In this article, I am going to show how to download bills (or any other file ) from a website with HtmlUnit.
I suggest you read these articles first: Introduction of how to do web scraping with Java and Autologin
Since I am hosting this blog on Digital Ocean (10$ in credit if you sign up via this link), I will show you how to write a bot to automatically download every bill you have.
Login
To submit the login form without needing to inspect the dom, we will use the magic method I wrote in the previous article.
Then we have to go to the billing page : https://cloud.digitalocean.com/settings/billing
String baseUrl = "https://cloud.digitalocean.com";
String login = "email";
String password = "password" ;
try {
WebClient client = Authenticator.autoLogin(baseUrl + "/login", login, password);
HtmlPage page = client.getPage("https://cloud.digitalocean.com/settings/billing");
if(page.asText().contains("You need to sign in for access to this page")){
throw new Exception(String.format("Error during login on %s , check your credentials", baseUrl));
}
}catch (Exception e) {
e.printStackTrace();
}
Fetching the bills
Let's create a new Class called Bill or Invoice to represent a bill :
Bill.java
public class Bill {
private String label ;
private BigDecimal amount ;
private Date date;
private String url ;
//... getters & setters
}
Now we need to inspect the dom to see how we can extract the description, amount, date, and URL of each bill. Open your favorite tool :
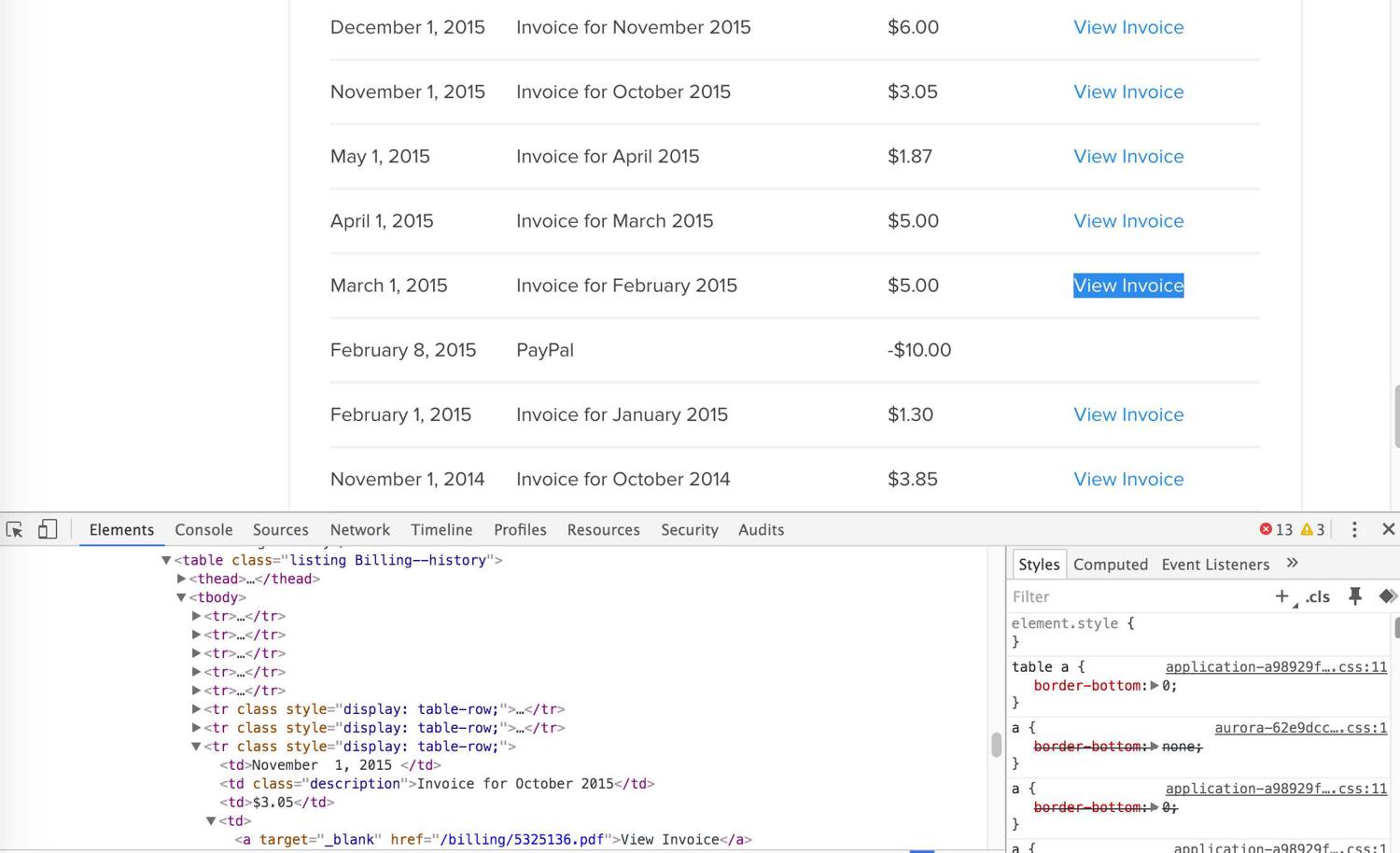
We are lucky here, it's a clean DOM, with a nice and well-structured table. Since HtmlUnit has many methods to handle HTML tables, we will use these :
HtmlTableto store the table and iterate on each rowgetCellto select the cells
Then, using the Jackson library we will export the Bill objects to JSON and print it.
