Introduction
CAPTCHA - Completely Automated Public Turing test to tell Computers and Humans Apart! All these little tasks and riddles you need to solve before a site lets you proceed to the actual content.
💡 Want to skip ahead and try to avoid CAPTCHAs?
At ScrapingBee, it is our goal to provide you with the right tools to avoid triggering CAPTCHAs in the first place. Our web scraping API has been carefully tuned so that your requests are unlikely to get stopped by a CAPTCHA, give it a go.
Sign up and get a comfortable 1,000 API requests completely for free!
While CAPTCHAs can be a hassle when you just regularly browse the web, they turn into a proper annoyance when you are trying to run your web scraping jobs. To be fair, that is their purpose, but that nonetheless does not make your live easier when you just try to aggregate information from different sites.
So what can we do about this? That's precisely what we are going to discuss in this article: what types of CAPTCHAs there are and how to solve them programmatically, with a particular focus on reCAPTCHA and hCaptcha
Please fasten your seatbelts and get ready for a lot of traffic lights 🚦, motorcycles 🏍️, and crosswalks 🚸!

What are the different types of CAPTCHAs?
CAPTCHAs originally started out relatively simple, with an image of slightly distorted text characters, which the user was supposed to enter in a textbox.

If the entered text matched the image, the site assumed a real human sent that. Over time, OCR got better, so CAPTCHAs became more complex and more difficult to solve. Today, CAPTCHAs can come in the following variants:
- Text-based
- Using checkboxes
- Image-based
- Audio-based
- With sliders
- 3D objects
- Math calculations
- Invisible and passive
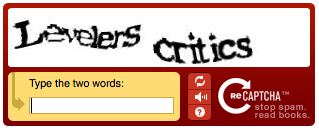
Text
One of the most common type of CAPTCHAs is text-based and requires the user to decipher the text in an image and provide the correct answer in response. Google famously used this approach in its first version of reCAPTCHA for digitising books.
Checkboxes
At least from a UX point of view, CAPTCHAs with checkboxes are probably the easiest type of CAPTCHA. The user simply checks the box in question and that will "confirm" they are not a bot. The exact type of implementation can still vary, from something simple like an HTML checkbox (<input type="checkbox" />) to more sophisticated implementations, involving JavaScript and server-side requests.
A very common variant of the checkbox CAPTCHA is version 2 of Google's own reCAPTCHA service:

Another common service using this approach is Cloudflare with Turnstile:
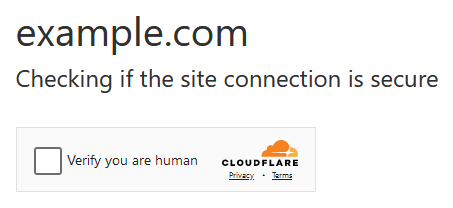
💡Interested in bypassing Cloudflare protection? Check out our guide on Scraping with Cloudscraper.
Images
The dreaded 🚦, right?
Yes, once again it is Google's reCAPTCHA which made the image CAPTCHA famous. This is where the user is supposed to match the image against a certain task and gets granted access upon successful completion.
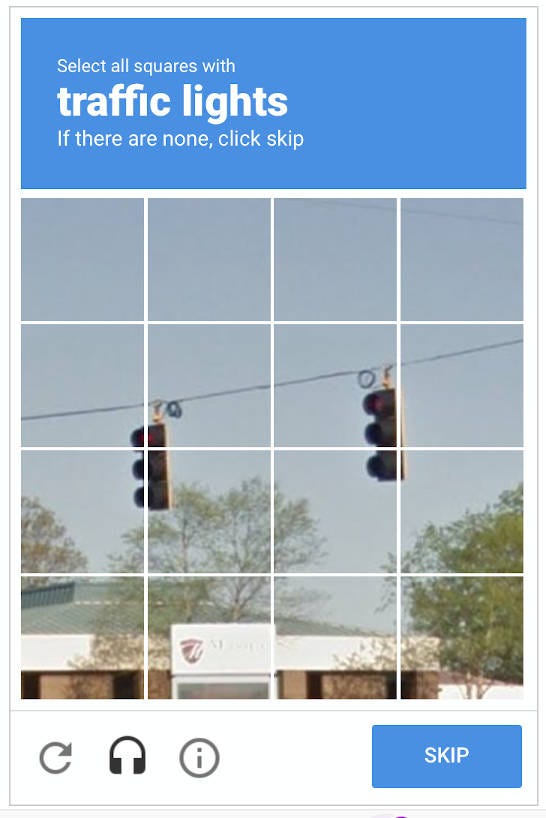
This type of CAPTCHA has become notorious to an extent, that it even made it into an xkcd comic strip.
