Getting Started with Goutte
While Node.js and Python dominate the web scraping landscape, Goutte is the go-to choice for PHP developers. It's a powerful library that provides a simple yet efficient solution to automatically extract data from websites.
Whether you're a beginner or an experienced developer, Goutte allows you to effortlessly scrape data from websites and seamlessly display it on the frontend directly from your PHP scripts. Goutte also ensures that the scraping process doesn't compromise loading time or consume excessive backend resources such as RAM, making it an optimal choice for PHP-based scraping tasks.
In this article, you'll see how you can use Goutte to scrape data from static and dynamic websites as well as fill out forms.

Installing Goutte
Before installing Goutte on your machine, make sure you have installed the following:
Goutte requires PHP version 7.1 or higher. You can use the following command to check which PHP version is installed on your machine:
php --version
To install Goutte for your project, create a directory called php-scraping to keep the libraries, dependencies, and PHP scripts you'll use to scrape data from websites.
In this directory, run the following command to install the Goutte library:
composer require fabpot/goutte
Note: It will add fabpot/goutte as a required dependency in your composer.json file.
{
"require": {
"fabpot/goutte": "^4.0"
}
}
The output above shows that Goutte version 4 has been installed for the project.
Common Methods of Goutte
Below is a list of common methods from the Goutte library that allow you to interact with web pages, navigate through links, submit forms, and extract specific elements based on filters:
request(): sends a request to the specified URL and returns an object that represents the HTML content of a web pageselectLink(): selects a link with a particular condition on a web pagelink(): returns a link from a specific HTML element on a web pageclick(): performs a click action on a selected link on a web pagetext(): prints the text content presented on an HTML elementfilter(): selects only HTML elements with specific values such as class name, ID, and tagsselectButton(): selects a form with a button that has a specific labelsubmit(): submits data to a form object with specific form data
You will use these methods in the following examples to learn how to scrape data using Goutte.
Basic Scraping with Goutte
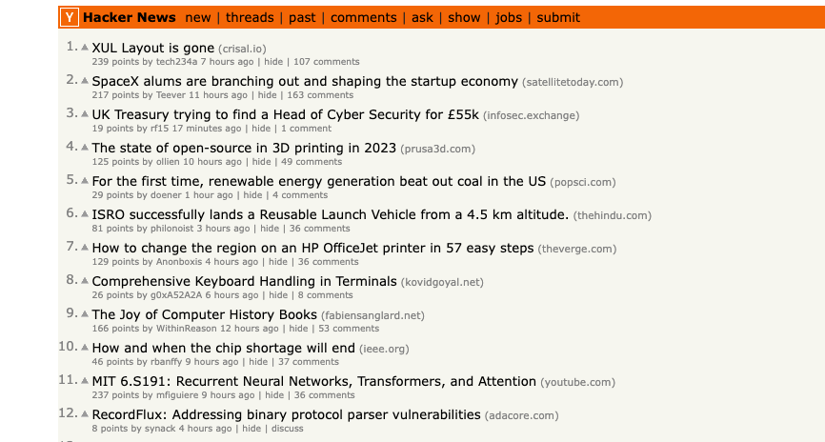
In this first example, you will scrape data from a static website called Hacker News. Specifically, you will collect the following:
- The title of the article
- The link to the article
The collected data will be saved in a CSV file.
Create a PHP File
To start, create a PHP file in the project directory and name it web-static-scraper.php.
Import Libraries
Next, import the PHP library you will use to scrape and collect data from the web page:
<?php
// Include the required autoload file
require 'vendor/autoload.php';
// Import the Goutte client class
use Goutte\Client;
In this code snippet, the require 'vendor/autoload.php'; line includes the autoload file that is typically generated by Composer. The autoload file ensures that all necessary classes and dependencies are automatically loaded when they are used in the code. The use Goutte\Client; line imports the Client class from the Goutte library. This makes it easier to work with the Client class and access its methods and properties when scraping data from the web page.
Create a New Goutte Instance
Next, you need to create a new object for the client class from the Goutte library:
// Create a new instance of the Goutte client
$client = new Client();
The client class is responsible for handling HTTP requests, interacting with web pages, and extracting data from them.
In the code snippet above, the $client object allows you to use the methods and functionalities provided by the client class to perform different actions.
Access the Hacker News Website
To scrape data with Goutte, you need to define the website URL in a simple PHP variable—for example, the $url variable. The URL for the Hacker News website you'll be using is https://news.ycombinator.com/.
