I want to scrape a website, but wait, how do I get the links?
Good question! That's exactly what we are going to answer in this blog post.
While there are multiple options for this, we are going with an easy route, that is, Extracting links from sitemap!
Most websites on the internet provides all of their links in a sitemap.xml or similar file. The reason they create this is to make it easier for search engines to find the website links.
Sneak Peek
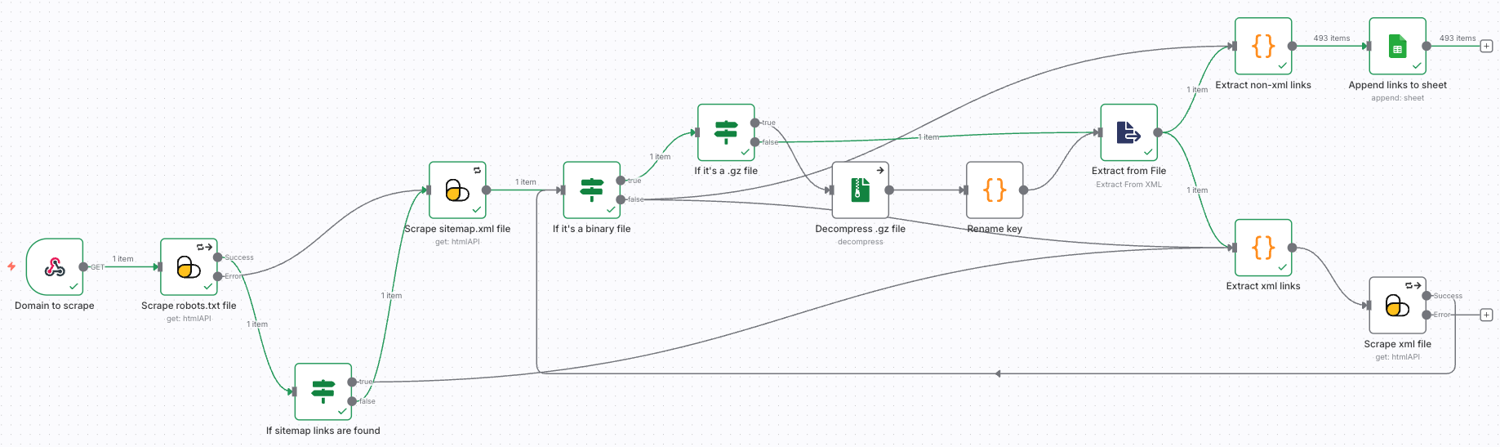
In case you are curious, here is a screenshot of what we will be building:
Prerequisites
These are the prerequisites to build our workflow:
- A ScrapingBee API key
- An n8n instance (cloud or self-hosted)
- A Google Sheet with a single column named links
And that would be it! Let's get started!
Action Plan
Here is a rough sketch on what the workflow should do:
- Look for sitemaps in robots.txt file
- If found, we will extract the xml links and scrape them
- If not found, we will check the sitemap.xml file
- After scraping a .xml or .xml.gz file, if the file is binary we will extract text from it
- If it's compressed file, we will first decompress it and then extract text from the file
- If it's a text response, or after extracting it from file, we will extract the xml and non-xml links from it
- We will append all the non-xml links to a Google sheet
- We will send a scraping request for new xml links and connect the workflow to itself to create a recursive behaviour
- The workflow will stop when all non-xml links are added to the sheet
Sitemap Link Extractor Workflow
1. Input: Webhook (domain parameter)
Create a Webhook node named "Domain to scrape". Trigger it with:
https://<your-webhook-url>?domain=n8n.io
This provides {{ $('Domain to scrape').item.json.query.domain }} to downstream nodes.
2. Try robots.txt first (faster discovery)
Add a ScrapingBee node named "Scrape robots.txt file":
- URL:
https://{{ $('Domain to scrape').item.json.query.domain }}/robots.txt
Render JS: false (robots are static text)
Retry On Fail: true
On Error: Continue (using error output) — so the flow can fall back to sitemap.xml Then add an IF node named "If sitemap links are found" to look for
Sitemap:lines:Left value:
{{ $json.data }}Operator:
containsRight value:
Sitemap:
True path: go straight to Extract XML links (step 6.2).
False path: go to step 3 to fetch
sitemap.xml.
3. Fallback to /sitemap.xml
Add a ScrapingBee node named "Scrape sitemap.xml file":
URL:
https://{{ $('Domain to scrape').item.json.query.domain }}/sitemap.xmlRender JS:
falseRetry On Fail:
true;
This node feeds into binary/text detection (step 4.1).