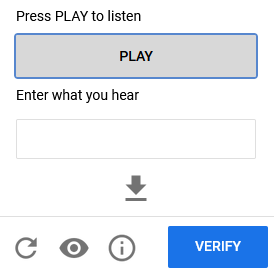
Audio
With audio CAPTCHAs, users need to listen to a short audio clip and transcribe the words into text.
reCAPTCHA provides this as alternative accessibility solution, especially for visually impaired people.
Sliders
Slider CAPTCHAs are a special form of an image CAPTCHA and require the user to position an image cut-out (typically in the shape of a puzzle piece) at the correct position within the original image.
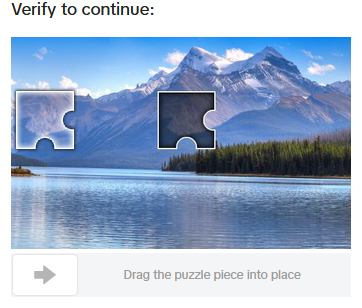
3D objects
3D objects are a fairly new addition to CAPTCHAs and typically show you a set of different three-dimensional objects in a scene along with instructions to pick a matching picture or adjust the scene in a particular way.

Math calculations
Math CAPTCHAs put your basic arithmetic skills to a test. It challenges you with a basic math formula and you just need to enter the correct number to pass.
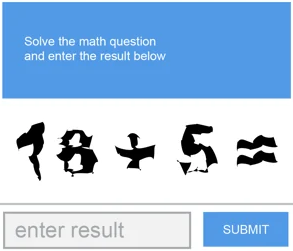
Invisible CAPTCHAs
The most user-friendly CAPTCHAs are those which do not require user interaction but work transparently in the background. Popular implementations are Google's reCAPTCHA and Cloudflare's Turnstile.

What is reCAPTCHA?
reCAPTCHA is a free CAPTCHA service launched by Google in 2007, with the purpose to provide site owners an easy way to integrate a SaaS-based CAPTCHA API into their sites. Originally, it was also designed to assist with the digitisation of library and newspaper archives and prompted users with scanned content and, thus, crowdsourced the conversion of documents only available in printed form.
reCAPTCHA v1
The first version was a typical text-based CAPTCHA, where the user was supposed to enter the words shown in the CAPTCHA image. You can see a screenshot of it under the text CAPTCHA type.
Google stopped supporting version 1 in 2018.
reCAPTCHA v2
reCAPTCHA v2 was released in 2013 and introduced behavioural analysis, which means reCAPTCHA fingerprints the browser and the user behaviour (i.e. input events, such as mouse and keyboard) already before it even renders the CAPTCHA box and shows by default only a CAPTCHA checkbox. Once the user clicks the checkbox, reCAPTCHA will use the fingerprint to determine whether the user shall pass immediately or be still presented with a proper CAPTCHA challenge.
There's also an "invisible" CAPTCHA implementation, which can be transparently integrated into your site's workflows.
reCAPTCHA v3
In 2018, Google once more enhanced reCAPTCHA and introduced an implementation, which does not require any user interaction at all but rather calculates a bot-score, indicating how likely the request is from a real person versus an automated script.
How to bypass reCAPTCHA when webscraping
All right, now that we got a fairly complete overview what types of CAPTCHAs there are, how can we use that knowledge to enable our web scraper to successfully extract data without stumbling over a CAPTCHA?
