Web crawling is a powerful technique to collect data from the web by finding all the URLs for one or multiple domains. Python has several popular web crawling libraries and frameworks.
In this article, we will first introduce different crawling strategies and use cases. Then we will build a simple web crawler from scratch in Python using two libraries: Requests and Beautiful Soup. Next, we will see why it’s better to use a web crawling framework like Scrapy. Finally, we will build an example crawler with Scrapy to collect film metadata from IMDb and see how Scrapy scales to websites with several million pages.

What is a web crawler?
Web crawling and web scraping are two different but related concepts. Web crawling is a component of web scraping, the crawler logic finds URLs to be processed by the scraper code.
A web crawler starts with a list of URLs to visit, called the seed. For each URL, the crawler finds links in the HTML, filters those links based on some criteria and adds the new links to a queue. All the HTML or some specific information is extracted to be processed by a different pipeline.
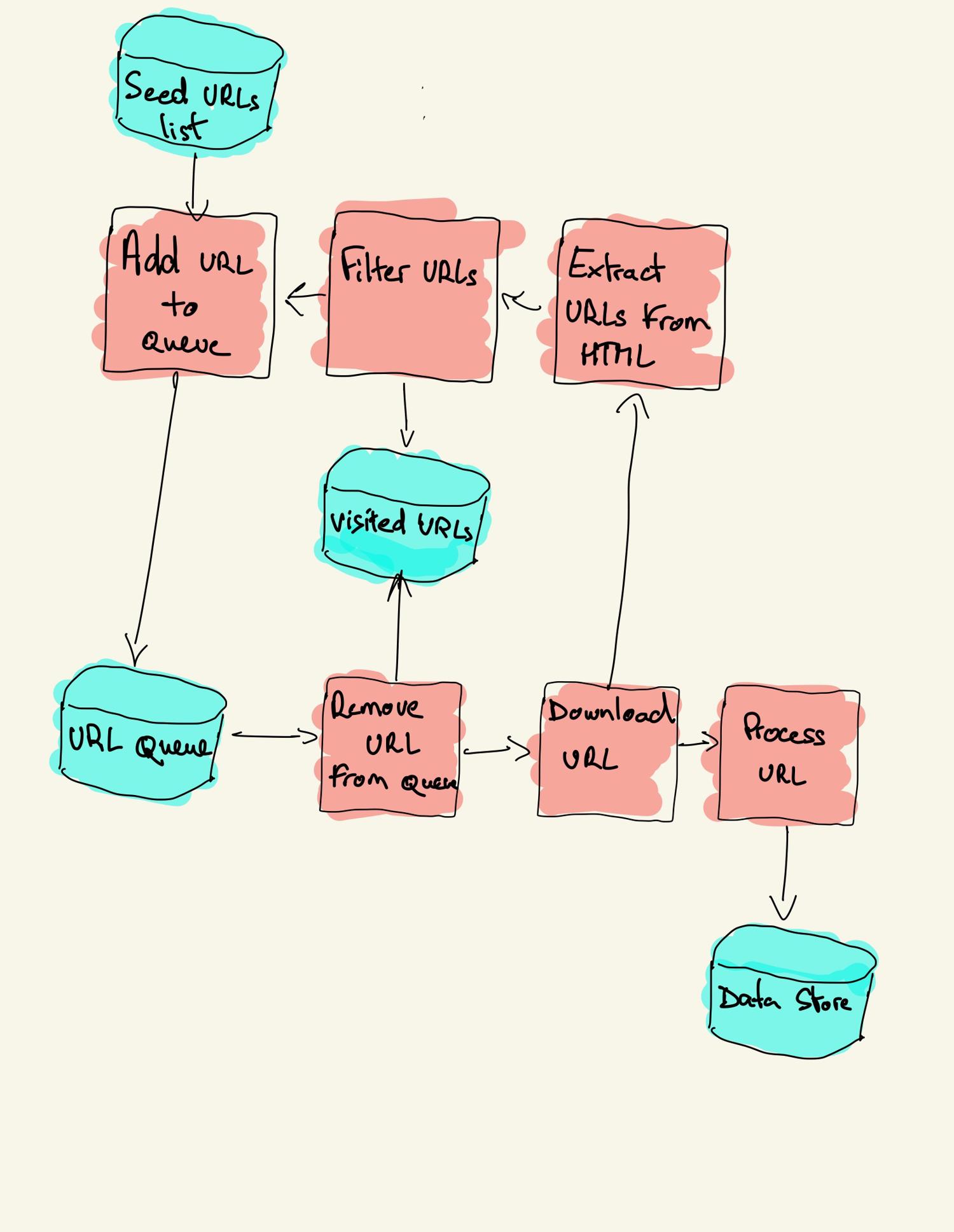
Web crawling strategies
In practice, web crawlers only visit a subset of pages depending on the crawler budget, which can be a maximum number of pages per domain, depth or execution time.