Then, you can use the $client object to send a GET request to the specified URL. The request() method on the $client object takes two parameters:
- The HTTP method (in this case, GET)
- The URL to request
// Define the URL of the web page to scrape
$url = "https://news.ycombinator.com/";
// Send a GET request to the URL and retrieve the web page
$crawler = $client->request('GET', $url);
The $crawler variable is assigned the resulting Crawler object, which represents the HTML content of the web page from the specified URL. The Crawler object provides methods for filtering and extracting specific elements from the HTML page.
Below, you'll see how you can use it for processing and extracting data from the web page.
Scrape Data Using HTML Elements
To scrape data from the Hacker News link, you need to use the CSS class selector presented on the web page.
Open the Hacker News URL in your web browser, then right-click and select Inspect to identify the CSS class. You can use your mouse to view the page and identify the CSS class that holds the list of data presented in each article on the web page.
<span class="titleline">
<a href="https://github.com/rexdex/recompiler">Xbox360 -> Windows Executable Converter (2017)</a>
<span class="sitebit comhead">
(<a href="from?site=github.com/rexdex">
<span class="sitestr">github.com/rexdex</span>
</a>
</span>
</span>
The HTML snippet above shows a span element with the HTML class titleline. With that element, we've got our title, as well as article link. Using the filter() method of $crawler, we can pass a CSS selector for that class (i.e. .titleline) and receive a list of all elements with that class.
// Create an empty array to store the extracted data #1
$data = [];
// Filter the DOM elements with class 'titleline' and perform an action for each matched element #2
$crawler->filter('.titleline')->each(function ($node) use (&$data) {
// Extract the title text from the node #3
$title = $node->text();
// Extract the link URL from the node #4
$link = $node->filter('a')->attr('href');
// Add the title and link to the data array #5
$data[] = [$title, $link];
});
The code above extracts data from the DOM elements with the class name titleline and stores it in an array called $data. Here's a breakdown of what the code does according to its corresponding comment number:
- Initializes an empty array called
$datato store the extracted data from the HTML elements - Filters the HTML elements using the CSS class selector
.titlelinewith the help of thefilter()method of the$crawlerobject - Extracts the text content of the current
$nodeelement using thetext()method and assigns it to the variable$title - Filters the current
$nodeto select theaelement within it using thefilter()method, retrieves the value of thehrefattribute using theattr()method, and assigns the URL to the variable$link - Appends an array containing the
$titleand$linkvalues to the$dataarray. Each iteration adds a new array entry to$dataconsisting of the extracted title and link for the current element
The $data array will contain multiple arrays, each representing a pair of extracted title and link values from the HTML elements with the class name titleline.
Save Scraped Data
The final block of code in your PHP file is responsible for saving the scraped data to the CSV file in the specific directory:
// Specify the directory path where you want to save the CSV file
$directory = 'data/';
// Specify the CSV file path
$filePath = $directory . 'scraped_data.csv';
// Create a CSV file for writing
$csvFile = fopen($filePath, 'w');
// Write headers to the CSV file
fputcsv($csvFile, ['Title', 'Link']);
// Write each row of data to the CSV file
foreach ($data as $row) {
// Write a row to the CSV file
fputcsv($csvFile, $row);
}
// Close the CSV file
fclose($csvFile);
The code block specifies the directory path where you want to save the CSV file. It then concatenates the $directory variable with the file name scraped_data.csv to form the complete file path.
It also creates a new CSV file for writing at the specified file path $filePath and uses the fputcsv() function to write an array containing the header values (in this case, Title and Link) as the first row of the CSV file.
Finally, within the loop, it uses the fputcsv() function to write each row of data from the $data array to the CSV file. At the end, it closes the CSV file by calling fclose() on the file pointer resource $csvFile .