Unfortunately, there is not just one single, universal answer but there are different aspects to take into account and that's what we are going to look at next.
Solve CAPTCHAs programmatically
One approach is to simply accept the fact that your scraper may run into CAPTCHAs and try to solve them automatically.
There are plenty of CAPTCHA solving services out there and we'll have a closer look at one of them in just a moment.
Avoid CAPTCHAs altogether
The other and more efficient way is to try and avoid CAPTCHA challenges in the first place. Sites typically do not employ CAPTCHAs straight away, but only if your requests exceeded a certain threshold or were flagged as bot-like. To avoid that, always make sure to:
- Behave like a real browser (headless browsers, TLS fingerprinting)
- Pay attention to dedicated honeypot elements on the site
- Distribute requests across user agents and IP addresses (e.g. ideally residential proxies)
- Pace your requests (don't crawl to quickly)
Bypassing reCAPTCHA and hCaptcha using a reCAPTCHA solving API service
If you search for "recaptcha solving service", you'll find a myriad of platforms and services (e.g. captchas.io, 2captcha.com, anti-captcha.com, capsolver.com, and many others) which all offer a very similar set of features and typically even have similar pricing. For the following Python example we chose anti-captcha.com and use its CAPTCHA API to solve the CAPTCHA at https://recaptcha-demo.appspot.com/recaptcha-v2-checkbox-explicit.php.
Before we dive right into the code, let's first install all the necessary dependencies with pip.
pip install webdriver-manager selenium anticaptchaofficial
Once we have those installed, we can go on right to the code. So without further ado, here the full code sample:
from selenium import webdriver
from selenium.webdriver.firefox.service import Service as FirefoxService
from webdriver_manager.firefox import GeckoDriverManager
from selenium.webdriver.common.by import By
from anticaptchaofficial.recaptchav3proxyless import *
import re
def solve_captcha(url, sitekey):
solver = recaptchaV3Proxyless()
solver.set_verbose(1)
solver.set_key("YOUR_API_KEY_HERE")
solver.set_website_url(url)
solver.set_website_key(sitekey)
solver.set_min_score(0.9)
return solver.solve_and_return_solution()
driver = webdriver.Firefox(service=FirefoxService(GeckoDriverManager().install()))
driver.get("https://recaptcha-demo.appspot.com/recaptcha-v2-checkbox-explicit.php")
# Extract site key
sitekey = re.search('''sitekey['"]\s*:\s*(['"])(.+)\\1''', driver.page_source)
if sitekey == None:
print('No site key found, please configure manually')
driver.quit()
quit()
sitekey = sitekey.group(2)
user = driver.find_element(By.CSS_SELECTOR, 'input[name="ex-a"]')
user.clear()
user.send_keys('username')
pwd = driver.find_element(By.CSS_SELECTOR, 'input[name="ex-b"]')
pwd.clear()
pwd.send_keys('password')
captcha_response = solve_captcha(driver.current_url, sitekey)
if captcha_response == 0:
print('Error during CAPTCHA resolution')
driver.quit()
quit()
# Set CAPTCHA value
driver.execute_script('document.querySelector("#g-recaptcha-response").innerHTML="' + captcha_response + '"');
# Click submit button
driver.find_element(By.CSS_SELECTOR, 'button[type="submit"]').click()
Beautiful, isn't it? But what exactly are we doing here? Let's figure that out one step at a time, shall we?
- We import all the necessary libraries.
- Then, we define the function
solve_captcha, which performs the actual service call to our CAPTCHA API. More on that in a second. - Next, we initialise a Firefox web driver instance and save the reference in
driver. This is going to be our main object to interact with the browser instance. - With our driver object ready, we can call its
getmethod to load the indicated URL into our browser window. - Now that the page is loaded, we have access to the HTML code (
.page_source) and use the regular expressionsitekey['"]\s*:\s*(['"])(.+)\1to extract the site key configured within the page (we are going to pass this tosolve_captchalater). - Next, we use the
find_elementmethod to find the two input fields and call.clear()and.send_keys()to enter some custom text. - Time for the CAPTCHA magic! 🪄 - we now call our function
solve_captchaand pass it the current URL, as well as the site key. This will be a blocking call and the service may take a few seconds to return the correct solution. - Once
solve_captchareturned,captcha_responseshould have the correct answer. If it contains the value "0", an error occurred. - We now run custom JavaScript code in the context of our page (
execute_script) to set the content of a hidden<textarea>object to our CAPTCHA solution. - Last, but not least, we find the submit (again with
find_element) and click it to submit our form.