Many websites provide a robots.txt file to indicate which paths of the website can be crawled, and which ones are off-limits. There's also sitemap.xml, which is a bit more explicit than robots.txt and specifically instructs bots which paths should be crawled and provide additional metadata for each URL.
Popular web crawler use cases include:
- Search engines (e.g. Googlebot, Bingbot, Yandex Bot…) collect all the HTML for a significant part of the Web. This data is indexed to make it searchable.
- SEO analytics tools on top of collecting the HTML also collect metadata like the response time, response status to detect broken pages and the links between different domains to collect backlinks.
- Price monitoring tools crawl e-commerce websites to find product pages and extract metadata, notably the price. Product pages are then periodically revisited.
- Common Crawl maintains an open repository of web crawl data. For example, the archive from May 2022 contains 3.45 billion web pages.
Next, we will compare three different strategies for building a web crawler in Python. First, using only standard libraries, then third party libraries for making HTTP requests and parsing HTML, and, finally, a web crawling framework.
Building a simple web crawler in Python from scratch
To build a simple web crawler in Python we need at least one library to download the HTML from a URL and another one to extract links. Python provides the standard libraries urllib for performing HTTP requests and html.parser for parsing HTML. An example Python crawler built only with standard libraries can be found on Github.
There are also other popular libraries, such as Requests and Beautiful Soup, which may provide an improved developer experience when composing HTTP requests and handling HTML documents. If you wan to learn more, you can check this guide about the best Python HTTP client.
You can install the two libraries locally.
pip install requests bs4
A basic crawler can be built following the previous architecture diagram.
import logging
from urllib.parse import urljoin
import requests
from bs4 import BeautifulSoup
logging.basicConfig(
format='%(asctime)s %(levelname)s:%(message)s',
level=logging.INFO)
class Crawler:
def __init__(self, urls=[]):
self.visited_urls = []
self.urls_to_visit = urls
def download_url(self, url):
return requests.get(url).text
def get_linked_urls(self, url, html):
soup = BeautifulSoup(html, 'html.parser')
for link in soup.find_all('a'):
path = link.get('href')
if path and path.startswith('/'):
path = urljoin(url, path)
yield path
def add_url_to_visit(self, url):
if url not in self.visited_urls and url not in self.urls_to_visit:
self.urls_to_visit.append(url)
def crawl(self, url):
html = self.download_url(url)
for url in self.get_linked_urls(url, html):
self.add_url_to_visit(url)
def run(self):
while self.urls_to_visit:
url = self.urls_to_visit.pop(0)
logging.info(f'Crawling: {url}')
try:
self.crawl(url)
except Exception:
logging.exception(f'Failed to crawl: {url}')
finally:
self.visited_urls.append(url)
if __name__ == '__main__':
Crawler(urls=['https://www.imdb.com/']).run()
Our bot here defines a Crawler class with a couple of helper methods (download_url using the Requests library, get_linked_urls using the Beautiful Soup library, and add_url_to_visit to filter URLs) and then continues by instantiating the class with our IMDb start URL and calling its run() method.
The run will run as long as there are pending URLs in urls_to_visit, will pass each URL to crawl(), extract any links, and add them to urls_to_visit - rinse and repeat.
To run our crawler, simply enter this command on your command line.
python crawler.py
The crawler logs one line for each visited URL.
