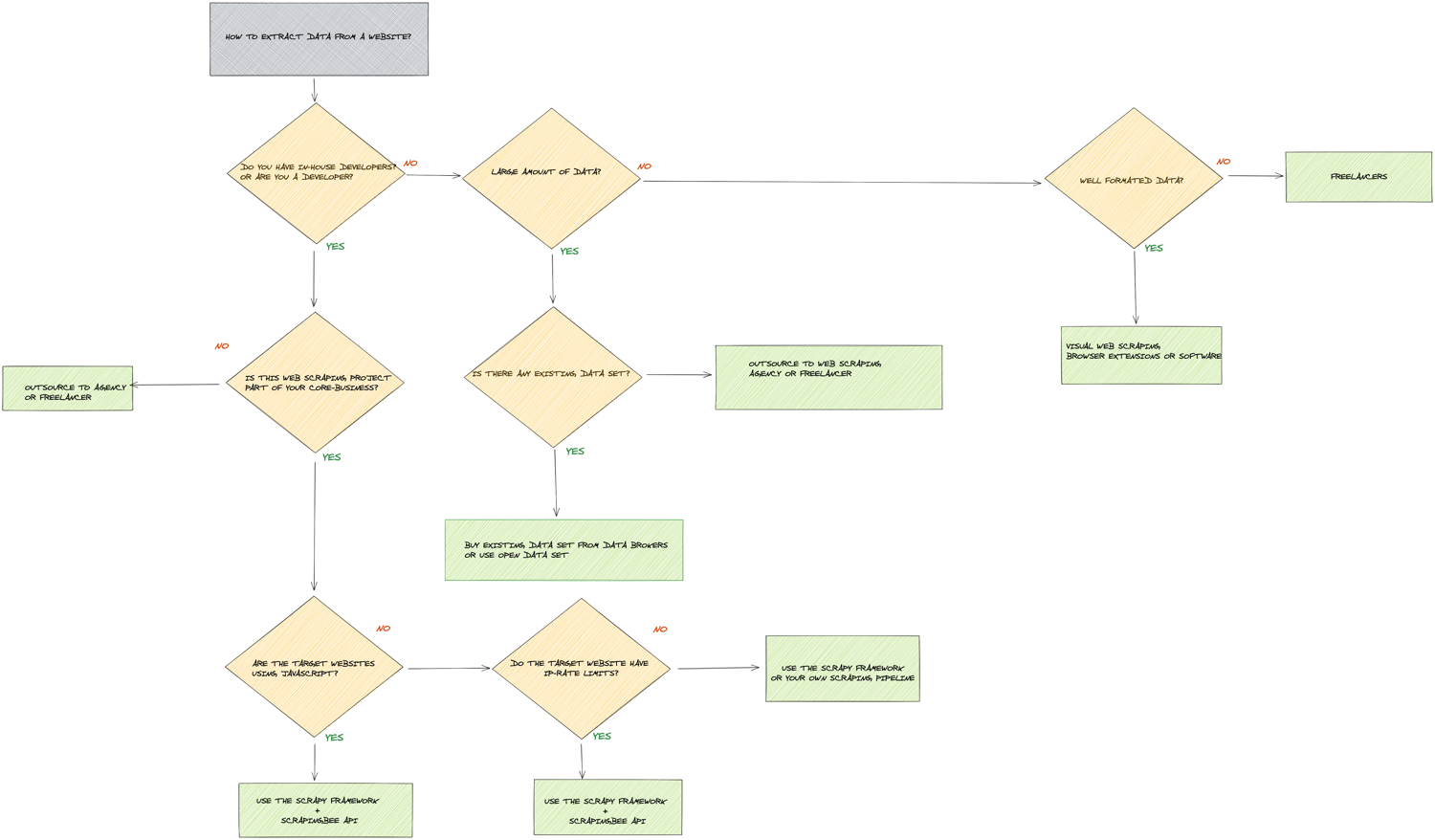
See high-resolution diagram here
From building your web scraping pipeline in-house, to web scraping frameworks and no-code web scraping tools, it's not an easy task to know what to start with.
Before diving into how to extract data from the web, let's look at the different web scraping use cases.

What are the different use cases for web scraping?
Here are some interesting web scraping use cases:
- Online price monitoring: Many retailers are monitoring the market online in order to dynamically change their pricing. They monitor their competitors's stock, price changes, sales, new product...