If everything went fine, our browser window should now show a success message.
Avoiding reCAPTCHA and hCaptcha using a web scraping API
Even though some sites do, most sites won't bother their visitors with CAPTCHAs by default, but only once requests either exceed some custom-defined thresholds configured in their WAF system or follow a pattern atypical for regular users. For such sites, it is best to stay under the radar and make your scraper appear as natural as you can. For that, you need to pay particular attention to the following topics:
Real browser environment
Nothing will give away your scraper identity quicker than a default HTTP client user agent like the following:
Java-http-client/17.0.7
PycURL/7.44.1 libcurl/7.81.0 GnuTLS/3.7.3 zlib/1.2.11 nghttp2/1.43.0 librtmp/2.3
And while there are entire blog articles on how to handle the provided user agent, it probably won't be enough to such switch that to a standard browser user agent (e.g. Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:122.0) Gecko/20100101 Firefox/122.0) as scraping protection systems typically evaluate a lot more than just the user agent. Among other things, they also check
- the fingerprint of the whole browser engine
- the specifics of the TLS handshake
- the ability to run JavaScript code
Headless browsers offer a simple way out of this conundrum, as they'll allow you to run your scraper in the native environment of the web - a regular browser, with all its abilities and features.
ISP addresses
While many people use VPNs (which typically come with datacenter addresses) for regular browsing sessions as well, the majority still surfs the web with their regular ISP-assigned IP addresses. If you scrape a site from your regular AWS or GCP instance, your requests will immediately stand out with their datacenter-assigned IP address. Residential proxies can come to the rescue here, as they allow you to tunnel your scraping requests through regular ISP networks, used by regular users.
Knowing the site's audience
Many sites have an international audience, but if you scrape a site which provides a service for an audience from a specific geographic region, it may fire an alert if you suddenly crawl the entire site from across the planet. Once more proxies can come to the rescue, as they allow you to tunnel your requests through that specific region. Especially with geo-restricted content, that approach is a must.
Pacing requests
Pay attention to how fast you crawl and scrape a site. A scraper can send hundreds of requests a second, no regular user will do that. So make sure you implement reasonable and realistic delays between your individual requests. Also try to randomise your requests (e.g. avoid requests with sequential numbers) and consider that a page load involves more than just the HTML content (i.e. images, style sheets).
ℹ️ Making sure your scraping requests never get blocked
If you want to find out more on how to avoid CAPTCHAs, please check out our article Web Scraping without getting blocked.
Using Scraping APIs
Dedicated scraping platforms, such as ScrapingBee, do all that heavy lifting for you out-of-the-box. They are a kind of Swiss Army knive and provide all the tools and implementations we discussed, conveniently in one place. This includes seamless access to headless browser instances, transparent handling of proxies (including residential ones), native JavaScript support, request throttle management, and more.
Summary
CAPTCHAs can definitely lead to a lot of frustration when you just want to complete a quick scraping job, but you should not despair, as there are plenty of ways to approach them from within a scraper context.
We hope you enjoyed this article and that we managed to provide you with more details on the world of CAPTCHAs, namely what different types of CAPTCHAs there are, how to solve them programmatically, and what tools to use to avoid them altogether.
Always remember, it's bad enough if you have to jump through these hoops when you just browse the web yourself.
You don't want your scraping jobs to have to do the same.
As always, ScrapingBee wishes happy scraping and as few CAPTCHAs as possible!
Before you go, check out these related reads:

Alexander is a software engineer and technical writer with a passion for everything network related.