INFO:Crawling: https://www.imdb.com/
INFO:Crawling: https://www.imdb.com/?ref_=nv_home
INFO:Crawling: https://www.imdb.com/calendar/?ref_=nv_mv_cal
INFO:Crawling: https://www.imdb.com/list/ls016522954/?ref_=nv_tvv_dvd
INFO:Crawling: https://www.imdb.com/chart/top/?ref_=nv_mv_250
INFO:Crawling: https://www.imdb.com/chart/moviemeter/?ref_=nv_mv_mpm
INFO:Crawling: https://www.imdb.com/feature/genre/?ref_=nv_ch_gr
The code is very simple but there are many performance and usability issues to solve before successfully crawling a complete website.
- The crawler is slow and supports no parallelism. As can be seen from the timestamps, it takes about one second to crawl each URL. Each time the crawler makes a request it waits for the response and doesn't do much else.
- The download URL logic has no retry mechanism, the URL queue is not a real queue and not very efficient with a high number of URLs.
- The link extraction logic doesn’t support standardizing URLs by removing URL query string parameters, doesn’t handle relative anchor/fragment URLs (i.e.
href="#myanchor"), and doesn’t support filtering URLs by domain or filtering out requests to static files. - The crawler doesn’t identify itself and ignores the robots.txt file.
💡Want more methods for gathering all the URLs on a website? Then check out our guide on multiple methods for finding all the URLs on a website
Next, we will see how Scrapy provides all these functionalities and makes it easy to extend for your custom crawls.
Web crawling with Scrapy
Scrapy is the most popular web scraping and crawling Python framework with close to 50k stars on Github. One of the advantages of Scrapy is that requests are scheduled and handled asynchronously. This means that Scrapy can send another request before the previous one has completed or do some other work in between. Scrapy can handle many concurrent requests but can also be configured to respect the websites with custom settings, as we’ll see later.
Scrapy has a multi-component architecture. Normally, you will implement at least two different classes: Spider and Pipeline. Web scraping can be thought of as an ETL where you extract data from the web and load it to your own storage. Spiders extract the data and pipelines load it into the storage. Transformation can happen both in spiders and pipelines, but I recommend that you set a custom Scrapy pipeline to transform each item independently of each other. This way, failing to process an item has no effect on other items.
On top of all that, you can add spider and downloader middlewares in between components as it can be seen in the diagram below.
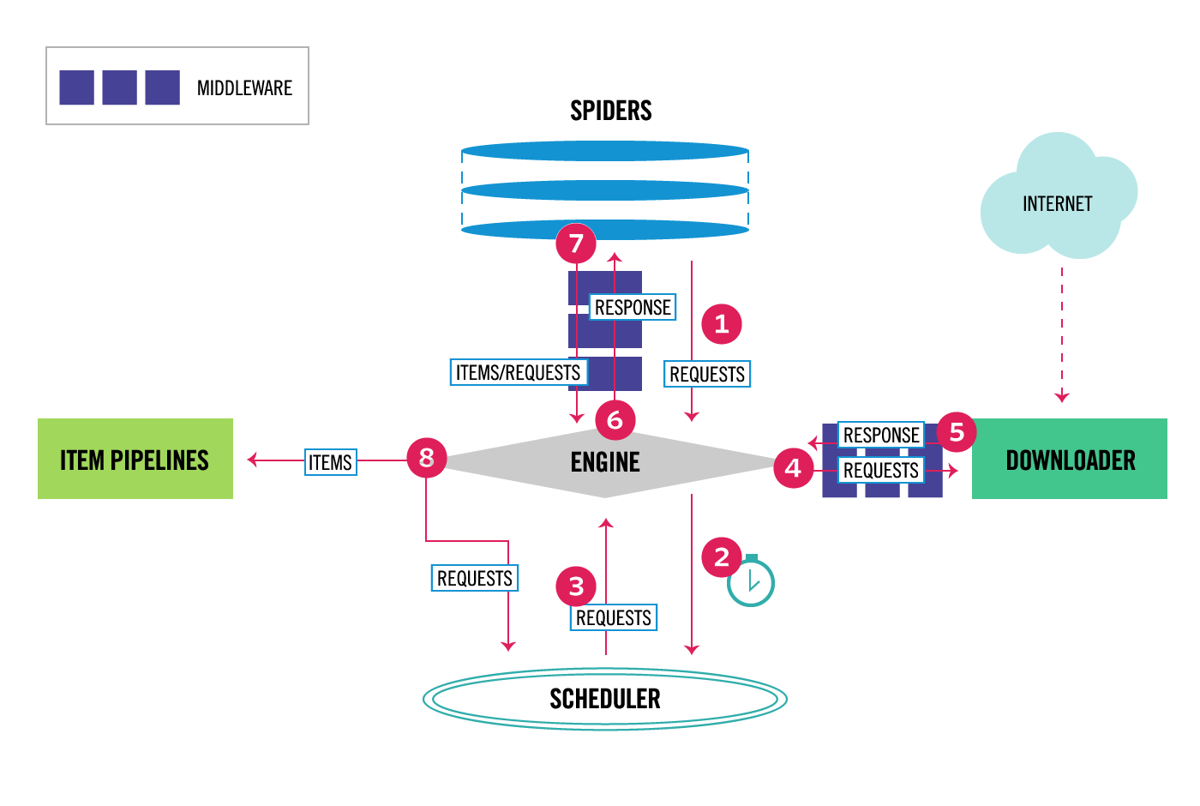
Scrapy Architecture Overview [source]