Run the PHP Code
Here is the complete code you should have in your PHP file:
<?php
// Include the required autoload file
require 'vendor/autoload.php';
// Import the Goutte client class
use Goutte\Client;
// Create a new instance of the Goutte client
$client = new Client();
// Define the URL of the web page to scrape
$url = "https://news.ycombinator.com/";
// Send a GET request to the URL and retrieve the web page
$crawler = $client->request('GET', $url);
// Create an empty array to store the extracted data
$data = [];
// Filter the DOM elements with class 'titleline' and perform an action for each matched element
$crawler->filter('.titleline')->each(function ($node) use (&$data) {
// Extract the title text from the node
$title = $node->text();
// Extract the link URL from the node
$link = $node->filter('a')->attr('href');
// Add the title and link to the data array
$data[] = [$title, $link];
});
// Specify the directory path where you want to save the CSV file
$directory = 'data/';
// Specify the CSV file path
$filePath = $directory . 'scraped_data.csv';
// Create a CSV file for writing
$csvFile = fopen($filePath, 'w');
// Write headers to the CSV file
fputcsv($csvFile, ['Title', 'Link']);
// Write each row of data to the CSV file
foreach ($data as $row) {
// Write a row to the CSV file
fputcsv($csvFile, $row);
}
// Close the CSV file
fclose($csvFile);
To scrape the title and link for each article on the Hacker News web page, open your terminal and run the PHP script file:
php web-static-scraper.php
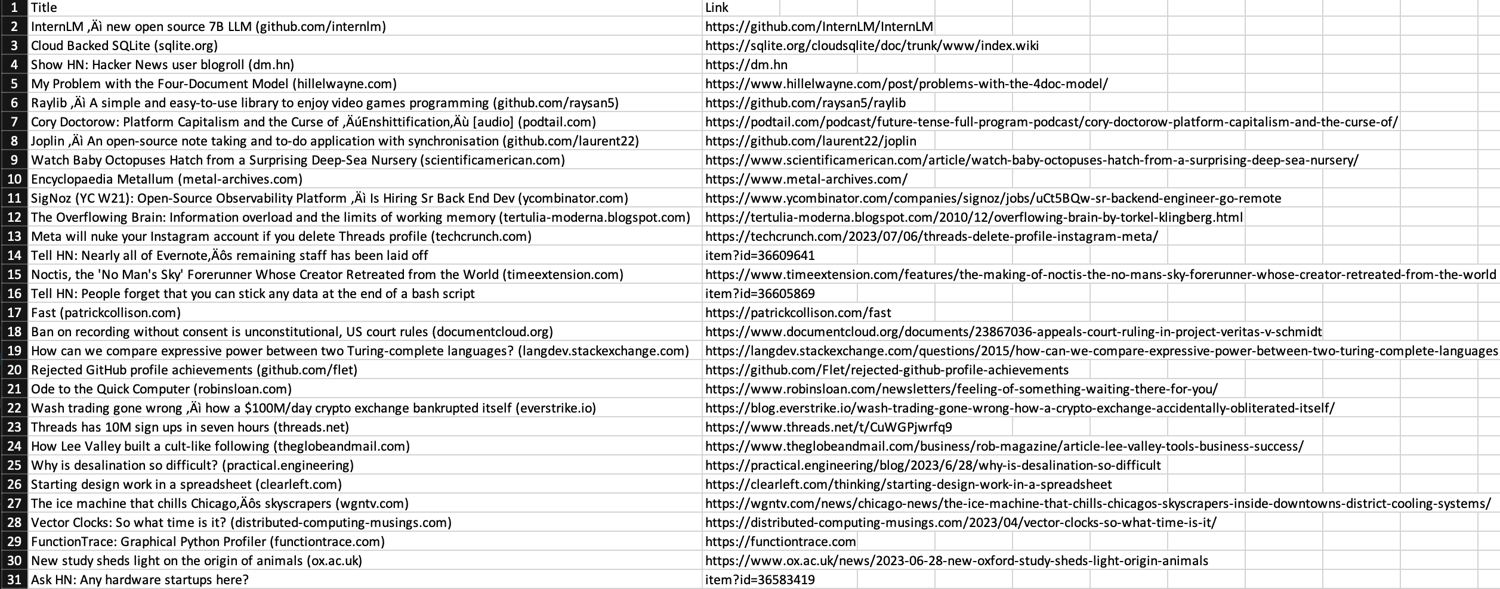
You should now see the scraped data in the CSV file inside the data directory. As you can see in the screenshot below, both the title and link are presented for each article.
Scraping Data from a Dynamic Website
Now let's see how you can use Goutte to interact with a dynamic website such as Scrape This Site.
In this section, you'll search and collect the statistics of a particular hockey team since 1990. You will see how to
- select the search form;
- submit a team name in the search form; and
- scrape statistical data for the selected team.
Create a PHP File
First, create a PHP file named hockey-team-data.php in the project directory. You'll use this file for writing the PHP code to interact with and scrape data from the website.