HtmlTable billsTable = (HtmlTable) page.getFirstByXPath("//table[@class='listing Billing--history']");
for(HtmlTableRow row : billsTable.getBodies().get(0).getRows()){
String label = row.getCell(1).asText();
// We only want the invoice row, not the payment one
if(!label.contains("Invoice")){
continue ;
}
Date date = new SimpleDateFormat("MMMM d, yyyy", Locale.ENGLISH).parse(row.getCell(0).asText());
BigDecimal amount =new BigDecimal(row.getCell(2).asText().replace("$", ""));
String url = ((HtmlAnchor) row.getCell(3).getFirstChild()).getHrefAttribute();
Bill bill = new Bill(label, amount, date, url);
bills.add(bill);
ObjectMapper mapper = new ObjectMapper();
String jsonString = mapper.writeValueAsString(bill) ;
System.out.println(jsonString);
It's almost finished, the last thing is to download the invoice. It's pretty easy, we will use the Pageobject to store the pdf, and call a getContentAsStreamon it. It's better to check if the file has the right content type when doing this (application/pdf in our case)
Page invoicePdf = client.getPage(baseUrl + url);
if(invoicePdf.getWebResponse().getContentType().equals("application/pdf")){
IOUtils.copy(invoicePdf.getWebResponse().getContentAsStream(), new FileOutputStream("DigitalOcean" + label + ".pdf"));
}
That's it, here is the output :
{"label":"Invoice for December 2015","amount":0.35,"date":1451602800000,"url":"/billing/XXXXX.pdf"}
{"label":"Invoice for November 2015","amount":6.00,"date":1448924400000,"url":"/billing/XXXX.pdf"}
{"label":"Invoice for October 2015","amount":3.05,"date":1446332400000,"url":"/billing/XXXXX.pdf"}
{"label":"Invoice for April 2015","amount":1.87,"date":1430431200000,"url":"/billing/XXXXX.pdf"}
{"label":"Invoice for March 2015","amount":5.00,"date":1427839200000,"url":"/billing/XXXXX.pdf"}
{"label":"Invoice for February 2015","amount":5.00,"date":1425164400000,"url":"/billing/XXXXX.pdf"}
{"label":"Invoice for January 2015","amount":1.30,"date":1422745200000,"url":"/billing/XXXXXX.pdf"}
{"label":"Invoice for October 2014","amount":3.85,"date":1414796400000,"url":"/billing/XXXXXX.pdf"}
As usual, you can find the full code on this Github Repo
If you want to learn more about the parsing, you can checkout out our tutorial about HTML parsing in Java
If you like web scraping and are tired of taking care of proxies, JS rendering, and captchas, you can check our new web scraping API, the first 1000 API calls are on us.
Before you go, check out these related reads:
- Web Scraping vs Web Crawling: Ultimate Guide
- How to Log in to Almost Any Websites

Kevin worked in the web scraping industry for 10 years before co-founding ScrapingBee. He is also the author of the Java Web Scraping Handbook.