4. Binary vs text responses & .gz handling
4.1 Detect binary responses
Add an IF node named "If it’s a binary file":
- Left value:
{{ $binary }} - Operator:
is not empty(object → is not empty)
True → check if it’s .gz.
False → treat as text JSON and send into link extraction directly.
4.2 If it’s .gz, decompress and normalize the key
Add an IF node named "If it’s a .gz file":
- Left value:
{{ $binary.data.fileExtension }} - Operator:
equals - Right value:
gz
If true:
4.2.1. Add a Compression node (“Decompress .gz file”)
4.2.2. Then connect it to Code node (“Rename key”) to move the decompressed binary from file_0 to data so the XML parser can consume a single property:
// Rename key (runOnceForEachItem)
const item = $input.item;
item.binary.data = item.binary.file_0;
delete item.binary.file_0;
return item;
Then forward to Extract from File (XML parser) in step 5.
If false (binary but not gz), forward binary to Extract from File directly.
If the earlier "If it’s a binary file" was false (text mode), skip to Step 6 (the extractors can parse URLs from text too).
5. Parse XML to JSON (works for .xml and decompressed .gz)
Add Extract from File (operation: XML) with:
- Binary property:
data
This converts your binary XML into structured JSON for robust URL extraction. From here, we fork to two Code nodes: one that emits non-XML links (pages) and one that emits XML links (child sitemaps).
6. Extract links (two Code nodes)
Create both Code nodes and connect them to:
- Extract from File (when binary/XML) and
- The non-binary (text) branch from "If it’s a binary file" so the same extraction logic works for both cases.
6.1 Code: Extract non-XML links
This code takes in a collection of input items, scans through every nested field to collect all text strings, and extracts any URLs it finds. It then cleans those URLs by decoding &, removing trailing punctuation or brackets, and stripping away escape sequences like \n. Before keeping them, it filters out any unwanted links, such as those ending in .xml or .xml.gz, or pointing to www.sitemaps.org or www.w3.org. It also ensures that only unique links are included by tracking them in a set. Finally, it returns each valid, cleaned, non-XML link as a separate output item in the format { "link": "..." }.
// Code node: return only non-XML links as separate items { "link": "..." }
// Excludes *.xml, *.xml.gz, any link to www.sitemaps.org, and www.w3.org
// Robust against escaped \n, mixed HTML/XML/JSON, and trailing punctuation
const items = $input.all();
const seen = new Set();
const results = [];
// Add only non-XML URLs, excluding sitemaps.org and w3.org
function add(url) {
if (!url) return;
// Decode common HTML entity for &
url = url.replace(/&/gi, "&");
// Trim trailing punctuation/brackets that often stick to URLs
url = url.replace(/[)\]\},.;!?'"\u00BB\u203A>]+$/g, "");
// Ignore query/hash when checking extension
const noQuery = url.replace(/[#?].*$/, "");
// Skip *.xml and *.xml.gz
if (/\.xml(\.gz)?$/i.test(noQuery)) return;
// Skip www.sitemaps.org links
if (/^https?:\/\/www\.sitemaps\.org\//i.test(noQuery)) return;
// Skip www.w3.org links
if (/^https?:\/\/www\.w3\.org\//i.test(noQuery)) return;
if (!seen.has(url)) {
seen.add(url);
results.push({ json: { link: url } });
}
}
// Recursively collect all string values from any object/array shape
function collectStrings(value, out) {
if (value == null) return;
if (typeof value === 'string') { out.push(value); return; }
if (Array.isArray(value)) { for (const v of value) collectStrings(v, out); return; }
if (typeof value === 'object') {
for (const k of Object.keys(value)) collectStrings(value[k], out);
}
}
// Normalize both real control chars and escaped sequences like "\n"
function normalizeText(text) {
return String(text)
.replace(/\\[nrvtf]/g, ' ') // turn escaped \n \r \t \v \f into spaces
.replace(/[\n\r\t\f\v]+/g, ' '); // collapse real control whitespace
}
// URL extractor that stops at whitespace AND backslash (handles leftover "\n")
function extractFromText(text) {
if (!text) return;
const t = normalizeText(text);
const urlRe = /https?:\/\/[^\s\\<>"')]+/gi;
let m;
while ((m = urlRe.exec(t)) !== null) add(m[0]);
}
// Process all input items
for (const item of items) {
// Merge any pre-existing links if present
if (Array.isArray(item.json?.links)) {
for (const l of item.json.links) add(String(l));
}
// Extract from every string field (any key/shape)
const strings = [];
collectStrings(item.json ?? {}, strings);
for (const s of strings) extractFromText(s);
}
return results;
Connect this node to Google Sheets → Append (step 7).