Import Libraries and Create a New Goutte Instance
You need to import the PHP library that will be used to interact with the web page and scrape data from it. Also create a new object for the client class of the Goutte library:
<?php
// Include the required autoload file
require 'vendor/autoload.php';
// Import the Goutte client class
use Goutte\Client;
// Create a new instance of the Goutte client
$client = new Client();
Access the Website
Define the website URL in a simple PHP variable such as url then use the $client object to send a GET request to the specified URL:
// Define the URL of the web page to scrape
$url = "https://www.scrapethissite.com/";
// Send a GET request to the URL and retrieve the web page
$crawler = $client->request('GET', $url);
Click the Sandbox Link
The next step is to perform a click action using the $crawler object. It will simulate clicking on the "Sandbox" link on the home page of the site and then navigating to the web scraping sandbox page:
// Click on the 'Sand box' link to navigate to web scraping sandbox
$crawler = $client->click($crawler->selectLink('Sandbox')->link());
As you can see, the selectLink() method is used to select the sandbox link, and the click() method is used to click the selected link.
Click on the Desired Link
The web scraping sandbox page shows different links. You want to navigate to the "Hockey Teams: Forms, Searching and Pagination" page, so create a click action for this link using the $crawler object:
// Click on the 'Hockey Teams: Forms, Searching and Pagination' link to navigate to the team stats from 1990
$crawler = $client->click($crawler->selectLink('Hockey Teams: Forms, Searching and Pagination')->link());
Select the Search Form
After accessing this page, you need to select the search form using the selectButton() method and pass the search value:
// Select the 'Search' form
$form = $crawler->selectButton('Search')->form();
This code selects the button with the label Search from the previously obtained $crawler object. It then returns an object representing the HTML form element (->form()).
You will use the $form object to interact with the form by filling in its fields (search query) and then submitting it.
Submit the Search Form
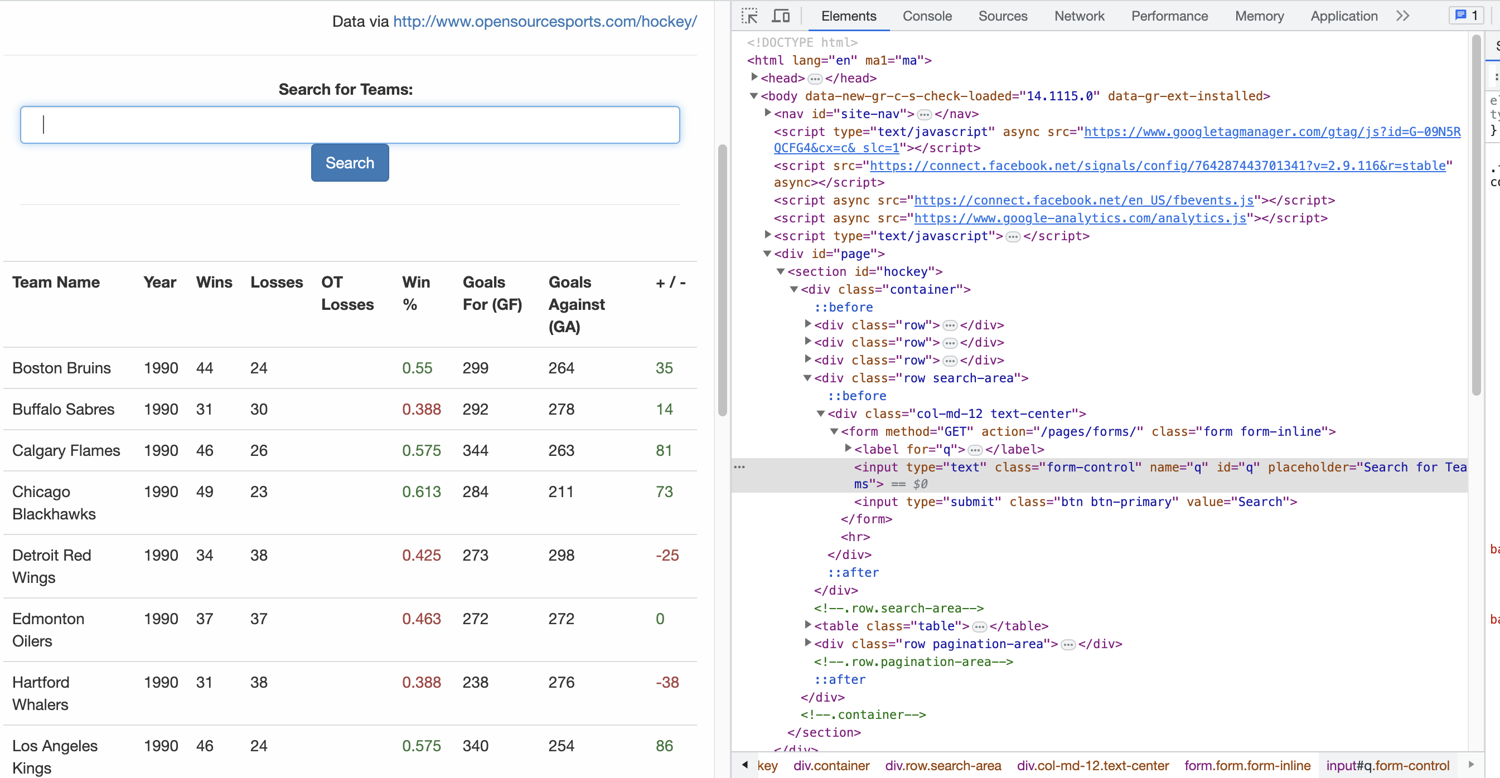
To find the names of the input elements in the search form, follow these steps:
- Right-click on the web page and select Inspect to open the browser's developer tools and view the web page's code.