- Real estate: Lots of real-estate startups need data from real-estate listings. It's also a gold mine for market research.
- News aggregation: News websites are heavily scrapped for sentiment analysis, as alternative data for finance/hedge funds...
- Social media: Many companies are extracting data from social media to search for signals. Influencer marketing agencies are getting insights from influencers by looking at their followers growth and other metrics.
- Review aggregation: Lots of startups are in the review aggregation business and brand management. They extract reviews from lots of different websites about restaurants, hotels, doctors and businesses.
- Lead generation: When you have a list of websites that are your target customer, it can be interesting to collect their contact information (email, phone number...) for your outreach campaigns.
- Search engine results: Monitoring search engine result page is essential to the SEO industry to monitoring the rankings. Other industries like online retailers are also monitoring E-commerce search engine like Google Shopping or even marketplace like Amazon monitor and improve their rankings.
In our experience with ScrapingBee, these are the main use cases that we saw the most with our customers.Of course, there are many others.
How to extract data from the web with code
In this part we're going to look at the different ways to extract data programmatically (using code). If you are a tech company or have in-house developers this is generally the way to go.
For large web-scraping operations, writing your own web scraping code is usually the most cost-effective and flexible option you have. There are many different technologies and frameworks available, and that's what we are going to look at in this part.
In-house web scraping pipeline
As an example let's say you are a price-monitoring service extracting data from many different E-commerce websites.
You web scraping stack will probably include the following:
- Proxies
- Headless Browsers
- Extraction rules (XPath and CSS selectors)
- Job Scheduling
- Storage
- Monitoring
Proxies are a central piece of any web scraping operation. Many websites display different data based on the IP address country. For example, an online retailer will display prices in Euros for people within the European Union. An American website will display a price in Dollars for US people based in the US. Depending on where your servers are located and the target website you want to extract data from, you might need proxies in another country.
Also, having a large proxy pool is a must-have in order to avoid getting blocked by third-party website. There are two types of proxies, data-center IPs and residential proxies. Some websites block data-center IPs entirely, in that case you will need to use a residential IP address to access the data. Then there is a hybrid type of proxies that combines the best of the two world: ISP proxies
Headless Browsers are another important layer in modern web scraping. There are more and more websites that are built using shiny front-end frameworks like Vue.js, Angular.js, React.js. Those Javascript frameworks use back-end API to fetch the data and client-side rendering to draw the DOM (Document Object Model). If you were using a regular HTTP client that doesn't render the Javascript code, the page you'd get would be almost empty. That's one of the reason why Headless Browsers are so important.
The other benefit of using a Headless Browser is that many websites are using "Javascript challenge" to detect if an HTTP client is a bot or a real user. By using a Headless Browser, you're more likely to bypass those automated test and get the target HTML page.
The three most used APIs to run headless browsers are Selenium, Puppeteer and Playright. Selenium is the oldest one, it has librairies in almost all programming languages and support every major browsers.
Puppeteer only supports NodeJS, it is maintained by the Google team and supports Chrome (Firefox support will come later, it's experimental at the moment).
Playwright is the newest player, it is maintained by Microsoft and supports every major browsers.
Extraction rules is the logic that you will use in order to select the HTML element and extract the data. The two easiest ways to select HTML elements on a page are XPath selectors and CSS selectors.
This is generally where the main logic of your web scraping pipeline. It is where your developers are the most likely to spend time on. Websites are often updating their HTML (especially startups), so you will often have to update those XPath and CSS selectors.
Job Scheduling is another important piece. You might want to monitor the prices every day, or every week. The other benefit of using a job scheduling system is that you can retry failed job. Error handling is extremely important in web scraping. Many errors can happen that are outside of your control. Consider the following:
- The HTML on the page has changed, and it broke your extraction rules
- The target website can be down.
- It is also possible that you proxy server is slow or doesn't work.
- A request can be blocked.
Job scheduling and error handling can be done using any form of message broker and job scheduling librairies, like Sidekiq in Ruby or RQ in Python.
Storage: After extracting the data from a website, you generally want to save it somewhere. The scraped data is generally stored in the following common formats:
- JSON
- CSV
- XML
- Into an SQL or noSQL database
Monitoring your web scraping pipeline is very important. As said earlier, many problems can happen when extracting data from the web at scale. You need to ensure that your scrapers don't break, that the proxies are working properly. Splunk is a great tool to analyze logs, set up dashboard and alerts. There are also open-source alternatives like the Kibana and the whole ELK stack.