If you used Scrapy before, you know that a web scraper is defined as a class that inherits from the base Spider class and implements a parse method to handle each response. If you are new to Scrapy, you can read this article for easy scraping with Scrapy.
from scrapy.spiders import Spider
class ImdbSpider(Spider):
name = 'imdb'
allowed_domains = ['www.imdb.com']
start_urls = ['https://www.imdb.com/']
def parse(self, response):
pass
Scrapy also provides several generic spider classes: CrawlSpider, XMLFeedSpider, CSVFeedSpider and SitemapSpider. The CrawlSpider class inherits from the base Spider class and provides an extra rules attribute to define how to crawl a website. Each rule uses a LinkExtractor to specify which links are extracted from each page. Next, we will see how to use each one of them by building a crawler for IMDb, the Internet Movie Database.
Building an example Scrapy crawler for IMDb
Before trying to crawl IMDb, I checked IMDb robots.txt file to see which URL paths are allowed. The robots file only disallows 26 paths for all user-agents. Scrapy reads the robots.txt file beforehand and respects it when the ROBOTSTXT_OBEY setting is set to true. This is the case for all projects generated with the Scrapy command startproject.
scrapy startproject scrapy_crawler
This command creates a new project with the default Scrapy project folder structure.
scrapy_crawler/
├── scrapy.cfg
└── scrapy_crawler
├── __init__.py
├── items.py
├── middlewares.py
├── pipelines.py
├── settings.py
└── spiders
├── __init__.py
Then you can create a spider in scrapy_crawler/spiders/imdb.py with a rule to extract all links.
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
class ImdbCrawler(CrawlSpider):
name = 'imdb'
allowed_domains = ['www.imdb.com']
start_urls = ['https://www.imdb.com/']
rules = (Rule(LinkExtractor()),)
Now, simply launch the crawler with the scrapy command
scrapy crawl imdb --logfile imdb.log
You will get lots of logs, including one log for each request. Exploring the logs I noticed that even if we set allowed_domains to only crawl web pages under https://www.imdb.com, there were requests to external domains, such as amazon.com.
[scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (302) to <GET https://www.amazon.com/b/?&node=5160028011&ref_=ft_iba> from <GET [https://www.imdb.com/whitelist-offsite?url=https%3A%2F%2Fwww.amazon.com%2Fb%2F%3F%26node%3D5160028011%26ref_%3Dft_iba&page-action=ft-iba&ref=ft_iba](https://www.imdb.com/whitelist-offsite?url=https%3A%2F%2Fwww.amazon.com%2Fb%2F%3F%26node%3D5160028011%26ref_%3Dft_iba&page-action=ft-iba&ref=ft_iba)>
IMDb redirects paths under /whitelist-offsite and /whitelist to external domains. There is an open Scrapy Github issue that shows that external URLs don’t get filtered out when OffsiteMiddleware is applied before RedirectMiddleware. To fix this issue, we can configure the link extractor to skip URLs starting with two regular expressions.