- Look for the section of code that represents the search form.
- Within the form code, locate the input elements and examine their attributes.
- The
nameattribute of each input element will contain the name of the input field. This name can be used to identify and handle the input data, such as adding the team name.
As you can see in the screenshot below, the input element for the team name is q.
Next, use the submit() method to submit the search form with the value of the team name using the Goutte client and the $form object. You will search the stats for a team called Dallas Stars:
// Submit the 'Search' form with the provided team name
$crawler = $client->submit($form, ['q' => 'Dallas Stars']);
Scrape the Stats of the Team
The final block of code is to scrape the stats of the team and save them in a CSV file:
// Create an empty array to store the extracted data
$data = [];
// Filter the DOM elements with class 'team' and perform an action for each matched element
$crawler->filter('.team')->each(function ($node) use (&$data) {
// Find all <td> elements within the current 'team' element and extract their text values
$tdValues = $node->filter('td')->each(function ($tdNode) {
return trim($tdNode->text());
});
// Add the extracted <td> values to the data array
$data[] = $tdValues;
});
// Specify the directory path where you want to save the CSV file
$directory = 'data/';
// Specify the CSV file path
$csvFilePath = $directory . 'team.csv';
// Open the CSV file in write mode
$file = fopen($csvFilePath, 'w');
// Write the header row to the CSV file
$headerRow = [
'Team Name',
'Year',
'Wins',
'Losses',
'OT Losses',
'Win %',
'Goals For (GF)',
'Goals Against (GA)',
'+ / -'
];
fputcsv($file, $headerRow);
// Write the data rows to the CSV file
foreach ($data as $row) {
fputcsv($file, $row);
}
// Close the CSV file
fclose($file);
The code block starts by creating an empty array to keep all scraped stats for the hockey team.
It then filters the elements by the CSS class team and processes each filtered element by finding all td HTML elements and extracting their text content within the current team element.
Finally, it defines the path and file name of the CSV file, adds the header row, and then saves the data to the CSV file.
Run the PHP Code
Here is the complete code in the PHP file.
