The Best Web Scraping API to Avoid Getting Blocked
Scrape websites with our powerful web scraping API, without managing proxies, browsers, or anti-bot defenses. Fetch pages, leverage AI extraction, or integrate with dedicated APIs for LLM, RAG, and analytics pipelines.
- Easy to integrate
- 1,000 free scraper API credits
- No credit card required

Built for teams that scrape at scale
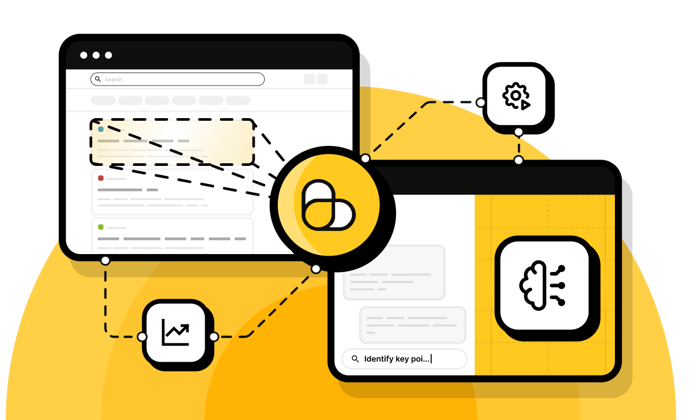
AI Ready Data
Define your AI web scraping rules in JSON, or describe what you need with AI Query. Run these workflows via the ScrapingBee CLI to integrate with AI coding tools like ChatGPT, Claude, Codex, Cursor, Claude Code, and Gemini.
- Structured JSON or Markdown from extraction rules
- Natural-language extraction with AI queries
- CLI integration for AI Agents. Connect with ChatGPT, Claude, Codex, Cursor, Claude Code, and Gemini

Render JavaScript in a real browser
Use headless Chrome when a page needs JavaScript rendering. Wait for selectors, run custom interaction scenarios for complex flows, set viewport and headers, and capture screenshots of the rendered output for debugging.
- JavaScript rendering in headless Chrome
- Wait for selectors and browser events
- Custom scenarios for complex interactions
- Adjust viewport and headers, capture screenshots of the final render

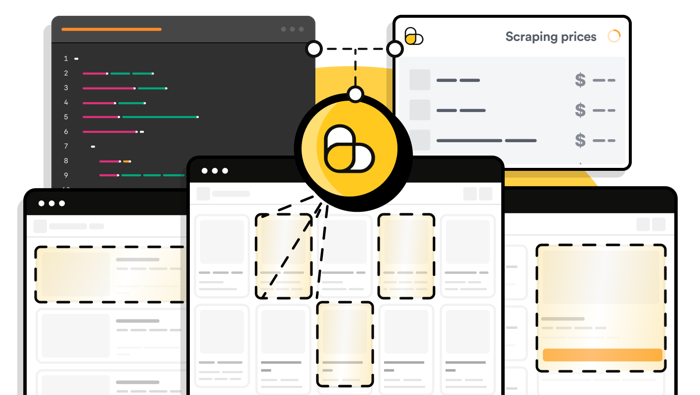
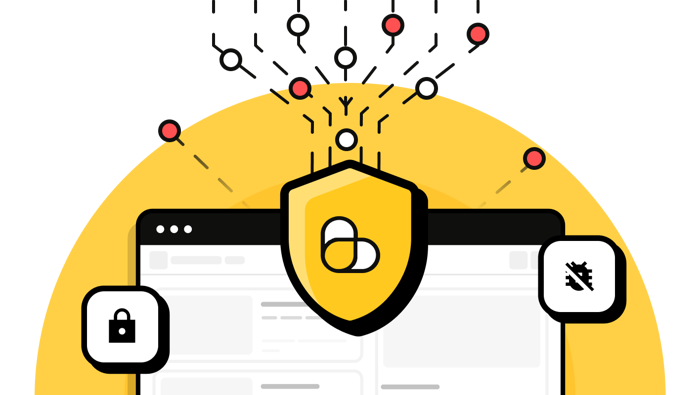
Automate your proxy rotation
ScrapingBee rotates proxies automatically, gives you premium proxies for harder websites, and offers stealth proxies for the toughest anti-bot setups. Add country-level geolocation and keep scraping without building your own proxy fleet.
- Premium residential and stealth proxies
- Country-level geolocation
- Lower block rates with less infrastructure overhead
- Automatic proxy rotation

Built for every use case
AI



Our Scraper APIs
HTML API
Dedicated Scraping APIs
Amazon API
Collect Amazon product, pricing, and review data directly for monitoring, analytics, and competitive research.

Fast Search API
Get real-time search results in under a second for AI, monitoring, analytics, and search-driven workflows.
Google Search API
Get Google search data through a dedicated endpoint, including organic results, ads, news, maps, and more.
YouTube API
Access YouTube search results, video metadata, comments, and transcripts in a ready-to-use format without maintaining your own scraper.

ChatGPT API
Generate and collect ChatGPT responses in JSON, Markdown, or plain text for analysis, monitoring, and downstream workflows.
Walmart API
Pull Walmart product, pricing, and review data in one scraper API call for monitoring, analytics, and competitive research.

Amazon API
Collect Amazon product, pricing, and review data directly for monitoring, analytics, and competitive research.
Fast Search API
Get real-time search results in under a second for AI, monitoring, analytics, and search-driven workflows.
Google Search API
Get Google search data through a dedicated endpoint, including organic results, ads, news, maps, and more.
YouTube API
Access YouTube search results, video metadata, comments, and transcripts in a ready-to-use format without maintaining your own scraper.
ChatGPT API
Generate and collect ChatGPT responses in JSON, Markdown, or plain text for analysis, monitoring, and downstream workflows.
Walmart API
Pull Walmart product, pricing, and review data in one scraper API call for monitoring, analytics, and competitive research.
Amazon API
Collect Amazon product, pricing, and review data directly for monitoring, analytics, and competitive research.
Fast Search API
Get real-time search results in under a second for AI, monitoring, analytics, and search-driven workflows.
Google Search API
Get Google search data through a dedicated endpoint, including organic results, ads, news, maps, and more.
YouTube API
Access YouTube search results, video metadata, comments, and transcripts in a ready-to-use format without maintaining your own scraper.
ChatGPT API
Generate and collect ChatGPT responses in JSON, Markdown, or plain text for analysis, monitoring, and downstream workflows.
Walmart API
Pull Walmart product, pricing, and review data in one scraper API call for monitoring, analytics, and competitive research.
"A reliable scraping backbone for multilingual market analysis."


"ScrapingBee really grew on us! Very good so far and we'll continue using it for a large project coming up as it just provides the consistency we need."



ScrapingBee has filled the void and allowed me to use an API to scrape instead of learning other libraries. "It has helped speed up our route towards complete competitive intelligence.


Compliance-Ready Web Scraping at Scale

Ready to get started?
Get 1,000 free API Credits No credit card required

Simple, transparent pricing.
Cancel anytime, no questions asked!
Need more monthly credits or higher concurrency?
Talk to Product ExpertNot sure which plan you need?
Web Scraping API FAQs
A web scraping API lets you fetch data from websites without building and maintaining your own scraping infrastructure. Instead of managing proxies, browsers, retries, and anti-bot issues yourself, you send a request to the API and get back the page HTML, rendered content, or extracted data.