class ImdbCrawler(CrawlSpider):
name = 'imdb'
allowed_domains = ['www.imdb.com']
start_urls = ['https://www.imdb.com/']
rules = (
Rule(LinkExtractor(
deny=[
re.escape('https://www.imdb.com/offsite'),
re.escape('https://www.imdb.com/whitelist-offsite'),
],
)),
)
Rule and LinkExtractor classes support several arguments to filter URLs. For example, you can ignore specific file extensions and reduce the number of duplicate URLs by sorting or collapsing query strings.
If you don’t find a specific argument for your use case, you can use the parameter process_value of LinkExtractor or process_links of Rule. For example, we got the same page twice, once as plain URL, another time with additional query string parameters.
To limit the number of crawled URLs, we can remove all query strings from URLs with the url_query_cleaner function from the w3lib library and use it in process_links.
from w3lib.url import url_query_cleaner
def process_links(links):
for link in links:
link.url = url_query_cleaner(link.url)
yield link
class ImdbCrawler(CrawlSpider):
name = 'imdb'
allowed_domains = ['www.imdb.com']
start_urls = ['https://www.imdb.com/']
rules = (
Rule(LinkExtractor(
deny=[
re.escape('https://www.imdb.com/offsite'),
re.escape('https://www.imdb.com/whitelist-offsite'),
],
), process_links=process_links),
)
Now that we have limited the number of requests to process, we can add a parse_item method to extract data from each page and pass it to a pipeline to store it. For example, we can either take response.text process it in a different pipeline or select the HTML metadata.
To select the HTML metadata in the header tag we can specify our own XPath expressions but I find it better to use a library, extruct, that extracts all metadata from an HTML page. You can install it with pip install extruct.
import re
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from w3lib.url import url_query_cleaner
import extruct
def process_links(links):
for link in links:
link.url = url_query_cleaner(link.url)
yield link
class ImdbCrawler(CrawlSpider):
name = 'imdb'
allowed_domains = ['www.imdb.com']
start_urls = ['https://www.imdb.com/']
rules = (
Rule(
LinkExtractor(
deny=[
re.escape('https://www.imdb.com/offsite'),
re.escape('https://www.imdb.com/whitelist-offsite'),
],
),
process_links=process_links,
callback='parse_item',
follow=True
),
)
def parse_item(self, response):
return {
'url': response.url,
'metadata': extruct.extract(
response.text,
response.url,
syntaxes=['opengraph', 'json-ld']
),
}
I set the follow attribute to True so that Scrapy still follows all links from each response, even if we provided a custom parse method. I also configured extruct to extract only Open Graph metadata and JSON-LD, a popular method for encoding linked data using JSON in the Web, used by IMDb. You can run the crawler and store items in JSON lines format to a file.
scrapy crawl imdb --logfile imdb.log -o imdb.jl -t jsonlines
The output file imdb.jl contains one line for each crawled item. For example, the extracted Open Graph metadata, for a movie taken from the <meta> tags in the HTML, looks like this.
{
"url": "http://www.imdb.com/title/tt2442560/",
"metadata": {"opengraph": [{
"namespace": {"og": "http://ogp.me/ns#"},
"properties": [
["og:url", "http://www.imdb.com/title/tt2442560/"],
["og:image", "https://m.media-amazon.com/images/M/MV5BMTkzNjEzMDEzMF5BMl5BanBnXkFtZTgwMDI0MjE4MjE@._V1_UY1200_CR90,0,630,1200_AL_.jpg"],
["og:type", "video.tv_show"],
["og:title", "Peaky Blinders (TV Series 2013\u2013 ) - IMDb"],
["og:site_name", "IMDb"],
["og:description", "Created by Steven Knight. With Cillian Murphy, Paul Anderson, Helen McCrory, Sophie Rundle. A gangster family epic set in 1900s England, centering on a gang who sew razor blades in the peaks of their caps, and their fierce boss Tommy Shelby."]
]
}]}
}
The JSON-LD for a single item is too long to be included in the article, here is a sample of what Scrapy extracts from the <script type="application/ld+json"> tag.