<?php
// Include the required autoload file
require 'vendor/autoload.php';
// Import the Goutte client class
use Goutte\Client;
// Create a new instance of the Goutte client
$client = new Client();
// Define the URL of the web page to scrape
$url = "https://www.scrapethissite.com/";
// Send a GET request to the URL and retrieve the web page
$crawler = $client->request('GET', $url);
// Click on the 'Sand box' link to navigate to web scraping sandbox
$crawler = $client->click($crawler->selectLink('Sandbox')->link());
// Click on the 'Hockey Teams: Forms, Searching and Pagination' link to navigate to the team stats from 1990
$crawler = $client->click($crawler->selectLink('Hockey Teams: Forms, Searching and Pagination')->link());
// Select the 'Search' form
$form = $crawler->selectButton('Search')->form();
// Submit the 'Search' form with the provided team name
$crawler = $client->submit($form, ['q' => 'Dallas Stars']);
// Create an empty array to store the extracted data
$data = [];
// Filter the DOM elements with class 'team' and perform an action for each matched element
$crawler->filter('.team')->each(function ($node) use (&$data) {
// Find all <td> elements within the current 'team' element and extract their text values
$tdValues = $node->filter('td')->each(function ($tdNode) {
return trim($tdNode->text());
});
// Add the extracted <td> values to the data array
$data[] = $tdValues;
});
// Specify the directory path where you want to save the CSV file
$directory = 'data/';
// Specify the CSV file path
$csvFilePath = $directory . 'team.csv';
// Open the CSV file in write mode
$file = fopen($csvFilePath, 'w');
// Write the header row to the CSV file
$headerRow = [
'Team Name',
'Year',
'Wins',
'Losses',
'OT Losses',
'Win %',
'Goals For (GF)',
'Goals Against (GA)',
'+ / -'
];
fputcsv($file, $headerRow);
// Write the data rows to the CSV file
foreach ($data as $row) {
fputcsv($file, $row);
}
// Close the CSV file
fclose($file);
To scrape the stats of the selected team from the website, open your terminal and run the PHP script file:
php hockey-team-data.php
You should see a list of stats for the Dallas Stars hockey team in a CSV file:
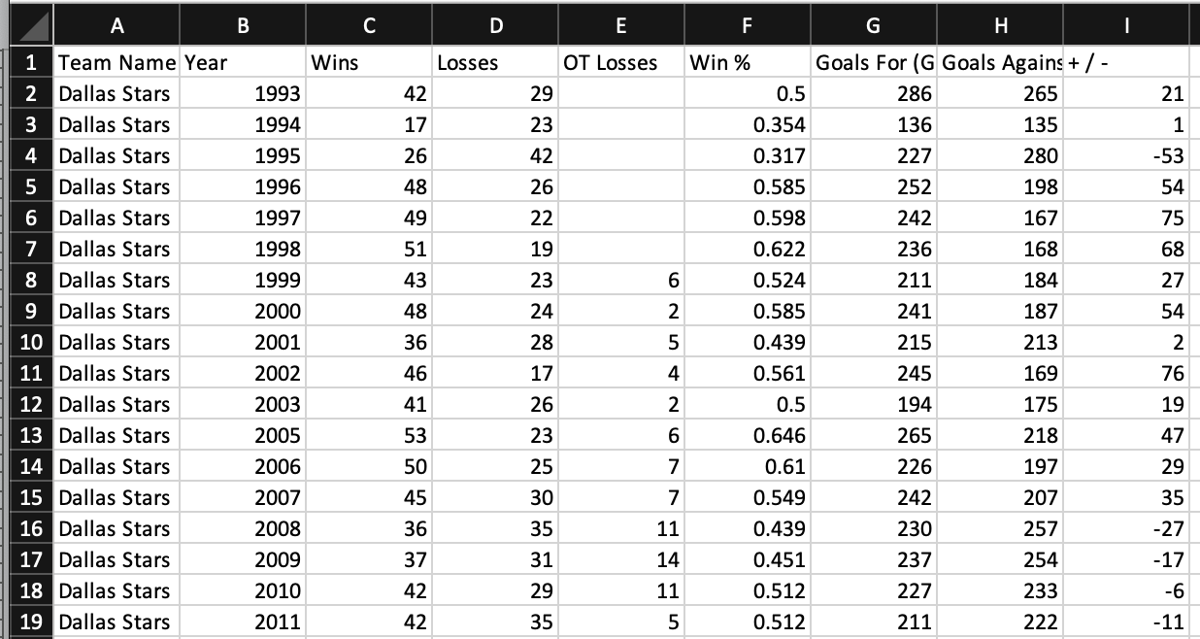
Conclusion
In this article, you learned how to use the Goutte PHP library to scrape data from both Hacker News and Scrape This Site. You learned how to use different HTML elements such as class names, forms, buttons, and links to automatically interact with and collect the data that you need.
Although Goutte enables scraping, it can be time-consuming and quickly becomes complicated for more complex web scraping tasks. Goutte is also deprecated and has become a proxy for the HttpBrowser class from the Symfony BrowserKit component. The Goutte team recommends migrating away from it.
ℹ️ For more PHP webscraping knowledge check out our PHP webscraping tutorial.
To simplify the process of scraping and avoid using a library that may be deprecated, consider Scrapingbee's scraping platform. It's a no-code web scraping API that can handle rotating proxies, headless browsers, and CAPTCHAs.
If you prefer not to deal with rate limits, proxies, user agents, and browser fingerprints, check it out. The first 1,000 calls are free!

Davis David is a data scientist passionate about artificial intelligence, machine learning, deep learning, and software development. Davis is the co-organizer of AI meetups, workshops, and events with the goal of building a community of data scientists in Tanzania to solve local problems.