Scrapy
Scrapy is an open source python web scraping framework. In our opinion, it's an amazing starting point to extract structured data from websites at scale. It solves many common problems in a very elegant way:
- Concurrency (Scraping multiple pages at the same time)
- Auto-throttling, in order to avoid disturbing the third party websites you're extracting data from
- Flexible export type format, CSV, JSON, XML and backend for storage (Amazon S3, FTP, Google cloud...)
- Automatic crawling
- Built-in media pipeline to download images and assets
If you want to dig deeper into Scrapy, we wrote an extensive guide about web scraping with Scrapy.
ScrapingBee
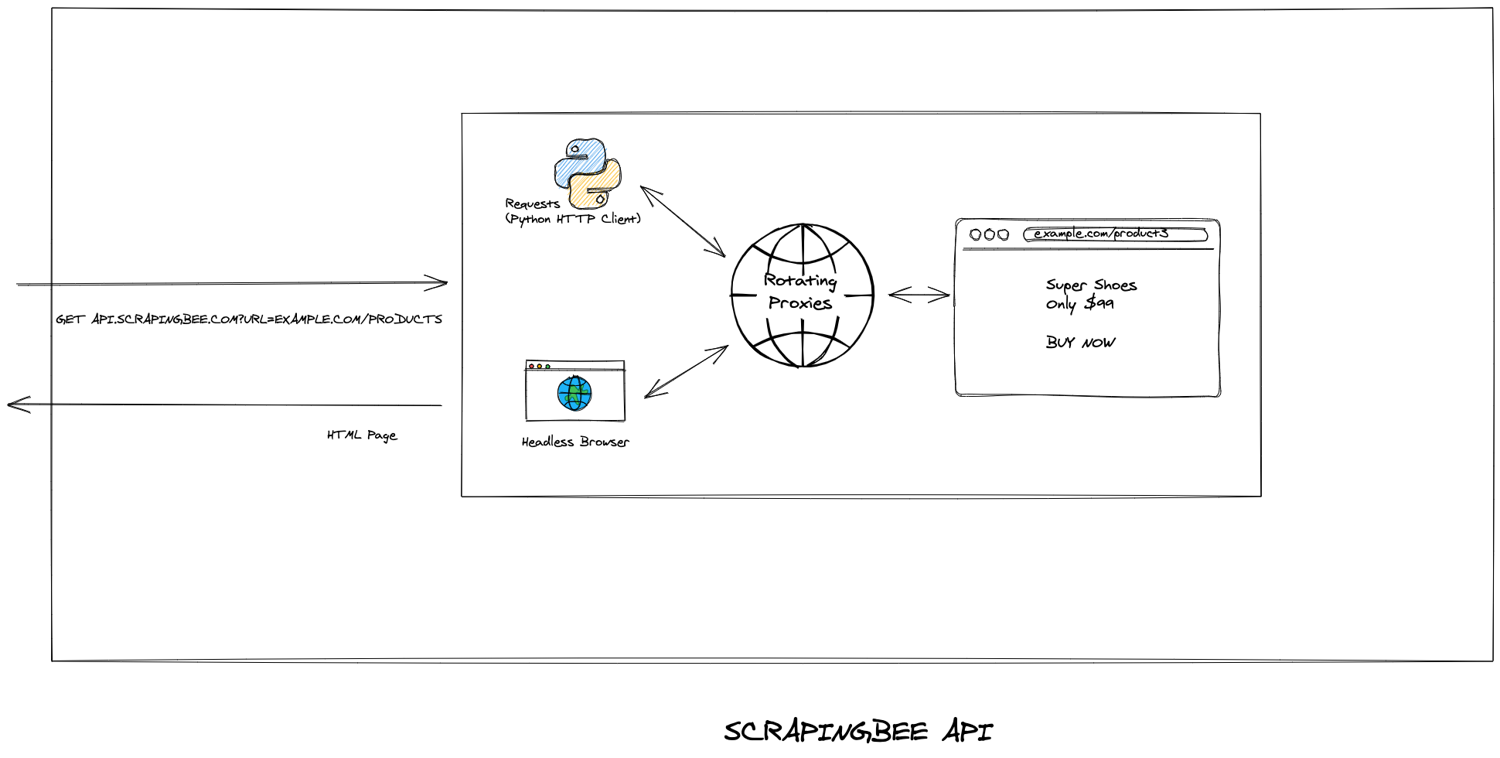
ScrapingBee can help you with both the proxy management and headless browsers. It's an excellent solution when you don't want to deal with neither of those.
There are many issues with running healdess browsers in production. It is easy to run one Selenium or Puppeteer instance on your laptop, but running dozens in production is another realm. First, you need powerful servers. Headless Chrome for example, requires at least 1 GB of ram and one CPU core to run smoothly.
Want to run 50 headless Chrome instances in parralel? That's 50GB of ram and 50 CPU cores. You then need either one giant bare-metal server costings thousands of dollars per month, or many small servers.
On top of that, you will need a load balancer, monitoring, and probably putting all of this into docker containers. It's a lot of work and this is one of the problem we solve at ScrapingBee. Instead of doing all of the above, you could use ScrapingBee with a simple API call.
The other sweet spot for ScrapingBee is proxy management. Many websites are using IP rate-limits on their pages. Let's say a website allows 10 requests per day per IP address. If you need to perform 100,000 requests in a single day, you will need 10,000 unique proxies. That's a lot. Generally, proxy providers charges around one to three dollars per unique IP address per month. The bill can blow up very quickly.
With ScrapingBee, you get access to a huge proxy pool for a fraction of the cost.
Pulling data from the web without code / low-code
At ScrapingBee, we love code! But what if you don't have developers in your company? There are still solutions! Some solution are code-free, others requires little code (APIs). This is particulary effective if you need data for a one-time project, and not on a recurring basis.
Data brokers
If you need a huge amount of data from the web for a specific use case, you may want to check that the dataset doesn't already exist. For example, let's say you want the list of all the websites in the world using a particular technology like Shopify. It would be a huge task to crawl the entire web or a directory (if such a directory exists) to get this list. You can easily get this list by buying it to data brokers like builtwith.com.
Website-specific APIs
If you need to pull data from a specific website (as opposed to many different websites), there might be an existing API that you could use. For example, at ScrapingBee, we have a dedicated Google Search API. The benefits of using an API is that you don't have to handle the maintenance when the target website updates its HTML. Which means no monitoring on your end, no more extraction rules updates, and you don't have to deal with proxies getting blocked all the time.
Also, make sure that the target website isn't offering a public or private API to access the data, it's generally cost-effective and you will spent less time that trying to pull the data yourself.
Web browser extension
Web browser extension can be an efficient way of extracting data from a website. The sweet spot is when you want to extract well-formated data, for example a table or a list of elements on a page. Some extensions like DataMiner offers ready-to-use scraping recipes for popular websites like Amazon, Ebay or Walmart.
Web scraping tools
Web scraping tools like ScreamingFrog or ScrapeBox are great to extract data from the web, and Google specifically. Depending on your use case, like SEO, keyword research or finding broken links, it might be the easiest thing to use.
Other softwares like ParseHub are also great for people without coding knowledge. Those are desktop applications that makes extracting data from the web an easy task. You create instructions on the app, like selecting the element you need, scrolling etc.
Those softwares have limits though, and the learning curve is steep.
Outsource to web scraping agencies or freelancers
There are many web scraping agencies and freelancers who can help you with your web data extraction needs. It's can be great to outsource when your problem cannot be solved through no-code solution.
Freelancers are the most flexible solution, as they can adapt their code to any website. The ouput format can be anything you could think of: CSV, JSON, dumping data into an SQL database...
The easiest way to find freelancers is to go on Upwork.com or Toptal(https://www.toptal.com/)
Web Scraping agencies are another great solution, especially for large-scale scraping operation. If you need to develop and maintain scrapers for many websites, you will probably need a team, a single freelancer won't be able to handle everything.
Final thoughts
This was a long blog post, you should now have a good knowledge of the different ways to pull data from the web.
If you're still not sure about what to choose, keep in mind that many things we discussed on this page are easy and quick to test.
Most of the software we talked about have a trial period. If you choose to build your own scrapers and use ScrapingBee, you can also get started quickly.
If you want to learn more building your own scrapers with code, you might be interested by those guides:
Did we missed something? Ping us on Twitter
Happy Scraping!
Before you go, check out these related reads:

Kevin worked in the web scraping industry for 10 years before co-founding ScrapingBee. He is also the author of the Java Web Scraping Handbook.


{kind=link}