"json-ld": [
{
"@context": "http://schema.org",
"@type": "TVSeries",
"url": "/title/tt2442560/",
"name": "Peaky Blinders",
"image": "https://m.media-amazon.com/images/M/MV5BMTkzNjEzMDEzMF5BMl5BanBnXkFtZTgwMDI0MjE4MjE@._V1_.jpg",
"genre": ["Crime","Drama"],
"contentRating": "TV-MA",
"actor": [
{
"@type": "Person",
"url": "/name/nm0614165/",
"name": "Cillian Murphy"
},
...
]
...
}
]
Exploring the logs, I noticed another common issue with crawlers. By sequentially clicking on filters, the crawler generates URLs with the same content, only that the filters were applied in a different order.
- https://www.imdb.com/name/nm2900465/videogallery/content_type-trailer/related_titles-tt0479468
- https://www.imdb.com/name/nm2900465/videogallery/related_titles-tt0479468/content_type-trailer
Long filter and search URLs is a difficult problem that can be partially solved by limiting the length of URLs with a Scrapy setting, URLLENGTH_LIMIT.
I used IMDb as an example to show the basics of building a web crawler in Python. I didn’t let the crawler run for long as I didn’t have a specific use case for the data. In case you need specific data from IMDb, you can check the IMDb Datasets project that provides a daily export of IMDb data or Cinemagoer, a Python package specifically for fetching and handling IMDb data.
Web crawling at scale
If you attempt to crawl a big website like IMDb, with over 130 million pages (at least according to Google), it’s important to crawl responsibly by adjusting your crawler and tweaking its settings accordingly.
- USER_AGENT - Allows you to specify the user agent and provide possible contact details
- DOWNLOAD_DELAY - Specifies for how many seconds your crawler should wait between requests
- CONCURRENT_REQUESTS_PER_DOMAIN - Indicates how many simultaneous requests maximum your crawler should send to one site
- AUTOTHROTTLE_ENABLED - Enables automated and dynamic request throttling
Notice that Scrapy crawls are optimized for a single domain by default. If you are crawling multiple domains check these settings to optimize for broad crawls, including changing the default crawl order from depth-first to breath-first. To limit your crawl budget, you can limit the number of requests with the CLOSESPIDER_PAGECOUNT setting of the close spider extension.
With the default settings, Scrapy crawls about 600 pages per minute for a website like IMDb. Crawling 130 million pages would take about half a year at that speed with a single robot. If you need to crawl multiple websites it can be better to launch separate crawlers for each big website or group of websites. If you are interested in distributed web crawls, you can read how a developer crawled 250M pages with Python in less than two days using 20 Amazon EC2 machine instances.
In some cases, you may run into websites that require you to execute JavaScript code to render all the HTML. Fail to do so, and you may not collect all links on the website. Because nowadays it’s very common for websites to render content dynamically in the browser I wrote a Scrapy middleware for rendering JavaScript pages using ScrapingBee’s API.
Conclusion
We compared the code of a Python crawler using third-party libraries for downloading URLs and parsing HTML with a crawler built using a popular web crawling framework. Scrapy is a very performant web crawling framework and it’s easy to extend with your custom code. But you need to know all the places where you can hook your own code and the settings for each component.
Configuring Scrapy properly becomes even more important when crawling websites with millions of pages. If you want to learn more about web crawling I suggest that you pick a popular website and try to crawl it. You will definitely run into new issues, which makes the topic fascinating!
💡 While this article does cover quite a bit of the more advanced topics (e.g. request throttling) there are still quite a few details to take into account to successfully crawl sites.
For example, some sites only serve geo-restricted content, perform browser fingerprinting, or require the client to solve CAPTCHAs. There's another article which addresses these issues and goes into detail on how you can scrape the web without getting blocked, please feel free to check it out.
Finding the right CSS selector can be, admittedly, a lot of fun, but if your project is on a schedule, you may not want to have to deal with user agents, distributed IP addresses, rate limiting, and headless browser instances. And that's exactly what ScrapingBee was made for and where it can help you to have a hassle-free SaaS web-scraping experience - please check out our no-code data extraction platform.