6.2 Code: Extract XML links (child sitemaps)
This code scans any incoming items (no matter how nested) to find and extract only URLs that end in .xml or .xml.gz: it recursively collects all string fields, normalizes text to handle real and escaped control characters (like \n), and uses a URL regex that stops at whitespace or backslashes to avoid trailing junk; for each found URL it decodes & to &, trims common trailing punctuation/brackets, checks the extension on the path while ignoring any ?query/#hash, deduplicates using a Set, and outputs each unique match as a separate item in the shape { json: { xml: "https://..." } }.
// Code node: extract .xml and .xml.gz from ANY input shape
// Output: [{ json: { xml: "https://..." } }, ... ]
const items = $input.all();
const seen = new Set();
const results = [];
// Add a URL if it ends with .xml or .xml.gz (ignoring ?query/#hash)
function add(url) {
if (!url) return;
// Decode common HTML entity for &
url = url.replace(/&/gi, "&");
// Trim trailing punctuation/brackets that often stick to URLs
url = url.replace(/[)\]\},.;!?'"\u00BB\u203A>]+$/g, "");
// Check extension on the path only
const noQuery = url.replace(/[#?].*$/, "");
if (!/\.xml(\.gz)?$/i.test(noQuery)) return;
if (!seen.has(url)) {
seen.add(url);
results.push({ json: { xml: url } });
}
}
// Recursively collect all string values from any object/array shape
function collectStrings(value, out) {
if (value == null) return;
if (typeof value === 'string') { out.push(value); return; }
if (Array.isArray(value)) { for (const v of value) collectStrings(v, out); return; }
if (typeof value === 'object') {
for (const k of Object.keys(value)) collectStrings(value[k], out);
}
}
// Normalize both real control chars and escaped sequences like "\n"
function normalizeText(text) {
return String(text)
.replace(/\\[nrvtf]/g, ' ') // turn escaped \n \r \t \v \f into spaces
.replace(/[\n\r\t\f\v]+/g, ' '); // collapse real control whitespace
}
// URL extractor that stops at whitespace AND backslash (handles leftover "\n")
function extractFromText(text) {
if (!text) return;
const t = normalizeText(text);
const urlRe = /https?:\/\/[^\s\\<>"')]+/gi; // note the extra '\\' stop char
let m;
while ((m = urlRe.exec(t)) !== null) add(m[0]);
}
// Process all input items (schema-agnostic)
for (const item of items) {
// Merge any pre-existing links arrays if present
if (Array.isArray(item.json?.links)) {
for (const l of item.json.links) extractFromText(String(l));
}
// Extract from every string field (any key/shape, nested included)
const strings = [];
collectStrings(item.json ?? {}, strings);
for (const s of strings) extractFromText(s);
}
return results;
Connect this node to “Scrape xml file” (ScrapingBee), which fetches each child sitemap URL and goes back into the binary/text → decompress → parse loop. That’s what makes the workflow recursive across nested sitemaps.
7. Append discovered page links to Google Sheets
Add Google Sheets → Append named “Append links to sheet”:
Document: your Sheet URL
Sheet: the worksheet (e.g.,
Sheet1)Columns mapping:
{ "links": "{{ $json.link }}" }Options:
useAppend: true
This node should receive items only from “Extract non-xml links” so you store page URLs (not sitemap URLs).
8. Make the recursion work
Wire the "Scrape xml file" (ScrapingBee) back to "If it’s a binary file"
This loop continues until there are no more .xml or .xml.gz URLs to fetch, while regular page links keep streaming into Sheets.
Testing
Trigger the webhook:
curl "https://<your-webhook-url>?domain=n8n.io"
If everything goes well, you should see the website links being appended to the Google Sheet link you provided.
Final note on very large sitemaps (important)
If a sitemap (or its nested children) is very large, the workflow can consume a lot of memory and crash depending on your n8n plan or server configuration. If this happens, consider upgrading your n8n plan for more memory or self-hosting n8n on a machine with higher RAM.
Conclusion
You now have a complete, recursive sitemap extractor powered by ScrapingBee—perfect for URL discovery, SEO auditing, and large-scale scraping pipelines.
We hope you’ve enjoyed it, and see you again next time!
P.S. We have also created it as a template in n8n.
Before you go, check out these related reads:

